Efficient Domain Decomposition for the Helmholtz Equation on GPUs
Pith reviewed 2026-06-26 12:59 UTC · model grok-4.3
The pith
Domain decomposition assigns each Helmholtz subdomain to a GPU thread block solved by WaveHoltz for 2x-25x speedup over MINRES on A100.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
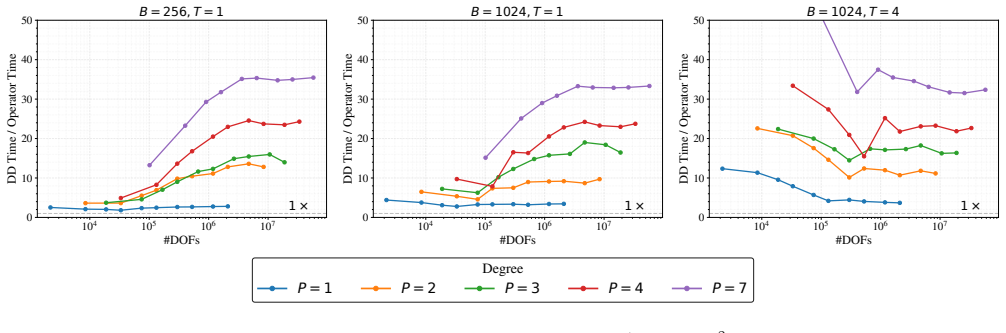
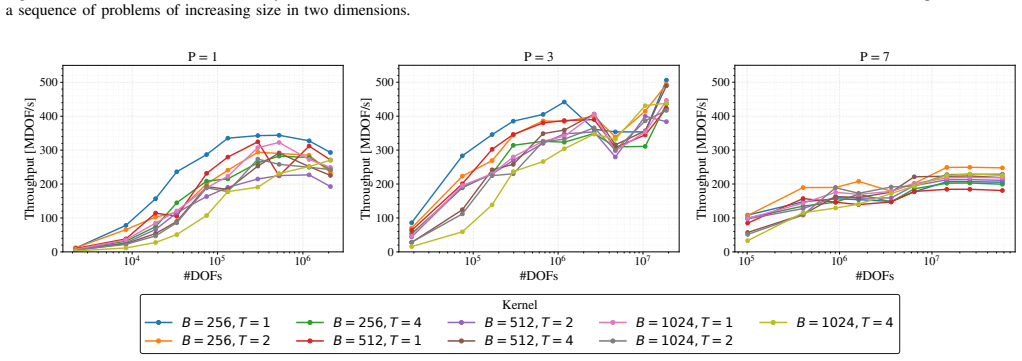
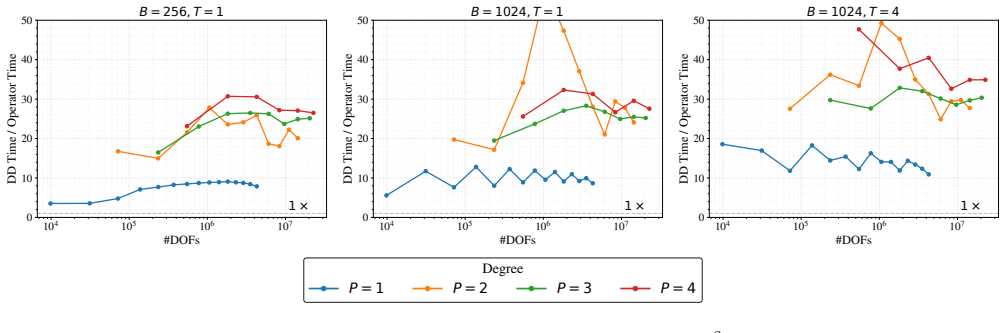
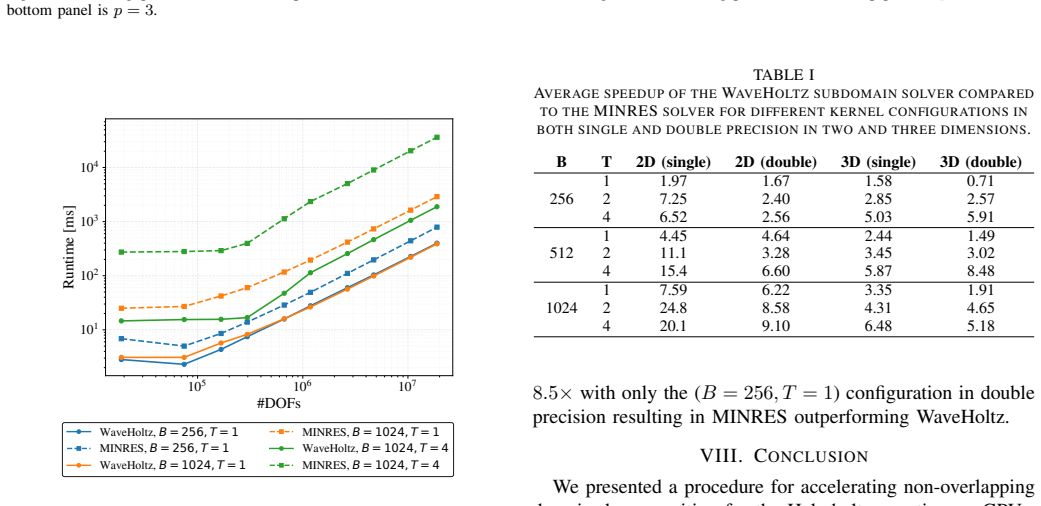
A block-level domain decomposition scheme that maps every subdomain to one GPU thread block and solves it