Bridging the Age Gap: Towards Detecting Neural Audio Codec Synthesized Elderly Speech Deepfake
Pith reviewed 2026-06-26 12:49 UTC · model grok-4.3
The pith
Fusing LanguageBind and ImageBind via BONSAI detects synthesized elderly speech deepfakes at 1.66 percent average EER.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that multimodal foundation models such as LanguageBind and ImageBind are more effective for detecting neural audio codec synthesized elderly speech deepfakes due to their exposure to elderly content during cross-modal pretraining, and that fusing them through the BONSAI framework with Jensen-Shannon Divergence achieves an average EER of 1.66 percent, outperforming individual foundation models and competitive state-of-the-art baselines to set a new benchmark for the ECFD task.
What carries the argument
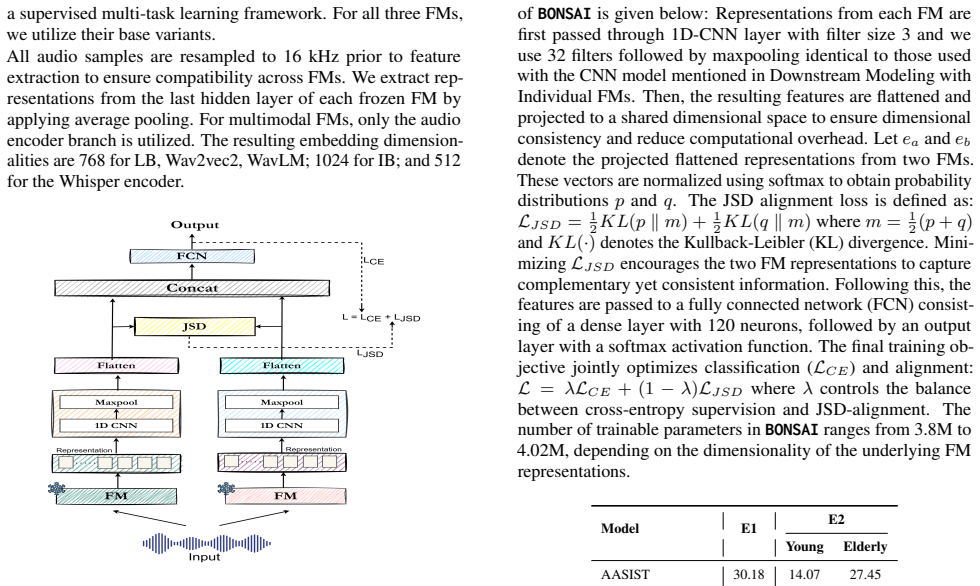
BONSAI framework, which fuses outputs from multimodal foundation models using Jensen-Shannon Divergence to produce a single detection score for elderly codec fakes.
If this is right
- Standard codec fake detectors require age-specific adaptation or retraining to handle elderly voices reliably.
- Cross-modal pretraining that includes elderly audio-visual pairs improves downstream detection of demographic subgroups.
- Jensen-Shannon Divergence fusion of multiple foundation models provides a practical route to lower error rates on this task.
- The released ECF dataset in English and Chinese enables systematic study of age-related vulnerabilities in audio deepfake detection.
Where Pith is reading between the lines
- The same fusion approach could be tested on other demographic gaps such as child or accented speech to check broader applicability.
- If pretraining exposure drives the gain, periodically refreshing foundation models with newer elderly speech data might produce further error reductions.
- BONSAI could be evaluated on live elderly voice authentication systems to measure real-world false acceptance rates.
Load-bearing premise
The superior performance of LanguageBind and ImageBind on elderly speech arises specifically from their exposure to elderly content during cross-modal pretraining.
What would settle it
An experiment that measures LanguageBind and ImageBind performance on elderly codec fakes after removing or masking elderly content from their pretraining data and finds no performance gap relative to other models would falsify the core hypothesis.
