Analyzing Language and Geographical Variation in Speech Representations Across 60 Indic Languages
Pith reviewed 2026-06-26 15:57 UTC · model grok-4.3
The pith
Joint language and district supervision produces speech embeddings with global language clusters containing district-aligned subclusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Language-district supervision produces global language clusters with structured within language subclusters aligned to district variation, enhancing geographical separability without degrading language-level organization.
What carries the argument
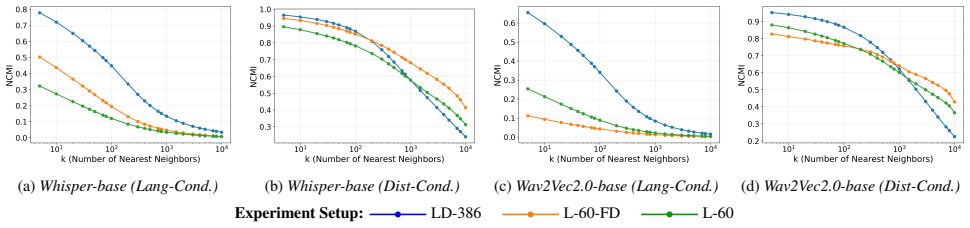
Normalized Conditional Mutual Information (NCMI) metric that quantifies how joint language-district supervision organizes embeddings into language clusters with district subclusters.
If this is right
- District discrimination improves when conditioned on language under joint supervision.
- Marginal language classification performance remains strong.
- Geographical separability increases in the embedding space.
- Within-language subclusters align to district variation.
Where Pith is reading between the lines
- The resulting structure may support downstream tasks such as accent-aware or region-specific speech recognition.
- The same joint-supervision pattern could be tested on other language families that show high internal geographical variation.
- NCMI could be applied more broadly to diagnose multi-level organization in other representation-learning settings.
Load-bearing premise
Differences in district discrimination conditioned on language arise specifically from the choice of joint versus language-only supervision rather than dataset properties, fine-tuning details, or the NCMI metric itself.
What would settle it
An experiment that trains with language-only supervision on matched data but yields the same NCMI scores for district-within-language structure would falsify the claim that joint supervision drives the observed organization.
Figures
read the original abstract
Self-supervised speech encoders are often fine-tuned with language supervision, which can overlook geographical variation. To understand the learned representations under joint supervision of language and district compared to language-only supervision, we fine-tune Whisper-base and Wav2Vec2.0-base for classification tasks with joint language-district (386 classes) and language-only classification (60 languages). The language-district supervision improves district discrimination conditioned on language in the embedding space while strong marginal language classification. We analyze the structure of the learned embeddings using Normalized Conditional Mutual Information (NCMI), showing that language-district supervision produces global language clusters with structured within language subclusters aligned to district variation, enhancing geographical separability without degrading language-level organization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper fine-tunes Whisper-base and Wav2Vec2.0-base on 60 Indic languages using either language-only supervision (60 classes) or joint language-district supervision (386 classes). It claims that the joint objective yields embeddings that preserve strong marginal language clustering while producing structured within-language subclusters aligned to district variation, thereby improving geographical separability; this is quantified via Normalized Conditional Mutual Information (NCMI) between language and district labels in the embedding space.
Significance. If the attribution to joint supervision survives proper controls, the result would demonstrate that adding district-level labels during fine-tuning can enrich speech representations with geographical structure without harming language-level organization. This has potential implications for building more robust multilingual ASR systems in linguistically and geographically diverse regions. The NCMI-based analysis offers a concrete way to measure conditional structure in learned embeddings.
major comments (2)
- [§3] §3 (experimental design): the comparison of 386-class joint supervision against 60-class language-only supervision does not include ablations that hold label cardinality fixed, match class priors, or use identical optimization schedules. Because the two conditions differ in the number of output classes and effective batch statistics, it is unclear whether the reported NCMI gains in within-language district discrimination (§4) arise specifically from the joint supervision signal or from the finer label space itself.
- [§4] §4 (NCMI definition and results): the paper does not report error bars, statistical significance tests, or sensitivity analyses for the NCMI values across the two supervision regimes. Without these, the claim that language-district supervision “enhances geographical separability without degrading language-level organization” rests on point estimates whose reliability cannot be assessed.
minor comments (2)
- [Abstract, §3] The abstract and §3 should explicitly state the total number of utterances per language/district and any class-balancing steps applied during fine-tuning.
