DisSpeech: Low-Resource Controllable Mandarin Stuttered Speech Synthesis for ASR Augmentation
Pith reviewed 2026-06-26 12:51 UTC · model grok-4.3
The pith
DisSpeech generates controllable stuttered Mandarin speech from under 50 hours of data to improve ASR models on disfluent speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
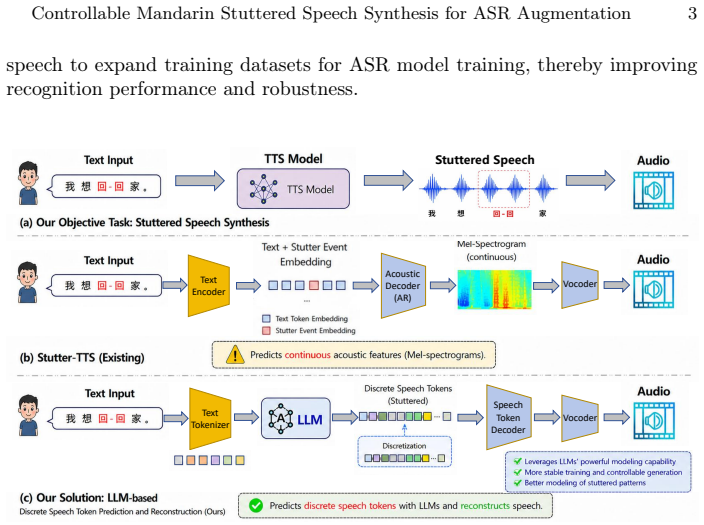
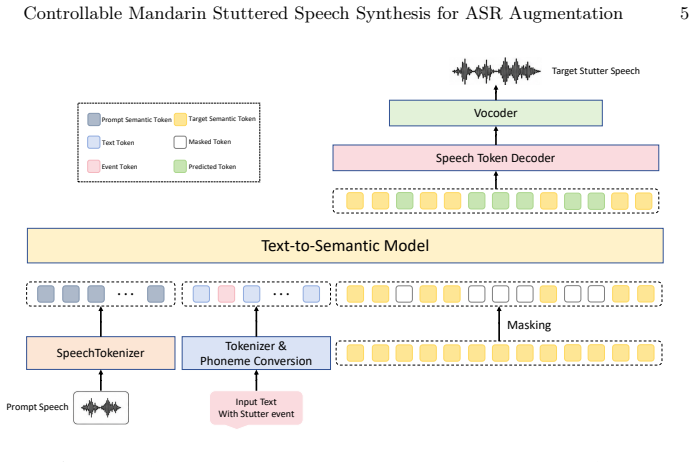
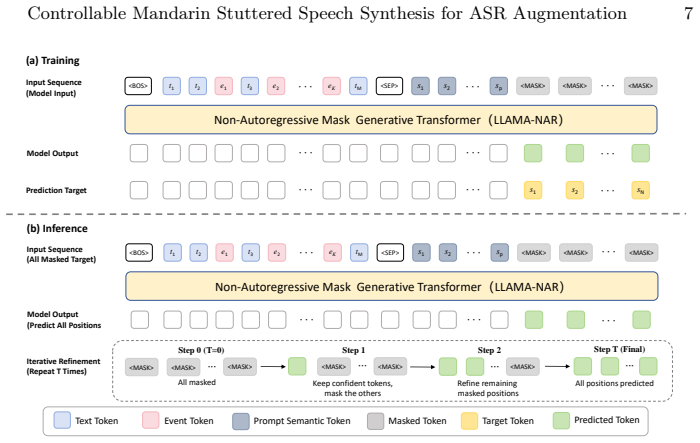
DisSpeech is a discrete speech token-based framework that maps text and stuttering event labels into semantic speech tokens by a non-autoregressive masked generative Transformer, followed by prosody-aware acoustic reconstruction with explicit pitch and energy modeling. Fine-tuned on less than 50 hours of Mandarin stuttered speech, the system generates controllable stuttered speech that outperforms prior synthesis methods in quality and event controllability. When used for ASR data augmentation, the synthesized speech improves multiple recognizers, reaching a state-of-the-art CER of 4.19 percent on the evaluated Mandarin stuttered speech recognition task with only slight degradation on fluent
What carries the argument
Non-autoregressive masked generative Transformer that maps text and explicit stuttering event labels to semantic speech tokens before prosody-aware acoustic reconstruction.
