Communication-Semantic-Aware RDMA Loss Recovery for QP-scalable Hyperscale AI Training
Pith reviewed 2026-06-30 23:33 UTC · model grok-4.3
The pith
CSA-UD recovers RDMA packet losses in AI training by exploiting synchronization semantics to enable scalable unreliable datagram use without per-pair queue pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
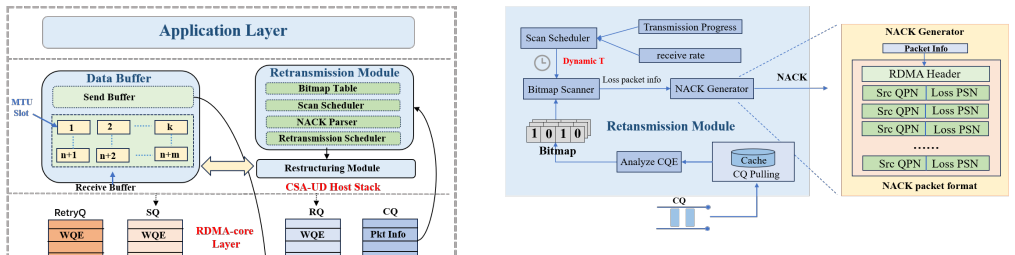
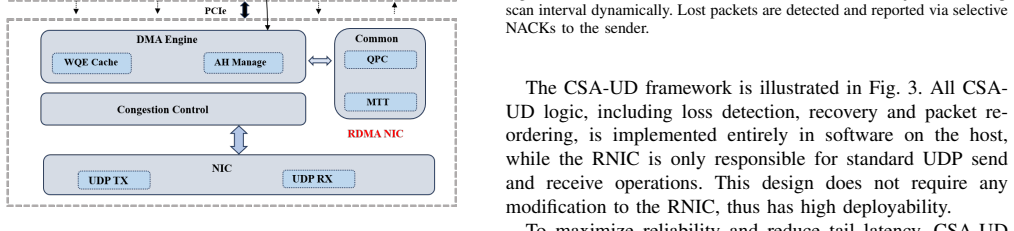
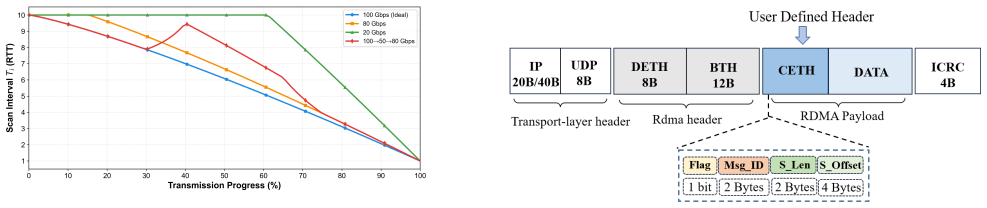
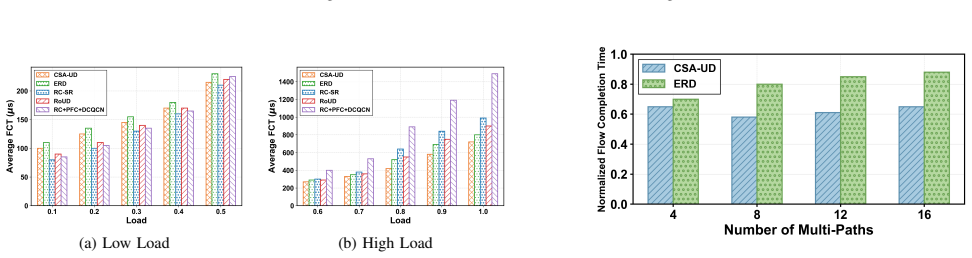
CSA-UD decouples data transmission from loss recovery and dynamically adjusts the loss detection interval, accelerating tail recovery and exploiting the synchronization semantics of distributed training. It further supports multipath transmission and bitmap-guided reassembly, enabling high throughput without requiring lossless fabrics.
What carries the argument
Communication-Semantic-Aware Unreliable Datagram (CSA-UD) loss recovery that uses training synchronization points to set dynamic loss detection intervals.
