Nonparametric Deconvolution and Denoising using Simulation Based Inference
Pith reviewed 2026-06-26 12:03 UTC · model grok-4.3
The pith
A likelihood-free framework uses convolutional MMD to recover latent densities and denoise signals from additive noise via simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
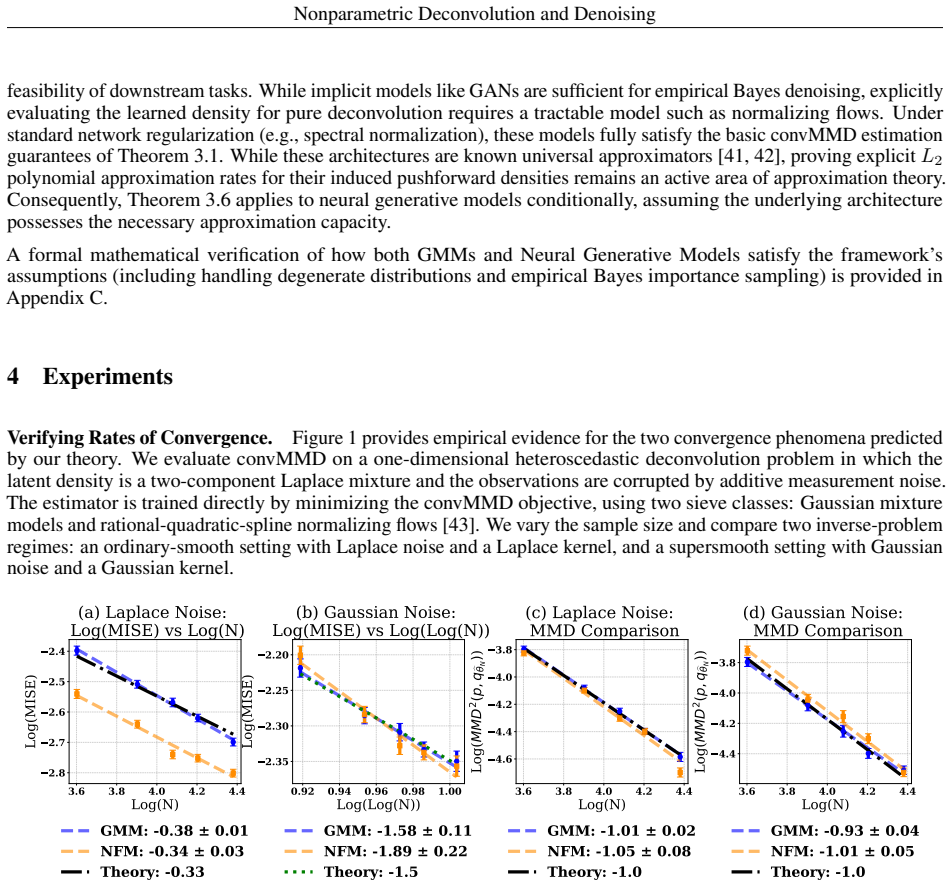
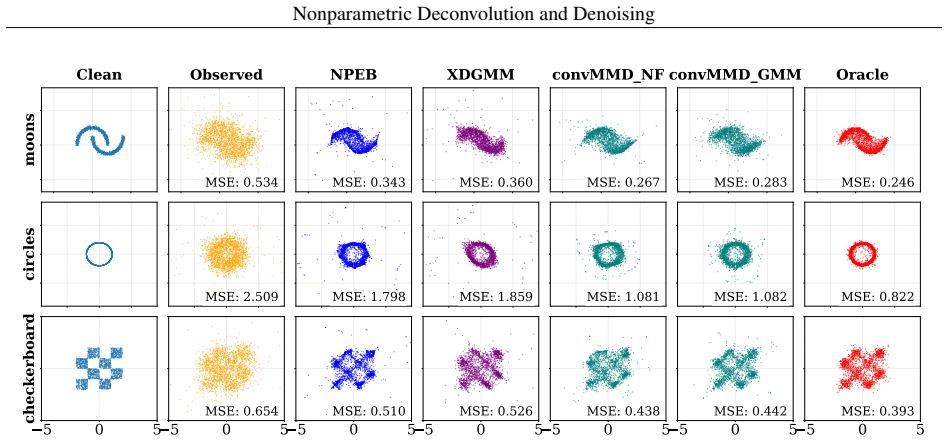
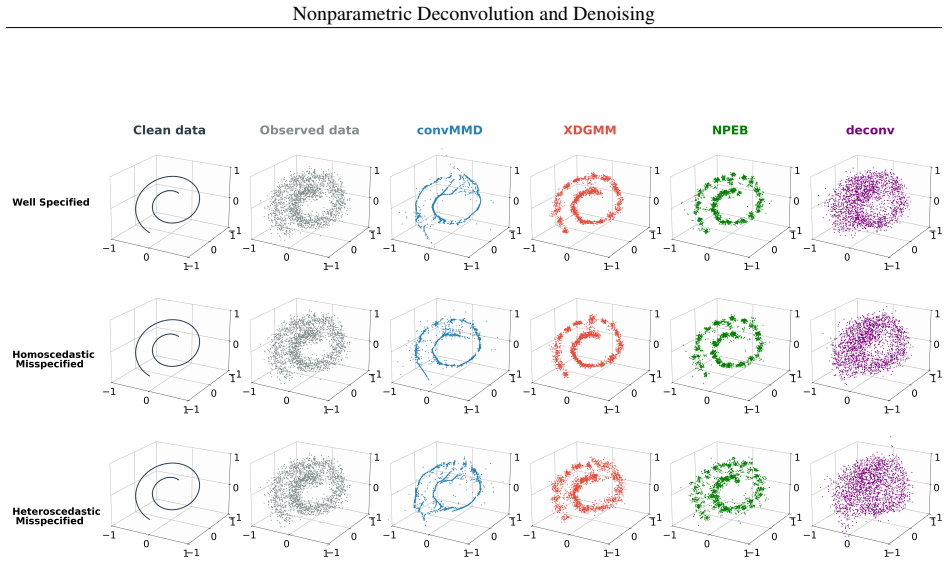
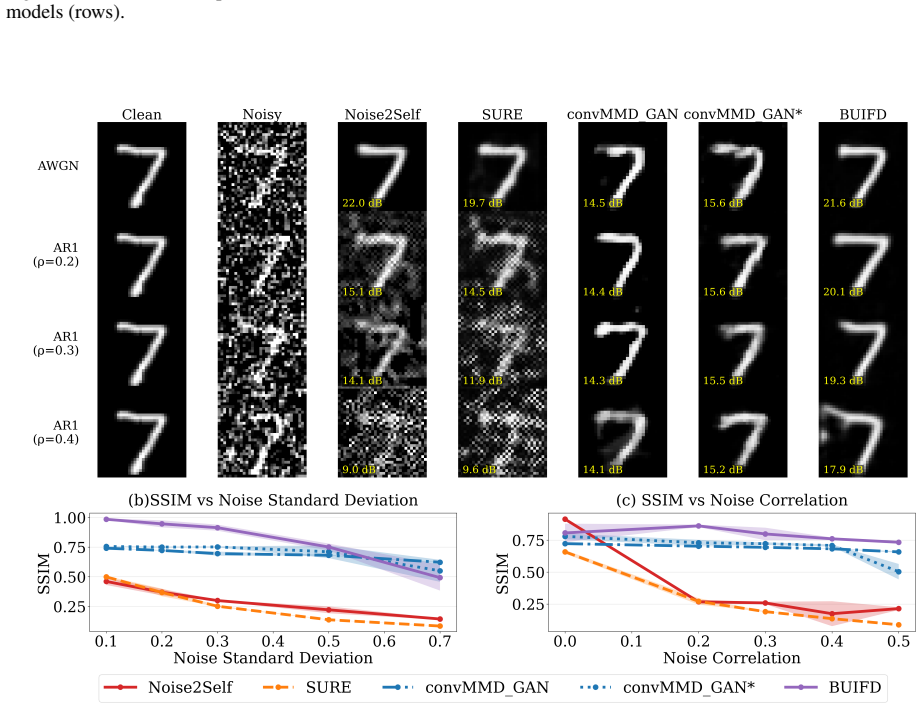
The authors claim that a convolutional maximum mean discrepancy loss yields a differentiable, simulation-based objective for learning a latent generative model by matching the observed data distribution to the noise-convolved model distribution. This framework performs nonparametric density deconvolution and empirical Bayes denoising for homoscedastic or heteroscedastic multivariate noise. They extend convMMD to nonparametric estimation, proving finite-sample bounds for empirical sieve minimizers and L2 convergence rates under Sobolev smoothness that recover polynomial rates for ordinary-smooth noise and logarithmic rates for super-smooth noise.
