Lost in Aggregation: A Multi-Scale Diagnostic Benchmark for LLM Spatial Navigation
Pith reviewed 2026-06-26 10:34 UTC · model grok-4.3
The pith
LLMs handle individual spatial skills at fine, meso, and macro scales but cannot aggregate them into long sequential navigation plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
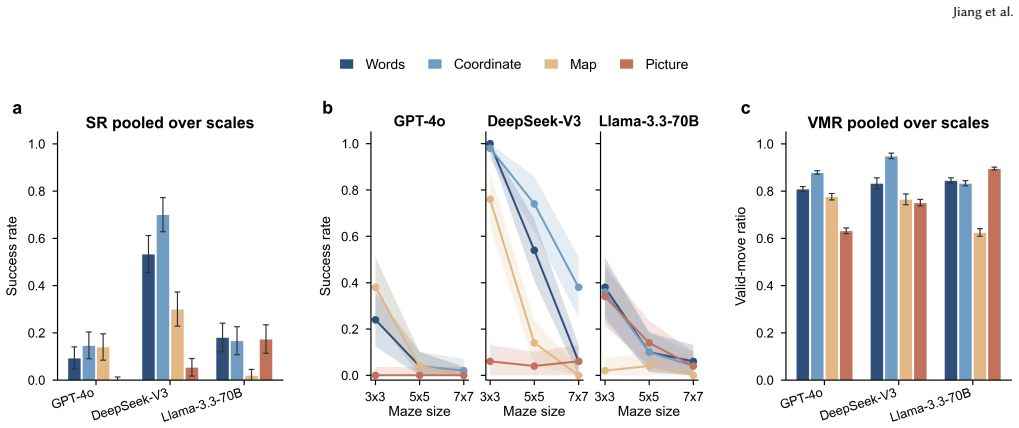
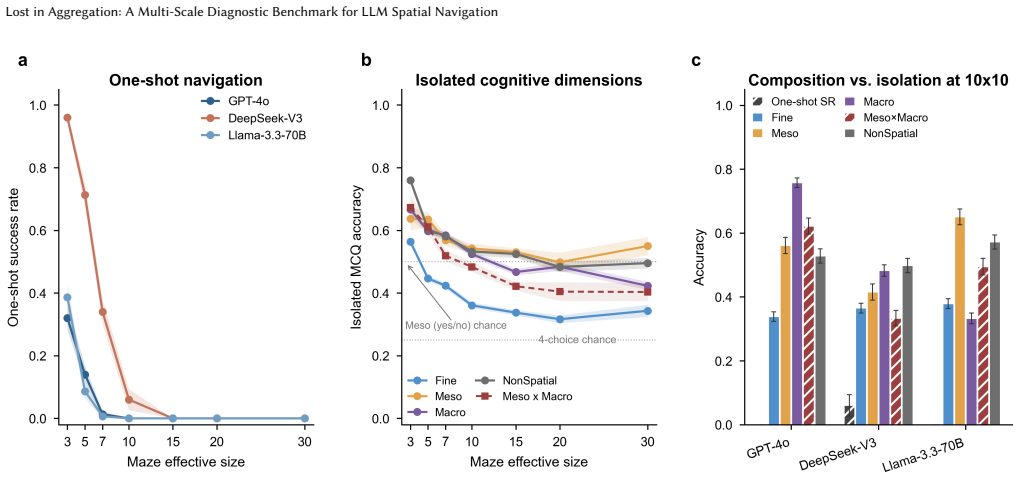
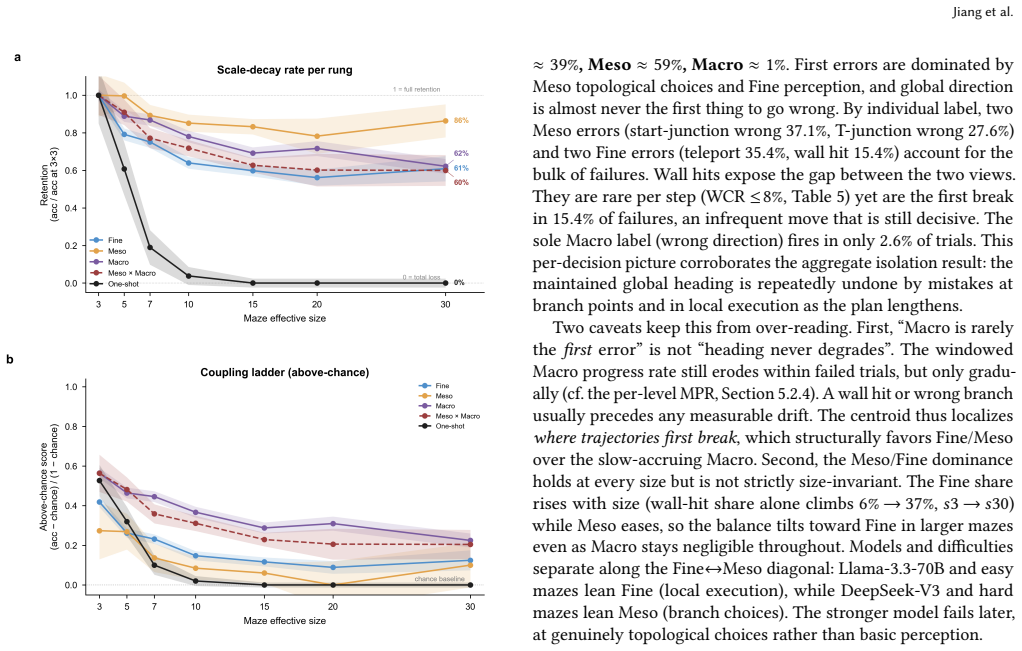
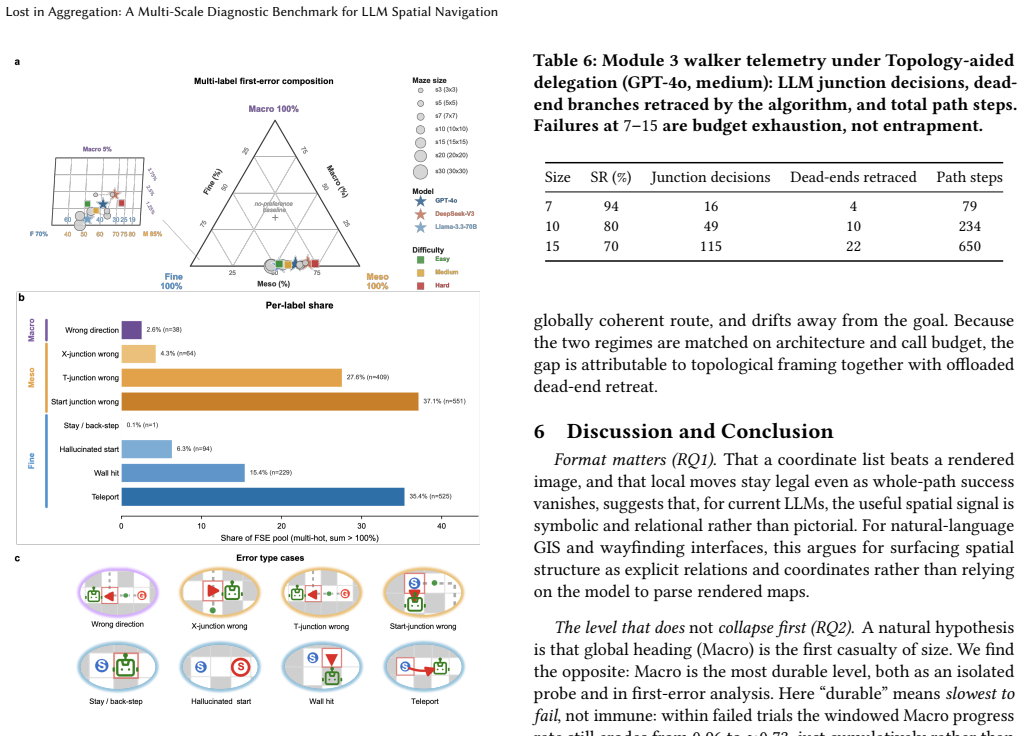
