Novelty-Aware Agentic Retrieval: Comparing Research Contributions Through Structured Multi-Step Reasoning
Pith reviewed 2026-06-26 11:04 UTC · model grok-4.3
The pith
An agentic retrieval system adds structured multi-step reasoning to RAG to extract per-paper contributions, overlaps, and problem-method gap matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
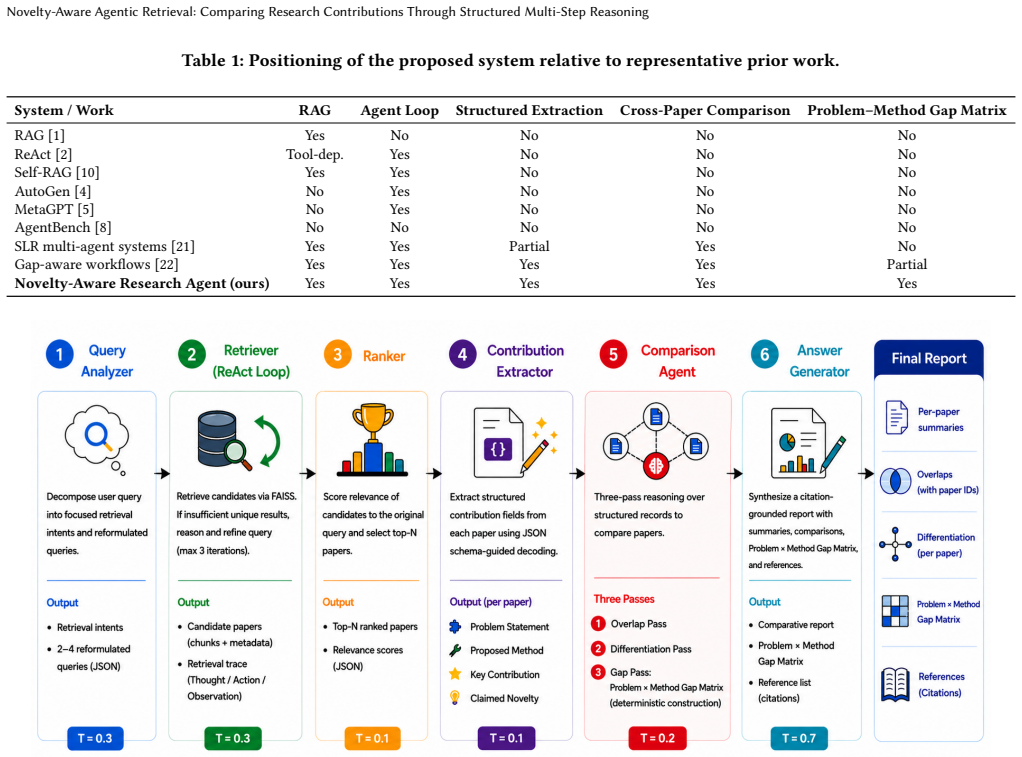
By layering query analysis, a ReAct-style retrieval loop, relevance ranking, schema-guided contribution extraction, a three-pass comparison agent, and answer generation on a RAG pipeline, the system generates structured comparison artifacts including per-paper contribution records, paper-level overlaps, and a problem x method gap matrix, capabilities that standard retrieval-augmented generation does not provide.
What carries the argument
The three-pass comparison agent that receives schema-guided contribution records and populates a problem-by-method gap matrix.
Load-bearing premise
The evaluation depends on author-assigned graded relevance labels for the 100-paper corpus and on manual checks of only 20 gap-matrix cells.
What would settle it
An independent expert labeling of the same or a larger corpus followed by re-running the system would show whether the structured outputs still differ from RAG and whether the gap cells match the new labels.