What carries the argument
The convMMD loss, which measures discrepancy between the empirical distribution of noisy observations and the distribution of a candidate latent density after convolution with the known noise.
If this is right
- The learned density serves as an empirical prior for posterior denoising of individual latent values.
- The approach is compatible with sieve classes such as Gaussian mixtures and normalizing flows.
- It applies to both homoscedastic and heteroscedastic multivariate noise.
- Convergence rates are polynomial for ordinary-smooth noise and logarithmic for super-smooth noise.
Where Pith is reading between the lines
- The simulation requirement could support extensions to settings where the noise distribution is only approximately known but still simulatable.
- Integration with high-capacity deep generative models might enable scaling to higher-dimensional latent spaces beyond the sieve classes considered.
- The framework's reliance on convolution suggests it may inform other inverse problems where forward simulation is easier than likelihood evaluation.
Load-bearing premise
The measurement noise must be additive with a known distribution that can be accurately simulated or convolved with the latent model.
What would settle it
A Monte Carlo experiment in which the estimated latent density fails to converge in L2 norm to the true density at the predicted rate as the number of observations increases, when the latent density satisfies the assumed Sobolev smoothness and the noise is ordinary-smooth.
Figures
read the original abstract
Latent signals are often obscured by measurement noise, yet encode the underlying laws and dynamics of complex systems; learning both the signals and their distributions remains a central challenge in scientific inference. The noise is often non-negligible, and the likelihoods for expressive generative models are often intractable. We utilize a convolutional maximum mean discrepancy (convMMD) loss and propose a likelihood-free framework for nonparametric density deconvolution and empirical Bayes denoising under additive measurement error. Our method learns a latent generative model by matching the observed data distribution to the noise-convolved model distribution. This yields a differentiable, simulation-based objective for multivariate homoscedastic or heteroscedastic noise, compatible with expressive sieve classes such as Gaussian mixtures and normalizing flows. The learned density then serves as an empirical prior for posterior denoising of individual latent values. Theoretically, we extend convMMD from parametric to nonparametric estimation, proving finite-sample bounds for empirical sieve minimizers and $L_2$ convergence rates under Sobolev smoothness. These rates recover the classical inverse-problem dependence: polynomial for ordinary-smooth and logarithmic for super-smooth noises. Our method provides a practical, theoretically grounded approach to deconvolution and denoising under generative latent distribution models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a likelihood-free nonparametric framework for density deconvolution and empirical Bayes denoising under additive measurement error. It employs a convolutional maximum mean discrepancy (convMMD) loss to match the observed data distribution to the noise-convolved latent generative model distribution, supporting sieve classes such as Gaussian mixtures and normalizing flows. The learned density serves as an empirical prior for posterior denoising. Theoretically, the work extends convMMD to nonparametric estimation by proving finite-sample bounds for empirical sieve minimizers and L2 convergence rates under Sobolev smoothness, with rates that recover the classical inverse-problem dependence (polynomial for ordinary-smooth noise, logarithmic for super-smooth noise).
