Wh0: Generative World Models as Scalable Sources of Egocentric Human Hand Manipulation Data
Pith reviewed 2026-06-26 11:46 UTC · model grok-4.3
The pith
A generative world model produces 50,000 egocentric human-hand videos that convert into robot supervision and raise zero-shot dexterous task success from 8.3 percent to 38.9 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
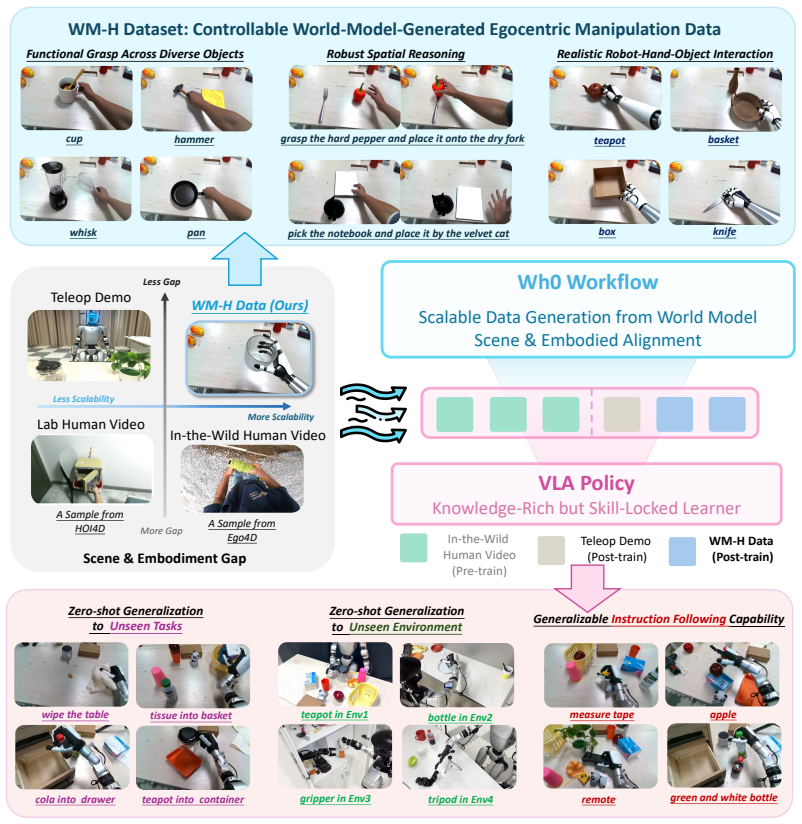
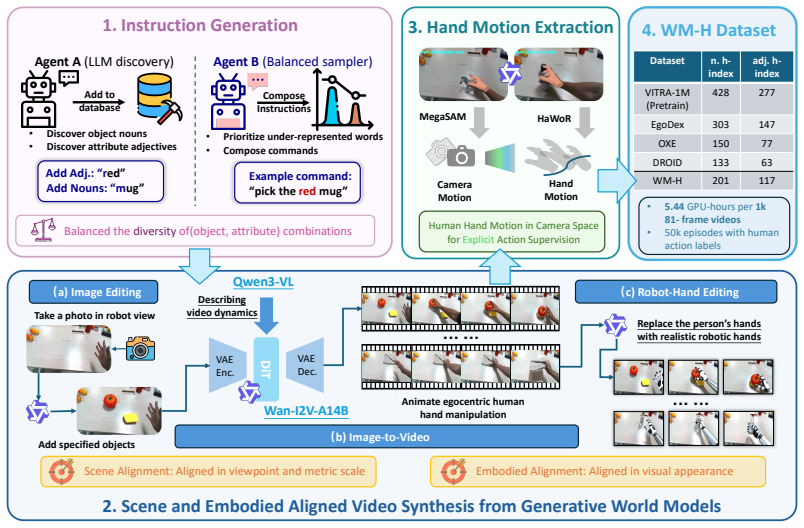
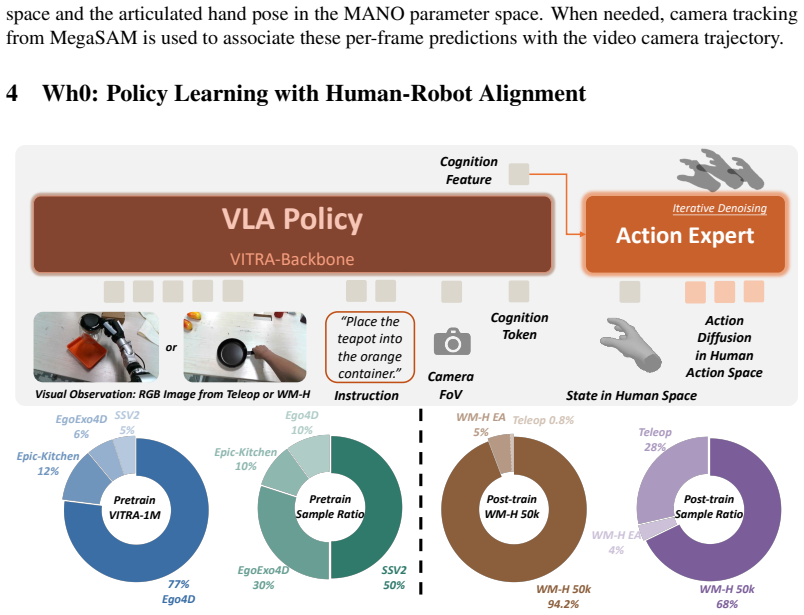
Conditioned on language, objects, and scenes, a generative world model yields the WM-H dataset of 50k egocentric human-object interaction videos; after hand motion reconstruction and visual editing, co-training with a small amount of real robot data adapts pretrained VLA models to dexterous manipulation, raising zero-shot success across 18 real-world tasks from 8.3 percent to 38.9 percent.
What carries the argument
Generative world model that outputs controllable WM-H videos, followed by hand motion reconstruction and visual editing to create robot-trainable supervision.
If this is right
- Pretrained VLA models gain dexterous capabilities from far less real-robot data once supplemented by the generated episodes.
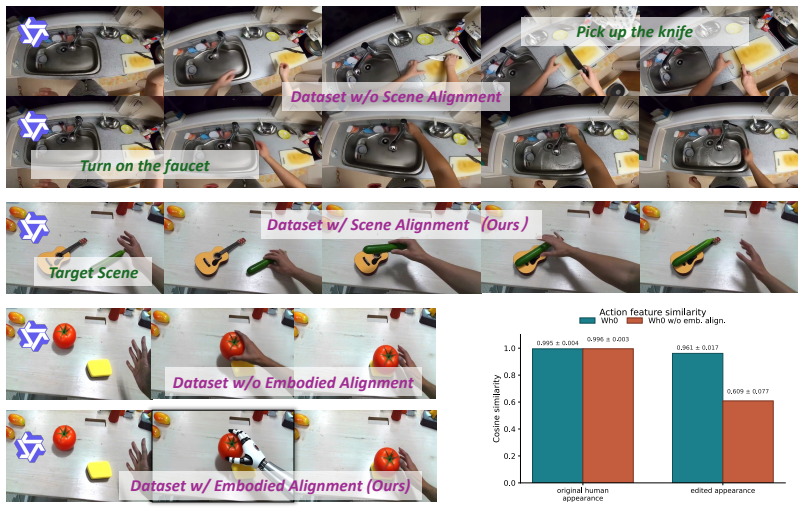
- Performance gains are driven by the combination of large-scale video generation and explicit scene/embodiment alignment steps.
- The method supports generalization across objects, scenes, and tasks that were previously limited by data scale or alignment.
- Ablations confirm that removing either scalable generation or alignment reduces the observed gains.
Where Pith is reading between the lines
- The same generative pipeline could be applied to other robot skills that currently lack large aligned datasets.
- If the world model can be further conditioned on robot-specific kinematics, the domain gap after editing might shrink even more.
- Open-sourcing the 50k-episode dataset and code allows direct measurement of how much additional real data is still required for target performance levels.
Load-bearing premise
Videos from the generative model, once reconstructed and edited, supply supervision aligned enough with real robot bodies that the resulting training signal transfers without large unmanageable domain gaps.
What would settle it
Retraining the same VLA models on the 18 tasks using only the robot data versus the combined robot-plus-WM-H data and finding no measurable difference in zero-shot success rates.
