RAIDS: Rethinking Data Systems as Responsible Intelligent Infrastructure
Pith reviewed 2026-06-26 11:32 UTC · model grok-4.3
The pith
RAIDS treats responsibility as execution semantics through operator-level contracts that compose across data pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
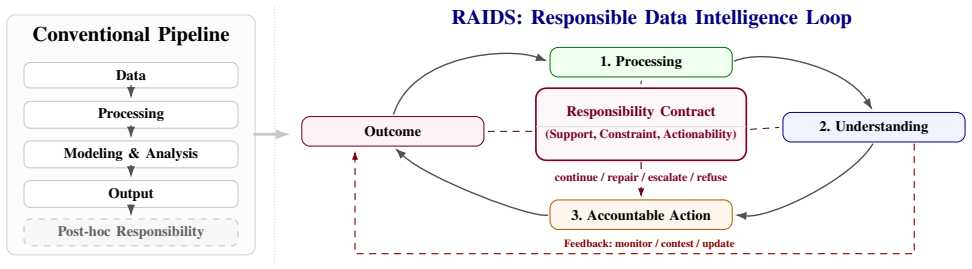
Responsibility is operationalized as an operator-level contract that exposes an output together with its support, constraint, and actionability state; these contracts compose across holistic data-to-decision pipelines, and responsibility preservation becomes the primary systems objective so that state remains adequate or the system changes course.
What carries the argument
The operator-level responsibility contract, which attaches support, constraint satisfaction, and actionability states to each operator output under a responsibility context and enables composition across pipelines.
If this is right
- Responsibility state must remain sufficient during execution or the system must repair, replan, escalate, or refuse.
- Query optimization and execution engines must incorporate responsibility dimensions alongside accuracy and efficiency.
- Provenance, oversight, and evaluation mechanisms become native to the execution model rather than added later.
- Data mining and decision pipelines can be designed end-to-end with responsibility as a first-class property.
Where Pith is reading between the lines
- Existing provenance systems could be extended by mapping their metadata directly onto the three responsibility state dimensions.
- Domain-specific responsibility contexts would need standardization before contracts can cross application boundaries.
- Performance experiments could test whether responsibility-aware scheduling changes latency or throughput under realistic workloads.
Load-bearing premise
Responsibility states can be defined for arbitrary operators and composed across pipelines in a way that permits practical preservation or repair.
What would settle it
A working implementation of responsibility contracts on a multi-operator pipeline where states cannot be maintained or repaired without losing correctness or incurring prohibitive overhead.
Figures
read the original abstract
Data systems are evolving from information infrastructure into decision infrastructure. Yet responsibility mechanisms have not kept pace: an output can be accurate or efficient while still lacking sufficient support, satisfied constraints, and actionability for responsible use. We propose RAIDS (Responsible and Intelligent Data System), a vision for data systems as responsible intelligent infrastructure. RAIDS treats responsibility not as post-hoc metadata, but as execution semantics for holistic data-to-decision and data mining pipelines. Its core abstraction is an operator-level responsibility contract: each operator exposes an output together with support, constraint, and actionability state under an explicit responsibility context, and these contracts compose across pipelines. These states capture whether an output is grounded, whether execution satisfies relevant limits, and which action modes are permissible. We introduce responsibility preservation as the organizing systems objective: responsibility state should remain sufficient as execution proceeds, or the system should repair, replan, escalate, refuse, or otherwise change course. We outline a BlueSky research agenda for RAIDS, spanning responsibility-preserving execution, responsibility-aware optimization, provenance, oversight, and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAIDS, a vision for data systems as responsible intelligent infrastructure. Responsibility is reframed as execution semantics rather than post-hoc metadata, with the core abstraction being an operator-level responsibility contract that exposes an output together with support, constraint-satisfaction, and actionability states under an explicit responsibility context; these contracts are asserted to compose across pipelines. Responsibility preservation is introduced as the organizing objective (triggering repair, replan, escalation, or refusal when states become insufficient), and a BlueSky research agenda is sketched across execution, optimization, provenance, oversight, and evaluation.
