ESPnet3: Infrastructure for Scalable Speech and Audio Research in the Foundation Model Era
Pith reviewed 2026-06-26 11:52 UTC · model grok-4.3
The pith
ESPnet3 uses a modular DataOrganizer and dataset sharding to cut speech pre-training time by 21.1 minutes per epoch while allowing new models to be added in about 46 lines of code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ESPnet3 is a speech and audio research framework built on a modular system architecture with configuration-driven dataset composition and unified Python-based workflows. It introduces a DataOrganizer abstraction for flexible dataset integration and dataset sharding for memory-efficient large-scale training, while allowing recipe-specific logic through lightweight stage overrides. In OWSM pre-training experiments, ESPnet3 reduces per-epoch training time by 21.1 minutes compared to ESPnet2 and achieves >80% GPU utilization in multi-node training. Fine-tuning experiments show that new models and datasets can be integrated with around 46 lines of additional code.
What carries the argument
The DataOrganizer abstraction paired with dataset sharding, which manages flexible dataset composition and enables memory-efficient training across nodes.
If this is right
- Per-epoch training time drops by 21.1 minutes during large-scale pre-training.
- Multi-node training reaches more than 80 percent GPU utilization.
- New models and datasets integrate with roughly 46 lines of additional code.
- Recipe-specific logic stays isolated through lightweight stage overrides.
Where Pith is reading between the lines
- The same modular pattern could reduce setup costs for other data-heavy foundation-model experiments outside speech.
- Public release of checkpoints and logs would let independent groups verify the utilization numbers on their own clusters.
- Dataset sharding might extend naturally to multi-modal audio-text or audio-video training pipelines.
Load-bearing premise
The measured drops in training time and rises in GPU utilization come from the new DataOrganizer and sharding design rather than differences in hardware, other code changes, or unstated optimizations.
What would settle it
Re-running the OWSM pre-training on the same hardware and base code but without the DataOrganizer and sharding changes, then finding no reduction in epoch time or GPU utilization, would falsify the performance claims.
Figures


read the original abstract
Recent speech research involves increasingly large datasets, complex models, and diverse experimental workflows. However, existing frameworks require substantial engineering effort to support such experiments. We present ESPnet3, a speech and audio research framework built on a modular system architecture with configuration-driven dataset composition and unified Python-based workflows. ESPnet3 introduces a DataOrganizer abstraction for flexible dataset integration and dataset sharding for memory-efficient large-scale training, while allowing recipe-specific logic through lightweight stage overrides. In OWSM pre-training experiments, ESPnet3 reduces per-epoch training time by \emph{21.1 minutes} compared to ESPnet2 and achieves \emph{>80\% GPU utilization} in multi-node training. Fine-tuning experiments show that new models and datasets can be integrated with around \emph{46 lines of additional code}. ESPnet3 will be publicly released with model checkpoints and training logs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ESPnet3, a modular speech and audio research framework built on configuration-driven dataset composition, a DataOrganizer abstraction for flexible dataset integration, and dataset sharding for memory-efficient large-scale training. It allows recipe-specific logic via lightweight stage overrides and reports empirical results from OWSM pre-training: a 21.1-minute reduction in per-epoch training time versus ESPnet2, >80% GPU utilization in multi-node training, and the ability to integrate new models/datasets with ~46 lines of additional code. The framework is slated for public release with checkpoints and logs.
Significance. If the performance and integration claims can be substantiated with controlled experiments, ESPnet3 would address a practical bottleneck in scaling speech foundation-model research by reducing custom engineering effort. The public release of artifacts would further strengthen its utility for the community.
major comments (2)
- [Abstract] Abstract (performance claims paragraph): The headline results (21.1 min/epoch reduction and >80% multi-node GPU utilization) are presented without any description of the ESPnet2 baseline configuration, hardware match, batch-size equivalence, data-pipeline settings, or other variables held constant. This prevents attribution of the observed deltas to the new DataOrganizer and sharding design rather than unmentioned implementation differences.