Figures
read the original abstract
Scientific literature search is an information retrieval (IR) task in which ranked lists are insufficient: a researcher entering a new area needs to know not only which papers are relevant, but how they relate, where they overlap, how they differ, and what problem-method combinations are absent. Standard retrieval-augmented generation (RAG) summarizes documents independently, discarding this comparative signal. We present the Novelty-Aware Research Agent, a prototype agentic retrieval system that layers structured multi-step reasoning on a RAG pipeline through six typed-contract components: query analysis, a ReAct-style retrieval loop, relevance ranking, schema-guided contribution extraction, a three-pass comparison agent, and answer generation. Beyond returning relevant papers, it produces structured comparison artifacts: per-paper contribution records, paper-level overlaps, and a problem x method gap matrix. On a 100-paper corpus, the system supports five structured comparison capabilities that a standard RAG baseline supports none of, while remaining query-sensitive: across three main queries no paper appears in all three top-5 sets (mean pairwise Jaccard 0.12), and an extended seven-query evaluation holds the pattern across ten queries (mean Jaccard 0.115, 18 of 29 retrieved papers query-exclusive). Under author-assigned graded relevance the ranker attains mean Precision@5 1.000 and nDCG@5 0.752 on the main queries, ahead of BM25, dense, and hybrid retrieval; over ten queries Precision@5 is non-saturated at 0.980 with nDCG@5 0.739. Schema compliance is 86.7% on the main queries and 84.0% over the ten-query set, and validating 20 sampled empty gap-matrix cells yields a gap precision of 0.600. We discuss the latency-structure trade-off in agentic retrieval and identify corpus scale, author-assigned labels, and limited independent evaluation as the main limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Novelty-Aware Research Agent, a prototype agentic retrieval system that augments a RAG pipeline with six typed-contract components (query analysis, ReAct-style retrieval, relevance ranking, schema-guided contribution extraction, three-pass comparison, and answer generation) to produce structured artifacts including per-paper contribution records, paper-level overlaps, and a problem x method gap matrix. On a 100-paper corpus it claims to support five structured comparison capabilities absent from standard RAG baselines while remaining query-sensitive (mean pairwise Jaccard 0.12 across three main queries' top-5 sets; 0.115 across ten queries), attaining Precision@5 of 1.000 / nDCG@5 of 0.752 under author-assigned labels, 86.7% schema compliance, and 0.600 gap precision from 20 sampled cells.
Significance. If the empirical claims hold under independent validation, the work would advance agentic IR by showing how multi-step reasoning can generate comparative structures (overlaps, gaps) that standard RAG cannot, with the label-independent query-sensitivity result and direct corpus measurements providing a concrete baseline for future systems.
major comments (3)
- [evaluation on the 100-paper corpus] Evaluation on the 100-paper corpus: Precision@5 = 1.000, nDCG@5 = 0.752, schema compliance 86.7%, and gap precision 0.600 are all computed against author-assigned graded relevance labels plus manual checks on only 20 sampled gap-matrix cells; this makes the numeric superiority and structured-output correctness claims dependent on potentially biased labels whose generalizability is not tested via independent annotators.
- [evaluation on the 100-paper corpus] The central claim that the system supports five structured comparison capabilities that standard RAG supports none of rests on the same 100-paper corpus and 20-cell validation; with corpus scale and label independence acknowledged as limitations but not addressed experimentally, the load-bearing empirical distinction between the agent and baselines remains under-supported.
- [evaluation on the 100-paper corpus] While the query-sensitivity result (mean Jaccard 0.12, 18 of 29 papers query-exclusive) is label-independent and therefore more robust, it does not validate the correctness of the generated contribution records, overlaps, or gap matrix, leaving the primary novelty claim partially untested.
Simulated Author's Rebuttal
We thank the referee for the constructive focus on evaluation methodology. We address each major comment below, agreeing where the critique identifies genuine limitations already noted in the manuscript while defending the prototype nature of the work. We propose targeted revisions to strengthen caveats without overstating the current results.
read point-by-point responses
-
Referee: [evaluation on the 100-paper corpus] Evaluation on the 100-paper corpus: Precision@5 = 1.000, nDCG@5 = 0.752, schema compliance 86.7%, and gap precision 0.600 are all computed against author-assigned graded relevance labels plus manual checks on only 20 sampled gap-matrix cells; this makes the numeric superiority and structured-output correctness claims dependent on potentially biased labels whose generalizability is not tested via independent annotators.
Authors: We agree that author-assigned labels carry bias risk and that the 20-cell gap sample is limited; independent annotators would strengthen generalizability. The manuscript already flags 'author-assigned labels' and 'limited independent evaluation' as core limitations. Schema compliance (86.7%) relies on objective structural matching to the defined schema rather than subjective relevance. We will revise the limitations and evaluation sections to more explicitly discuss label-bias implications and to recommend independent annotation as required future work. revision: partial
-
Referee: [evaluation on the 100-paper corpus] The central claim that the system supports five structured comparison capabilities that standard RAG supports none of rests on the same 100-paper corpus and 20-cell validation; with corpus scale and label independence acknowledged as limitations but not addressed experimentally, the load-bearing empirical distinction between the agent and baselines remains under-supported.
Authors: The five capabilities (contribution records, overlaps, gap matrix, etc.) are produced by the agent's typed-contract components, which standard RAG lacks by design; the empirical results quantify output quality on this corpus rather than prove universal superiority. The distinction is therefore both architectural and initial-empirical. We will add clarifying text in the introduction and discussion to separate the capability demonstration from the scale-limited metrics, while reiterating the prototype framing. revision: partial
-
Referee: [evaluation on the 100-paper corpus] While the query-sensitivity result (mean Jaccard 0.12, 18 of 29 papers query-exclusive) is label-independent and therefore more robust, it does not validate the correctness of the generated contribution records, overlaps, or gap matrix, leaving the primary novelty claim partially untested.