- [§4] Notation for NCMI should be defined with a short equation or reference to the exact mutual-information formula used, rather than only a high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (experimental design): the comparison of 386-class joint supervision against 60-class language-only supervision does not include ablations that hold label cardinality fixed, match class priors, or use identical optimization schedules. Because the two conditions differ in the number of output classes and effective batch statistics, it is unclear whether the reported NCMI gains in within-language district discrimination (§4) arise specifically from the joint supervision signal or from the finer label space itself.
Authors: The joint language-district supervision uses 386 classes by design, as each class corresponds to a unique language-district pair; this is the natural formulation of the joint objective rather than an arbitrary choice. Matching cardinality exactly would require artificial merging of districts or subsampling, which would alter the geographical signal we aim to study. Optimization schedules were aligned as closely as possible (same epochs, learning rate schedule, and batch size), with differences arising only from the output layer dimensionality. We will revise §3 to explicitly discuss this design rationale and its implications as a limitation, while noting that the observed NCMI improvements are tied to the joint labeling structure. revision: partial
-
Referee: [§4] §4 (NCMI definition and results): the paper does not report error bars, statistical significance tests, or sensitivity analyses for the NCMI values across the two supervision regimes. Without these, the claim that language-district supervision “enhances geographical separability without degrading language-level organization” rests on point estimates whose reliability cannot be assessed.
Authors: We acknowledge that variability measures are needed to support the claims. The reported NCMI figures come from single training runs owing to the high computational cost of fine-tuning on 60 languages. In the revision we will add sensitivity analyses (e.g., across different numbers of clusters and embedding projection dimensions) and, where feasible, report results from multiple random seeds with error bars and basic significance testing to quantify the stability of the observed differences. revision: yes
Circularity Check
No circularity: purely empirical analysis with no derivations or self-referential predictions
full rationale
The paper is an empirical study that fine-tunes Whisper and Wav2Vec2 models on language-only (60-class) vs. joint language-district (386-class) supervision tasks, then measures embedding structure via the NCMI metric. No mathematical derivations, first-principles predictions, or quantities are claimed; all results are experimental outcomes on held-out data. NCMI is a standard information-theoretic measure applied post-hoc to embeddings and does not reduce to any fitted parameter by construction. No self-citations are load-bearing for the core claims, and the analysis does not rename known results or smuggle ansatzes. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech embedding spaces learned by deep neural networks have become foundational to modern speech processing sys- tems, supporting tasks such as language identification (LID), automatic speech recognition (ASR), speaker verification, and accent classification. Beyond downstream performance, recent work shows that supervised and self-supervise...
Pith/arXiv arXiv 2026
-
[2]
We select 60 languages spanning 165 districts, yielding 386 language-district classes
Dataset We conduct experiments on a subset of theVaanispeech cor- pus [17], a large-scale Indian speech dataset with fine-grained geographical metadata, making it well suited for analyzing the interaction between language-level supervision and geographi- cal variation in multilingual speech models. We select 60 languages spanning 165 districts, yielding 3...
-
[3]
Experimental Setup & Embedding Analysis 3.1. Pretrained Models Architecture We evaluate two pretrained speech encoders: Whisper-base and Wav2Vec2.0-base. Whisper-base operates on log-Mel spectro- gram inputs, while Wav2Vec2.0-base processes raw waveforms via a convolutional feature encoder followed by a Transformer context network. In both cases, the enco...
-
[4]
Experiments and Results 4.1. Language Classification Performanc Table 1 reports overall classification accuracy, marginal lan- guage performance (obtained by aggregating district probabili- ties for LD-386), and district-level performance for joint mod- els. For Whisper-base, LD-386 achieves strong marginal lan- guage performance (84.79% accuracy, 79.00 F...
-
[5]
Conclusion and Future Work We show that supervision granularity shapes multilingual speech embeddings: joint language-district training, while in- creasing task difficulty, preserves strong marginal language performance and markedly improves district discriminability. Language-conditioned probing and NCMI analysis reveal that fine-grained supervision form...
-
[6]
Neighbors and relatives: How do speech embeddings reflect linguistic connections across the world?
T. T ¨or¨o, A. Suni, and J. ˇSimko, “Neighbors and relatives: How do speech embeddings reflect linguistic connections across the world?”PLoS One, vol. 20, no. 8, p. e0330755, 2025
2025
-
[7]
Quantifying language variation acoustically with few resources,
M. Bartelds and M. Wieling, “Quantifying language variation acoustically with few resources,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022, pp. 3735–3741
2022
-
[8]
Deep learning for spoken language identification: Can we visualize speech signal patterns?