Significance. If the proposed abstractions can be developed into concrete, composable mechanisms, the work could shift data-system research toward treating responsibility as a first-class, enforceable property of pipelines rather than an external concern. This would have broad implications for trustworthy data-to-decision systems. At present the contribution is entirely prospective; its significance therefore rests on whether future realizations of the contract and preservation ideas prove tractable.
major comments (2)
- [Abstract] Abstract and core-abstraction paragraph: the central claim that responsibility contracts 'compose across pipelines' and thereby enable responsibility preservation (or repair/replan) is load-bearing, yet the manuscript supplies neither a formal semantics for the three states nor a worked example for any pair of operators (e.g., filter then aggregate). Without such grounding the composition claim remains an assertion rather than a demonstrated property.
- The paragraph introducing responsibility preservation: no argument is given that the support/constraint/actionability states are closed under composition or that maintaining them remains tractable for arbitrary operators; this directly affects whether preservation can serve as a practical systems objective.
minor comments (2)
- Several key terms ('responsibility context', 'responsibility preservation', 'action modes') are introduced without an initial glossary or illustrative definition, making the high-level proposal harder to evaluate.
- The research agenda section would benefit from explicit prioritization or a minimal concrete milestone (e.g., a two-operator prototype) to make the vision more actionable for readers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the load-bearing aspects of the proposed abstractions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and core-abstraction paragraph: the central claim that responsibility contracts 'compose across pipelines' and thereby enable responsibility preservation (or repair/replan) is load-bearing, yet the manuscript supplies neither a formal semantics for the three states nor a worked example for any pair of operators (e.g., filter then aggregate). Without such grounding the composition claim remains an assertion rather than a demonstrated property.
Authors: The manuscript is explicitly a vision paper that introduces responsibility contracts and preservation as organizing concepts rather than as a completed formalism. We do not claim to have established or demonstrated composition; the text presents it as the intended semantics of the abstraction whose realization is listed among the open questions in the BlueSky agenda. Adding formal semantics or operator-pair examples would shift the paper from a prospective outline to a technical development, which lies outside its stated scope. revision: no
-
Referee: The paragraph introducing responsibility preservation: no argument is given that the support/constraint/actionability states are closed under composition or that maintaining them remains tractable for arbitrary operators; this directly affects whether preservation can serve as a practical systems objective.
Authors: We concur that no closure or tractability argument appears, because the manuscript does not assert that the states are closed or that preservation is immediately tractable. Instead, it nominates preservation as the systems objective whose feasibility, including compositionality and scalability across operators, constitutes part of the research program to be pursued. The absence of such arguments is therefore consistent with the paper's framing as an agenda rather than a solved system. revision: no
Circularity Check
High-level vision proposal with no derivations or equations
full rationale
The manuscript is a conceptual vision paper proposing RAIDS as a new abstraction for data systems. It contains no equations, no formal derivations, no fitted parameters, no predictions, and no mathematical claims that could reduce to inputs by construction. The core ideas (operator-level responsibility contracts, responsibility preservation) are presented as definitional proposals rather than derived results. No self-citation chains or uniqueness theorems are invoked to justify load-bearing steps. This is the expected non-finding for a high-level systems vision paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Responsibility can be captured through explicit states of support, constraint satisfaction, and actionability under a responsibility context.
invented entities (2)
-
Responsibility contract
no independent evidence
-
Responsibility preservation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dissecting racial bias in an algorithm used to manage the health of populations,
Z. Obermeyer, B. Powers, C. V ogeli, and S. Mullainathan, “Dissecting racial bias in an algorithm used to manage the health of populations,” Science, vol. 366, no. 6464, pp. 447–453, 2019
2019
-
[2]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohl, P. Payne, M. Senevi- ratne, P. Gamble, C. Kelly, N. Sch ¨arli, A. Chowdhery, P. Mansfield, D. Demner-Fushman, B. Ag ¨uera y Arcas, D. Webster, G. S. Corrado, Y . Matias, K. Chou, J. Gottweis, N. Tomasev, Y . Liu, A. Rajkomar, J. Barral, C. Semt...