Significance. If the theoretical results hold, the contribution is significant as it provides a simulation-based approach to nonparametric inverse problems with explicit finite-sample and rate guarantees that align with known minimax behavior in deconvolution. The method's compatibility with expressive generative models and heteroscedastic noise, combined with the likelihood-free objective, addresses a practical gap in scientific inference where likelihoods are intractable.
major comments (2)
- [Abstract] Abstract: The central claim that finite-sample bounds for empirical sieve minimizers and L2 convergence rates under Sobolev smoothness are proved, recovering classical inverse-problem rates, is load-bearing. However, the abstract provides no statement of the required assumptions on the sieve class, the kernel, or the noise convolution operator, preventing assessment of whether the extension from parametric to nonparametric convMMD is valid.
- [Method description] Method description (as summarized): The simulation-based objective requires that the additive noise distribution is known and can be accurately simulated or convolved with the latent model. This assumption is load-bearing for consistency of the density estimator; the manuscript should explicitly address robustness when the noise is only approximately known, as this directly impacts the claimed convergence rates.
minor comments (1)
- [Notation] Clarify notation for the multivariate convMMD kernel and how the convolution is implemented in the objective for heteroscedastic noise.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that finite-sample bounds for empirical sieve minimizers and L2 convergence rates under Sobolev smoothness are proved, recovering classical inverse-problem rates, is load-bearing. However, the abstract provides no statement of the required assumptions on the sieve class, the kernel, or the noise convolution operator, preventing assessment of whether the extension from parametric to nonparametric convMMD is valid.
Authors: We agree that the abstract would benefit from a brief statement of the key assumptions to clarify the scope of the theoretical claims. The full paper states these in the theorem statements and proofs (characteristic kernel, sieve with sufficient approximation capacity for the Sobolev ball, and standard smoothness conditions on the convolution operator for ordinary- and super-smooth noise). We will revise the abstract to note that the results hold under these standard assumptions on the kernel, sieve, and noise operator. revision: yes
-
Referee: [Method description] Method description (as summarized): The simulation-based objective requires that the additive noise distribution is known and can be accurately simulated or convolved with the latent model. This assumption is load-bearing for consistency of the density estimator; the manuscript should explicitly address robustness when the noise is only approximately known, as this directly impacts the claimed convergence rates.
Authors: The method assumes the noise distribution is known and simulatable, which is standard for simulation-based deconvolution to ensure the convMMD objective is well-defined. We will add a dedicated remark or subsection discussing robustness to approximate noise knowledge, including how misspecification affects consistency and rates, along with practical guidance on sensitivity analysis. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation relies on a simulation-based convMMD objective that explicitly convolves or simulates from a known additive noise distribution to match the observed data distribution, then applies standard sieve estimation theory to obtain finite-sample bounds and Sobolev L2 rates. These steps are conditioned on external, simulatable inputs and classical inverse-problem analysis rather than any self-referential fit, prediction-by-construction, or load-bearing self-citation. The central claims remain independent of the target results.