If this is right
- CSA-UD achieves better scalability than RC by avoiding RNIC queue-pair cache limits on the order of thousands of entries.
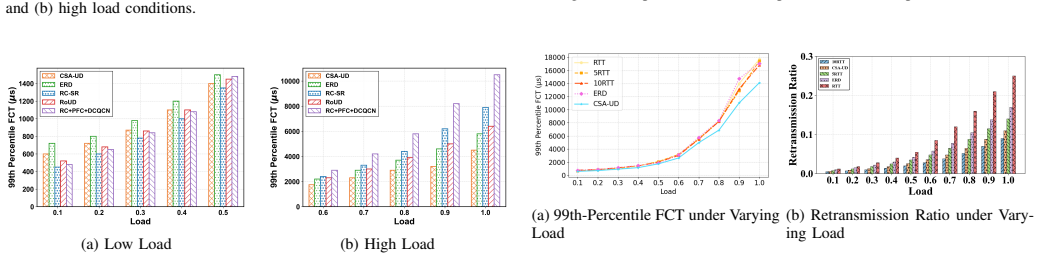
- Under high network load it reduces 99th-percentile flow completion times by over 30 percent compared with existing RC and UD counterparts.
- Collective operations such as All-Reduce and All-to-All can run at high throughput without lossless fabrics.
- Multipath transmission combined with bitmap-guided reassembly keeps tail recovery fast even when individual paths experience loss.
Where Pith is reading between the lines
- The same semantic-aware interval adjustment could be applied to other periodically synchronized distributed workloads outside AI training.
- Bitmap-guided reassembly may allow existing RDMA hardware to support higher message rates without additional lossless-network requirements.
- Dynamic loss detection tuned to sync points might be tested on workloads that have regular barriers but lack the strict all-to-all pattern of training collectives.
Load-bearing premise
The synchronization semantics of distributed training can be safely exploited to dynamically adjust loss detection intervals without missing losses or adding unacceptable overhead in production hyperscale deployments.
What would settle it
A production-scale training run in which CSA-UD's dynamic detection intervals either miss losses that delay iterations or add overhead that negates the reported tail-latency gains.
Figures




read the original abstract
Current artificial intelligence (AI) infrastructures widely adopt Remote Direct Memory Access (RDMA) to support high-performance communication. Training trillion-parameter models involves frequent collective communication operations, such as All-Reduce and All-to-All, which generate intensive RDMA traffic. Existing RDMA deployments predominantly use the reliable connection (RC) model, where each process pair requires a dedicated queue pair (QP). This leads to poor scalability: since the RDMA-capable network interface card (RNIC) can cache only a few thousand QPs, excess entries trigger PCIe round-trip penalties. Meanwhile, global synchronization makes training sensitive to tail latency, where a few packet losses can delay iteration completion. To address these challenges, we propose Communication-Semantic-Aware Unreliable Datagram (CSA-UD), a novel RDMA loss recovery mechanism that combines scalability and reliability. CSA-UD decouples data transmission from loss recovery and dynamically adjusts the loss detection interval, accelerating tail recovery and exploiting the synchronization semantics of distributed training. It further supports multipath transmission and bitmap-guided reassembly, enabling high throughput without requiring lossless fabrics. Testbed experiments and ns-3 simulations show that CSA-UD significantly reduces tail latency under large-scale collective communication. Under high network load, it achieves better scalability than RC and over 30% lower 99th percentile flow completion times compared with counterparts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CSA-UD, a novel RDMA loss recovery mechanism for hyperscale AI training that decouples data transmission from loss recovery, dynamically adjusts loss detection intervals by exploiting collective synchronization semantics (e.g., All-Reduce), supports multipath transmission and bitmap-guided reassembly, and claims to achieve QP scalability superior to RC while reducing tail latency. Testbed experiments and ns-3 simulations are reported to show better scalability than RC and over 30% lower 99th-percentile flow completion times under high network load.