2023
-
[3]
Y . Yan, H. Li, H. He, G. Kai, Z. Yang, and G. Liu, “SALP-CG: Standard- aligned LLM pipeline for classifying and grading large volumes of online conversational health data,” arXiv preprint arXiv:2601.09717, 2026
arXiv 2026
-
[4]
Empirical asset pricing via machine learning,
S. Gu, B. Kelly, and D. Xiu, “Empirical asset pricing via machine learning,”Journal of Financial Economics, vol. 136, no. 1, pp. 222– 253, 2020
2020
-
[5]
AEFA: An ensemble framework for fraud detection in the forex market,
W. Wang, J. Yu, Z. Yang, M. Ju, S. Yu, J. Wu, L. Liu, Y . Liu, J. Shepherd, and W. Zhang, “AEFA: An ensemble framework for fraud detection in the forex market,” inAdvanced Data Mining and Applications. Springer Nature Singapore, 2025, pp. 34–49
2025
-
[6]
ForexAgent: Identifying trading strategies in forex markets with large language models,
X. Shu, M. Ju, Z. Chen, Y . Ding, W. Zhang, D. Wen, and Z. Yang, “ForexAgent: Identifying trading strategies in forex markets with large language models,” in2026 IEEE International Conference on Big Data and Smart Computing, ser. BigComp, 2026, pp. 55–62
2026
-
[7]
Gov- ernment by algorithm: Artificial intelligence in federal administrative agencies,
D. F. Engstrom, D. E. Ho, C. M. Sharkey, and M.-F. Cu ´ellar, “Gov- ernment by algorithm: Artificial intelligence in federal administrative agencies,” Administrative Conference of the United States, Tech. Rep., 2020
2020
-
[8]
Accountable algorithms,
J. A. Kroll, J. Huey, S. Barocas, E. W. Felten, J. R. Reidenberg, D. G. Robinson, and H. Yu, “Accountable algorithms,”University of Pennsylvania Law Review, vol. 165, no. 3, pp. 633–705, 2017
2017
-
[9]
Fair prediction with disparate impact: A study of bias in recidivism prediction instruments,
A. Chouldechova, “Fair prediction with disparate impact: A study of bias in recidivism prediction instruments,”Big Data, vol. 5, no. 2, pp. 153–163, 2017
2017
-
[10]
Runaway feedback loops in predictive policing,
D. Ensign, S. A. Friedler, S. Neville, C. Scheidegger, and S. Venkatasub- ramanian, “Runaway feedback loops in predictive policing,” inProceed- ings of the 1st Conference on Fairness, Accountability and Transparency, ser. FAT* ’18, 2018, pp. 160–171
2018
-
[11]
Improving access to building licensing information in Australia: Design and development of a graph-based retrieval-augmented generation artificial intelligence system,
D. Yan, J. Liu, B. Han, Z. Yang, J. He, J. Xu, R. Y . Sunindijo, and C. C. Wang, “Improving access to building licensing information in Australia: Design and development of a graph-based retrieval-augmented generation artificial intelligence system,”Buildings, vol. 16, no. 6, p. 1224, 2026
2026
-
[12]
T. Hey, S. Tansley, and K. Tolle, Eds.,The Fourth Paradigm: Data- Intensive Scientific Discovery. Microsoft Research, 2009
2009
-
[13]
Highly accurate protein structure prediction with AlphaFold,
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. ˇZ´ıdek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera- Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstei...
2021
-
[14]
Scaling deep learning for materials discovery,
A. Merchant, S. Batzner, S. S. Schoenholz, M. Aykol, G. Cheon, and E. D. Cubuk, “Scaling deep learning for materials discovery,”Nature, vol. 624, pp. 80–85, 2023
2023
-
[15]
Accurate medium-range global weather forecasting with 3D neural networks,
K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian, “Accurate medium-range global weather forecasting with 3D neural networks,” Nature, vol. 619, pp. 533–538, 2023
2023
-
[16]
Machine learning for environ- mental monitoring,
M. Hino, E. Benami, and N. Brooks, “Machine learning for environ- mental monitoring,”Nature Sustainability, vol. 1, pp. 583–588, 2018
2018
-
[17]
Machine learning methods in weather and climate applications: A survey,
L. Chen, B. Han, X. Wang, J. Zhao, W. Yang, and Z. Yang, “Machine learning methods in weather and climate applications: A survey,”Applied Sciences, vol. 13, no. 21, p. 12019, 2023
2023
-
[18]
Holistic evaluation of language models,
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. Cosgrove, C. D. Manning, C. R´e, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. Wang, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. Guh...