Figures

read the original abstract
In this study, we introduce the Elderly CodecFake Detection (ECFD) task and release the Elderly-CodecFake (ECF) dataset in English and Chinese. We show that state-of-the-art CF detectors trained on previous benchmark CF datasets generalize poorly to elderly speech, revealing a critical vulnerability. We further hypothesize and demonstrate that multimodal foundation models (FMs) such as LanguageBind (LB) and ImageBind (IB) are more effective for ECFD due to their exposure to elderly content during cross-modal pretraining. Motivated by prior evidence that fusion of FMs enhances downstream performance, we explore fusion of FMs for ECFD. To this end, we propose BONSAI, a novel framework that employs Jensen-Shannon Divergence as the fusion mechanism. BONSAI with the fusion of LB and IB achieves an average EER (%) of 1.66 and outperforms individual FMs as well as competitive SOTA baselines, establishing a new benchmark for the ECFD task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Elderly CodecFake Detection (ECFD) task and releases the Elderly-CodecFake (ECF) dataset in English and Chinese. It reports that state-of-the-art codec-fake detectors trained on prior benchmarks generalize poorly to elderly speech. The authors hypothesize that multimodal foundation models (LanguageBind, ImageBind) outperform prior detectors specifically because of elderly content exposure during cross-modal pretraining, and propose BONSAI, a fusion framework using Jensen-Shannon divergence, which achieves 1.66% average EER and sets a new benchmark.
Significance. If the empirical results prove robust and reproducible, the work identifies a genuine generalization gap in current deepfake detection for elderly speech and supplies a new public dataset, both of which are valuable contributions. The fusion mechanism itself may be of broader interest, but the causal attribution of gains to elderly pretraining exposure is not yet isolated.
major comments (2)
- [Abstract] Abstract: The central explanatory claim—that LB and IB outperform prior detectors 'due to their exposure to elderly content during cross-modal pretraining'—is not supported by any isolating experiment. No ablation removes elderly examples from pretraining, no comparison is made to otherwise-matched multimodal models lacking such exposure, and no representation probing for age-related features is reported. Consequently the reported 1.66% EER cannot be attributed to the hypothesized factor rather than generic multimodal fusion or the JS-divergence mechanism.
- [Abstract] Abstract: No information is supplied on ECF dataset construction—elderly speech sources, synthesis pipelines, speaker demographics, train/test splits, or language-specific balancing. Without these details the generalization claims and the numerical benchmark cannot be verified or reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of our hypotheses and improve reproducibility. We respond to each major comment below and will incorporate revisions in the next manuscript version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central explanatory claim—that LB and IB outperform prior detectors 'due to their exposure to elderly content during cross-modal pretraining'—is not supported by any isolating experiment. No ablation removes elderly examples from pretraining, no comparison is made to otherwise-matched multimodal models lacking such exposure, and no representation probing for age-related features is reported. Consequently the reported 1.66% EER cannot be attributed to the hypothesized factor rather than generic multimodal fusion or the JS-divergence mechanism.
Authors: We agree that the manuscript does not contain isolating experiments (e.g., ablating elderly data from pretraining or probing representations) that would causally link performance gains exclusively to elderly content exposure. The original text presents this as a hypothesis motivated by known pretraining characteristics of LB/IB and the observed generalization gap to elderly speech. In revision we will rephrase the abstract and relevant sections to describe the advantage as a plausible hypothesis supported by indirect evidence, while explicitly noting that gains could also arise from multimodal fusion or the JS-divergence mechanism. Performing the suggested controlled ablations is not feasible without access to the original pretraining corpora. revision: yes
-
Referee: [Abstract] Abstract: No information is supplied on ECF dataset construction—elderly speech sources, synthesis pipelines, speaker demographics, train/test splits, or language-specific balancing. Without these details the generalization claims and the numerical benchmark cannot be verified or reproduced.