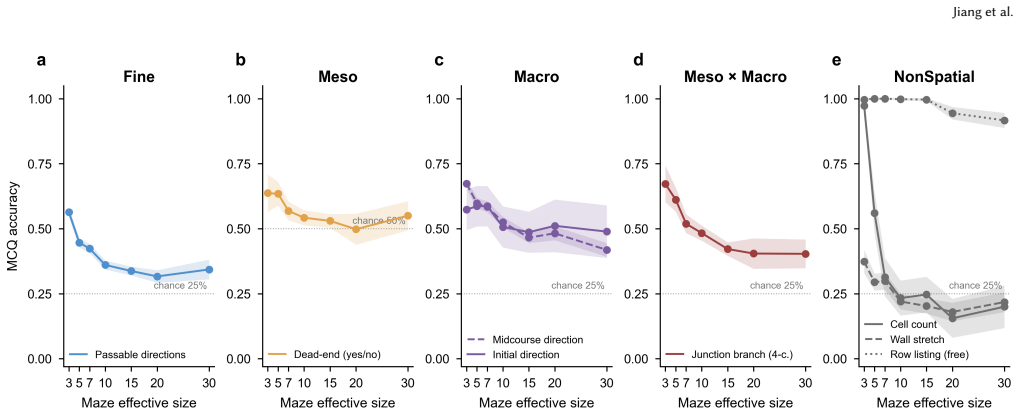
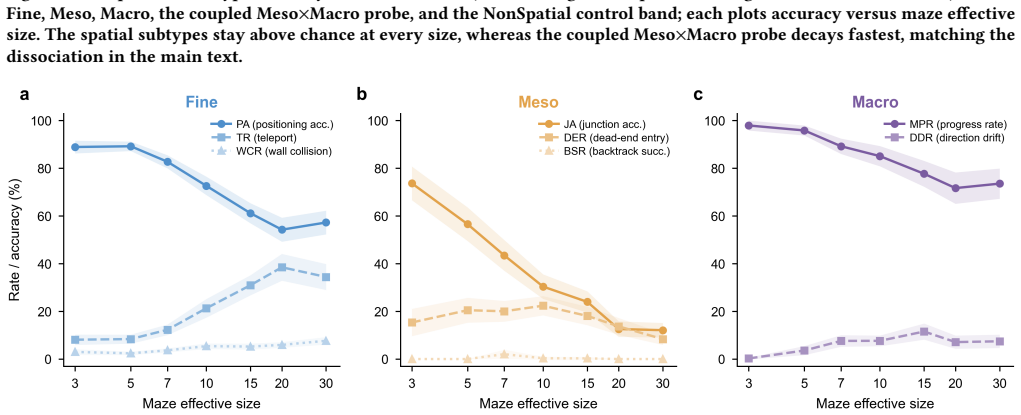
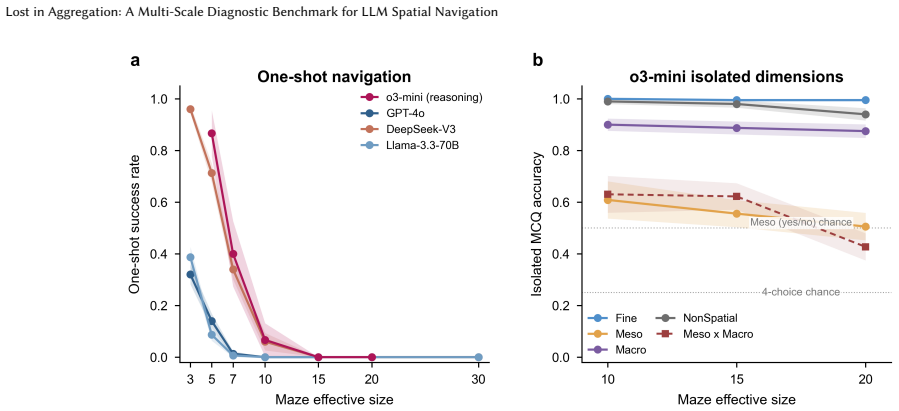
The central claim is that the barrier to LLM spatial navigation is cross-scale aggregation of individually available competences over a long sequential plan, not any single perceptual deficit. End-to-end one-shot navigation collapses to near zero by 10x10 mazes for GPT-4o, DeepSeek-V3, and Llama-3.3-70B, while the same models respond to isolated Fine, Meso, and