- [Abstract] Abstract: No methods, error bars, dataset details, or statistical controls are supplied for the reported training-time and utilization numbers, leaving the central empirical claims unverifiable from the provided text.
minor comments (1)
- [Abstract] The phrase 'around 46 lines of additional code' is given without a concrete code listing or section reference, making it difficult to evaluate the integration claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for greater transparency around the empirical claims in the abstract. We agree that the current abstract text does not supply sufficient context for the reported deltas and will revise the manuscript to improve verifiability while preserving the abstract's brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claims paragraph): The headline results (21.1 min/epoch reduction and >80% multi-node GPU utilization) are presented without any description of the ESPnet2 baseline configuration, hardware match, batch-size equivalence, data-pipeline settings, or other variables held constant. This prevents attribution of the observed deltas to the new DataOrganizer and sharding design rather than unmentioned implementation differences.
Authors: We accept the point. Section 4.1 of the manuscript already specifies the matched experimental conditions (identical 8 imes A100 nodes, same per-GPU batch size of 32, identical data sharding parameters, and the same OWSM training corpus). To make this attribution explicit from the abstract itself, we will add a short clause stating that the comparison used identical hardware, batch sizes, and data-pipeline settings. This change will be made in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: No methods, error bars, dataset details, or statistical controls are supplied for the reported training-time and utilization numbers, leaving the central empirical claims unverifiable from the provided text.
Authors: Dataset details for the OWSM pre-training corpus appear in Section 3. The reported figures are single-run wall-clock measurements under the controlled conditions noted above; error bars were not computed because the engineering focus was on end-to-end reproducibility rather than statistical variance across random seeds. In the revision we will (i) insert a parenthetical reference to Section 4.1 in the abstract and (ii) add a short methods footnote or table caption that states the measurement protocol, thereby allowing readers to locate the full controls without lengthening the abstract body. revision: partial
Circularity Check
No circularity; empirical engineering measurements are self-contained
full rationale
The manuscript reports direct empirical measurements (per-epoch training time reduction of 21.1 minutes, >80% GPU utilization, ~46 lines of code for integration) from OWSM pre-training and fine-tuning experiments. No equations, fitted parameters, uniqueness theorems, or derivation chains exist that could reduce any claimed result to its own inputs by construction. The central claims are observational benchmarks of the framework rather than self-referential predictions or ansatzes smuggled via self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech and audio research has entered the foundation-model era. Training corpora have expanded from thousands to millions of hours [1–7], while model sizes have grown to billions of param- eters [8–15]. Large-scale training now enables unified models that cover diverse languages, accents, and tasks within a single architecture [2,16,17]. At t...
Pith/arXiv arXiv 2026
-
[2]
These toolkits differ in both task coverage and infrastructure design, as summa- rized in Table 1
Related Works Several open-source toolkits [30, 35] have been developed for end-to-end speech and audio processing, each emphasizing dif- ferent design priorities and user communities. These toolkits differ in both task coverage and infrastructure design, as summa- rized in Table 1. ESPnet [26] supports a broad range of speech modeling tasks, while other ...
-
[3]
Design ESPnet3 is designed around three architectural principles: configuration-driven data abstraction for declarative dataset com- position and scalable iteration, modular system architecture that separates experiment logic from framework internals, and a uni-
-
[4]
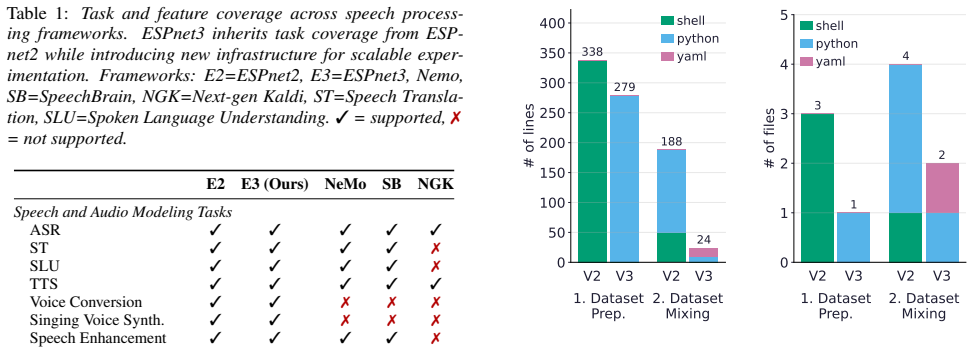
Dataset Mixing 0 50 100 150 200 250 300 350 400# of lines 338 188 V2 V2 279 24 V3 V3 shell python yaml
-
[5]
(a) ESPnet3 significantly reduces the lines of code to prepare and mix the datasets for large scale training
Dataset Mixing 0 1 2 3 4 5# of files 3 4 V2 V2 1 2 V3 V3 shell python yaml Figure 1:Comparison of implementation effort between ESPnet2 (V2) and ESPnet3 (V3) for dataset management. (a) ESPnet3 significantly reduces the lines of code to prepare and mix the datasets for large scale training. (b) The number of files required to edit is also minimized. ESPne...