Authors: The full manuscript (Section 3) provides the requested details on elderly speech sources, codec synthesis pipelines, speaker demographics (age 60+, gender balance), speaker-disjoint train/test splits, and language balancing for English and Chinese. To improve accessibility and address the referee's concern directly, we will add a concise summary of dataset construction and key statistics to the abstract in the revised version. revision: yes
Circularity Check
No circularity: empirical measurements on released dataset with no derivations or self-referential reductions
full rationale
The paper introduces an ECFD task and ECF dataset, reports generalization failure of prior detectors, hypothesizes superior performance of LB/IB due to pretraining exposure, and presents BONSAI fusion results (EER 1.66) as direct experimental outcomes. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. The central performance claim is a measurement on held-out data rather than a quantity forced by construction from inputs. The explanatory hypothesis about elderly content exposure is not isolated experimentally, but this is a limitation of evidence strength, not a circular reduction of the reported result to its own definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction In recent years, the boundary between genuine and speech deep- fakes has become increasingly blurred. Current text-to-speech (TTS) and voice-conversion (VC) models can generate speech utterances in nearly human-level realism. While these capabil- ities support valuable applications in assistive communication, human–computer interaction, and e...
Pith/arXiv arXiv 2026
-
[2]
All data are obtained from publicly available corpora
Elderly Codecfake Dataset This section first describes the sources of real elderly speech data, followed by an overview of the NACs employed in this study. All data are obtained from publicly available corpora. Finally, we detail the pipeline used to generate ECF dataset. Real Elderly Speech Source:SeniorTalk(E1) [ 31]: It is a Mandarin conversational spe...
-
[3]
[ 21], one of the foundational CF detection work
and Lu et al. [ 21], one of the foundational CF detection work. The procedure converts real elderly speech into NAC- generated counterparts using multiple NACs that constitute the core of modern ALM systems. We start from publicly available elderly speech datasets described above, where each original recording is treated as a real reference sample. For cr...
-
[4]
We then detail the proposed framework,BONSAI
Methodology This section presents the FMs employed in our study, followed by the downstream modeling approaches. We then detail the proposed framework,BONSAI. 3.1. Foundation Models The FMs considered are SOTA in their respective benchmarks. Mutlimodal FMs: We select LanguageBind (LB) [ 40] and ImageBind (IB) [ 41] as multimodal FMs. IB maps diverse modal...
-
[5]
Experiments 4.1. Training Details We train the models by combining the training sets from Se- niorTalk and TIS, while validation and testing are performed separately on the respective validation and test splits of each individual dataset. All models are trained for 20 epochs using a learning rate of 1e-3 and a batch size of 32. We employ the Adam optimize...
-
[6]
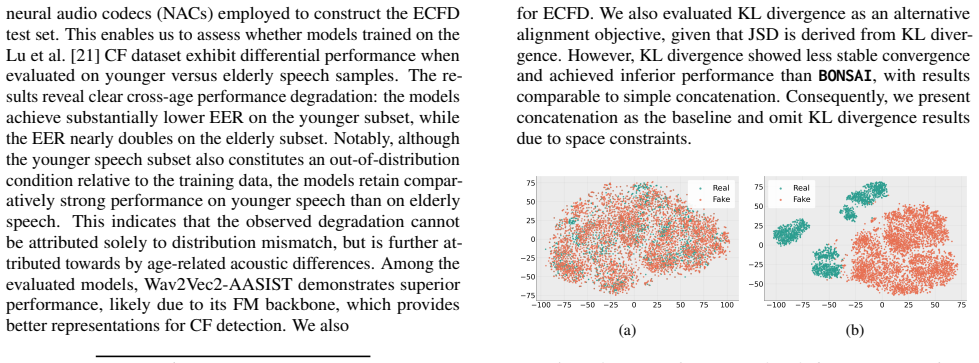
Our analysis demon- strated that existing SOTA CF detection models trained on prior benchmark datasets generalize poorly to elderly speech, reveal- ing a critical robustness gap
Conclusion In this work, we introduced the ECFD task and the ECF dataset comprising English and Chinese speech. Our analysis demon- strated that existing SOTA CF detection models trained on prior benchmark datasets generalize poorly to elderly speech, reveal- ing a critical robustness gap. Furthermore, we showed that multimodal FMs, such as LB and IB, pro...
-
[7]
Acknowledgement This work was supported by National Science and Technology Council (NSTC), Taiwan (grant#: 115-2634-F-002-012)
-
[8]
These tools did not contribute to the development of scientific concepts, data analysis, generation of results, or interpretation of findings
Generative AI Use Disclosure AI Assistants were utilized exclusively to enhance grammatical accuracy, clarity, and the overall readability of the manuscript. These tools did not contribute to the development of scientific concepts, data analysis, generation of results, or interpretation of findings. The authors assume full responsibility for the accuracy ...