with the WaveHoltz fixed-point iteration allows all subdomain solves to execute concurrently in a single kernel launch, achieving 2x-25x speedup over MINRES on A100 GPUs with the advantage increasing with subdomain size and an additional 2x-10x from single-precision arithmetic that MINRES cannot exploit because of lost Krylov-vector orthogonality.
What carries the argument
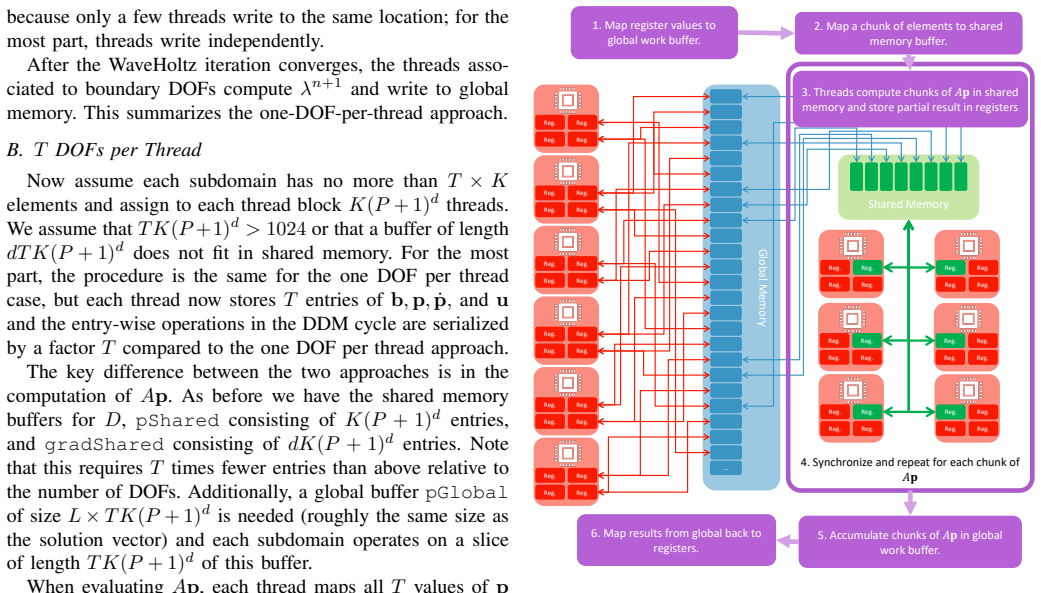
Block-level domain decomposition scheme that assigns each subdomain to one thread block and solves it with the WaveHoltz fixed-point iteration inside a single kernel launch.