Axiom & Free-Parameter Ledger
free parameters (1)
- sieve complexity
axioms (1)
- domain assumption Additive measurement error with known noise distribution
Reference graph
Works this paper leans on
-
[1]
Chapman and Hall/CRC, 2006
Raymond J Carroll, David Ruppert, Leonard A Stefanski, and Ciprian M Crainiceanu.Measurement error in nonlinear models: a modern perspective. Chapman and Hall/CRC, 2006
2006
-
[2]
Deconvolution in astronomy: A review.Publications of the Astronomical Society of the Pacific, 114:1051–1069, 2002
Jean-Luc Starck, Eric Pantin, and Fionn Murtagh. Deconvolution in astronomy: A review.Publications of the Astronomical Society of the Pacific, 114:1051–1069, 2002
2002
-
[3]
Visal Sok, Adam Muzzin, Pascale Jablonka, Z Cemile Marsan, Vivian YY Tan, Leo Alcorn, Danilo Marchesini, and Mauro Stefanon. Finite-resolution deconvolution of multiwavelength imaging of 20,000 galaxies in the cosmos field: The evolution of clumpy galaxies over cosmic time.The Astrophysical Journal, 924:7, 2022
2022
-
[4]
The decade cosmic shear project i: A new weak lensing shape catalog of 107 million galaxies
D Anbajagane, C Chang, Z Zhang, CY Tan, M Adamow, LF Secco, MR Becker, PS Ferguson, A Drlica-Wagner, RA Gruendl, et al. The decade cosmic shear project i: A new weak lensing shape catalog of 107 million galaxies. arXiv preprint arXiv:2502.17674, 2025
arXiv 2025
-
[5]
Weak lensing shear calibration with simulations of the hsc survey.Monthly Notices of the Royal Astronomical Society, 481:3170–3195, 2018
Rachel Mandelbaum, François Lanusse, Alexie Leauthaud, Robert Armstrong, Melanie Simet, Hironao Miyatake, Joshua E Meyers, James Bosch, Ryoma Murata, Satoshi Miyazaki, et al. Weak lensing shear calibration with simulations of the hsc survey.Monthly Notices of the Royal Astronomical Society, 481:3170–3195, 2018
2018
-
[6]
Eddington’s demon: inferring galaxy mass functions and other distributions from uncertain data.Monthly Notices of the Royal Astronomical Society, 474:5500–5522, 2018
Danail Obreschkow, Steven G Murray, Aaron SG Robotham, and Tobias Westmeier. Eddington’s demon: inferring galaxy mass functions and other distributions from uncertain data.Monthly Notices of the Royal Astronomical Society, 474:5500–5522, 2018
2018
-
[7]
Measurement error and the replication crisis.Science, 355:584–585, 2017
Eric Loken and Andrew Gelman. Measurement error and the replication crisis.Science, 355:584–585, 2017
2017
-
[8]
Bayesian-based iterative method of image restoration.Journal of the Optical Society of America, 62:55–59, 1972
William Hadley Richardson. Bayesian-based iterative method of image restoration.Journal of the Optical Society of America, 62:55–59, 1972
1972
-
[9]
An iterative technique for the rectification of observed distributions.Astronomical Journal, 79:745, 1974
Leon B Lucy. An iterative technique for the rectification of observed distributions.Astronomical Journal, 79:745, 1974
1974
-
[10]
A deep generative deconvolutional image model
Yunchen Pu, Win Yuan, Andrew Stevens, Chunyuan Li, and Lawrence Carin. A deep generative deconvolutional image model. InArtificial Intelligence and Statistics, pages 741–750. PMLR, 2016
2016
-
[11]
Digital image reconstruction: Deblurring and denoising.Annual Review of Astronomy and Astrophysics, 43:139–194, 2005
RC Puetter, TR Gosnell, and Amos Yahil. Digital image reconstruction: Deblurring and denoising.Annual Review of Astronomy and Astrophysics, 43:139–194, 2005
2005
-
[12]
Density deconvolution with normalizing flows
Tim Dockhorn, James A Ritchie, Yaoliang Yu, and Iain Murray. Density deconvolution with normalizing flows. arXiv preprint arXiv:2006.09396, 2020
arXiv 2006
-
[13]
Machines learn to infer stellar parameters just by looking at a large number of spectra.Monthly Notices of the Royal Astronomical Society, 501(4):6026–6041, 2021
Nima Sedaghat, Martino Romaniello, Jonathan E Carrick, and François-Xavier Pineau. Machines learn to infer stellar parameters just by looking at a large number of spectra.Monthly Notices of the Royal Astronomical Society, 501(4):6026–6041, 2021
2021
-
[14]