If this is right
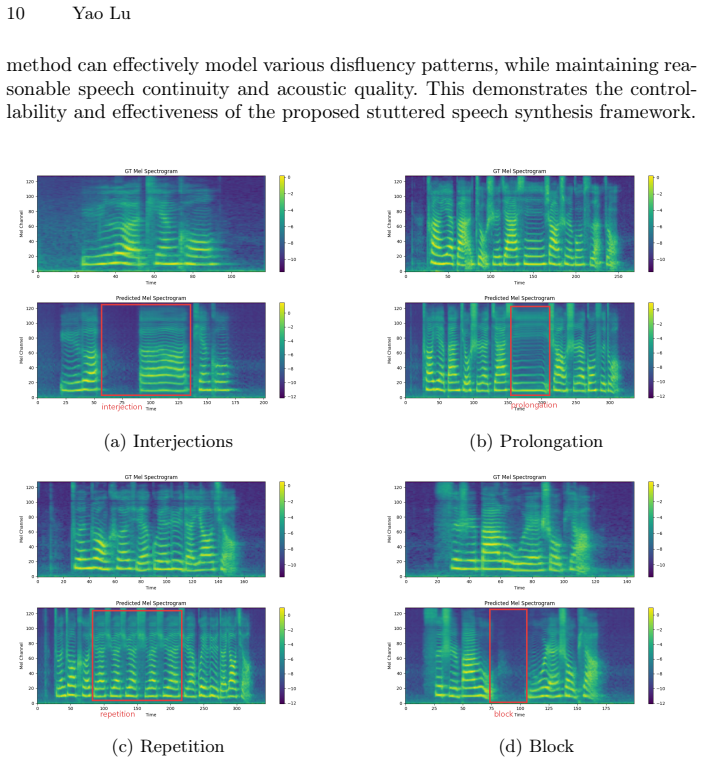
- The method outperforms earlier stuttered speech synthesis approaches in both quality and controllability of disfluency events.
- Augmenting ASR training with the generated speech yields measurable gains on stuttered test sets for multiple models.
- Qwen3-ASR-0.6B reaches 4.19 percent CER on the stuttered recognition task after augmentation.
- Performance loss on fluent speech remains slight after the same augmentation step.
- The framework operates effectively after fine-tuning on under 50 hours of target-language stuttered data.
Where Pith is reading between the lines
- The same label-driven token approach could be tested on other languages that also lack large stuttered corpora.
- Generated data might be mixed with real recordings in varying ratios to find the smallest augmentation volume that still lifts ASR accuracy.
- The controllability over specific disfluency types opens the possibility of targeted training sets for particular speaker populations or clinical applications.
- Because the pipeline separates semantic token generation from acoustic rendering, future work could swap in different acoustic models without retraining the label-to-token stage.
Load-bearing premise
That fine-tuning on less than 50 hours of real stuttered Mandarin speech produces synthetic examples realistic enough to improve ASR on actual disfluent recordings without introducing harmful artifacts.
What would settle it
Train ASR models on the same fluent data plus either DisSpeech-augmented stuttered examples or real stuttered examples, then compare character error rates on a held-out set of real Mandarin stuttered recordings.
Figures
read the original abstract
Stuttered speech recognition remains challenging, with disfluencies such as repetitions, prolongations, and blocks disrupting speech continuity and acoustic patterns. This problem is further aggravated in Mandarin scenarios by the limited availability of stuttered speech data, which makes it difficult to train robust ASR models for diverse disfluency patterns. To address this problem, this paper proposes DisSpeech, a discrete speech token-based framework for low-resource controllable Mandarin stuttered speech synthesis and ASR data augmentation. The proposed framework introduces explicit stuttering event labels to control different disfluency patterns. Text and stuttering event labels are mapped into semantic speech tokens by a non-autoregressive masked generative Transformer, followed by prosody-aware acoustic reconstruction with explicit pitch and energy modeling. With fine-tuning using less than 50 hours of Mandarin stuttered speech, DisSpeech can generate controllable stuttered speech with competitive speech quality. Experimental results show that the proposed method outperforms previous stuttered speech synthesis methods in both speech quality and event controllability. Furthermore, the synthesized stuttered speech effectively improves multiple ASR models, with Qwen3-ASR-0.6B achieving a state-of-the-art CER of 4.19% on the evaluated Mandarin stuttered speech recognition task, while causing only slight degradation on fluent speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DisSpeech, a discrete speech token-based framework for low-resource controllable Mandarin stuttered speech synthesis. It uses explicit stuttering event labels mapped via a non-autoregressive masked generative Transformer, followed by prosody-aware acoustic reconstruction with pitch and energy modeling. Fine-tuned on <50 hours of Mandarin stuttered data, it claims competitive synthesis quality and controllability, outperforming prior methods, and that the generated data augments multiple ASR models to achieve SOTA CER of 4.19% on stuttered speech recognition while only slightly degrading fluent speech performance.