Figures






read the original abstract
Scaling dexterous manipulation requires generalization across objects, scenes, and tasks, yet existing data sources face a trade-off between scale and scene/embodiment alignment: teleoperation data is well aligned with robot deployment but expensive to collect; simulation is scalable but limited by the sim-to-real gap; and real egocentric videos scale effectively but remain misaligned with robot deployment. We propose Wh0, a framework that uses generative video world models as scalable and controllable sources of egocentric human-hand manipulation data to unlock the manipulation capabilities of pretrained dexterous VLA models. Conditioned on language, objects, and scenes, Wh0 uses a generative world model to produce WM-H, a 50k-episode dataset of egocentric human-object interaction videos. Wh0 then converts the generated videos into robot-trainable supervision through hand motion reconstruction and visual editing. Co-trained with a limited amount of real robot data, WM-H adapts pretrained VLA models to dexterous manipulation deployment. Across 18 real-world dexterous manipulation tasks, compared with a model post-trained only on robot data, Wh0 improves zero-shot success on unseen tasks from 8.3% to 38.9%. Ablation studies further show that scalable generation and scene/embodiment alignment are key drivers of performance gains. Videos and open-source code can be found on our project website: https://chenyt31.github.io/wh0.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Wh0, a framework that uses generative video world models conditioned on language, objects, and scenes to synthesize WM-H, a 50k-episode dataset of egocentric human hand manipulation videos. These videos are converted into robot supervision via hand motion reconstruction and visual editing, then co-trained with limited real robot data to adapt pretrained dexterous VLA models. The central empirical claim is that this yields a zero-shot success rate increase on 18 unseen real-world dexterous manipulation tasks from 8.3% (robot data only) to 38.9%, with ablations attributing gains to generation scale and scene/embodiment alignment. Open-source code and videos are provided.
Significance. If the alignment between converted WM-H data and real robot embodiment holds, the work offers a scalable alternative to teleoperation for dexterous manipulation data, addressing embodiment and sim-to-real gaps in VLA training. The open-source release of code and videos is a clear strength that supports reproducibility and further validation. The approach directly targets the scale-alignment trade-off highlighted in the abstract.
major comments (3)
- [Abstract] Abstract: The headline result (8.3% o 38.9% zero-shot success across 18 tasks) rests on the claim that hand motion reconstruction plus visual editing produces supervision whose distribution is sufficiently close to real robot trajectories; however, no reconstruction accuracy numbers, pose error statistics, or distribution-shift metrics (e.g., trajectory statistics or divergence measures) between WM-H and real robot data are supplied to support this.
- [Methods] Methods / conversion pipeline description: No controls or quantitative checks are reported for generative artifacts such as inconsistent physics, hand-pose hallucinations, or embodiment mismatches introduced during video generation and editing; these omissions are load-bearing because any systematic bias could inflate the reported delta without reflecting genuine generalization.
- [Ablation studies] Ablation studies: While the abstract states that ablations demonstrate the importance of scalable generation and alignment, the manuscript provides no details on how alignment was quantified or how the ablation controls isolate the contribution of the conversion step versus other factors.
minor comments (3)
- [Results] Results tables or figures reporting the 8.3% and 38.9% figures do not include error bars or confidence intervals, making it difficult to assess the reliability of the performance delta.
- The 18 tasks are referred to only as 'unseen' without a table or appendix listing task descriptions, object sets, or how they differ from any training distribution.
- Dataset validation details for WM-H (e.g., diversity metrics or human preference studies on generated video quality) are not mentioned.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that additional quantitative support for the data conversion pipeline would strengthen the manuscript and will revise accordingly to address each point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result (8.3% o 38.9% zero-shot success across 18 tasks) rests on the claim that hand motion reconstruction plus visual editing produces supervision whose distribution is sufficiently close to real robot trajectories; however, no reconstruction accuracy numbers, pose error statistics, or distribution-shift metrics (e.g., trajectory statistics or divergence measures) between WM-H and real robot data are supplied to support this.