Macro probes at 30-75 percent accuracy far beyond that size. A multi-hot first-error analysis localizes failures to Meso junction choices (59 percent) and Fine perception (39 percent), with global direction almost never at fault (1 percent). Hierarchical delegation of per-step execution to a deterministic walker lifts performance at m
What carries the argument
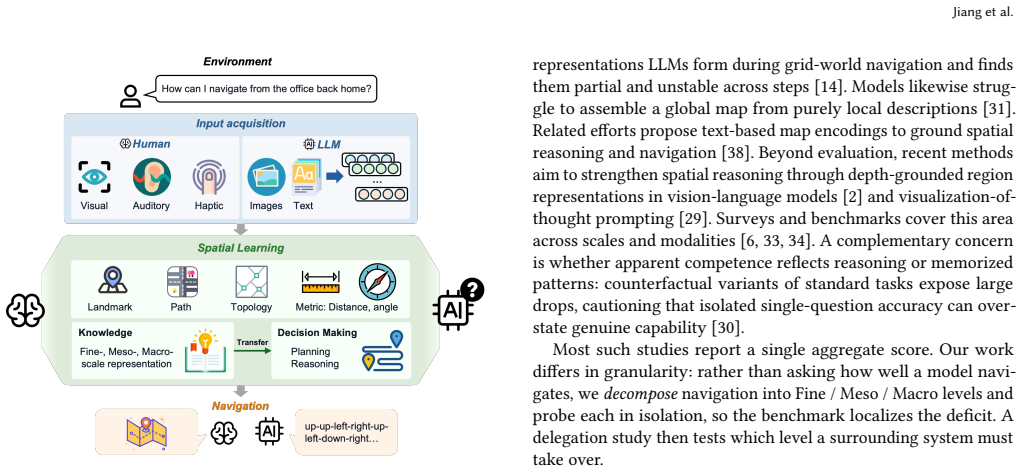
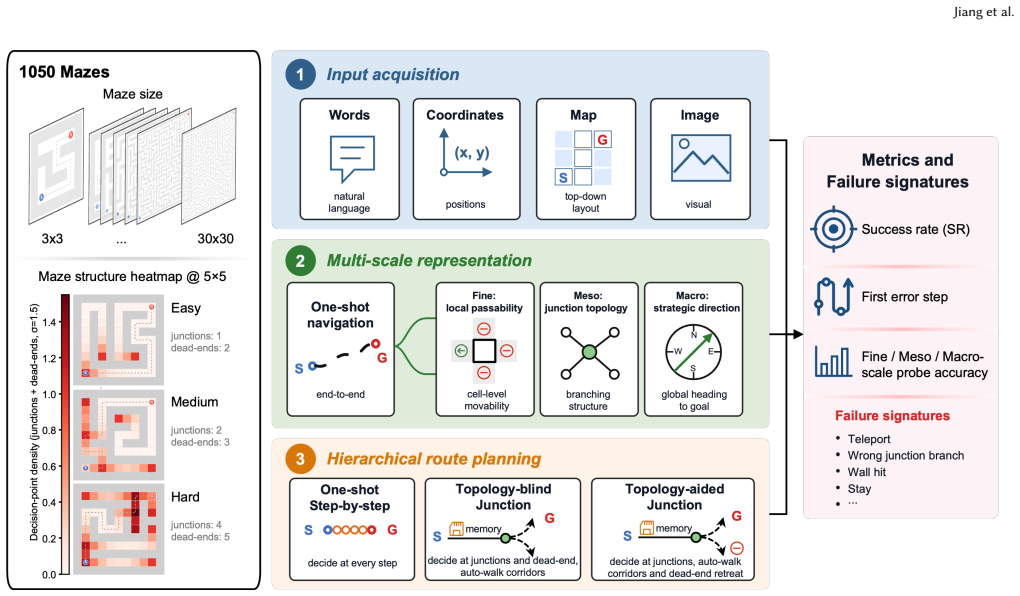
The multi-scale diagnostic benchmark that decomposes maze navigation into Fine (local passability), Meso (junction topology), and Macro (global goal direction) modules, with separate tests for input formats and hierarchical route planning.
If this is right
- Structured coordinate text input outperforms rendered images for all models.
- End-to-end navigation success falls to near zero by 10x10 mazes across the three tested LLMs.
- Failures localize to Meso (59 percent) and Fine (39 percent) scales, not Macro direction (1 percent).