Significance. If the performance claims and safety of the dynamic interval adjustment hold under realistic straggler and jitter conditions, the work could meaningfully improve scalability and tail-latency behavior in large-scale collective communication for trillion-parameter training without requiring lossless fabrics.
major comments (2)
- [Abstract / CSA-UD design] Abstract (and CSA-UD design paragraph): the central performance claims (>30% lower 99th-percentile FCT, better scalability than RC) rest on the ability to safely shorten loss-detection intervals via synchronization semantics, yet no quantitative bound, tolerance analysis, or worst-case overhead is supplied for iteration-time variation or stragglers; this directly affects whether the reliability guarantee and tail-latency benefit are preserved.
- [Abstract] Abstract: the reported experimental results supply no setup details, baselines, error bars, statistical tests, or data-exclusion rules, rendering the soundness of the 30% FCT reduction and scalability claims unverifiable from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the manuscript can be strengthened. We address each major comment below and will incorporate revisions to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract / CSA-UD design] Abstract (and CSA-UD design paragraph): the central performance claims (>30% lower 99th-percentile FCT, better scalability than RC) rest on the ability to safely shorten loss-detection intervals via synchronization semantics, yet no quantitative bound, tolerance analysis, or worst-case overhead is supplied for iteration-time variation or stragglers; this directly affects whether the reliability guarantee and tail-latency benefit are preserved.
Authors: We agree that explicit quantitative bounds and tolerance analysis are needed to fully substantiate the safety of dynamically shortening loss-detection intervals. The manuscript describes how collective synchronization (e.g., All-Reduce barriers) limits iteration-time variation, but does not supply formal worst-case overhead calculations or sensitivity analysis under stragglers/jitter. In revision we will add a new analysis subsection deriving bounds from testbed-measured straggler distributions, including the maximum safe shortening factor and overhead under high jitter, to confirm that reliability and tail-latency gains are preserved. revision: yes
-
Referee: [Abstract] Abstract: the reported experimental results supply no setup details, baselines, error bars, statistical tests, or data-exclusion rules, rendering the soundness of the 30% FCT reduction and scalability claims unverifiable from the provided text.
Authors: The abstract is intentionally concise and therefore omits detailed methodology. The full manuscript (Section 5) already contains the testbed configuration, ns-3 parameters, baselines (RC and prior UD schemes), error bars from repeated runs, and statistical tests. To improve verifiability directly from the abstract we will add a short clause summarizing key setup elements (node count, loss rate, baselines) and a pointer to the full evaluation section for error bars and statistical details. revision: partial
Circularity Check
No significant circularity in mechanism design or experimental validation
full rationale
The paper proposes CSA-UD as a new RDMA loss recovery design that decouples transmission from recovery and adjusts detection intervals using collective synchronization semantics. Performance claims rest on testbed experiments and ns-3 simulations rather than any derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps. No equations or self-referential reductions appear in the abstract or described approach; the central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
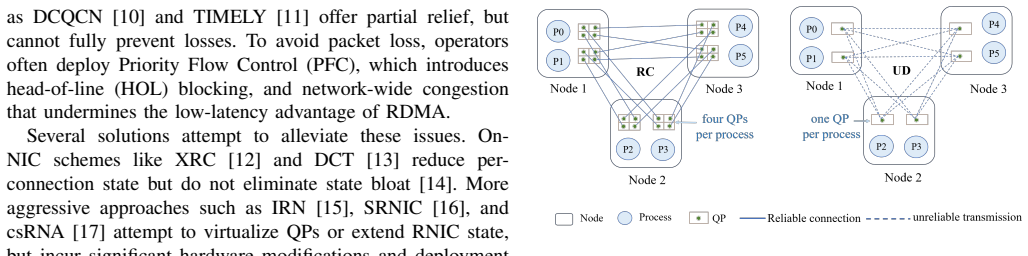
- domain assumption Existing RDMA deployments predominantly use the reliable connection (RC) model where each process pair requires a dedicated queue pair (QP).