-
[6]
Experiments This section evaluates ESPnet3 from a system perspective, fo- cusing on implementation simplicity and extensibility rather than raw model performance. We use OWSM V4 pre-training and fine-tuning as representative case studies to demonstrate how ESPnet3 supports multiple dimensions of scaling, including large-scale dataset integration and diver...
-
[7]
We achieved over 80% scaling efficiency even across nodes (Slingshot interconnect)
training. We achieved over 80% scaling efficiency even across nodes (Slingshot interconnect). Table 2:Comparison of training efficiency and implementa- tion complexity between ESPnet2 and ESPnet3 for OWSM-Base pre-training. Both experiments were conducted with the same hardware and training configurations.Upddenotes the average wall-clock time per optimiz...
-
[8]
As speech and audio research scales in data, model, language, and research styles, en- gineering overhead has become a critical constraint on research productivity
Conclusion In this paper, we present ESPnet3, a redesigned speech and audio research framework that addresses system-level bottlenecks that emerge in large-scale speech modeling. As speech and audio research scales in data, model, language, and research styles, en- gineering overhead has become a critical constraint on research productivity. ESPnet3 adopt...
-
[9]
Authors take full responsibility for the content
Generative AI Use Disclosure Generative AI tools have been used to help revise and refine the manuscript. Authors take full responsibility for the content
-
[10]
Linguistics, Artificial Intelligence and Lan- guage and Speech Technologies: from Research to Applications
Acknowledgements Experiments of this work used the Bridges2 system at PSC and Delta and DeltaAI system at NCSA through allocations CIS210014 and IRI120008P from the Advanced Cyberinfrastruc- ture Coordination Ecosystem: Services & Support (ACCESS) program, supported by National Science Foundation grants #2138259,#:2138286, #:2138307, #:2137603, and #:2138...
-
[11]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 28 492–28 518
2023
-
[12]
Google USM: Scaling automatic speech recognition beyond 100 languages,
Y . Zhang, W. Han, J. Qin, Y . Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V . Axelrod, G. Wang, Z. Meng, K. Hu, A. Rosenberg, R. Prabhavalkar, D. S. Park, P. Haghani, J. Riesa, G. Perng, H. Soltau, T. Strohman, B. Ramabhadran, T. Sainath, P. Moreno, C.-C. Chiu, J. Schalkwyk, F. Beaufays, and Y . Wu, “Google USM: Scaling automatic speech recognition beyond 1...
arXiv 2023
-
[13]
Moshi: a speech-text foundation model for real-time dialogue,
A. Défossez, L. Mazaré, M. Orsini, A. Royer, P. Pérez, H. Jégou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,” 2024
2024
-
[14]
Seam- less: Multilingual expressive and streaming speech translation,
Seamless Communication, B. Loïc, C. Yu-An, M. Mariano Co- ria, D. David, D. Ning, D. Mark, D. Paul-Ambroise, E. Brian, E. Hady, H. Justin, H. John, H. Min-Jae, I. Hirofumi, K. Christo- pher, K. Ilia, L. Pengwei, L. Daniel, M. Jean, M. Ruslan, R. Alice, S. Kaushik Ram, R. Abinesh, T. Tuan, W. Guillaume, Y . Yilin, Y . Ethan, E. Ivan, F. Pierre, G. Cynthia,...