Data denoising with transfer learning in single-cell transcriptomics.Nature methods, 16(9):875–878, 2019
Jingshu Wang, Divyansh Agarwal, Mo Huang, Gang Hu, Zilu Zhou, Chengzhong Ye, and Nancy R Zhang. Data denoising with transfer learning in single-cell transcriptomics.Nature methods, 16(9):875–878, 2019
2019
-
[15]
Hyperspectral image denoising: From model-driven, data-driven, to model-data-driven.IEEE Transactions on Neural Networks and Learning Systems, 35(10):13143–13163, 2023
Qiang Zhang, Yaming Zheng, Qiangqiang Yuan, Meiping Song, Haoyang Yu, and Yi Xiao. Hyperspectral image denoising: From model-driven, data-driven, to model-data-driven.IEEE Transactions on Neural Networks and Learning Systems, 35(10):13143–13163, 2023
2023
-
[16]
Optimal rates of convergence for deconvolving a density.Journal of the American Statistical Association, 83:1184–1186, 1988
Raymond J Carroll and Peter Hall. Optimal rates of convergence for deconvolving a density.Journal of the American Statistical Association, 83:1184–1186, 1988
1988
-
[17]
A consistent nonparametric density estimator for the deconvolution problem
Ming Chung Liu and Robert L Taylor. A consistent nonparametric density estimator for the deconvolution problem. Canadian Journal of Statistics, 17:427–438, 1989
1989
-
[18]
Deconvolving kernel density estimators.Statistics, 21:169–184, 1990
Leonard A Stefanski and Raymond J Carroll. Deconvolving kernel density estimators.Statistics, 21:169–184, 1990
1990
-
[19]
On the optimal rates of convergence for nonparametric deconvolution problems.Annals of Statistics, 19:1257–1272, 1991
Jianqing Fan. On the optimal rates of convergence for nonparametric deconvolution problems.Annals of Statistics, 19:1257–1272, 1991
1991
-
[20]
Density estimation with heteroscedastic error.Bernoulli, 14:562–579, 2008
Aurore Delaigle and Alexander Meister. Density estimation with heteroscedastic error.Bernoulli, 14:562–579, 2008
2008
-
[21]
Discrete-transform approach to deconvolution problems.Biometrika, 92:135–148, 2005
Peter Hall and Peihua Qiu. Discrete-transform approach to deconvolution problems.Biometrika, 92:135–148, 2005
2005
-
[22]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. InInternational Conference on Machine Learning, pages 1530–1538. PMLR, 2015. 11 Nonparametric Deconvolution and Denoising
2015
-
[23]
Glow: generative flow with invertible 1 × 1 convolutions
Diederik P Kingma and Prafulla Dhariwal. Glow: generative flow with invertible 1 × 1 convolutions. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 10236– 10245, 2018
2018
-
[24]
Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22:1–64, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22:1–64, 2021
2021
-
[25]
Stochastic forward–backward deconvolution: Training diffusion models with finite noisy datasets
Haoye Lu, Qifan Wu, and Yaoliang Yu. Stochastic forward–backward deconvolution: Training diffusion models with finite noisy datasets. InInternational Conference on Machine Learning, pages 40741–40768. PMLR, 2025
2025
-
[26]
Multivariate, heteroscedastic empirical Bayes via nonparametric maximum likelihood.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87:1–32, 2025
Jake A Soloff, Adityanand Guntuboyina, and Bodhisattva Sen. Multivariate, heteroscedastic empirical Bayes via nonparametric maximum likelihood.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87:1–32, 2025
2025
-
[27]
Extreme deconvolution: Inferring complete distribution functions from noisy, heterogeneous and incomplete observations.Annals of Applied Statistics, 5:1657–1677, 2011
Jo Bovy, David W Hogg, and Sam T Roweis. Extreme deconvolution: Inferring complete distribution functions from noisy, heterogeneous and incomplete observations.Annals of Applied Statistics, 5:1657–1677, 2011
2011
-
[28]
Ritwik Vashistha, Jeff M Phillips, Abhra Sarkar, and Arya Farahi. Convolutional maximum mean discrepancy for inference in noisy data.arXiv preprint arXiv:2604.12022, 2026
Pith/arXiv arXiv 2026
-
[29]
An empirical bayes approach to statistics
Herbert E Robbins. An empirical bayes approach to statistics. InBreakthroughs in Statistics: Foundations and Basic Theory, pages 388–394. Springer
-
[30]