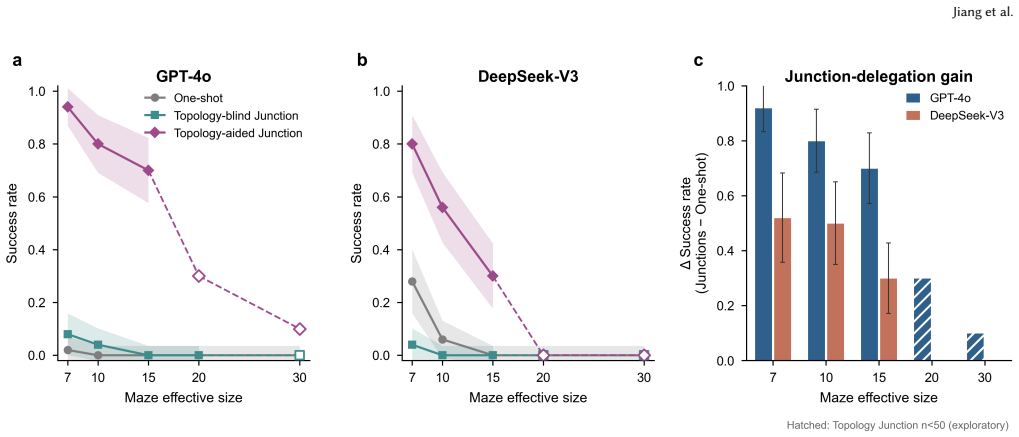
- Delegating execution to a deterministic walker and prompting only at junctions raises GPT-4o success by up to 92 points at mid sizes.
- The scaling wall re-emerges by 30x30 even under hierarchical planning.
Where Pith is reading between the lines
- The same aggregation difficulty may limit LLM performance on other long-horizon sequential tasks that require repeated integration of local and global information.
- Explicit training or prompting regimes that force repeated cross-scale checks could be tested directly with this benchmark.
- The released set of 1,050 topology-annotated mazes can serve as a reusable diagnostic for new models without requiring new data collection.
Load-bearing premise
That performance on isolated single-level probes measures the same underlying competences that would be available during full end-to-end sequential navigation.
What would settle it
A controlled test in which models receive explicit correct information from the other two scales at every decision point yet still fail at the same rates as in the original end-to-end setting.
Figures

read the original abstract
Large language models (LLMs) are increasingly deployed as planners and assistants in tasks with inherent spatial structure, such as navigation and route planning, yet they remain brittle in sequential spatial reasoning. We ask not merely whether LLMs fail at navigation but where in the spatial-cognition pipeline they get lost. We introduce a multi-scale diagnostic benchmark that decomposes maze navigation into three cognitive levels drawn from human spatial cognition: Fine (local passability), Meso (junction topology), and Macro (global goal direction). We evaluate three instruction-tuned chat LLMs (GPT-4o, DeepSeek-V3, Llama-3.3-70B) on 1,050 topology-annotated mazes spanning seven sizes (3x3 to 30x30) and three difficulty tiers. The benchmark is organized as three modules. (i) Input acquisition: among four input formats, structured coordinate text is the most navigable, far surpassing rendered images. (ii) Multi-scale representation: end-to-end one-shot navigation collapses to near zero by 10x10 for every model, yet the same models respond to isolated single-level probes (Fine, Meso, Macro) at 30-75% far beyond that size. A multi-hot first-error analysis localizes failures to Meso junction choices (59%) and Fine perception (39%), with global direction almost never at fault (1%). The barrier is therefore the cross-scale aggregation of individually available competences over a long sequential plan, not any single perceptual deficit. (iii) Hierarchical route planning: delegating per-step execution to a deterministic walker and querying the LLM only at junctions, with an explicit cell-type prompt, lifts GPT-4o success by up to 92 points at mid sizes, but the same scaling wall re-emerges by 30x30. We release the benchmark, mazes, and code as a reusable diagnostic instrument for spatial reasoning in LLMs, available at https://yuhanjiang415.github.io/lost-in-aggregation/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a multi-scale diagnostic benchmark for LLM spatial navigation that decomposes maze tasks into Fine (local passability), Meso (junction topology), and Macro (global goal direction) levels. Evaluations of GPT-4o, DeepSeek-V3, and Llama-3.3-70B on 1,050 annotated mazes (3x3 to 30x30) show end-to-end one-shot navigation collapsing near zero by 10x10, while isolated single-level probes achieve 30-75% success at larger sizes. A multi-hot first-error analysis on failing trajectories attributes errors to Meso (59%) and Fine (39%), with Macro at 1%. Hierarchical planning (LLM queried only at junctions) improves mid-size performance by up to 92 points but encounters the same wall at 30x30. The central claim is that failures arise from cross-scale aggregation of available competences rather than any single perceptual deficit. The benchmark, mazes, and code are released publicly.