Authors: We agree that direct quantitative metrics on reconstruction accuracy and distribution shift would provide stronger support for the central claim. In the revised version we will add a dedicated subsection reporting hand-pose reconstruction error statistics (using standard metrics from the hand-pose literature) together with trajectory-level comparisons (e.g., velocity histograms and KL divergence) between the converted WM-H data and the real-robot trajectories used in training. revision: yes
-
Referee: [Methods] Methods / conversion pipeline description: No controls or quantitative checks are reported for generative artifacts such as inconsistent physics, hand-pose hallucinations, or embodiment mismatches introduced during video generation and editing; these omissions are load-bearing because any systematic bias could inflate the reported delta without reflecting genuine generalization.
Authors: We acknowledge that explicit controls for generative artifacts are important. While the current manuscript uses downstream real-robot task success as the primary validation, we will add a new paragraph in the Methods section describing the artifact-filtering heuristics applied during dataset curation and will report simple quantitative checks (e.g., fraction of generations discarded for pose inconsistency and visual examples of retained vs. filtered frames). revision: yes
-
Referee: [Ablation studies] Ablation studies: While the abstract states that ablations demonstrate the importance of scalable generation and alignment, the manuscript provides no details on how alignment was quantified or how the ablation controls isolate the contribution of the conversion step versus other factors.
Authors: We will expand the Ablation studies section to clarify the alignment quantification (visual feature similarity and per-task success breakdowns) and to detail the experimental controls that isolate the conversion pipeline from generation scale. Additional ablation tables will be included to make these distinctions explicit. revision: yes
Circularity Check
No significant circularity; central result is independent empirical measurement
full rationale
The paper's headline claim is an empirical zero-shot success rate improvement (8.3% → 38.9%) measured on 18 separate real-world dexterous manipulation tasks. This evaluation uses physical robot deployment and is not obtained by fitting parameters to the generated WM-H data or by any self-referential equation. The conversion pipeline (hand motion reconstruction + visual editing) is presented as a preprocessing step whose output is then tested externally; no derivation reduces the reported metric to the input data by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Episode count (50k)
axioms (1)
- domain assumption Generative world models can produce controllable, realistic egocentric human-object interaction videos when conditioned on language, objects, and scenes.
invented entities (1)
-
WM-H dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, ...
2023
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. T. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Conference on Robot Learning, 6-9 November 202...
2024
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.CoRR, abs/2410.24164, 2024. 9
Pith/arXiv arXiv 2024
-
[5]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A. Cheng, X. Zou, Y . Fang, X. Cheng, R. Qiu, H. Yin, S. Liu, S. Han, Y . Lu, and X. Wang. Egovla: Learning vision-language-action models from egocentric human videos.CoRR, abs/2507.12440, 2025
Pith/arXiv arXiv 2025
-
[6]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.CoRR, abs/2505.11709, 2025
Pith/arXiv arXiv 2025
-
[7]
Q. Li, Y . Deng, Y . Liang, L. Luo, L. Zhou, C. Yao, L. Zeng, Z. Feng, H. Liang, S. Xu, Y . Zhang, X. Chen, H. Chen, L. Sun, D. Chen, J. Yang, and B. Guo. Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos.arXiv preprint arXiv:2510.21571, 2025
arXiv 2025
-
[8]
H. Luo, Y . Feng, W. Zhang, S. Zheng, Y . Wang, H. Yuan, J. Liu, C. Xu, Q. Jin, and Z. Lu. Being-h0: vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
arXiv 2025
-
[9]
H. Luo, Y . Wang, W. Zhang, S. Zheng, Z. Xi, C. Xu, H. Xu, H. Yuan, C. Zhang, Y . Wang, et al. Being-h0. 5: Scaling human-centric robot learning for cross-embodiment generalization. arXiv preprint arXiv:2601.12993, 2026
arXiv 2026
-
[10]
H. Luo, W. Zhang, Y . Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y . Fu, and Z. Lu. Being-h0. 7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
Pith/arXiv arXiv 2026
-
[11]
A. Gavryushin, X. Wang, R. J. Malate, C. Yang, D. Liconti, R. Zurbrügg, R. K. Katzschmann, and M. Pollefeys. Maple: Encoding dexterous robotic manipulation priors learned from ego- centric videos.arXiv preprint arXiv:2504.06084, 2025
arXiv 2025
-
[12]
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025
Pith/arXiv arXiv 2025
-
[13]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, V . Cartillier, Z. Chavis, A. Furnari, R. Girdhar, J. Ham- burger, H. Jiang, D. Kukreja, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu,...
