SHACR: A Graph-Augmented Semi-Autonomous Framework for Multi-Class Conflict Resolution in Smart Home IoT Automation
Pith reviewed 2026-06-26 10:08 UTC · model grok-4.3
The pith
Anchoring large language models in a formal knowledge graph turns unreliable text-based conflict detection into deterministic graph traversal for smart home IoT rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
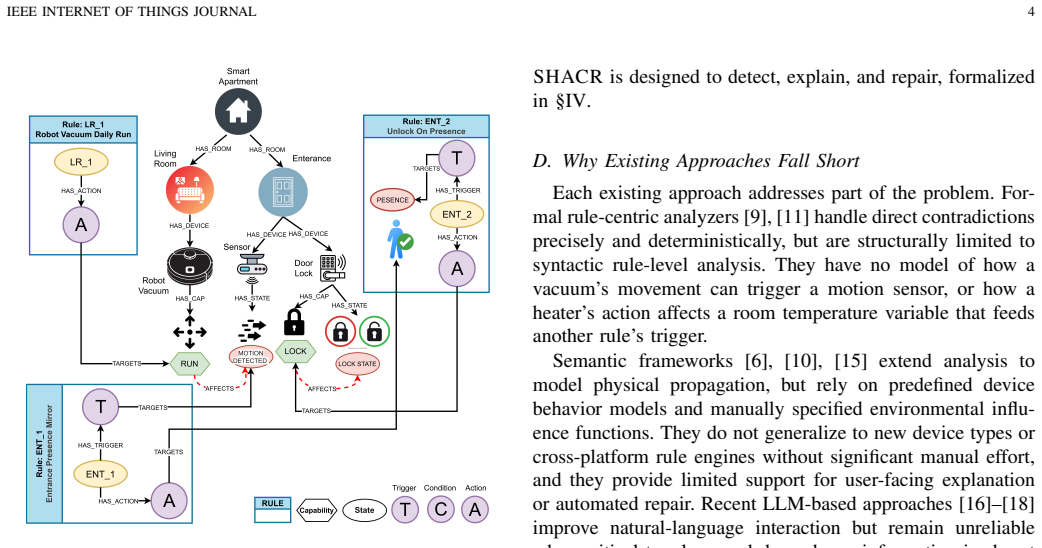
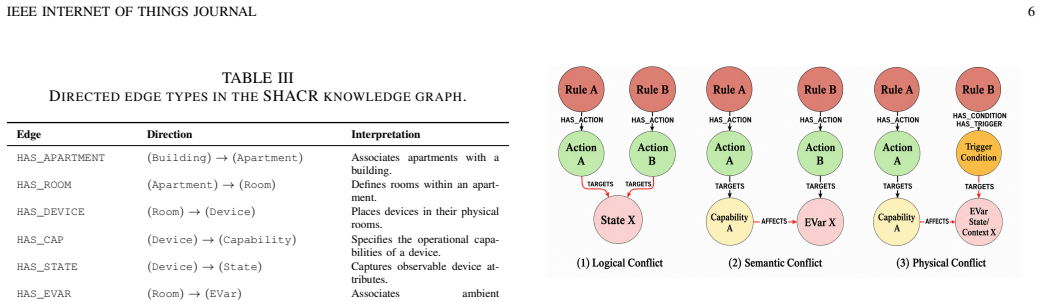
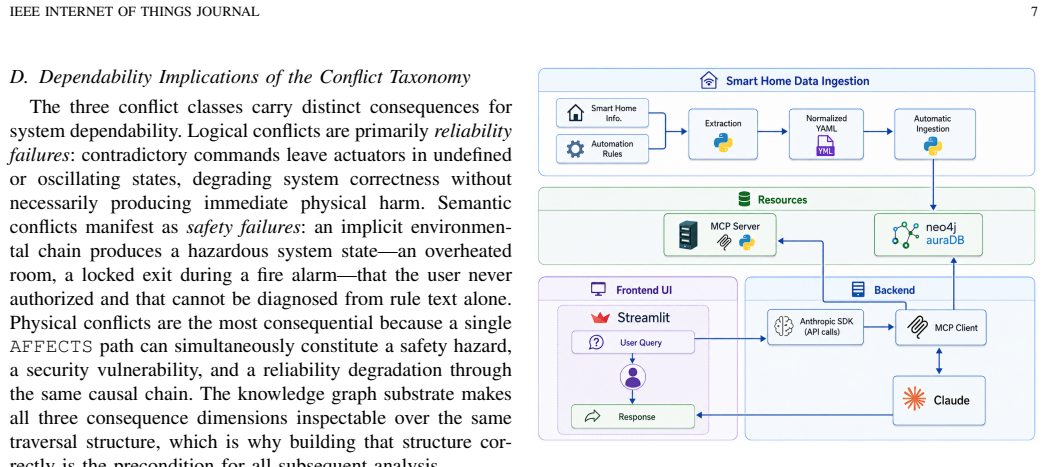
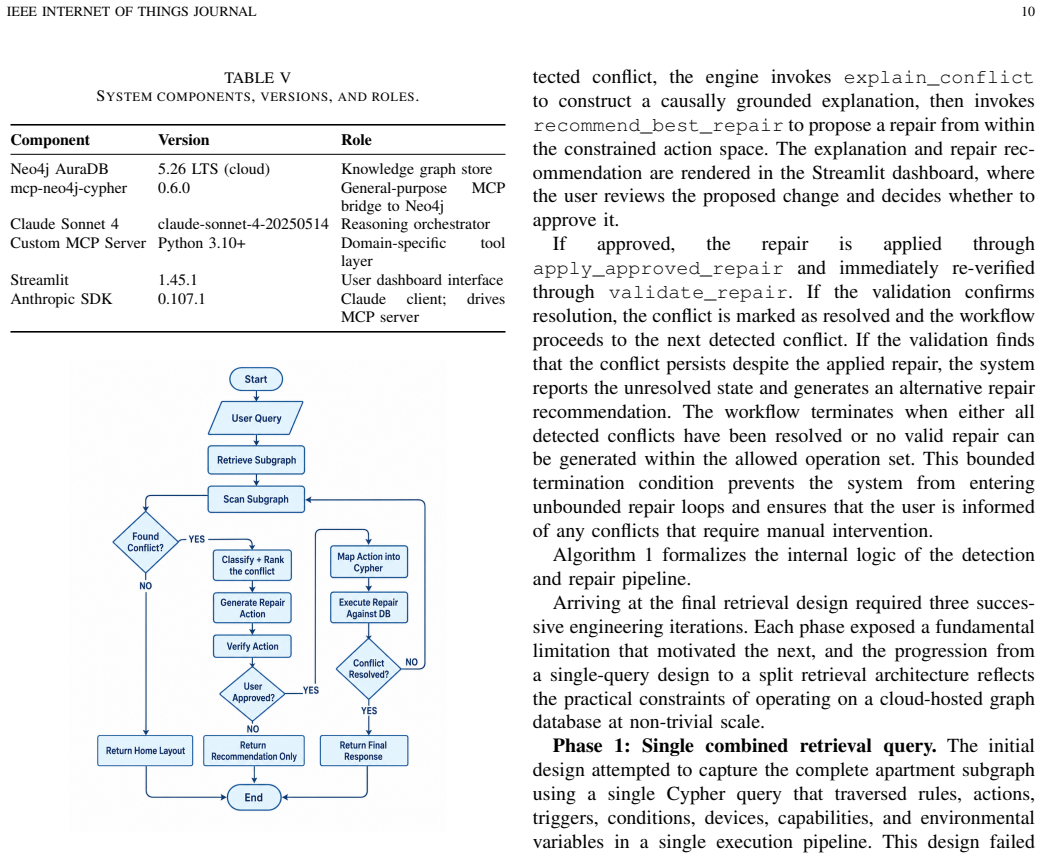
SHACR encodes devices, capabilities, physical states, and Trigger-Condition-Action rules as typed, traversable entities in a directed knowledge graph. Elevating physical cause-effect relationships to first-class graph edges transforms conflict detection from fragile text inference into deterministic multi-hop graph traversal, unifying logical, semantic, and physical conflict classes. It drives a closed-loop Scan-Explain-Repair-Validate workflow that bounds the LLM's action space. On a testbed of 203 rules across 70 apartments, adding the graph cuts classification errors by 36.7 percent, lifts F1 from 0.59 to 0.79, and with few-shot calibration reaches 0.95, while the same calibration barely
What carries the argument
The directed knowledge graph with typed entities for devices, capabilities, physical states, and rules, where physical cause-effect relationships serve as traversable edges; it supports the Scan-Explain-Repair-Validate workflow to bound LLM reasoning.