2023
-
[19]
Tabular-textual question answering: From parallel program generation to large language models,
X. Tang, L. Chen, W. Yang, Z. Yang, M. Ju, X. Shu, Z. Yang, and Y . Tang, “Tabular-textual question answering: From parallel program generation to large language models,”World Wide Web, vol. 28, no. 4, p. 42, 2025
2025
-
[20]
Parallel program generation for hybrid tabular-textual question answer- ing,
W. Yang, Z. Yang, L. Chen, R. Yan, Z. Yang, L. Zhang, and Y . Tang, “Parallel program generation for hybrid tabular-textual question answer- ing,” inWeb and Big Data. Springer Nature Singapore, 2024, pp. 121–137
2024
-
[21]
Big data and its technical challenges,
H. V . Jagadish, J. Gehrke, A. Labrinidis, Y . Papakonstantinou, J. M. Patel, R. Ramakrishnan, and C. Shahabi, “Big data and its technical challenges,”Communications of the ACM, vol. 57, no. 7, pp. 86–94, 2014
2014
-
[22]
The cambridge report on database research,
A. Ailamaki, S. Madden, D. Abadi, G. Alonso, S. Amer-Yahia, M. Bal- azinska, P. A. Bernstein, P. Boncz, M. Cafarella, S. Chaudhuri, S. David- son, D. DeWitt, Y . Diao, X. L. Dong, M. Franklin, J. Freire, J. Gehrke, A. Halevy, J. M. Hellerstein, M. D. Hill, S. Idreos, Y . Ioannidis, C. Koch, D. Kossmann, T. Kraska, A. Kumar, G. Li, V . Markl, R. Miller, C....
arXiv 2025
-
[23]
Survey of vector database management systems,
J. J. Pan, J. Wang, and G. Li, “Survey of vector database management systems,”The VLDB Journal, vol. 33, no. 5, pp. 1591–1615, 2024
2024
-
[24]
Machine learning: Trends, perspec- tives, and prospects,
M. I. Jordan and T. M. Mitchell, “Machine learning: Trends, perspec- tives, and prospects,”Science, vol. 349, no. 6245, pp. 255–260, 2015
2015
-
[25]
DataPerf: Benchmarks for data-centric AI development,
M. Mazumder, C. Banbury, X. Yao, B. Karla ˇs, W. G. Rojas, S. Diamos, G. Diamos, L. He, A. Parrish, H. R. Kirk, J. Quaye, C. Rastogi, D. Kiela, D. Jurado, D. Kanter, R. Mosquera, J. Ciro, L. Aroyo, B. Acun, L. Chen, M. S. Raje, M. Bartolo, S. Eyuboglu, A. Ghorbani, E. Goodman, O. Inel, T. Kane, C. R. Kirkpatrick, T.-S. Kuo, J. Mueller, T. Thrush, J. Vansc...