If this is right
- The speedup margin over MINRES widens as subdomain size increases.
- Single-precision execution supplies additional acceleration unavailable to MINRES because of orthogonality loss under reduced precision.
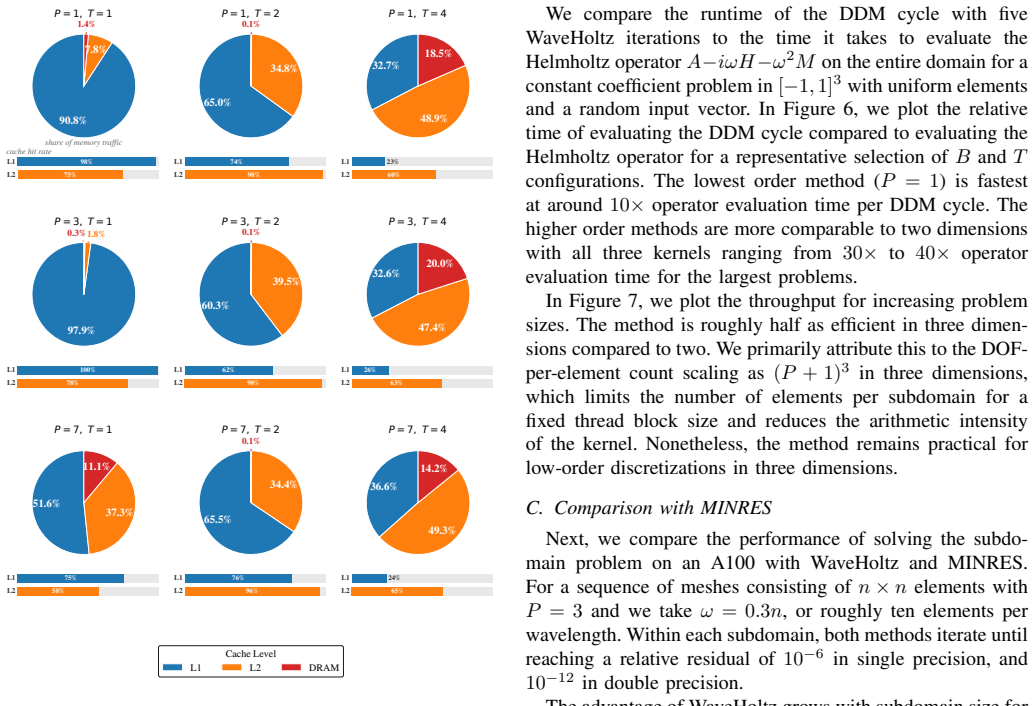
- Subdomain data remains largely resident in L1 and L2 cache through shared-memory and register-level operations.
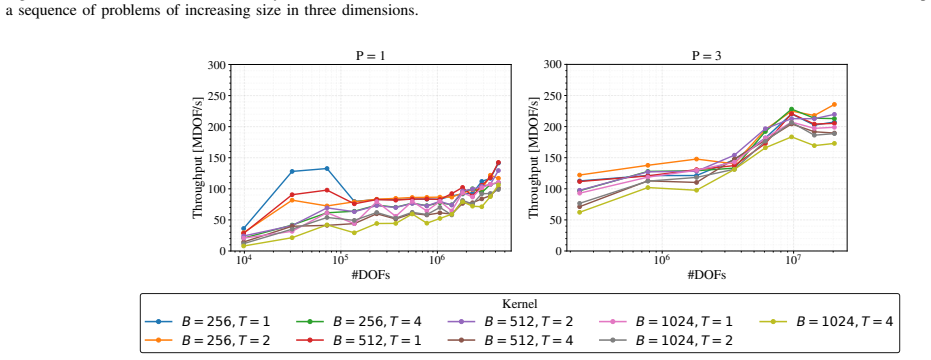
- Two threading strategies (one degree of freedom per thread or multiple) cover both small and large subdomains.
Where Pith is reading between the lines
- The same block-level mapping and cache-resident design could be tested on other indefinite systems such as Maxwell or elasticity equations on GPUs.
- Energy use per solve may drop because global memory traffic is replaced by on-chip operations.