-
[9]
Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,
Z. Wu, T. Kinnunen, N. Evans, J. Yamagishi, C. Hanilçi, M. Sahidullah, and A. Sizov, “Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,” in INTERSPEECH 2015 16th Annual Conference of the International Speech Communication Association. International Speech Com- munication Association, 2015, pp. 2037–2041
2015
-
[10]
The asvspoof 2017 challenge: As- sessing the limits of replay spoofing attack detection,
T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, and K. A. Lee, “The asvspoof 2017 challenge: As- sessing the limits of replay spoofing attack detection,” 2017
2017
-
[11]
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wang, J. Yamagishi, M. Todisco, H. Delgado, A. Nautsch, N. Evans, M. Sahidullah, V . Vestman, T. Kinnunen, K. A. Leeet al., “Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,”Computer Speech & Language, vol. 64, p. 101114, 2020
2019
-
[12]
Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kin- nunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautschet al., “Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 31, pp. 2507–2522, 2023
2021
-
[13]
Asvspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J.-w. Jung, H.-j. Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. Kinnunenet al., “Asvspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,”arXiv preprint arXiv:2408.08739, 2024
arXiv 2024
-
[14]
Combining evidences from mel cep- stral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech
T. B. Patel and H. A. Patil, “Combining evidences from mel cep- stral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech.” inInterspeech, 2015, pp. 2062–2066
2015
-
[15]
Cochlear filter and instantaneous frequency based features for spoofed speech detection,
——, “Cochlear filter and instantaneous frequency based features for spoofed speech detection,”IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 4, pp. 618–631, 2016
2016
-
[16]
Toward robust audio spoofing detection: A detailed comparison of traditional and learned features,
B. Balamurali, K. E. Lin, S. Lui, J.-M. Chen, and D. Herremans, “Toward robust audio spoofing detection: A detailed comparison of traditional and learned features,”IEEE Access, vol. 7, pp. 84 229– 84 241, 2019
2019
-
[17]
Spoofing speech detection using temporal convolutional neural network,
X. Tian, X. Xiao, E. S. Chng, and H. Li, “Spoofing speech detection using temporal convolutional neural network,” in2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE, 2016, pp. 1–6
2016
-
[18]
A light convolutional gru-rnn deep feature extractor for asv spoofing detection,
A. Gomez-Alanis, A. M. Peinado, J. A. Gonzalez, and A. M. Gomez, “A light convolutional gru-rnn deep feature extractor for asv spoofing detection,” inProc. Interspeech, vol. 2019, 2019, pp. 1068–1072
2019
-
[19]
Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.- J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” inICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 6367–6371
2022
-
[20]
The vicomtech audio deep- fake detection system based on wav2vec2 for the 2022 add chal- lenge,
J. M. Martín-Doñas and A. Álvarez, “The vicomtech audio deep- fake detection system based on wav2vec2 for the 2022 add chal- lenge,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9241–9245
2022
-
[21]
Automatic speaker verification spoofing and deep- fake detection using wav2vec 2.0 and data augmentation,
H. Tak, M. Todisco, X. Wang, J.-w. Jung, J. Yamagishi, and N. Evans, “Automatic speaker verification spoofing and deep- fake detection using wav2vec 2.0 and data augmentation,” inThe Speaker and Language Recognition Workshop (Odyssey 2022). ISCA, 2022
2022
-
[22]
Im- proved DeepFake Detection Using Whisper Features,
P. Kawa, M. Plata, M. Czuba, P. Szyma ´nski, and P. Syga, “Im- proved DeepFake Detection Using Whisper Features,” inInter- speech 2023, 2023, pp. 4009–4013
2023
-
[23]
Audio deep- fake detection with self-supervised wavlm and multi-fusion atten- tive classifier,