Significance. If the results hold with proper verification, the work addresses a genuine gap in low-resource stuttered speech synthesis and ASR augmentation for Mandarin. Strengths include the explicit use of stuttering event labels for controllability and the non-autoregressive token approach, which could enable scalable data generation where real stuttered corpora are scarce.
major comments (3)
- [Results section] Results section (and abstract): The central claim of SOTA CER 4.19% for Qwen3-ASR-0.6B after augmentation provides no baseline CER on the same test set, no absolute improvement magnitude, no test-set size, and no statistical significance or confidence intervals, leaving the generalization from synthesis to real ASR improvement unverified.
- [Experimental setup] Experimental setup: No ablation isolating the contribution of explicit stuttering event labels versus simply increasing data volume is reported, which is load-bearing for the controllability and augmentation claims.
- [Methods and results] Methods and results: The assumption that <50h fine-tuning produces sufficiently diverse, controllable, and artifact-free tokens for ASR improvement lacks quantitative metrics on token diversity, reconstruction error rates, or side-effect analysis on fluent speech beyond the qualitative 'slight degradation' statement.
minor comments (1)
- [Abstract] Abstract and introduction: Consider adding a brief statement of the exact Mandarin stuttered test corpus and its size to allow readers to contextualize the CER result.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to strengthen the presentation of results and experiments.
read point-by-point responses
-
Referee: [Results section] Results section (and abstract): The central claim of SOTA CER 4.19% for Qwen3-ASR-0.6B after augmentation provides no baseline CER on the same test set, no absolute improvement magnitude, no test-set size, and no statistical significance or confidence intervals, leaving the generalization from synthesis to real ASR improvement unverified.
Authors: We agree that these supporting details are required to fully substantiate the claim. In the revised manuscript we will add the baseline CER without augmentation on the identical test set, the absolute improvement value, the test-set size, and statistical significance or confidence intervals. revision: yes
-
Referee: [Experimental setup] Experimental setup: No ablation isolating the contribution of explicit stuttering event labels versus simply increasing data volume is reported, which is load-bearing for the controllability and augmentation claims.
Authors: The referee correctly notes the absence of this ablation. We will add an ablation study in the revision that directly compares the effect of explicit stuttering event labels against equivalent increases in data volume without label control. revision: yes
-
Referee: [Methods and results] Methods and results: The assumption that <50h fine-tuning produces sufficiently diverse, controllable, and artifact-free tokens for ASR improvement lacks quantitative metrics on token diversity, reconstruction error rates, or side-effect analysis on fluent speech beyond the qualitative 'slight degradation' statement.
Authors: We accept that additional quantitative evidence is needed. The revised version will report token diversity statistics, reconstruction error metrics, and a quantitative breakdown of effects on fluent-speech ASR performance rather than relying solely on the qualitative description. revision: yes
Circularity Check
No circularity; empirical pipeline with external validation
full rationale
The paper's core chain is a standard synthesis pipeline (text+labels → semantic tokens via masked Transformer → prosody-aware acoustic reconstruction) trained on <50h data and evaluated via downstream ASR CER on held-out real stuttered speech. No equation or result is shown to equal its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation. All reported gains (CER 4.19%, controllability, minimal fluent-speech degradation) are presented as measured outcomes against prior methods and baselines, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A non-autoregressive masked generative Transformer can effectively map text and stuttering event labels to semantic speech tokens
Reference graph
Works this paper leans on
-
[1]
Stuttering Foundation. 2020. Stuttering Facts and Information
2020
-
[2]
In: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI 2023), pp
Feng, L., Xiong, Z., Li, X., Fan, M.: CoPracTter: Toward integrating personalized practice scenarios, timely feedback and social support into an online support tool for coping with stuttering in China. In: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI 2023), pp. 1–15 (2023)
2023
-
[3]
(2024, June)
Mujtaba, D., Mahapatra, N., Arney, M., Yaruss, J., Gerlach-Houck, H., Herring, C., & Bin, J. (2024, June). Lost in transcription: Identifying and quantifying the accuracy biases of automatic speech recognition systems against disfluent speech. In Proceedings of the 2024 Conference of the North American Chapter of the Asso- ciation for Computational Lingui...