- The absence of reductions inside the kernel suggests the method could scale to multi-GPU nodes with fewer inter-device synchronizations.
Load-bearing premise
WaveHoltz converges in a small fixed number of iterations for the chosen subdomains while single-precision arithmetic still delivers sufficient accuracy for the target applications.
What would settle it
A measurement showing that the number of WaveHoltz iterations required grows steadily with subdomain size or that single-precision results deviate from double-precision reference solutions beyond acceptable application error thresholds.
Figures

read the original abstract
The Helmholtz equation governs wave propagation in acoustics, electromagnetics, and seismology, but its indefinite nature makes it difficult to solve with iterative methods. Domain decomposition methods are a natural fit for massively parallel architectures, yet mapping efficient Helmholtz solvers onto modern GPUs remains a challenge. We address both with two key contributions: (1) a block-level domain decomposition scheme, in which each subdomain is assigned to a single thread block and all solves run concurrently in a single kernel launch, and (2) WaveHoltz as the subdomain solver. WaveHoltz is a fixed-point iteration that is uniquely well-suited to the GPU execution model due to its minimal memory footprint and no reduction operations. Together, these eliminate device-level synchronizations and replace global memory traffic with shared memory and register-level operations, keeping subdomain data largely resident in L1 and L2 cache. We explore two threading strategies: one degree of freedom per thread for small subdomains, and multiple degrees of freedom per thread for larger ones. Benchmarks of our CUDA based implementation on a NVIDIA A100 show that WaveHoltz achieves 2x-25x speedup over MINRES, with the advantage growing with subdomain size. Crucially, evaluating the subdomain solver in single rather than double precision yields an additional 2x-10x speedup--a benefit largely unattainable by MINRES due to loss of Krylov vector orthogonality under reduced precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a block-level domain decomposition method for the Helmholtz equation on GPUs, assigning each subdomain to one thread block with all solves in a single kernel launch, and using WaveHoltz fixed-point iteration as the subdomain solver. It reports 2x-25x speedups over MINRES on A100 GPUs (advantage growing with subdomain size) plus 2x-10x from single precision, enabled by minimal memory footprint, no reductions, and avoidance of device synchronizations.
Significance. If the iteration counts remain small and bounded and single-precision accuracy holds, the work would provide a practical GPU-native solver for indefinite Helmholtz problems in acoustics and seismology by keeping data in cache and eliminating global synchronizations. The architecture-specific design choices are a strength.
major comments (2)
- [Abstract] Abstract: the headline speedups (2x-25x over MINRES, growing with subdomain size) rest on WaveHoltz requiring only a small fixed number of iterations. No data, plots, or tables reporting observed iteration counts versus subdomain size, wave number k, or mesh resolution are referenced, so it is impossible to confirm the contraction rate remains independent of these parameters as required for the claimed scaling.
- [Abstract] Abstract (single-precision paragraph): the additional 2x-10x speedup from single precision is asserted to be unattainable by MINRES due to orthogonality loss, yet no error analysis, residual norms, or accuracy verification against double-precision reference solutions is supplied. For an indefinite operator this is load-bearing for the single-precision claim.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the test problems (domain, boundary conditions, range of k) used to obtain the reported timings.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the two major comments point by point below. We agree that the manuscript would benefit from explicit supporting data on iteration counts and single-precision accuracy and will incorporate these elements in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline speedups (2x-25x over MINRES, growing with subdomain size) rest on WaveHoltz requiring only a small fixed number of iterations. No data, plots, or tables reporting observed iteration counts versus subdomain size, wave number k, or mesh resolution are referenced, so it is impossible to confirm the contraction rate remains independent of these parameters as required for the claimed scaling.
Authors: We agree that the abstract and main text do not reference explicit iteration-count data versus subdomain size, k, or mesh resolution. Although the paper emphasizes the fixed-point character of WaveHoltz, a dedicated table or plot confirming bounded iterations is absent. In the revised manuscript we will add a new table (or figure) in Section 4 reporting observed WaveHoltz iteration counts across the tested range of subdomain sizes, wave numbers, and resolutions to substantiate that the count remains small and largely independent of these parameters. revision: yes
-
Referee: [Abstract] Abstract (single-precision paragraph): the additional 2x-10x speedup from single precision is asserted to be unattainable by MINRES due to orthogonality loss, yet no error analysis, residual norms, or accuracy verification against double-precision reference solutions is supplied. For an indefinite operator this is load-bearing for the single-precision claim.