2023
-
[26]
Data quality management for responsible AI in data lakes,
C. Cortes, C. Sanz, L. Etcheverry, and A. Marotta, “Data quality management for responsible AI in data lakes,” inVLDB Workshops, 2024
2024
-
[27]
Towards interpretable and trustworthy time series reasoning: A BlueSky vision,
K. Ning, Z. Pan, Y . Jiang, A. Schneider, Y . Nevmyvaka, and D. Song, “Towards interpretable and trustworthy time series reasoning: A BlueSky vision,” in2025 IEEE International Conference on Data Mining Work- shops (ICDMW), 2025, pp. 2497–2502
2025
-
[28]
Text-to- SQL empowered by large language models: A benchmark evaluation,
D. Gao, H. Wang, Y . Li, X. Sun, Y . Qian, B. Ding, and J. Zhou, “Text-to- SQL empowered by large language models: A benchmark evaluation,” Proceedings of the VLDB Endowment, vol. 17, no. 5, pp. 1132–1145, 2024
2024
-
[29]
Semantic operators and their optimization: Enabling LLM- based data processing with accuracy guarantees in LOTUS,
L. Patel, S. Jha, M. Pan, H. Gupta, P. Asawa, C. Guestrin, and M. Zaharia, “Semantic operators and their optimization: Enabling LLM- based data processing with accuracy guarantees in LOTUS,”Proceedings of the VLDB Endowment, vol. 18, no. 11, pp. 4171–4184, 2025
2025
-
[30]
DocETL: Agentic query rewriting and evaluation for complex docu- ment processing,
S. Shankar, T. Chambers, T. Shah, A. G. Parameswaran, and E. Wu, “DocETL: Agentic query rewriting and evaluation for complex docu- ment processing,” arXiv preprint arXiv:2410.12189, 2024
arXiv 2024
-
[31]
Graphy’our data: Towards end-to-end modeling, exploring and generating report from raw data,
L. Lai, C. Luo, Y . Lou, M. Ju, and Z. Yang, “Graphy’our data: Towards end-to-end modeling, exploring and generating report from raw data,” inCompanion of the 2025 International Conference on Management of Data, ser. SIGMOD Companion ’25, 2025, pp. 147–150
2025
-
[32]
Artificial intelligence risk management framework (AI RMF 1.0),
National Institute of Standards and Technology, “Artificial intelligence risk management framework (AI RMF 1.0),” National Institute of Standards and Technology, Tech. Rep. NIST AI 100-1, 2023
2023
-
[33]
Responsible data management,
J. Stoyanovich, S. Abiteboul, B. Howe, H. V . Jagadish, and S. Schelter, “Responsible data management,”Communications of the ACM, vol. 65, no. 6, pp. 64–74, 2022
2022
-
[34]
S. Abiteboul and J. Stoyanovich, “Transparency, fairness, data pro- tection, neutrality: Data management challenges in the face of new regulation,” arXiv preprint arXiv:1903.03683, 2019
Pith/arXiv arXiv 1903
-
[35]
Designing data governance,
V . Khatri and C. V . Brown, “Designing data governance,”Communica- tions of the ACM, vol. 53, no. 1, pp. 148–152, 2010
2010
-
[36]
Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic audit- ing,
I. D. Raji, A. Smart, R. N. White, M. Mitchell, T. Gebru, B. Hutchinson, J. Smith-Loud, D. Theron, and P. Barnes, “Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic audit- ing,” inProceedings of the 2020 Conference on Fairness, Accountability, and Transparency, ser. FAT* ’20, 2020, pp. 33–44
2020
-
[37]
Calibrating noise to sensitivity in private data analysis,
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to sensitivity in private data analysis,” inTheory of Cryptography, ser. TCC ’06, 2006, pp. 265–284
2006
-
[38]
European Parliament and Council of the European Union, “Regulation (EU) 2016/679 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data (General Data Protection Regulation),” Official Journal of the European Union, OJ L 119, 4 May 2016, 2016
2016
-
[39]
Environmental footprints of query processing: A vision for sustainable database architectures,
M. Bachras and H.-A. Jacobsen, “Environmental footprints of query processing: A vision for sustainable database architectures,”Proceedings of the VLDB Endowment, vol. 18, no. 11, pp. 4064–4072, 2025
2025
-
[40]
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),
European Parliament and Council of the European Union, “Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),” Official Journal of the European Union, OJ L, 2024/1689, 12 July 2024, 2024
2024
-
[41]
Data validation for machine learning,
E. Breck, N. Polyzotis, S. Roy, S. E. Whang, and M. Zinkevich, “Data validation for machine learning,” inProceedings of the 2nd Conference on Machine Learning and Systems, ser. MLSys, 2019, pp. 334–347
2019
-
[42]
Model cards for model reporting,