If this is right
- Multiple classes of conflicts become detectable in a single unified system via graph traversal.
- Actionable repairs can be generated for non-expert users through the bounded LLM workflow.
- Performance improvements persist across different LLMs since the graph is the key addition.
- Real-world deployment across 70 apartments validates the approach on 203 rules.
Where Pith is reading between the lines
- Similar graph structures could apply to conflict management in other automated systems like industrial IoT or vehicle networks.
- Maintaining the graph might require ongoing semi-automatic updates as new devices are added.
- Future work could test if the graph allows smaller LLMs to achieve comparable performance.
Load-bearing premise
The manually or semi-automatically constructed knowledge graph correctly encodes all relevant physical cause-effect relationships and device interactions without omissions that would cause missed conflicts.
What would settle it
A set of rules involving an unencoded physical interaction, such as an unmodeled temperature effect between two devices, where the system misses a resulting conflict that manual inspection identifies.
Figures

read the original abstract
Smart home automation increasingly relies on user-defined rules across heterogeneous IoT devices. While these rules appear harmless in isolation, their concurrent execution creates hidden, cross-rule interactions via shared devices, environmental variables, and physical topology. These interactions result in unsafe, wasteful, or privacy-threatening behaviors that are completely invisible to text-only analysis. Existing conflict detectors remain siloed, catching either static syntactic conflicts or specific environment-mediated interactions without unifying the two or providing actionable repairs for non-expert users. This paper presents SHACR, a smart home conflict resolution framework that anchors Large Language Model (LLM) unpredictability by grounding its reasoning in a formal, directed knowledge graph. SHACR encodes devices, capabilities, physical states, and Trigger-Condition-Action rules as typed, traversable entities. By elevating physical cause-effect relationships to first-class graph edges, SHACR transforms conflict detection from fragile text inference into deterministic multi-hop graph traversal, unifying logical, semantic, and physical conflict classes. It drives a closed-loop Scan-Explain-Repair-Validate workflow that uses the graph to bound the LLM's action space. We evaluated SHACR on a testbed of 203 rules deployed across 70 apartments within a smart building. By holding the underlying LLM fixed and introducing SHACR's knowledge graph, classification errors drop by 36.7\%, F1 rises from 0.59 to 0.79, and few-shot calibration further lifts F1 to 0.95, whereas the same calibration barely helps a graph-free LLM. Ultimately, this work challenges the current AI paradigm, establishing that structured knowledge representation is a far more critical factor for dependable IoT automation management than prompt engineering or underlying model architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHACR, a framework for multi-class conflict resolution in smart home IoT automation that augments LLMs with a directed knowledge graph encoding devices, capabilities, physical states, and Trigger-Condition-Action rules as typed entities. Physical cause-effect relationships are elevated to graph edges to enable deterministic multi-hop traversal for unifying logical, semantic, and physical conflicts. A closed-loop Scan-Explain-Repair-Validate workflow bounds the LLM. On a testbed of 203 rules across 70 apartments, holding the LLM fixed while adding the graph reduces classification errors by 36.7%, raises F1 from 0.59 to 0.79, and reaches 0.95 with few-shot calibration (versus minimal gain without the graph), supporting the claim that structured knowledge representation outweighs prompt engineering or model architecture.