Authors: The manuscript states the single-precision advantage but does not supply direct accuracy verification or residual comparisons. We will add to the revision (likely as a short subsection or appendix) a verification study that reports relative solution errors and residual norms for single-precision WaveHoltz against double-precision reference solutions, confirming that accuracy remains acceptable for the acoustics and seismology applications targeted. revision: yes
Circularity Check
No circularity; claims rest on empirical benchmarks with no self-referential derivation
full rationale
The manuscript describes a block-level domain decomposition scheme paired with the WaveHoltz fixed-point iteration as subdomain solver, implemented in CUDA for A100 GPUs. All reported results are wall-clock timings and speedups (2x-25x over MINRES, plus single-precision gains) obtained from direct execution on test problems. No equations, uniqueness theorems, or parameter-fitting steps are invoked whose outputs are then relabeled as predictions; the suitability arguments cite only the algorithmic properties of fixed-point iteration (low memory, no reductions) that are independent of the measured timings. No self-citation chain or ansatz smuggling appears in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Why it is difficult to solve Helmholtz problems with classical iterative methods,
O. G. Ernst and M. J. Gander, “Why it is difficult to solve Helmholtz problems with classical iterative methods,” eng, inNumerical Analysis of Multiscale Problems, ser. Lecture Notes in Computational Science and Engineering, Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 325–363,ISBN: 3642220606
2011
-
[2]
Advances in iterative methods and pre- conditioners for the Helmholtz equation,
Y . A. Erlangga, “Advances in iterative methods and pre- conditioners for the Helmholtz equation,” eng,Archives of computational methods in engineering, vol. 15, no. 1, pp. 37–66, 2008,ISSN: 1134-3060
2008
-
[3]
On controllability methods for the Helmholtz equation,
M. Grote and J. Tang, “On controllability methods for the Helmholtz equation,”Journal of Computational and Applied Mathematics, vol. 358, pp. 306–326, 2019
2019
-
[4]
Parallel controllability methods for the Helmholtz equation,
M. J. Grote, F. Nataf, J. H. Tang, and P.-H. Tournier, “Parallel controllability methods for the Helmholtz equation,”Computer Methods in Applied Mechanics and Engineering, vol. 362, p. 112 846, 2020
2020
-
[5]
Waveholtz: It- erative solution of the Helmholtz equation via the wave equation,
D. Appel ¨o, F. Garcia, and O. Runborg, “Waveholtz: It- erative solution of the Helmholtz equation via the wave equation,” eng,SIAM journal on scientific computing, vol. 42, no. 4, A1950–A1983, 2020,ISSN: 1064-8275
2020
-
[6]
Convergence of the semi-discrete waveholtz iteration,
A. Rotem, O. Runborg, and D. Appel ¨o, “Convergence of the semi-discrete waveholtz iteration,”Journal of Computational Physics, p. 114 882, 2026,ISSN: 0021- 9991.DOI: https://doi.org/10.1016/j.jcp.2026.114882 [Online]. Available: https : / / www. sciencedirect . com / science/article/pii/S0021999126002329
-
[7]
An optimal O(N) Helmholtz solver for complex geometry using WaveHoltz and overset grids,
D. Appel ¨o, J. W. Banks, W. D. Henshaw, and D. W. Schwendeman, “An optimal O(N) Helmholtz solver for complex geometry using WaveHoltz and overset grids,” ArXiv, vol. abs/2504.03074, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:277596478
arXiv 2025
-
[8]
M ´ethodes de d ´ecomposition de demains pour les probl `ems de propagation d‘ondes en r ´egime harmonique,
B. Depr ´es, “M ´ethodes de d ´ecomposition de demains pour les probl `ems de propagation d‘ondes en r ´egime harmonique,”PhD thesis, 1991
1991
-
[9]
L-sweeps: A scalable, parallel precondi- tioner for the high-frequency helmholtz equation,
M. Taus, L. Zepeda-N ´u˜nez, R. J. Hewett, and L. Demanet, “L-sweeps: A scalable, parallel precondi- tioner for the high-frequency helmholtz equation,”Jour- nal of Computational Physics, vol. 420, p. 109 706, 2020,ISSN: 0021-9991.DOI: https : / / doi . org / 10 . 1016 / j . jcp . 2020 . 109706 [Online]. Available: https : / / www . sciencedirect . com / s...