Significance. If substantiated, the work supplies a reusable diagnostic instrument that separates perceptual from aggregation failures in LLM sequential reasoning, with direct relevance to planning applications. The public release of materials supports reproducibility and community use. The empirical decomposition into human-inspired cognitive levels offers a concrete framework for future LLM spatial-cognition studies.
major comments (2)
- [multi-scale representation module] The central claim that the barrier is cross-scale aggregation (rather than missing individual competences) depends on isolated Fine/Meso/Macro probes measuring the same underlying abilities deployed mid-trajectory in sequential navigation. The multi-hot first-error analysis (59% Meso, 39% Fine) is performed only on failing end-to-end trajectories and does not test whether the model, given the identical partial history, can correctly answer the corresponding probe. This assumption is load-bearing for the localization result and the aggregation conclusion.
- [experimental results and first-error analysis] The reported first-error breakdown (59% Meso, 39% Fine, 1% Macro) and probe success rates lack error bars, confidence intervals, or statistical tests, and the abstract provides no implementation details on how first-error localization was performed. These omissions affect the reliability of the claim that global direction is almost never at fault.
minor comments (2)
- [input acquisition] The four input formats in the input-acquisition module are described but not illustrated; a supplementary table or figure with concrete examples of each format would aid reproducibility.
- [hierarchical route planning] The hierarchical condition description would benefit from explicit pseudocode showing the exact cell-type prompt and junction-query interface.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment below, indicating planned revisions where appropriate. Our responses focus on clarifying methodological assumptions and improving statistical reporting.
read point-by-point responses
-
Referee: [multi-scale representation module] The central claim that the barrier is cross-scale aggregation (rather than missing individual competences) depends on isolated Fine/Meso/Macro probes measuring the same underlying abilities deployed mid-trajectory in sequential navigation. The multi-hot first-error analysis (59% Meso, 39% Fine) is performed only on failing end-to-end trajectories and does not test whether the model, given the identical partial history, can correctly answer the corresponding probe. This assumption is load-bearing for the localization result and the aggregation conclusion.
Authors: We appreciate this methodological observation. The isolated probes are designed to measure the availability of each scale-specific competence independently of sequential integration demands, while the first-error analysis attributes failures in the integrated task based on the first deviation in the trajectory. We agree that conditioning probes on the exact partial history from failing trajectories would provide stronger validation of the localization. We will revise the manuscript to explicitly discuss this assumption as a limitation of the current design and its implications for interpreting the aggregation claim, while noting that full conditional probing is planned for follow-up work. revision: partial
-
Referee: [experimental results and first-error analysis] The reported first-error breakdown (59% Meso, 39% Fine, 1% Macro) and probe success rates lack error bars, confidence intervals, or statistical tests, and the abstract provides no implementation details on how first-error localization was performed. These omissions affect the reliability of the claim that global direction is almost never at fault.
Authors: We agree that the lack of error bars, confidence intervals, and statistical tests reduces the robustness of the reported breakdowns. We will add these elements (including standard errors and appropriate tests such as chi-squared for category proportions) to all figures and tables in the revised manuscript. We will also expand the methods section with full implementation details on the multi-hot first-error localization procedure, including labeling criteria and trajectory processing steps. The abstract will be updated to reference these details where space allows, with the main text providing the complete description. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted parameters
full rationale
The paper presents an empirical diagnostic benchmark for LLM navigation across scales, reporting observed success rates on isolated probes versus end-to-end tasks. No equations, derivations, parameter fitting, or self-citation chains appear in the provided text. Central claims rest on direct experimental measurements (e.g., 30-75% probe success vs. near-zero end-to-end), which are falsifiable against external benchmarks and do not reduce to any input by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Fine/Meso/Macro decomposition drawn from human spatial cognition accurately partitions the navigation task for LLMs.
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sün- derhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. 2018. Vision-and- Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 3674–3683. doi:10.11...