Y . Guo, H. Huang, X. Chen, H. Zhao, and Y . Wang, “Audio deep- fake detection with self-supervised wavlm and multi-fusion atten- tive classifier,” inICASSP 2024-2024 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 702–12 706
2024
-
[24]
Efficient audio deepfake detection using wavlm with early exiting,
A. Pimentel, Y . Zhu, H. R. Guimarães, and T. H. Falk, “Efficient audio deepfake detection using wavlm with early exiting,” in2024 IEEE International Workshop on Information Forensics and Secu- rity (WIFS). IEEE, 2024, pp. 1–6
2024
-
[25]
Leveraging SSL Speech Features and Mamba for Enhanced DeepFake Detection,
H. M. Tran, D. Lolive, D. Guennec, A. Sini, A. Delhay, and P.- F. Marteau, “Leveraging SSL Speech Features and Mamba for Enhanced DeepFake Detection,” inInterspeech 2025, 2025, pp. 5323–5327
2025
-
[26]
Multi-level ssl feature gating for audio deepfake de- tection,
H. M. Tran, D. Lolive, A. Sini, A. Delhay, P.-F. Marteau, and D. Guennec, “Multi-level ssl feature gating for audio deepfake de- tection,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 11 766–11 775
2025
-
[27]
Audiolm: a language modeling approach to audio gener- ation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “Audiolm: a language modeling approach to audio gener- ation,”IEEE/ACM transactions on audio, speech, and language processing, vol. 31, pp. 2523–2533, 2023
2023
-
[28]
Codecfake: Enhancing anti- spoofing models against deepfake audios from codec-based speech synthesis systems,
H. Wu, Y . Tseng, and H. yi Lee, “Codecfake: Enhancing anti- spoofing models against deepfake audios from codec-based speech synthesis systems,” inInterspeech 2024, 2024, pp. 1770–1774
2024
-
[29]
Codecfake: An initial dataset for detecting llm-based deepfake audio,
Y . Lu, Y . Xie, R. Fu, Z. Wen, J. Tao, Z. Wang, X. Qi, X. Liu, Y . Li, Y . Liu, X. Wang, and S. Shi, “Codecfake: An initial dataset for detecting llm-based deepfake audio,” inInterspeech 2024, 2024, pp. 1390–1394
2024
-
[30]
Codecfake+: A large-scale neu- ral audio codec-based deepfake speech dataset,
X. Chen, J. Du, H. Wu, L. Zhang, I. Lin, I. Chiu, W. Ren, Y . Tseng, Y . Tsao, J.-S. R. Janget al., “Codecfake+: A large-scale neu- ral audio codec-based deepfake speech dataset,”arXiv preprint arXiv:2501.08238, 2025
Pith/arXiv arXiv 2025
-
[31]
Whiadd: Semantic- acoustic fusion for robust audio deepfake detection,
J. Cui, B. Yu, Q. Wang, F. Meng, and J. Lu, “Whiadd: Semantic- acoustic fusion for robust audio deepfake detection,” inProceed- ings of the 33rd ACM International Conference on Multimedia, 2025, pp. 11 610–11 618
2025
-
[32]
The codecfake dataset and countermea- sures for the universally detection of deepfake audio,
Y . Xie, Y . Lu, R. Fu, Z. Wen, Z. Wang, J. Tao, X. Qi, X. Wang, Y . Liu, H. Chenget al., “The codecfake dataset and countermea- sures for the universally detection of deepfake audio,”IEEE Trans- actions on Audio, Speech and Language Processing, 2025
2025
-
[33]
How does our voice change as we age? a systematic review and meta-analysis of acoustic and perceptual voice data from healthy adults over 50 years of age,
S. Rojas, E. Kefalianos, and A. V ogel, “How does our voice change as we age? a systematic review and meta-analysis of acoustic and perceptual voice data from healthy adults over 50 years of age,” Journal of Speech, Language, and Hearing Research, vol. 63, no. 2, pp. 533–551, 2020
2020
-
[34]
The INTERSPEECH 2020 Computational Paralinguistics Challenge: Elderly Emotion, Breathing & Masks,
B. W. Schulleret al., “The INTERSPEECH 2020 Computational Paralinguistics Challenge: Elderly Emotion, Breathing & Masks,” inInterspeech 2020, 2020, pp. 2042–2046
2020
-
[35]
Is Everything Fine, Grandma? Acous- tic and Linguistic Modeling for Robust Elderly Speech Emotion Recognition,
G. So˘gancıo˘glu, O. Verkholyak, H. Kaya, D. Fedotov, T. Cadée, A. A. Salah, and A. Karpov, “Is Everything Fine, Grandma? Acous- tic and Linguistic Modeling for Robust Elderly Speech Emotion Recognition,” inInterspeech 2020, 2020, pp. 2097–2101