Bayes, oracle bayes and empirical bayes.Statistical Science, 34:177–201, 2019
Bradley Efron. Bayes, oracle bayes and empirical bayes.Statistical Science, 34:177–201, 2019
2019
-
[31]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13:723–773, 2012
2012
-
[32]
Hilbert space embeddings and metrics on probability measures.Journal of Machine Learning Research, 11:1517–1561, 2010
Bharath K Sriperumbudur, Arthur Gretton, Kenji Fukumizu, Bernhard Schölkopf, and Gert RG Lanckriet. Hilbert space embeddings and metrics on probability measures.Journal of Machine Learning Research, 11:1517–1561, 2010
2010
-
[33]
Approximation and convergence properties of generative adversarial learning.Advances in Neural Information Processing Systems, 30, 2017
Shuang Liu, Olivier Bousquet, and Kamalika Chaudhuri. Approximation and convergence properties of generative adversarial learning.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[34]
Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106:1602– 1614, 2011
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106:1602– 1614, 2011
2011
-
[35]
Rates of convergence for the Gaussian mixture sieve.Annals of Statistics, 28:1105–1127, 2000
Christopher R Genovese and Larry Wasserman. Rates of convergence for the Gaussian mixture sieve.Annals of Statistics, 28:1105–1127, 2000
2000
-
[36]
Entropies and rates of convergence for maximum likelihood and Bayes estimation for mixtures of normal densities.Annals of Statistics, 29:1233–1263, 2001
Subhashis Ghosal and Aad W Van Der Vaart. Entropies and rates of convergence for maximum likelihood and Bayes estimation for mixtures of normal densities.Annals of Statistics, 29:1233–1263, 2001
2001
-
[37]
Generative adversarial nets
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InProceedings of the 28th International Conference on Neural Information Processing Systems-Volume 2, pages 2672–2680, 2014
2014
-
[38]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265. PMLR, 2015
2015
-
[39]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[40]
Score- based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[41]
Coupling- based invertible neural networks are universal diffeomorphism approximators.Advances in Neural Information Processing Systems, 33:3362–3373, 2020
Takeshi Teshima, Isao Ishikawa, Koichi Tojo, Kenta Oono, Masahiro Ikeda, and Masashi Sugiyama. Coupling- based invertible neural networks are universal diffeomorphism approximators.Advances in Neural Information Processing Systems, 33:3362–3373, 2020
2020
-
[42]
Multilayer feedforward networks are universal approxi- mators.Neural Networks, 2:359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approxi- mators.Neural Networks, 2:359–366, 1989
1989
-
[43]
Neural spline flows
Conor Durkan, Artur Bekasovs, Iain Murray, and George Papamakarios. Neural spline flows. In33rd Conference on Neural Information Processing Systems, pages 7511–7522. Neural Information Processing Systems Foundation, Inc, 2019
2019
-
[44]
Finite sample properties of parametric mmd estimation: robustness to misspecification and dependence.Bernoulli, 28(1):181–213, 2022
Badr-Eddine Chérief-Abdellatif and Pierre Alquier. Finite sample properties of parametric mmd estimation: robustness to misspecification and dependence.Bernoulli, 28(1):181–213, 2022. 12 Nonparametric Deconvolution and Denoising
2022
-
[45]
Universal robust regression via maximum mean discrepancy.Biometrika, 111(1):71–92, 2024
Pierre Alquier and Mathieu Gerber. Universal robust regression via maximum mean discrepancy.Biometrika, 111(1):71–92, 2024
2024
-
[46]
On the rate of convergence in Wasserstein distance of the empirical measure
Nicolas Fournier and Arnaud Guillin. On the rate of convergence in Wasserstein distance of the empirical measure. Probability Theory and Related Fields, 162:707–738, 2015
2015
-
[47]
MMD GAN: Towards deeper understanding of moment matching network.Advances in Neural Information Processing Systems, 30:1–11, 2017
Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. MMD GAN: Towards deeper understanding of moment matching network.Advances in Neural Information Processing Systems, 30:1–11, 2017
2017