2023
-
[15]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann, J. R. Lee, Y . T. Lee, Y . Li, W. Liu, C. C. T. Mendes, A. Nguyen, E. Price, G. de Rosa, O. Saarikivi, A. Salim, S. Shah, X. Wang, R. Ward, Y . Wu, D. Yu, C. Zhang, and Y . Zhang, “Phi-4 technical report,” arXiv preprint arXiv:2412.08905, 2024
Pith/arXiv arXiv 2024
-
[16]
S. Xian, W. Xiong, G. Zhifang, W. Yongqi, Z. Pei, Z. Xinyu, G. Zishan, H. Hongkun, X. Yu, Y . Baosong, X. Jin, Z. Jingren, and L. Junyang, “Qwen3-ASR technical report,”arXiv preprint arXiv:2601.21337, 2026
Pith/arXiv arXiv 2026
-
[17]
OWSM v4: Improving Open Whisper-Style Speech Models via Data Scaling and Cleaning,
Y . Peng, M. Shakeel, Y . Sudo, W. Chen, J. Tian, C.-J. Lin, and S. Watanabe, “OWSM v4: Improving Open Whisper-Style Speech Models via Data Scaling and Cleaning,” inProc. Interspeech, 2025
2025
-
[18]
YuE: Scaling open foundation models for long-form music generation,
R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y . Zang, H. Liu, Y . Liang, W. Ma, X. Du, X. Du, Z. Ye, T. Zheng, Z. Jiang, Y . Ma, M. Liu, Z. Tian, Z. Zhou, L. Xue, X. Qu, Y . Li, S. Wu, T. Shen, Z. Ma, J. Zhan, C. Wang, Y . Wang, X. Chi, X. Zhang, Z. Yang, X. Wang, S. Liu, L. Mei, P. Li, J. Wang, J. Yu, G. Pang, X. Li, Z. Wang, X. Zhou, L. Yu, E. Benetos, Y...
2025
-
[19]
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities,
G. Saon, A. Dekel, A. Brooks, T. Nagano, A. Daniels, A. Satt, A. Mittal, B. Kingsbury, D. Haws, E. Morais, G. Kurata, H. Aronowitz, I. Ibrahim, J. Kuo, K. Soule, L. Lastras, M. Suzuki, R. Hoory, S. Thomas, S. Novitasari, T. Fukuda, V . Sunder, X. Cui, and Z. Kons, “Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities,”arXiv p...
arXiv 2025
-
[20]
Qwen-Audio: Advancing universal audio understanding via unified large-scale audio-language models,
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-Audio: Advancing universal audio understanding via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
Pith/arXiv arXiv 2023
-
[21]
Kimi-Audio technical report,
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
2025
-
[22]
Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,
S. Ghosh, A. Goel, J. Kim, S. Kumar, Z. Kong, S. gil Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,” inThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems, 2025
2025
-
[23]
Step-audio 2 technical report,
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Li, M. Chen, P. Liu, W. You, X. T. Zhang, X. Li, X. Yang, Y . Deng, Y . Huang, Y . Li, Y . Zhang, Z. You, B. Li, C. Wan, H. Hu, J. Zhen, S. Chen, S. Yuan, X. Zhang, Y . Jiang, Y . Zhou, Y . Yang, B. Li, B. Ma, C. Song, D. Pang, G. Hu, H. Sun, K. An, N. Wang, S. Gao, W. Ji, W. Li, ...
2025
-
[24]
OWLS: Scaling laws for multilingual speech recognition and translation models,
W. Chen, J. Tian, Y . Peng, B. Yan, C.-H. H. Yang, and S. Watan- abe, “OWLS: Scaling laws for multilingual speech recognition and translation models,” inForty-second International Conference on Machine Learning, 2025
2025
-
[25]
Bagpiper: Solving open-ended audio tasks via rich captions,
J. Tian, H. Wang, B.-H. Su, C. yu Huang, Q. Wang, J. Shi, W. Chen, X. Gong, S. Arora, C.-J. Li, M. Someki, T. Maekaku, Y . Shino- hara, J. Sakuma, C.-H. H. Yang, and S. Watanabe, “Bagpiper: Solving open-ended audio tasks via rich captions,”arXiv preprint arXiv:2602.05220, 2026
Pith/arXiv arXiv 2026
-
[26]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandi, A. Baevski, Y . Adi, X. Zhang, W.-N. Hsu, A. Conneau, and M. Auli, “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Research, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[27]
Towards robust speech representation learning for thousands of languages,
W. Chen, W. Zhang, Y . Peng, X. Li, J. Tian, J. Shi, X. Chang, S. Maiti, K. Livescu, and S. Watanabe, “Towards robust speech representation learning for thousands of languages,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024
2024
-
[28]
ESPnet-SDS: Unified toolkit and demo for spo- ken dialogue systems,
S. Arora, Y . Peng, J. Shi, J. Tian, W. Chen, S. Bharadwaj, H. Fu- tami, Y . Kashiwagi, E. Tsunoo, S. Shimizu, V . Srivastav, and S. Watanabe, “ESPnet-SDS: Unified toolkit and demo for spo- ken dialogue systems,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com- putational Linguistics: Human Language T...