Authors: We agree that query-sensitivity alone does not establish correctness of the structured artifacts. Correctness is additionally evidenced by the objective schema-compliance rate and the sampled gap validation. The novelty claim centers on the agentic pipeline enabling these artifacts in a query-sensitive manner. We will revise the results and discussion sections to explicitly distinguish the label-independent robustness metric from the quality metrics supporting artifact correctness. revision: partial
- Independent annotator validation of the 100-paper corpus relevance labels and gap-matrix cells
- Experimental evaluation on a substantially larger corpus
Circularity Check
No circularity; empirical metrics are direct measurements
full rationale
The paper describes a prototype agentic system with six typed components and reports empirical performance on a fixed 100-paper corpus. All numeric results (Precision@5 1.000, nDCG@5 0.752, schema compliance 86.7%, gap precision 0.600, mean Jaccard 0.12) are obtained by direct counting or manual validation against author-assigned graded labels and 20 sampled cells. No equations, fitted parameters, or self-citations are invoked to derive these quantities; the claims do not reduce to any input by construction. The evaluation section explicitly flags author-assigned labels and limited independent validation as limitations, confirming the results are presented as corpus-specific observations rather than self-referential derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented genera- tion for knowledge-intensive NLP tasks.arXiv preprint arXiv:2005.11401, 2020. https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2023. https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. Efficient guided generation for large language models.arXiv preprint arXiv:2307.09702, 2023. https://arxiv.org/abs/2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023. https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework.arXiv preprint arXiv:2308.00352, 2024. https://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society.arXiv preprint arXiv:2303.17760, 2023. https: //arxiv.org/abs/2303.17760
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforce- ment learning.arXiv preprint arXiv:2303.11366, 2023. https://arxiv.org/abs/2303. 11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688, 2023. https://arxiv....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior.arXiv preprint arXiv:2304.03442, 2023. https://arxiv.org/abs/ 2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. arXiv preprint arXiv:2310.11511, 2023. https://arxiv.org/abs/2310.11511
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective Retrieval Augmented Generation.arXiv preprint arXiv:2401.15884, 2024. https://arxiv.org/ abs/2401.15884
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A survey on large language model based au- tonomous agents.Frontiers of Computer Science, 18:186345, 2024
Lei Wang, Chengbang Ma, Xueyang Feng, Zeyu Zhang, Hao-ran Yang, Jingsen Zhang, Zhi-Yang Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-rong Wen. A survey on large language model based au- tonomous agents.Frontiers of Computer Science, 18:186345, 2024. https://api. semanticscholar.org/CorpusID:261064713
2024
-
[13]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022. https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, and Tao Yu
Tianbao Xie, Fan Zhou, Zhoujun Cheng, Peng Shi, Luoxuan Weng, Yitao Liu, Toh Jing Hua, Junning Zhao, Qian Liu, Che Liu, Leo Z. Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, and Tao Yu. OpenAgents: An open platform for language agents in the wild.arXiv preprint arXiv:2310.10634, 2023. https: //arxiv.org/abs/2310.10634
-
[15]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023. https: //arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
https://arxiv.org/abs/2308.10848
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models.arXiv preprint arXiv:2305.18323, 2023. https://arxiv. org/abs/2305.18323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Yuan Li, Yixuan Zhang, and Lichao Sun. MetaAgents: Simulating Interactions of Human Behaviors for LLM-based Task-oriented Coordination via Collaborative Generative Agents.arXiv preprint arXiv:2310.06500, 2023. https://arxiv.org/abs/ 2310.06500
-
[20]
ART: Automatic multi-step reasoning and tool-use for large language models
Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. ART: Automatic multi-step reasoning and tool-use for large language models.arXiv preprint arXiv:2303.09014, 2023. https://arxiv.org/abs/2303.09014
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Reasoning with Language Model is Planning with World Model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023. https://arxiv.org/abs/2305.14992
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Abdul Malik Sami, Zeeshan Rasheed, Kai-Kristian Kemell, Muhammad Waseem, Terhi Kilamo, Mika Saari, Anh Nguyen Duc, Kari Systä, and Pekka Abrahamsson. System for systematic literature review using multiple AI agents: Concept and an empirical evaluation.arXiv preprint arXiv:2403.08399, 2024. https://arxiv.org/ abs/2403.08399
-
[23]
Movina Moses, Mohab Elkaref, James Barry, Vishnudev Kuruvanthodi, Muthukumaran Ramasubramanian, Campbell Watson, and Geeth R. De Mel. Agentic workflows for gap-aware literature reviews.AGU Annual Meeting,
-
[24]
https://research.ibm.com/publications/agentic-workflows-for-gap-aware- literature-reviews
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.