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchin- son, E. Spitzer, I. D. Raji, and T. Gebru, “Model cards for model reporting,” inProceedings of the Conference on Fairness, Accountability, and Transparency, ser. FAT* ’19, 2019, pp. 220–229
2019
-
[43]
Datasheets for datasets,
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. Daum ´e III, and K. Crawford, “Datasheets for datasets,”Communi- cations of the ACM, vol. 64, no. 12, pp. 86–92, 2021
2021
-
[44]
Provenance semirings,
T. J. Green, G. Karvounarakis, and V . Tannen, “Provenance semirings,” inProceedings of the Twenty-Sixth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, ser. PODS ’07, 2007, pp. 31–40
2007
-
[45]
OneProvenance: Efficient extraction of dynamic coarse-grained provenance from database query event logs,
F. Psallidas, A. Agrawal, C. Sugunan, K. Ibrahim, K. Karanasos, J. Camacho-Rodr ´ıguez, A. Floratou, C. Curino, and R. Ramakrish- nan, “OneProvenance: Efficient extraction of dynamic coarse-grained provenance from database query event logs,”Proceedings of the VLDB Endowment, vol. 16, no. 12, pp. 3662–3675, 2023
2023
-
[46]
Auditing algorithms: Research methods for detecting discrimination on internet platforms,
C. Sandvig, K. Hamilton, K. Karahalios, and C. Langbort, “Auditing algorithms: Research methods for detecting discrimination on internet platforms,” inData and Discrimination: Converting Critical Concerns into Productive Inquiry, 2014
2014
-
[47]
Actionable auditing: Investigating the impact of publicly naming biased performance results of commercial AI products,
I. D. Raji and J. Buolamwini, “Actionable auditing: Investigating the impact of publicly naming biased performance results of commercial AI products,” inProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, ser. AIES ’19, 2019, pp. 429–435
2019
-
[48]
Data man- agement challenges in production machine learning,
N. Polyzotis, S. Roy, S. E. Whang, and M. Zinkevich, “Data man- agement challenges in production machine learning,”SIGMOD Record, vol. 46, no. 2, pp. 17–20, 2017
2017
-
[49]
Hidden technical debt in machine learning systems,
D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V . Chaudhary, M. Young, J.-F. Crespo, and D. Dennison, “Hidden technical debt in machine learning systems,” inAdvances in Neural Information Processing Systems, vol. 28, 2015, pp. 2503–2511
2015
-
[50]
Make your database system dream of electric sheep: Towards self-driving operation,
A. Pavlo, M. Butrovich, L. Ma, P. Menon, W. S. Lim, D. Van Aken, and W. Zhang, “Make your database system dream of electric sheep: Towards self-driving operation,”Proceedings of the VLDB Endowment, vol. 14, no. 12, pp. 3211–3221, 2021
2021
-
[51]
One size does not fit all—a contingency approach to data governance,
K. Weber, B. Otto, and H. ¨Osterle, “One size does not fit all—a contingency approach to data governance,”ACM Journal of Data and Information Quality, vol. 1, no. 1, 2009
2009
-
[52]
Data governance: A conceptual framework, structured review, and research agenda,
R. Abraham, J. Schneider, and J. vom Brocke, “Data governance: A conceptual framework, structured review, and research agenda,”Interna- tional Journal of Information Management, vol. 49, pp. 424–438, 2019
2019
-
[53]
Data governance: Organizing data for trustworthy artificial intelligence,
M. Janssen, P. Brous, E. Estevez, L. S. Barbosa, and T. Janowski, “Data governance: Organizing data for trustworthy artificial intelligence,” Government Information Quarterly, vol. 37, no. 3, p. 101493, 2020
2020
-
[54]
Capturing and querying fine-grained provenance of preprocessing pipelines in data science,
A. Chapman, P. Missier, G. Simonelli, and R. Torlone, “Capturing and querying fine-grained provenance of preprocessing pipelines in data science,”Proceedings of the VLDB Endowment, vol. 14, no. 4, pp. 507– 520, 2021
2021
-
[55]
Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems,
A. Datta, S. Sen, and Y . Zick, “Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems,” in2016 IEEE Symposium on Security and Privacy, 2016, pp. 598–617
2016
-
[56]
Croissant: A metadata format for ML-ready datasets,
M. Akhtar, O. Benjelloun, C. Conforti, L. Foschini, J. Giner-Miguelez, P. Gijsbers, S. Goswami, N. Jain, M. Karamousadakis, M. Kuchnik, S. Krishna, S. Lesage, Q. Lhoest, P. Marcenac, M. Maskey, P. Mattson, L. Oala, H. Oderinwale, P. Ruyssen, T. Santos, R. Shinde, E. Simperl, A. Suresh, G. Thomas, S. Tykhonov, J. Vanschoren, S. Varma, J. van der Velde, S. ...