2025
-
[29]
The university of cambridge system for the chime-7 dasr task,
K. Deng, X. Zheng, and P. Woodland, “The university of cambridge system for the chime-7 dasr task,”Proc. CHiME, pp. 73–76, 2023
2023
-
[30]
NOTSOFAR-1 Challenge: New Datasets, Base- line, and Tasks for Distant Meeting Transcription,
A. Vinnikov, A. Ivry, A. Hurvitz, I. Abramovski, S. Koubi, I. Gur- vich, S. Peer, X. Xiao, B. M. Elizalde, N. Kanda, X. Wang, S. Shaer, S. Yagev, Y . Asher, S. Sivasankaran, Y . Gong, M. Tang, H. Wang, and E. Krupka, “NOTSOFAR-1 Challenge: New Datasets, Base- line, and Tasks for Distant Meeting Transcription,” inInterspeech 2024, 2024, pp. 5003–5007
2024
-
[31]
Module-based end-to-end distant speech processing: A case study of far-field automatic speech recognition,
X. Chang, S. Watanabe, M. Delcroix, T. Ochiai, W. Zhang, and Y . Qian, “Module-based end-to-end distant speech processing: A case study of far-field automatic speech recognition,”IEEE Signal Processing Magazine, vol. 41, no. 6, pp. 39–50, 2024
2024
-
[32]
Accurate speaker count- ing, diarization and separation for advanced recognition of mul- tichannel multispeaker conversations,
A. Mitrofanov, T. Prisyach, T. Timofeeva, S. Novoselov, M. Ko- renevsky, Y . Khokhlov, A. Akulov, A. Anikin, R. Khalili, I. Lezhenin, A. Melnikov, D. Miroshnichenko, N. Mamaev, I. Ode- gov, O. Rudnitskaya, and A. Romanenko, “Accurate speaker count- ing, diarization and separation for advanced recognition of mul- tichannel multispeaker conversations,”Compu...
2025
-
[33]
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge,
N. Kamo, N. Tawara, A. Ando, T. Kano, H. Sato, R. Ikeshita, T. Moriya, S. Horiguchi, K. Matsuura, A. Ogawa, A. Plaquet, T. Ashihara, T. Ochiai, M. Mimura, M. Delcroix, T. Nakatani, T. Asami, and S. Araki, “NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge,” in8th International Work- shop on Speech Processing in Everyday Environments (CHi...
2024
-
[34]
The iacas-thinkit system for chime-7 challenge,
L. Ye, H. Lu, G. Cheng, Y . Chen, Z. Shang, and X. Li, “The iacas-thinkit system for chime-7 challenge,”Proc. CHiME, 2023
2023
-
[35]
The USTC-NERCSLIP systems for the CHiME-7 DASR challenge,
R. Wang, M. He, J. Du, H. Zhou, S. Niu, H. Chen, Y . Yue, G. Yang, S. Wu, L. Sunet al., “The USTC-NERCSLIP systems for the CHiME-7 DASR challenge,” 2023
2023
-
[36]
ESPnet: End-to-end speech processing toolkit,
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” inProc. Interspeech, 2018, pp. 2207–2211
2018
-
[37]
fairseq: A fast, extensible toolkit for sequence modeling,
M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grangier, and M. Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), W. Ammar, A. Louis, and N. Mostafazadeh, Eds. Minneapolis, Minnesota: Associatio...
2019
-
[38]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of-the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Met...