-
[2]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models. InAdvances in Neural Information Processing Systems 37 (NeurIPS). doi:10.48550/arXiv.2406.01584
-
[3]
Alan Dao and Dinh Bach Vu. 2025. AlphaMaze: Enhancing Large Language Models’ Spatial Intelligence via GRPO. arXiv:2502.14669
arXiv 2025
-
[4]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437 Lost in Aggregation: A Multi-Scale Diagnostic Benchmark for LLM Spatial Navigation
Pith/arXiv arXiv 2024
-
[5]
Hafsteinn Einarsson. 2025. MazeEval: A Benchmark for Testing Sequential Decision-Making in Language Models. arXiv:2507.20395
arXiv 2025
-
[6]
Jie Feng, Jinwei Zeng, Qingyue Long, Hongyi Chen, Jie Zhao, Yanxin Xi, Zhilun Zhou, Yuan Yuan, Shengyuan Wang, Qingbin Zeng, Songwei Li, Yunke Zhang, Yuming Lin, Tong Li, Jingtao Ding, Chen Gao, Fengli Xu, and Yong Li. 2025. A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Sc...
arXiv 2025
-
[7]
Scott M. Freundschuh and Max J. Egenhofer. 1997. Human Conceptions of Spaces: Implications for GIS.Transactions in GIS2, 4 (1997), 361–375. doi:10.1111/j.1467- 9671.1997.tb00063.x
-
[8]
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. 2023. Reasoning with Language Model is Planning with World Model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8154–8173. doi:10.18653/v1/2023.emnlp-main.507
-
[9]
Michael Igorevich Ivanitskiy, Rusheb Shah, Alex F. Spies, Tilman Räuker, Dan Valentine, Can Rager, Lucia Quirke, Chris Mathwin, Guillaume Corlouer, Cecilia Diniz Behn, and Samy Wu Fung. 2023. A Configurable Library for Generating and Manipulating Maze Datasets. arXiv:2309.10498
arXiv 2023
-
[10]
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, and Anil Murthy. 2024. LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks. InProceedings of the 41st International Conference on Machine Learning (ICML). doi:10.48550/arXiv. 2402.01817
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[11]
Zekun Li, Malcolm Grossman, Ehsan Qasemi, Mihir Kulkarni, Muhao Chen, and Yao-Yi Chiang. 2025. MapQA: Open-domain Geospatial Question Answering on Map Data. arXiv:2503.07871
arXiv 2025
-
[12]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[13]
Llama Team, AI @ Meta. 2024. The Llama 3 Herd of Models. arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[14]
Nicolás Martorell. 2025. From Text to Space: Mapping Abstract Spatial Models in LLMs During a Grid-World Navigation Task. arXiv:2502.16690
arXiv 2025
-
[15]
Yanghong Mei, Yirong Yang, Longteng Guo, Qunbo Wang, Ming-Ming Yu, Xingjian He, Wenjun Wu, and Jing Liu. 2025. UrbanNav: Learning Language- Guided Urban Navigation from Web-Scale Human Trajectories. arXiv:2512.09607
arXiv 2025
-
[16]
Roshanak Mirzaee, Hossein Rajaby Faghihi, Qiang Ning, and Parisa Kordjamshidi
-
[17]
SpartQA: A Textual Question Answering Benchmark for Spatial Rea- soning. InProceedings of the 2021 Conference of the North American Chap- ter of the Association for Computational Linguistics (NAACL-HLT). 4582–4598. doi:10.18653/v1/2021.naacl-main.364
-
[18]
Daniel R. Montello. 1993. Scale and Multiple Psychologies of Space. InSpatial Information Theory: A Theoretical Basis for GIS (COSIT ’93), Andrew U. Frank and Irene Campari (Eds.). Lecture Notes in Computer Science, Vol. 716. Springer, Berlin, Heidelberg, 312–321. doi:10.1007/3-540-57207-4_21
-
[19]
OpenAI. 2024. GPT-4o System Card. arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[20]
Michael Peer and Russell A. Epstein. 2025. Cognitive Maps for Hierarchical Spaces in the Human Brain. bioRxiv. doi:10.1101/2025.02.05.636580
-
[21]
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Krähenbühl, and Vladlen Koltun. 2025. Does Spatial Cognition Emerge in Frontier Models?. InInternational Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2410.06468
-
[22]
Zhengxiang Shi, Qiang Zhang, and Aldo Lipani. 2022. StepGame: A New Benchmark for Robust Multi-Hop Spatial Reasoning in Texts. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 36. 11321–11329. doi:10.1609/aaai.v36i10.21383