-
[48]
Noise2self: Blind denoising by self-supervision
Joshua Batson and Loic Royer. Noise2self: Blind denoising by self-supervision. InInternational conference on machine learning, pages 524–533. PMLR, 2019
2019
-
[49]
Training deep learning based denoisers without ground truth data
Shakarim Soltanayev and Se Young Chun. Training deep learning based denoisers without ground truth data. Advances in neural information processing systems, 31, 2018
2018
-
[50]
Blind universal bayesian image denoising with gaussian noise level learning.IEEE Transactions on Image Processing, 29:4885–4897, 2020
Majed El Helou and Sabine Süsstrunk. Blind universal bayesian image denoising with gaussian noise level learning.IEEE Transactions on Image Processing, 29:4885–4897, 2020
2020
-
[51]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[52]
A review of image denoising algorithms, with a new one
Antoni Buades, Bartomeu Coll, and Jean-Michel Morel. A review of image denoising algorithms, with a new one. Multiscale Modeling & Simulation, 4:490–530, 2005
2005
-
[53]
Image denoising by sparse 3-d transform-domain collaborative filtering.IEEE Transactions on Image Processing, 16:2080–2095, 2007
Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering.IEEE Transactions on Image Processing, 16:2080–2095, 2007
2080
-
[54]
Taming diffusion models for image restoration: a review.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 383, 2025
Ziwei Luo, Fredrik Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas Schön. Taming diffusion models for image restoration: a review.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 383, 2025
2025
-
[55]
Spectral normalization for generative adversarial networks.arXiv preprint arXiv:1802.05957, 2018
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks.arXiv preprint arXiv:1802.05957, 2018
Pith/arXiv arXiv 2018
-
[56]
How well generative adversarial networks learn distributions.Journal of Machine Learning Research, 22:1–41, 2021
Tengyuan Liang. How well generative adversarial networks learn distributions.Journal of Machine Learning Research, 22:1–41, 2021
2021
-
[57]
Error bounds for approximations with deep ReLU networks.Neural Networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep ReLU networks.Neural Networks, 94:103–114, 2017
2017
-
[58]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016
2016
-
[59]
On the method of bounded differences.Surveys in Combinatorics, 141:148–188, 1989
Colin McDiarmid et al. On the method of bounded differences.Surveys in Combinatorics, 141:148–188, 1989
1989
-
[60]
McGraw Hill, 1974
Walter Rudin.Real and complex analysis. McGraw Hill, 1974
1974
-
[61]
Elsevier, 2003
Robert A Adams and John JF Fournier.Sobolev spaces. Elsevier, 2003
2003
-
[62]
John Wiley & Sons, 1999
Gerald B Folland.Real analysis: modern techniques and their applications. John Wiley & Sons, 1999
1999
-
[63]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations
-
[64]
Antonin Schrab. A practical introduction to kernel discrepancies: Mmd, hsic & ksd.arXiv preprint arXiv:2503.04820, 2025
arXiv 2025
-
[65]
Mmd-fuse: Learning and combining kernels for two-sample testing without data splitting.Advances in Neural Information Processing Systems, 36:75151–75188, 2023
Felix Biggs, Antonin Schrab, and Arthur Gretton. Mmd-fuse: Learning and combining kernels for two-sample testing without data splitting.Advances in Neural Information Processing Systems, 36:75151–75188, 2023. 13 Nonparametric Deconvolution and Denoising A Assumptions For clarity, we collect here all assumptions used in the paper. Theorems in the main text...
2023
-
[66]
Here, we verify the sensitivity of the learned prior and downstream denoising performance on bandwidth choice
This heuristic provides user with a principled data-driven default. Here, we verify the sensitivity of the learned prior and downstream denoising performance on bandwidth choice. Setup.We hold the full training procedure fixed and vary only a single multiplicative scale factor s∈ 0.10,0.25,0.50,0.75,1.00,1.50,2.00,3.00,5.00 applied uniformly to all nine b...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.