2025
-
[14]
Y . Li, X. Wei, J. Luo, Y . Xiao, Y . Bai, G. Zhou, T. Zou, C. Gui, J. Wen, H. Zhang, et al. Egolive: A large-scale egocentric dataset from real-world human tasks.arXiv preprint arXiv:2604.23570, 2026
Pith/arXiv arXiv 2026
-
[15]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. InIEEE International Conference on Robotics and Automation, ICRA 2025, Atlanta, GA, USA, May 19-23, 2025, pages 13226– 13233. IEEE, 2025
2025
-
[16]
J. Shi, Z. Zhao, T. Wang, I. Pedroza, A. Luo, J. Wang, J. Ma, and D. Jayaraman. Zeromimic: Distilling robotic manipulation skills from web videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16939–16947. IEEE, 2025. 10
2025
-
[17]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. E. Wang, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B. Burgess-Limerick, B. Kim, B. Schölkopf...
2024
-
[18]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[19]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zur- brügg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[20]
R. Zhao, S. Xu, R. Jin, Y . Deng, Y . Tai, K. Jia, and G. Liu. Sim2real vla: Zero-shot generaliza- tion of synthesized skills to realistic manipulation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[21]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European conference on computer vision (ECCV), pages 720–736, 2018
2018
-
[22]
Wan Team, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 11
Pith/arXiv arXiv 2025
-
[23]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, D. Dworakowski, J. Fan, M. Fenzi, F. Ferroni, S. Fidler, D. Fox, S. Ge, Y . Ge, J. Gu, S. Gururani, E. He, J. Huang, J. S. Huffman, P. Jannaty, J. Jin, S. W. Kim, G. Klár, G. Lam, S. Lan, L. Leal-Taixé, A. Li, Z. Li, C. Lin, T. Lin, H. Ling, M. Liu, ...
Pith/arXiv arXiv 2025
-
[24]
Matsuo, Y
Y . Matsuo, Y . LeCun, M. Sahani, D. Precup, D. Silver, M. Sugiyama, E. Uchibe, and J. Mo- rimoto. Deep learning, reinforcement learning, and world models.Neural Networks, 152: 267–275, 2022
2022
-
[25]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-vla: A 3d vision-language-action generative world model. In R. Salakhutdinov, Z. Kolter, K. A. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, editors,Forty-first International Confer- ence on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceeding...
2024
-
[26]
R. G. Goswami, A. Bar, D. Fan, T. Yang, G. Zhou, P. Krishnamurthy, M. Rabbat, F. Khorrami, and Y . LeCun. World models can leverage human videos for dexterous manipulation.CoRR, abs/2512.13644, 2025
arXiv 2025
-
[27]
G. Lu, B. Jia, P. Li, Y . Chen, Z. Wang, Y . Tang, and S. Huang. Gwm: Towards scalable gaus- sian world models for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9263–9274, 2025
2025
-
[28]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y . Lin, L. Magne, A. Mandlekar, A. Narayan, Y . L. Tan, G. Wang, J. Wang, Q. Wang, Y . Xu, X. Zeng, K. Zheng, R. Zheng, M. Liu, L. Zettlemoyer, D. Fox, J. Kautz, S. Reed, Y . Zhu, and L. Fan. Dreamgen: Unlocking generalization in robot learning through neural trajectorie...
Pith/arXiv arXiv 2025
-
[29]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in Neural Information Processing Systems, 36:9156–9172, 2023
2023
-
[30]
H. Bharadhwaj, D. Dwibedi, A. Gupta, S. Tulsiani, C. Doersch, T. Xiao, D. Shah, F. Xia, D. Sadigh, and S. Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
Pith/arXiv arXiv 2024
- [31]
-
[32]
B. Chen, T. Zhang, H. Geng, K. Song, C. Zhang, P. Li, W. T. Freeman, J. Malik, P. Abbeel, R. Tedrake, et al. Large video planner enables generalizable robot control.arXiv preprint arXiv:2512.15840, 2025
Pith/arXiv arXiv 2025
-
[33]
H. Li, L. Sun, Y .-H. Hu, D. Ta, J. Barry, G. Konidaris, and J. Fu. Novaflow: Zero-shot manip- ulation via actionable flow from generated videos.arXiv preprint arXiv:2510.08568, 2025
arXiv 2025
-
[34]
B. Kim, T. Kim, J. Lee, and H. Joo. Dexterous world models.arXiv preprint arXiv:2512.17907, 2025
arXiv 2025
-
[35]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 12
Pith/arXiv arXiv 2026
-
[36]
MotuBrain Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, et al. Motubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792, 2026
Pith/arXiv arXiv 2026
-
[37]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[38]
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. LLontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, A. Zhang, ...