-
[23]
Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Gholamreza Haffari, and Yuan-Fang Li. 2024. An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 21440–21455. doi:10.18653/ v1/2024.emnlp-main.1195
2024
-
[24]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2023. PlanBench: An Extensible Benchmark for Eval- uating Large Language Models on Planning and Reasoning about Change. In Advances in Neural Information Processing Systems 36 (NeurIPS), Datasets and Benchmarks Track. doi:10.48550/arXiv.2206.10498
-
[25]
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. 2024. Is a Picture Worth a Thousand Words? Delving Into Spatial Reasoning for Vision Language Models. InAdvances in Neural Information Processing Systems 37 (NeurIPS). doi:10.48550/arXiv.2406.14852
-
[26]
Junjue Wang, Weihao Xuan, Heli Qi, Pengyu Dai, Kunyi Liu, Hongruixuan Chen, Zhuo Zheng, Junshi Xia, Stefano Ermon, and Naoto Yokoya. 2026. Can LLM Agents Respond to Disasters? Benchmarking Heterogeneous Geospatial Reasoning in Emergency Operations. arXiv:2605.11633
Pith/arXiv arXiv 2026
-
[27]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35 (NeurIPS). doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[28]
Thomas Wolbers and Mary Hegarty. 2010. What Determines Our Navigational Abilities?Trends in Cognitive Sciences14, 3 (2010), 138–146. doi:10.1016/j.tics. 2010.01.001
-
[29]
Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, and Chang Liu. 2024. VoroNav: Voronoi-Based Zero-Shot Object Navigation with Large Language Model. arXiv:2401.02695
arXiv 2024
-
[30]
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. 2024. Mind’s Eye of LLMs: Visualization-of-Thought Elicits Spatial Rea- soning in Large Language Models. InAdvances in Neural Information Processing Systems 37 (NeurIPS). doi:10.48550/arXiv.2404.03622
-
[31]
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. 2024. Reasoning or Reciting? Explor- ing the Capabilities and Limitations of Language Models Through Counterfactual Tasks. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics...
-
[32]
Sirui Xia, Aili Chen, Xintao Wang, Tinghui Zhu, Yikai Zhang, Jiangjie Chen, and Yanghua Xiao. 2025. Can LLMs Learn to Map the World from Local Descriptions? arXiv:2505.20874
arXiv 2025
-
[33]
Shuo Xing, Zezhou Sun, Shuangyu Xie, Kaiyuan Chen, Yanjia Huang, Yuping Wang, Jiachen Li, Dezhen Song, and Zhengzhong Tu. 2025. Can Large Vision Language Models Read Maps Like a Human? arXiv:2503.14607
arXiv 2025
-
[34]
Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, Gege Qi, and Yunjian Zhang. 2025. SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition. arXiv:2511.21471
Pith/arXiv arXiv 2025
-
[35]
Anran Yang, Cheng Fu, Qingren Jia, Weihua Dong, Mengyu Ma, Hao Chen, Fei Yang, and Hui Wu. 2025. Evaluating and Enhancing Spatial Cognition Abilities of Large Language Models.International Journal of Geographical Information Science39, 9 (2025), 2009–2044. doi:10.1080/13658816.2025.2490701
-
[36]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems 36 (NeurIPS). doi:10.48550/arXiv.2305.10601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[37]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). doi:10. 48550/arXiv.2210.03629
Pith/arXiv arXiv 2023
-
[38]
Dazhou Yu, Riyang Bao, Ruiyu Ning, Jinghong Peng, Gengchen Mai, and Liang Zhao. 2025. Spatial-RAG: Spatial Retrieval Augmented Generation for Real-World Geospatial Reasoning Questions. arXiv:2502.18470
arXiv 2025
-
[39]
Mike Zhang, Kaixian Qu, Vaishakh Patil, Cesar Cadena, and Marco Hutter. 2024. Tag Map: A Text-Based Map for Spatial Reasoning and Navigation with Large Language Models. arXiv:2409.15451
arXiv 2024
-
[40]
Gengze Zhou, Yicong Hong, and Qi Wu. 2024. NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7641–7649. doi:10.1609/ aaai.v38i7.28597 A Appendix This appendix collects four supplementary figures; full details are in each caption. Figure 8 break...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.