2020
-
[10]
A rapidly converging domain decom- position method for the helmholtz equation,
C. C. Stolk, “A rapidly converging domain decom- position method for the helmholtz equation,”Jour- nal of Computational Physics, vol. 241, pp. 240–252, 2013,ISSN: 0021-9991.DOI: https : / / doi . org / 10 . 1016 / j . jcp . 2013 . 01 . 039 [Online]. Available: https : / / www . sciencedirect . com / science / article / pii / S0021999113000922
2013
-
[11]
A non-overlapping domain decomposition method with perfectly matched layer transmission conditions for the helmholtz equation,
A. Royer, C. Geuzaine, E. B ´echet, and A. Modave, “A non-overlapping domain decomposition method with perfectly matched layer transmission conditions for the helmholtz equation,”Computer Methods in Ap- plied Mechanics and Engineering, vol. 395, p. 115 006, 2022,ISSN: 0045-7825.DOI: https : / / doi . org / 10 . 1016 / j . cma . 2022 . 115006 [Online]. Ava...
2022
-
[12]
M. J. Gander and H. Zhang, “A class of iterative solvers for the helmholtz equation: Factorizations, sweeping preconditioners, source transfer, single layer poten- tials, polarized traces, and optimized schwarz methods,” SIAM Review, vol. 61, no. 1, pp. 3–76, 2019.DOI: 10. 1137 / 16M109781X eprint: https : / / doi . org / 10 . 1137 / 16M109781X. [Online]....
2019
-
[13]
Absorbing boundary conditions and per- fectly matched layers in wave propagation problems,
F. Nataf, “Absorbing boundary conditions and per- fectly matched layers in wave propagation problems,” inDirect and Inverse Problems in Wave Propagation and Applications, I. Graham, U. Langer, J. Melenk, and M. Sini, Eds. Berlin, Boston: De Gruyter, 2013, pp. 219–232,ISBN: 9783110282283.DOI: doi:10.1515/ 9783110282283 . 219 [Online]. Available: https : / ...
-
[14]
Nu- merical experiments on a domain decomposition algo- rithm for nonlinear elliptic boundary value problems,
T. Hagstrom, R. Tewarson, and A. Jazcilevich, “Nu- merical experiments on a domain decomposition algo- rithm for nonlinear elliptic boundary value problems,” Applied Mathematics Letters, vol. 1, no. 3, pp. 299–302, 1988,ISSN: 0893-9659.DOI: https : / / doi . org / 10 . 1016 / 0893 - 9659(88 ) 90097 - 3 [Online]. Available: https : / / www. sciencedirect ....