2024
-
[4]
E., & Yaruss, J
Tichenor, S. E., & Yaruss, J. S. (2021). Variability of stuttering: Behavior and impact. American Journal of Speech-Language Pathology, 30(1), 75-88
2021
-
[5]
L., Jiang, P
MacDonald, R. L., Jiang, P. P., Cattiau, J., Heywood, R., Cave, R., Seaver, K., ... & Tomanek, K. (2021, August). Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia. In Interspeech (Vol. 2021, pp. 4833- 4837)
2021
-
[6]
(2023, July)
Jiang, Z., Yang, Q., Zuo, J., Ye, Z., Huang, R., Ren, Y., & Zhao, Z. (2023, July). Fluentspeech: Stutter-oriented automatic speech editing with context-aware diffu- sion models. In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 11655-11671)
2023
-
[7]
arXiv preprint arXiv:2106.15561
Tan,X.,Qin,T.,Soong,F.,&Liu,T.Y.(2021).Asurveyonneuralspeechsynthesis. arXiv preprint arXiv:2106.15561
-
[8]
(2021, June)
Zheng, X., Liu, Y., Gunceler, D., & Willett, D. (2021, June). Using synthetic audio to improve the recognition of out-of-vocabulary words in end-to-end asr systems. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5674-5678). IEEE
2021
-
[9]
Zhang, X., Vallés-Pérez, I., Stolcke, A., Yu, C., Droppo, J., Shonibare, O., ... & Ravichandran, V. (2022). Stutter-tts: Controlled synthesis and improved recognition of stuttered speech. arXiv preprint arXiv:2211.09731
-
[10]
(2019, July)
Li, N., Liu, S., Liu, Y., Zhao, S., & Liu, M. (2019, July). Neural speech synthe- sis with transformer network. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01, pp. 6706-6713)
2019
-
[11]
Wang, Y., Zhan, H., Liu, L., Zeng, R., Guo, H., Zheng, J., ... & Wu, Z. (2025, May). Maskgct: Zero-shot text-to-speech with masked generative codec transformer. In International Conference on Learning Representations (Vol. 2025, pp. 47127-47150)
2025
-
[12]
(2024, May)
Zhang, X., Zhang, D., Li, S., Zhou, Y., & Qiu, X. (2024, May). Speechtokenizer: Unified speech tokenizer for speech language models. In International Conference on Learning Representations (Vol. 2024, pp. 31798-31818)
2024
-
[13]
W., Watanabe, S., & Rudnicky, A
Chen, L. W., Watanabe, S., & Rudnicky, A. (2023, June). A unified one-shot prosody and speaker conversion system with self-supervised discrete speech units. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE
2023
-
[14]
Kong, J., Kim, J., & Bae, J. (2020). Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural information process- ing systems, 33, 17022-17033
2020
-
[15]
N., Adi, Y., Polyak, A., Bolte, B.,
Lakhotia, K., Kharitonov, E., Hsu, W. N., Adi, Y., Polyak, A., Bolte, B., ... & Dupoux, E. (2021). On generative spoken language modeling from raw audio. Trans- actions of the Association for Computational Linguistics, 9, 1336-1354
2021
-
[16]
(2022, December)
Zhang, Z., Zhou, L., Ao, J., Liu, S., Dai, L., Li, J., & Wei, F. (2022, December). Speechut: Bridging speech and text with hidden-unit for encoder-decoder based speech-text pre-training. In Proceedings of the 2022 Conference on Empirical Meth- ods in Natural Language Processing (pp. 1663-1676)
2022
-
[17]
Lin, G. T., Chuang, Y. S., Chung, H. L., Yang, S. W., Chen, H. J., Dong, S., ... & Lee, L. S. (2022). DUAL: Discrete spoken unit adaptive learning for textless spoken question answering. arXiv preprint arXiv:2203.04911
-
[18]
Hsu,W.N.,Bolte,B.,Tsai,Y.H.H.,Lakhotia,K.,Salakhutdinov,R.,&Mohamed, A. (2021). Hubert: Self-supervised speech representation learning by masked pre- diction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29, 3451-3460
2021
-
[19]
Défossez, A., Copet, J., Synnaeve, G., & Adi, Y. (2022). High fidelity neural audio compression. arXiv preprint arXiv:2210.13438. 14 Yao Lu
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
- [22]
-
[23]
K., Gopal, V., & Cutler, R
Reddy, C. K., Gopal, V., & Cutler, R. (2021, June). DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP) (pp. 6493-6497). IEEE
2021
-
[24]
(2021, July)
Kim, J., Kong, J., & Son, J. (2021, July). Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In International conference on machine learning (pp. 5530-5540). PMLR
2021
- [25]
-
[26]
Shi, X., Wang, X., Guo, Z., Wang, Y., Zhang, P., Zhang, X., ... & Lin, J. (2026). Qwen3-ASR Technical Report. arXiv preprint arXiv:2601.21337
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural informa- tion processing systems, 33, 12449-12460
2020
-
[28]
W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023, July). Robust speech recognition via large-scale weak supervision. In Inter- national conference on machine learning (pp. 28492-28518). PMLR
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.