2020
-
[36]
Human voices communicating trustworthy intent: A demographically di- verse speech audio dataset,
C. Maltezou-Papastylianou, R. Scherer, and S. Paulmann, “Human voices communicating trustworthy intent: A demographically di- verse speech audio dataset,”Scientific Data, vol. 12, no. 1, p. 921, 2025
2025
-
[37]
Strong alone, stronger together: Synergizing modality-binding foundation models with optimal transport for non-verbal emotion recognition,
O. C. Phukan, M. M. Akhtar, S. R. Behera, S. Kalita, A. B. Buduru, R. Sharma, S. M. Prasannaet al., “Strong alone, stronger together: Synergizing modality-binding foundation models with optimal transport for non-verbal emotion recognition,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[38]
O. C. Phukan, G. S. Kashyap, A. B. Buduru, and R. Sharma, “Het- erogeneity over homogeneity: Investigating multilingual speech pre-trained models for detecting audio deepfake,”arXiv preprint arXiv:2404.00809, 2024
arXiv 2024
-
[39]
Seniortalk: A chinese conversation dataset with rich annotations for super-aged seniors,
Y . Chen, H. Wang, shiyao wang, J. Chen, J. He, J. Zhou, X. Yang, Y . Wang, Y . Lin, and Y . Qin, “Seniortalk: A chinese conversation dataset with rich annotations for super-aged seniors,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. [Online]. Available: https://openreview.net/forum?id=...
2025
-
[40]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[41]
High fidelity neu- ral audio compression,
A. Défossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neu- ral audio compression,”arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[42]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasac- chi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021
2021
-
[43]
Speechtokenizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representations,
-
[44]
Available: https://openreview.net/forum?id= AF9Q8Vip84
[Online]. Available: https://openreview.net/forum?id= AF9Q8Vip84
-
[45]
Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec,
Z. Du, S. Zhang, K. Hu, and S. Zheng, “Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 591–595
2024
-
[46]
Audiodec: An open-source streaming high-fidelity neural audio codec,
Y .-C. Wu, I. D. Gebru, D. Markovi´c, and A. Richard, “Audiodec: An open-source streaming high-fidelity neural audio codec,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[47]
Snac: Multi- scale neural audio codec,
H. Siuzdak, F. Grötschla, and L. A. Lanzendörfer, “Snac: Multi- scale neural audio codec,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation, 2024
2024
-
[48]
Moshi: a speech-text foundation model for real-time dialogue,
A. Défossez, L. Mazaré, M. Orsini, A. Royer, P. Pérez, H. Jégou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[49]
Languagebind: Extending video- language pretraining to n-modality by language-based semantic alignment,
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, W. HongFa, Y . Pang, W. Jiang, J. Zhang, Z. Li, C. W. Zhang, Z. Li, W. Liu, and L. Yuan, “Languagebind: Extending video- language pretraining to n-modality by language-based semantic alignment,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/f...
2024
-
[50]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 180–15 190
2023
-
[51]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[52]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505– 1518, 2022
2022
-
[53]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[54]
Multi-sensor data fusion based on a generalised belief divergence measure,
F. Xiao, “Multi-sensor data fusion based on a generalised belief divergence measure,”arXiv preprint arXiv:1806.01563, 2018
Pith/arXiv arXiv 2018
-
[55]
Multimodal generative learn- ing utilizing jensen-shannon-divergence,
T. Sutter, I. Daunhawer, and J. V ogt, “Multimodal generative learn- ing utilizing jensen-shannon-divergence,”Advances in neural in- formation processing systems, vol. 33, pp. 6100–6110, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.