1988
-
[15]
Optimized schwarz methods without overlap for the helmholtz equation,
M. J. Gander, F. Magoul `es, and F. Nataf, “Optimized schwarz methods without overlap for the helmholtz equation,”SIAM Journal on Scientific Computing, vol. 24, no. 1, pp. 38–60, 2002.DOI: 10 . 1137 / S1064827501387012 eprint: https://doi.org/10.1137/ S1064827501387012. [Online]. Available: https://doi. org/10.1137/S1064827501387012
-
[16]
An optimized order 2 (oo2) method for the helmholtz equation,
P. Chevalier and F. Nataf, “An optimized order 2 (oo2) method for the helmholtz equation,”Comptes Rendus de l’Acad´emie des Sciences - Series I - Mathematics, vol. 326, no. 6, pp. 769–774, 1998,ISSN: 0764-4442. DOI: https://doi.org/10.1016/S0764-4442(98)80047-5 [Online]. Available: https : / / www. sciencedirect . com / science/article/pii/S0764444298800475
-
[17]
A quasi- optimal non-overlapping domain decomposition algo- rithm for the helmholtz equation,
Y . Boubendir, X. Antoine, and C. Geuzaine, “A quasi- optimal non-overlapping domain decomposition algo- rithm for the helmholtz equation,”Journal of Computa- tional Physics, vol. 231, no. 2, pp. 262–280, 2012,ISSN: 0021-9991.DOI: https://doi.org/10.1016/j.jcp.2011.08. 007 [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0021999111004797
-
[18]
Gmres with deflated restarting,
R. B. Morgan, “Gmres with deflated restarting,”SIAM Journal on Scientific Computing, vol. 24, no. 1, pp. 20– 37, 2002.DOI: 10.1137/S1064827599364659
-
[19]
Recycling krylov subspaces for se- quences of linear systems,
M. L. Parks, E. de Sturler, G. Mackey, D. D. Johnson, and S. Maiti, “Recycling krylov subspaces for se- quences of linear systems,”SIAM Journal on Scientific Computing, vol. 28, no. 5, pp. 1651–1674, 2006.DOI: 10.1137/040607277
-
[20]
Block iterative methods and recycling for improved scalability of linear solvers,
P. Jolivet and P.-H. Tournier, “Block iterative methods and recycling for improved scalability of linear solvers,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’16, Salt Lake City, Utah: IEEE Press, 2016,ISBN: 9781467388153
2016
-
[21]
A coarse space for heterogeneous helmholtz problems based on the dirichlet-to-neumann operator,
L. Conen, V . Dolean, R. Krause, and F. Nataf, “A coarse space for heterogeneous helmholtz problems based on the dirichlet-to-neumann operator,”Journal of Computational and Applied Mathematics, vol. 271, pp. 83–99, 2014,ISSN: 0377-0427.DOI: https :/ / doi . org/10.1016/j.cam.2014.03.031 [Online]. Available: https : / / www. sciencedirect . com / science /...
-
[22]
Iterative solution applied to the helmholtz equation: Complex deflation on unstructured grids,
R. Aubry, S. Dey, and R. L ¨ohner, “Iterative solution applied to the helmholtz equation: Complex deflation on unstructured grids,”Computer Methods in Applied Mechanics and Engineering, vol. 241-244, pp. 155– 171, 2012,ISSN: 0045-7825.DOI: https : / / doi . org / 10 . 1016 / j . cma . 2012 . 06 . 007 [Online]. Available: https : / / www. sciencedirect . c...
2012
-
[23]
J.-H. Kimn and M. Sarkis, “Restricted overlapping balancing domain decomposition methods and restricted coarse problems for the helmholtz problem,”Com- puter Methods in Applied Mechanics and Engineering, vol. 196, no. 8, pp. 1507–1514, 2007, Domain Decom- position Methods: recent advances and new challenges in engineering,ISSN: 0045-7825.DOI: https : / / ...
-
[24]
Scalable domain decomposition preconditioners for heterogeneous elliptic problems,
P. Jolivet, F. Hecht, F. Nataf, and C. Prud’homme, “Scalable domain decomposition preconditioners for heterogeneous elliptic problems,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, ser. SC ’13, Denver, Colorado: Association for Computing Ma- chinery, 2013,ISBN: 9781450323789.DOI: 10 . 1145 ...