2024
-
[57]
A standardized machine-readable dataset docu- mentation format for responsible AI,
N. Jain, M. Akhtar, J. Giner-Miguelez, R. Shinde, J. Vanschoren, S. V ogler, S. Goswami, Y . Rao, T. Santos, L. Oala, M. Karamousadakis, M. Maskey, P. Marcenac, C. Conforti, M. Kuchnik, L. Aroyo, O. Ben- jelloun, and E. Simperl, “A standardized machine-readable dataset docu- mentation format for responsible AI,” arXiv preprint arXiv:2407.16883, 2024
arXiv 2024
-
[58]
Interventional fairness: Causal database repair for algorithmic fairness,
B. Salimi, L. Rodriguez, B. Howe, and D. Suciu, “Interventional fairness: Causal database repair for algorithmic fairness,” inProceedings of the 2019 International Conference on Management of Data, ser. SIGMOD ’19, 2019, pp. 793–810
2019
-
[59]
Tailoring data source distributions for fairness-aware data integration,
F. Nargesian, A. Asudeh, and H. V . Jagadish, “Tailoring data source distributions for fairness-aware data integration,”Proceedings of the VLDB Endowment, vol. 14, no. 11, pp. 2519–2532, 2021
2021
-
[60]
Fairness of exposure in rankings,
A. Singh and T. Joachims, “Fairness of exposure in rankings,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’18, 2018, pp. 2219– 2228
2018
-
[61]
Equity of attention: Amortizing individual fairness in rankings,
A. J. Biega, K. P. Gummadi, and G. Weikum, “Equity of attention: Amortizing individual fairness in rankings,” inProceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’18, 2018, pp. 405–414
2018
-
[62]
HoloClean: Holistic data repairs with probabilistic inference,
T. Rekatsinas, X. Chu, I. F. Ilyas, and C. R ´e, “HoloClean: Holistic data repairs with probabilistic inference,”Proceedings of the VLDB Endowment, vol. 10, no. 11, pp. 1190–1201, 2017
2017
-
[63]
Active- Clean: Interactive data cleaning while learning convex loss models,
S. Krishnan, J. Wang, E. Wu, M. J. Franklin, and K. Goldberg, “Active- Clean: Interactive data cleaning while learning convex loss models,” in Proceedings of the 2016 International Conference on Management of Data, ser. SIGMOD ’16, 2016, pp. 948–959
2016
-
[64]
Confident learning: Es- timating uncertainty in dataset labels,
C. G. Northcutt, L. Jiang, and I. L. Chuang, “Confident learning: Es- timating uncertainty in dataset labels,”Journal of Artificial Intelligence Research, vol. 70, pp. 1373–1411, 2021
2021
-
[65]
CRAG: Comprehensive RAG benchmark,
X. Yang, K. Sun, H. Xin, Y . Sun, N. Bhalla, X. Chen, S. Choudhary, R. D. Gui, Z. W. Jiang, Z. Jiang, L. Kong, B. Moran, J. Wang, Y . E. Xu, A. Yan, C. Yang, E. Yuan, H. Zha, N. Tang, L. Chen, N. Scheffer, Y . Liu, N. Shah, R. Wanga, A. Kumar, W.-t. Yih, and X. L. Dong, “CRAG: Comprehensive RAG benchmark,” inAdvances in Neural Information Processing Syste...