Pith/arXiv arXiv 2025
-
[39]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: A vision-language-action model with open-world generalization. InProceedings of The 9th Conference on Robot Learning, 2025
2025
-
[40]
Physical Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnier, et al.π 0.7: A steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[41]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. Inconference on Robot Learning, pages 991–1002. PMLR, 2022
2022
-
[42]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[43]
Zhong, X
Y . Zhong, X. Huang, R. Li, C. Zhang, Z. Chen, T. Guan, F. Zeng, K. N. Lui, Y . Ye, Y . Liang, Y . Yang, and Y . Chen. Dexgraspvla: A vision-language-action framework towards general dex- terous grasping. In S. Koenig, C. Jenkins, and M. E. Taylor, editors,Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applicat...
2026
-
[44]
H. Liu, S. Guo, P. Mai, J. Cao, H. Li, and J. Ma. Robodexvlm: Visual language model-enabled task planning and motion control for dexterous robot manipulation. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2025, Hangzhou, China, October 19-25, 2025, pages 1381–1388. IEEE, 2025
2025
-
[45]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3d with transformers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9826–9836. IEEE, 2024
2024
-
[46]
Zhang, J
J. Zhang, J. Deng, C. Ma, and R. A. Potamias. Hawor: World-space hand motion reconstruc- tion from egocentric videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1805–1815, 2025
2025
-
[47]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile representation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023
2023
-
[48]
K. Shaw, S. Bahl, and D. Pathak. Videodex: Learning dexterity from internet videos. In Conference on Robot Learning, pages 654–665. PMLR, 2023. 13
2023
-
[49]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InEuropean Conference on Computer Vision, pages 570–587. Springer, 2022
2022
-
[50]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation. In D. Kulic, G. Venture, K. E. Bekris, and E. Coronado, editors,Robotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024, 2024
2024
- [51]
- [52]
-
[53]
S. Patel, S. Mohan, H. Mai, U. Jain, S. Lazebnik, and Y . Li. Robotic manipulation by imitating generated videos without physical demonstrations.arXiv preprint arXiv:2507.00990, 2025
Pith/arXiv arXiv 2025
-
[54]
K. Dharmarajan, W. Huang, J. Wu, L. Fei-Fei, and R. Zhang. Dream2flow: Bridging video gen- eration and open-world manipulation with 3d object flow.arXiv preprint arXiv:2512.24766, 2025
arXiv 2025
-
[55]
G. Team, A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, J. Zhu, K. Li, M. Xu, Q. Deng, S. Wang, W. Qin, X. Chen, X. Wang, Y . Wang, Y . Cao, Y . Chang, Y . Xu, Y . Ye, Y . Wang, Y . Zhou, Z. Zhang, Z. Dong, and Z. Zhu. Gigaworld-0: World models as data engine to empower embodied AI.CoRR, abs/2511.19861, 2025
arXiv 2025
-
[56]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S.-m. Yin, S. Bai, X. Xu, Y . Chen, et al. Qwen- image technical report.arXiv preprint arXiv:2508.02324, 2025
Pith/arXiv arXiv 2025
-
[57]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[58]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: modeling and capturing hands and bodies together.ACM Trans. Graph., 36(6):245:1–245:17, 2017
2017
-
[59]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[60]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, E. Byrne, Z. Chavis, et al. Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2024
2024
-
[61]
something something
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzy´nska, S. Westphal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pag...
2017
-
[62]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[63]
Masked-attention mask transformer for universal image seg- mentation,
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. HOI4D: A 4d egocentric dataset for category-level human-object interaction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 20981–20990. IEEE, 2022. doi:10.1109/CVPR52688.2022.02034. 15 Append...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.