-
[25]
S. G. Johnson,Notes on perfectly matched layers (pmls), 2021. arXiv: 2108.05348[cs.CE]
arXiv 2021
-
[26]
A perfectly matched layer for the absorption of electromagnetic waves,
J.-P. Berenger, “A perfectly matched layer for the absorption of electromagnetic waves,”Journal of Com- putational Physics, vol. 114, no. 2, pp. 185–200, 1994,ISSN: 0021-9991.DOI: https : / / doi . org / 10 . 1006 / jcph . 1994 . 1159 [Online]. Available: https : / / www . sciencedirect . com / science / article / pii / S0021999184711594
1994
-
[27]
Chapter 2: Opti- mized schwarz methods,
V . Dolean, P. Jolivet, and F. Nataf, “Chapter 2: Opti- mized schwarz methods,” inAn Introduction to Domain Decomposition Methods. 2015, pp. 35–75.DOI: 10 . 1137/1.9781611974065.ch2 eprint: https://epubs.siam. org/doi/pdf/10.1137/1.9781611974065.ch2. [Online]. Available: https://epubs.siam.org/doi/abs/10.1137/1. 9781611974065.ch2
-
[28]
D. A. Kopriva,Implementing Spectral Methods for Partial Differential Equations: Algorithms for Scien- tists and Engineers(Scientific Computation). Springer Netherlands, 2009
2009
-
[29]
Matrix-free finite-element computations on graphics processors with adaptively refined unstruc- tured meshes,
K. Ljungkvist, “Matrix-free finite-element computations on graphics processors with adaptively refined unstruc- tured meshes,” inProceedings of the 25th High Perfor- mance Computing Symposium, ser. HPC ’17, Virginia Beach, Virginia: Society for Computer Simulation In- ternational, 2017,ISBN: 9781510838222
2017
-
[30]
Gpu algorithms for efficient exascale discretizations,
A. Abdelfattah et al., “Gpu algorithms for efficient exascale discretizations,”Parallel Computing, vol. 108, p. 102 841, 2021,ISSN: 0167-8191.DOI: https://doi. org/10.1016/j.parco.2021.102841 [Online]. Available: https : / / www. sciencedirect . com / science / article / pii / S0167819121000879
-
[31]
High performance sparse mul- tifrontal solvers on modern gpus,
P. Ghysels and R. Synk, “High performance sparse mul- tifrontal solvers on modern gpus,”Parallel Computing, vol. 110, p. 102 897, 2022,ISSN: 0167-8191.DOI: https: / / doi . org / 10 . 1016 / j . parco . 2022 . 102897 [Online]. Available: https : / / www . sciencedirect . com / science / article/pii/S0167819122000059
2022
-
[32]
NVIDIA,NVIDIA cuDSS (preview): GPU-accelerated direct sparse solver, https://developer.nvidia.com/cudss, Accessed: 2026-03-27, 2025
2026
-
[33]
6. krylov subspace methods, part i,
Y . Saad, “6. krylov subspace methods, part i,” in Iterative Methods for Sparse Linear Systems. 2003, pp. 151–216.DOI: 10 . 1137 / 1 . 9780898718003 . ch6 eprint: https : / / epubs . siam . org / doi / pdf / 10 . 1137 / 1 . 9780898718003.ch6. [Online]. Available: https://epubs. siam.org/doi/abs/10.1137/1.9780898718003.ch6
-
[34]
Demystifying the nvidia ampere architec- ture through microbenchmarking and instruction-level analysis,
H. Abdelkhalik, Y . Arafa, N. Santhi, and A.-H. A. Badawy, “Demystifying the nvidia ampere architec- ture through microbenchmarking and instruction-level analysis,”2022 IEEE High Performance Extreme Com- puting Conference (HPEC), pp. 1–8, 2022. [Online]. Available: https : // api . semanticscholar. org /CorpusID : 251765382
2022
-
[35]
M. Kawai and K. Nakajima, “Low/adaptive precision computation in preconditioned iterative solvers for ill- conditioned problems,” inInternational Conference on High Performance Computing in Asia-Pacific Region, ser. HPCAsia ’22, Virtual Event, Japan: Association for Computing Machinery, 2022, pp. 30–40,ISBN: 9781450384988.DOI: 10 . 1145 / 3492805 . 349281...
-
[36]
Mixed precision block- jacobi preconditioner: Algorithms, performance evalua- tion and feature analysis,
N. Tian, S. Huang, and X. Xu, “Mixed precision block- jacobi preconditioner: Algorithms, performance evalua- tion and feature analysis,”CCF Transactions on High Performance Computing, vol. 7, no. 2, pp. 114–128, 2025
2025
-
[37]
Y . Guo, E. de Sturler, and T. Warburton,An adaptive mixed precision and dynamically scaled preconditioned conjugate gradient algorithm, 2025. arXiv: 2505.04155 [math.NA]. [Online]. Available: https://arxiv.org/abs/ 2505.04155
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.