- domain assumption Global synchronization in training makes it sensitive to tail latency from packet losses.
invented entities (1)
-
CSA-UD
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Insights into deepseek-v3: Scaling challenges and reflections on hardware for ai architectures,
C. Zhao, C. Deng, C. Ruan, D. Dai, H. Gao, J. Li, L. Zhang, P. Huang, S. Zhou, S. Ma, W. Liang, Y . He, Y . Wang, Y . Liu, and Y . X. Wei, “Insights into deepseek-v3: Scaling challenges and reflections on hardware for ai architectures,”arXiv preprint arXiv:2505.09343, 2025
-
[2]
K. F. Pilz, J. Sanders, R. Rahman, and L. Heim, “Trends in ai supercomputers,”arXiv preprint arXiv:2504.16026, 2025
-
[3]
Understanding communication characteristics of distributed training,
W. Li, X. Liu, Y . Li, Y . Jin, H. Tian, Z. Zhong, G. Liu, Y . Zhang, and K. Chen, “Understanding communication characteristics of distributed training,” inProceedings of the 8th Asia-Pacific Workshop on Network- ing (APNet), Sydney, NSW, Australia, Aug. 2024, pp. 1–8
2024
-
[4]
OHIO: Improving RDMA network scalability in MPI Alltoall through optimized hierarchical and intra/inter-node communication overlap design,
T. Tran, G. K. R. Kuncham, B. Ramesh, S. Xu, H. Subramoni, M. Abdul- jabbar, and D. K. Panda, “OHIO: Improving RDMA network scalability in MPI Alltoall through optimized hierarchical and intra/inter-node communication overlap design,” inProceedings of the 2024 IEEE Symposium on High-Performance Interconnects (HOTI). Santa Clara, CA, USA: IEEE, 2024
2024
-
[5]
Janus: A unified distributed training framework for sparse mixture-of-experts models,
J. Liu, J. H. Wang, and Y . Jiang, “Janus: A unified distributed training framework for sparse mixture-of-experts models,” inProceedings of the ACM SIGCOMM Conference. ACM, 2023, pp. 486–498
2023
-
[6]
Rdma over ethernet for distributed AI training at Meta scale,
A. Gangidi, R. Miao, S. Zheng, S. J. Bondu, G. Goes, H. Morsy, R. Puri, M. Riftadi, A. J. Shetty, J. Yang, S. Zhang, M. J. Fernandez, S. Gandham, and H. Zeng, “Rdma over ethernet for distributed AI training at Meta scale,” inProceedings of the ACM SIGCOMM 2024 Conference. Sydney, NSW, Australia: ACM, 2024, pp. 57–70
2024
-
[7]
Birds of a feather flock together: Scaling rdma rpcs with flock,
S. K. Monga, S. Kashyap, and C. Min, “Birds of a feather flock together: Scaling rdma rpcs with flock,” inProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP). ACM, 2021, pp. 212–227
2021
-
[8]
1rma: Re-envisioning remote memory access for multitenant datacenters,
A. Singhvi, A. Akella, D. Gibson, T. F. Wenisch, M. Wong-Chan, S. Clark, M. M. K. Martin, M. McLaren, P. Chandra, R. Cauble, H. M. G. Wassel, B. Montazeri, S. L. Sabato, J. Scherpelz, and A. Vahdat, “1rma: Re-envisioning remote memory access for multitenant datacenters,” in SIGCOMM ’20: Proceedings of the 2020 Annual Conference of the ACM Special Interest...