H. Mukherjee, S. Ghosh, S. Sen, O. Sk Md, K. Santosh, S. Phadikar, and K. Roy, “Deep learning for spoken language identification: Can we visualize speech signal patterns?”Neu- ral Computing and Applications, vol. 31, no. 12, pp. 8483–8501, 2019
2019
-
[9]
Indian language identifi- cation using deep learning,
S. Godbole, V . Jadhav, and G. Birajdar, “Indian language identifi- cation using deep learning,” inITM Web of Conferences, vol. 32. EDP Sciences, 2020, p. 01010
2020
-
[10]
Cross-corpora language recognition: A preliminary investigation with indian languages,
S. Dey, G. Saha, and M. Sahidullah, “Cross-corpora language recognition: A preliminary investigation with indian languages,” in2021 29th European Signal Processing Conference (EU- SIPCO). IEEE, 2021, pp. 546–550
2021
-
[11]
Cross-corpora spoken lan- guage identification with domain diversification and generaliza- tion,
S. Dey, M. Sahidullah, and G. Saha, “Cross-corpora spoken lan- guage identification with domain diversification and generaliza- tion,”Computer Speech & Language, vol. 81, p. 101489, 2023
2023
-
[12]
Self-supervised phonotactic representations for language identification
G. Ramesh, C. S. Kumar, and K. S. R. Murty, “Self-supervised phonotactic representations for language identification.” inInter- speech, 2021, pp. 1514–1518
2021
-
[13]
M. M. Shaik, D. Klakow, and B. M. Abdullah, “Self-supervised adaptive pre-training of multilingual speech models for language and dialect identification,”arXiv preprint arXiv:2312.07338, 2023
arXiv 2023
-
[14]
A unified approach to mul- tilingual automatic speech recognition with improved language identification for indic languages
N. Jakhar, S. Srivastava, and A. Baby, “A unified approach to mul- tilingual automatic speech recognition with improved language identification for indic languages.” inINTERSPEECH, 2024
2024
-
[15]
Dhwani - domain adapted hybrid whisper for audio transcrip- tion in indic languages,
S. Sasmal, H. Nikam, P. Dhote, M. Bhargava, and L. Singh, “Dhwani - domain adapted hybrid whisper for audio transcrip- tion in indic languages,” in2025 IEEE Pune Section International Conference (PuneCon), 2025, pp. 1–6
2025
-
[16]
Variation and instability in dialect-based embedding spaces,
J. Dunn, “Variation and instability in dialect-based embedding spaces,” inTenth Workshop on NLP for similar languages, Va- rieties and dialects (VarDial 2023), 2023, pp. 67–77
2023
-
[17]
Advanced accent/dialect identifi- cation and accentedness assessment with multi-embedding mod- els and automatic speech recognition,
S. Ghorbani and J. H. Hansen, “Advanced accent/dialect identifi- cation and accentedness assessment with multi-embedding mod- els and automatic speech recognition,”The Journal of the Acous- tical Society of America, vol. 155, no. 6, pp. 3848–3860, 2024
2024
-
[18]
Jointly improving dialect identifica- tion and asr in indian languages using multimodal feature fusion,
S. Kumar, P. K. Ghoshet al., “Jointly improving dialect identifica- tion and asr in indian languages using multimodal feature fusion,” inProc. Interspeech 2025, 2025, pp. 2770–2774
2025
-
[19]
Improving dialect identifi- cation in indian languages using multimodal features from dialect informed asr,
S. Kumar, S. Sharma, S. Udupa, S. Badiger, A. Singh, J. Ban- dekar, S. Murthy, P. K. Ghoshet al., “Improving dialect identifi- cation in indian languages using multimodal features from dialect informed asr,” inICASSP 2025-2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[20]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[21]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[22]
Vaani: Capturing the language landscape for an inclusive digital india,
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Vishwakarma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arx...
Pith/arXiv arXiv 2026
-
[23]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[24]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Ad- vances in neural information processing systems, vol. 32, 2019
2019
-
[25]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “Transformers: State-of-the-art natural language processing,” inProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45
2020
-
[26]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourget al., “Scikit-learn: Machine learning in python,”the Journal of ma- chine Learning research, vol. 12, pp. 2825–2830, 2011
2011
-
[27]
Scipy 1.0: fundamental algorithms for scientific comput- ing in python,
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright et al., “Scipy 1.0: fundamental algorithms for scientific comput- ing in python,”Nature methods, vol. 17, no. 3, pp. 261–272, 2020
2020
-
[28]
Array programming with numpy,
C. R. Harris, K. J. Millman, S. J. Van Der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smithet al., “Array programming with numpy,”nature, vol. 585, no. 7825, pp. 357–362, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.