2024
-
[66]
The FAIR guiding principles for scientific data management and stewardship,
M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J.-W. Boiten, L. B. da Silva Santos, P. E. Bourne, J. Bouwman, A. J. Brookes, T. Clark, M. Crosas, I. Dillo, O. Dumon, S. Edmunds, C. T. Evelo, R. Finkers, A. Gonzalez-Beltran, A. J. G. Gray, P. Groth, C. Goble, J. S. Grethe, J. Heringa, P. A. C. ’t Hoen, R. Hoo...
2016
-
[67]
Data quality aware hierarchical federated reinforcement learning framework for dynamic treatment regimes,
M. Li, X. Zhang, H. Ying, Y . Li, X. Han, and D. Yu, “Data quality aware hierarchical federated reinforcement learning framework for dynamic treatment regimes,” in2023 IEEE International Conference on Data Mining (ICDM), 2023, pp. 1103–1108
2023
-
[68]
Class-specific explainability for deep time series classifiers,
R. Doddaiah, P. S. Parvatharaju, E. A. Rundensteiner, and T. Hartvigsen, “Class-specific explainability for deep time series classifiers,” in2022 IEEE International Conference on Data Mining (ICDM), 2022, pp. 101– 110
2022
-
[69]
Equality of opportunity in super- vised learning,
M. Hardt, E. Price, and N. Srebro, “Equality of opportunity in super- vised learning,” inAdvances in Neural Information Processing Systems, vol. 29, 2016, pp. 3315–3323
2016
-
[70]
Metric-free individual fairness with coop- erative contextual bandits,
Q. Hu and H. Rangwala, “Metric-free individual fairness with coop- erative contextual bandits,” in2020 IEEE International Conference on Data Mining (ICDM), 2020, pp. 182–191
2020
-
[71]
Fair decision-making under uncertainty,
W. Zhang and J. C. Weiss, “Fair decision-making under uncertainty,” in2021 IEEE International Conference on Data Mining (ICDM), 2021, pp. 886–895
2021
-
[72]
Do they understand them? an updated evaluation on nonbinary pronoun handling in large language models,
X. Tang, Y . Ding, Z. Yang, Y . Chen, Y . Gu, W. Yang, M. Ju, X. Cao, Y . Liu, and W. Zhang, “Do they understand them? an updated evaluation on nonbinary pronoun handling in large language models,” inAI 2025: Advances in Artificial Intelligence. Springer Nature Singapore, 2025, pp. 204–219
2025
-
[73]
Transforming our world: The 2030 agenda for sustain- able development,
United Nations, “Transforming our world: The 2030 agenda for sustain- able development,” United Nations, 2015
2030
-
[74]
Blueprint for an AI bill of rights: Making automated systems work for the american people,
White House Office of Science and Technology Policy, “Blueprint for an AI bill of rights: Making automated systems work for the american people,” The White House, 2022
2022
-
[75]
Leveraging hierarchical rep- resentations for preserving privacy and utility in text,
O. Feyisetan, T. Diethe, and T. Drake, “Leveraging hierarchical rep- resentations for preserving privacy and utility in text,” in2019 IEEE International Conference on Data Mining (ICDM), 2019, pp. 210–219
2019
-
[76]
Fairness through awareness,
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel, “Fairness through awareness,” inProceedings of the 3rd Innovations in Theoretical Computer Science Conference, ser. ITCS ’12, 2012, pp. 214–226
2012
-
[77]
fair-LDP: Uncertainty-guided fairness and privacy for federated healthcare learning,
D. Chen, Q. Zhang, L. M. Kaplan, A. Jøsang, D. H. Jeong, F. Chen, and J.-H. Cho, “fair-LDP: Uncertainty-guided fairness and privacy for federated healthcare learning,” in2025 IEEE International Conference on Data Mining (ICDM), 2025, pp. 130–139
2025
-
[78]
Delayed im- pact of fair machine learning,
L. T. Liu, S. Dean, E. Rolf, M. Simchowitz, and M. Hardt, “Delayed im- pact of fair machine learning,” inProceedings of the 35th International Conference on Machine Learning, ser. ICML ’18, 2018, pp. 3150–3158
2018
-
[79]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[80]
From local to global: A graph RAG approach to query- focused summarization,
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson, “From local to global: A graph RAG approach to query- focused summarization,” arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.