2020
-
[9]
An optimized RDMA QP communication mechanism for hyperscale AI infrastructure,
J. Wang, B. Lin, J. Zhang, M. Sun, and Y . Pan, “An optimized RDMA QP communication mechanism for hyperscale AI infrastructure,”Cluster Computing, vol. 28, p. 66, Nov. 2025
2025
-
[10]
Congestion control for large-scale rdma deployments,
H. Eran, H. Patel, J. Bruno, and ..., “Congestion control for large-scale rdma deployments,” inProceedings of the 2015 ACM SIGCOMM Conference, 2015
2015
-
[11]
Timely: Rtt-based congestion control for the datacenter,
R. Mittal, V . T. Lam, N. Dukkipati, E. Blem, H. Wassel, M. Ghobadi, A. Vahdat, Y . Wang, D. Wetherall, and D. Zats, “Timely: Rtt-based congestion control for the datacenter,” inProceedings of the 2015 ACM SIGCOMM Conference, 2015
2015
-
[12]
Annex 14: Extended reliable connections (xrc),
InfiniBand Trade Association, “Annex 14: Extended reliable connections (xrc),” 2009, https://members.infinibandta.org/apps/org/workgroup/ibta/ documents.php?folder id=102
2009
-
[13]
Dynamically connected transport: Scalable rdma transport for large clusters,
A. Rosenbaum and A. Margolin, “Dynamically connected transport: Scalable rdma transport for large clusters,” inOpenFabrics Alliance Workshop, 2018
2018
-
[14]
NVIDIA Corporation,Mellanox Adapters Programmer’s Reference Manual (PRM), NVIDIA, 2020, available: https://network.nvidia.com/ files/doc-2020/ethernet-adapters-programming-manual.pdf
2020
-
[15]
Revisiting network support for RDMA,
R. Mittal, A. Shpiner, A. Panda, E. Zahavi, A. Krishnamurthy, S. Rat- nasamy, and S. Shenker, “Revisiting network support for RDMA,” in Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication (SIGCOMM ’18). Association for Computing Machinery, 2018, pp. 313–326
2018
-
[16]
Srnic: A scalable architecture for rdma nics,
Z. Wang, W. Bai, K. Chen, H. Zhang, and R. Miao, “Srnic: A scalable architecture for rdma nics,” inProc. USENIX NSDI, 2023
2023
-
[17]
A survey of storage systems in the rdma era,
S. Ma, T. Ma, K. Chenet al., “A survey of storage systems in the rdma era,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 12, pp. 4395–4409, 2022
2022
-
[18]
Roud: Scalable rdma over ud in lossy data center networks,
Z. He, Y . Chen, and B. Hua, “Roud: Scalable rdma over ud in lossy data center networks,” inProc. IEEE/ACM CCGrid, 2023
2023
-
[19]
Memory efficient loss recovery for hardware-based transport in datacenter,
Y . Lu, G. Chen, Z. Ruan, W. Xiao, B. Li, J. Zhang, Y . Xiong, P. Cheng, and E. Chen, “Memory efficient loss recovery for hardware-based transport in datacenter,” inProceedings of the 1st Asia-Pacific Workshop on Networking (APNet), Hong Kong, China, Aug. 2017, pp. 22–28
2017
-
[20]
Infiniband architecture specification, volume 1, release 1.8,
InfiniBand Trade Association, “Infiniband architecture specification, volume 1, release 1.8,” https://www.infinibandta.org/ibta-specification/, 2024, accessed: 2025-07-31
2024
-
[21]
Star: Breaking the scalability limit for rdma,
X. Wang, G. Chen, X. Yin, Y . Cheng, and B. Hua, “Star: Breaking the scalability limit for rdma,” inProc. IEEE ICNP, 2021
2021
-
[22]
Scalable reliable datagram (srd): Reliable high- throughput networking for hpc and ml workloads,
AWS Networking, “Scalable reliable datagram (srd): Reliable high- throughput networking for hpc and ml workloads,” 2022, https://aws. amazon.com/blogs/networking-and-content-delivery/introducing-srd/
2022
-
[23]
Mp-rdma: En- abling rdma with multi-path transport in datacenters,
G. Chen, Y . Geng, M. Alizadeh, and H. Balakrishnan, “Mp-rdma: En- abling rdma with multi-path transport in datacenters,” inProc. USENIX NSDI, 2018
2018
-
[24]
Load balancing in pfc-enabled datacenter networks,
J. Hu, C. Zeng, Z. Chen, W. Bai, and K. Chen, “Load balancing in pfc-enabled datacenter networks,” inProc. ACM Asia-Pacific Workshop on Networking (APNet), 2022, pp. 21–28
2022
-
[25]
Mptd: Optimizing multi-path transport with dynamic target delay in datacenters,
M. Li, S. Wang, T. Huang, and Y . Liu, “Mptd: Optimizing multi-path transport with dynamic target delay in datacenters,”Cluster Computing, vol. 27, no. 8, pp. 11 455–11 469, 2024
2024
-
[26]
Ud-assisted multi-path transport in rdma,
M. Choi, S. Lee, and Y . Kim, “Ud-assisted multi-path transport in rdma,” inProc. IEEE International Conference on Information and Communication Technology Convergence (ICTC), 2022, pp. 127–129
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.