2020
-
[39]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Repre- sentations, 2022
2022
-
[40]
ESPnet-EZ: Python-only ESPnet for easy fine-tuning and integration,
M. Someki, K. Choi, S. Arora, W. Chen, S. Cornell, J. Han, Y . Peng, J. Shi, V . Srivastav, and S. Watanabe, “ESPnet-EZ: Python-only ESPnet for easy fine-tuning and integration,” in2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 863–870
2024
-
[41]
Conformer: Convolution- augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution- augmented Transformer for Speech Recognition,” inProc. Inter- speech, 2020, pp. 5036–5040
2020
-
[42]
E-Branchformer: Branchformer with enhanced merging for speech recognition,
K. Kim, F. Wu, Y . Peng, J. Pan, P. Sridhar, K. J. Han, and S. Watan- abe, “E-Branchformer: Branchformer with enhanced merging for speech recognition,” in2022 IEEE Spoken Language Technology Workshop (SLT), 2023, pp. 84–91
2023
-
[43]
Hydra - a framework for elegantly configuring complex applications,
O. Yadan, “Hydra - a framework for elegantly configuring complex applications,” Github, 2019. [Online]. Available: https://github.com/facebookresearch/hydra
2019
-
[44]
VERSA: A versatile evaluation toolkit for speech, audio, and music,
J. Shi, H. jin Shim, J. Tian, S. Arora, H. Wu, D. Petermann, J. Q. Yip, Y . Zhang, Y . Tang, W. Zhang, D. S. Alharthi, Y . Huang, K. Saito, J. Han, Y . Zhao, C. Donahue, and S. Watanabe, “VERSA: A versatile evaluation toolkit for speech, audio, and music,” in2025 Annual Conference of the North American Chapter of the Association for Computational Linguist...
2025
-
[45]
The Kaldi speech recogni- tion toolkit,
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y . Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely, “The Kaldi speech recogni- tion toolkit,” inIEEE 2011 Workshop on Automatic Speech Recog- nition and Understanding, 2011
2011
-
[46]
NeMo: a toolkit for conversational AI and large language models
E. Harper, S. Majumdar, O. Kuchaiev, L. Jason, Y . Zhang, E. Bakh- turina, V . Noroozi, S. Subramanian, K. Nithin, H. Jocelyn, F. Jia, J. Balam, X. Yang, M. Livne, Y . Dong, S. Naren, and B. Ginsburg, “NeMo: a toolkit for conversational AI and large language models.”
-
[47]
SpeechBrain: A general-purpose speech toolkit,
M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y . Gao, R. D. Mori, and Y . Bengio, “SpeechBrain: A general-purpose speech toolkit,”arXiv preprint arXiv:2106.04624, 2021
arXiv 2021
-
[48]
Open-source conversational AI with SpeechBrain 1.0,
M. Ravanelli, T. Parcollet, A. Moumen, S. de Langen, C. Subakan, P. Plantinga, Y . Wang, P. Mousavi, L. D. Libera, A. Ploujnikov, F. Paissan, D. Borra, S. Zaiem, Z. Zhao, S. Zhang, G. Karakasidis, S.-L. Yeh, P. Champion, A. Rouhe, R. Braun, F. Mai, J. Zuluaga- Gomez, S. M. Mousavi, A. Nautsch, H. Nguyen, X. Liu, S. Sagar, J. Duret, S. Mdhaffar, G. Laperri...
2024
-
[49]
An analysis of environment, microphone and data simulation mismatches in robust speech recognition,
E. Vincent, S. Watanabe, A. A. Nugraha, J. Barker, and R. Marxer, “An analysis of environment, microphone and data simulation mismatches in robust speech recognition,”Comput. Speech Lang., vol. 46, no. C, p. 535–557, Nov. 2017. [Online]. Available: https://doi.org/10.1016/j.csl.2016.11.005
-
[50]
FalAR: A large-scale speaker-annotated European Portuguese speech cor- pus of parliamentary sessions,
F. Teixeira, C. Carvalho, M. Julião, C. Botelho, R. Solera-Ureña, S. Paulo, T. Rolland, B. Peters, I. Trancoso, and A. Abad, “FalAR: A large-scale speaker-annotated European Portuguese speech cor- pus of parliamentary sessions,” inProceedings of the 15th Interna- tional Conference on Language Resources and Evaluation (LREC 2026), 2026
2026
-
[51]
CAMÕES: A Comprehensive Automatic Speech Recogni- tion Benchmark for European Portuguese,
C. Carlos, T. Francisco, B. Catarina, P. Anna, S.-U. Rubén, P. Sér- gio, J. Mariana, R. Thomas, M. John, P. Diogo, T. Isabel, and A. Al- berto, “CAMÕES: A Comprehensive Automatic Speech Recogni- tion Benchmark for European Portuguese,” inProceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.