Significance. If the quantitative gains prove robust and the knowledge graph is verifiably complete, the work would be significant for IoT automation by offering a concrete method to detect interactions invisible to text-only analysis. The controlled comparison (LLM fixed, graph varied) and reproducible testbed provide clear grounding for attributing gains to structured representation rather than scaling. This could influence hybrid symbolic-neural designs in physical domains, though the paradigm-challenging assertion requires the completeness assumption to hold.
major comments (2)
- [Abstract] Abstract, third paragraph: the reported F1 lift (0.59 → 0.79) and 36.7% error reduction are attributed to introducing the knowledge graph while holding the LLM fixed, yet the text supplies no methodological details on baseline definitions, conflict labeling process, error analysis, or statistical tests. This directly weakens assessment of whether the gains are robust and load-bearing for the central claim that graph structure outweighs architecture.
- [Evaluation] Evaluation section (as described in abstract): the performance claims and the assertion that 'structured knowledge representation is a far more critical factor' rest on the assumption that the (manually or semi-automatically) constructed knowledge graph encodes all relevant physical cause-effect relationships, device interactions, and topology edges without omissions. No independent validation or completeness check is described; any missed edge would allow conflicts to evade the Scan-Explain-Repair-Validate loop while still producing the reported F1 improvement on the covered subset, undermining both the quantitative result and the broader paradigm challenge.
minor comments (1)
- [Abstract] The abstract could more explicitly separate the contributions of the graph-augmented traversal from the overall workflow to clarify what is being isolated in the controlled comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for improving methodological transparency. We address each point below and commit to revisions that strengthen the paper without misrepresenting the original contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract, third paragraph: the reported F1 lift (0.59 → 0.79) and 36.7% error reduction are attributed to introducing the knowledge graph while holding the LLM fixed, yet the text supplies no methodological details on baseline definitions, conflict labeling process, error analysis, or statistical tests. This directly weakens assessment of whether the gains are robust and load-bearing for the central claim that graph structure outweighs architecture.
Authors: We agree that the abstract's brevity omits key methodological details and that the Evaluation section would benefit from expanded exposition. The baseline is explicitly the identical LLM without graph access, as stated in the controlled comparison. Conflict labeling was performed by two IoT domain experts on the 203-rule set with documented inter-annotator agreement; error analysis appears via per-class breakdowns and case studies. In revision we will add a dedicated Evaluation subsection describing the labeling protocol, baseline configurations, and statistical significance testing (McNemar's test on paired error rates) to make the robustness claims fully verifiable. revision: yes
-
Referee: [Evaluation] Evaluation section (as described in abstract): the performance claims and the assertion that 'structured knowledge representation is a far more critical factor' rest on the assumption that the (manually or semi-automatically) constructed knowledge graph encodes all relevant physical cause-effect relationships, device interactions, and topology edges without omissions. No independent validation or completeness check is described; any missed edge would allow conflicts to evade the Scan-Explain-Repair-Validate loop while still producing the reported F1 improvement on the covered subset, undermining both the quantitative result and the broader paradigm challenge.
Authors: We accept that the absence of an explicit completeness argument is a limitation. The graph was assembled from device datasheets, manufacturer APIs, building topology records, and physical laws, followed by expert review against the testbed rules. While an exhaustive external oracle for every conceivable physical interaction is impractical, the 203-rule testbed was curated to span representative conflict classes. In the revised manuscript we will insert a graph-construction subsection and a limitations paragraph that (a) details the semi-automatic pipeline, (b) enumerates potential omission sources, and (c) explains how the closed-loop workflow can surface missed edges via LLM-assisted discovery. This addresses transparency while preserving the empirical comparison. revision: partial
Circularity Check
No circularity; empirical comparison holds LLM fixed while measuring graph contribution.
full rationale
The paper presents an empirical framework evaluated by holding the underlying LLM fixed and measuring performance lift from adding the knowledge graph on a 203-rule testbed. No equations, self-definitional constructs, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described derivation. The central claim rests on observable F1 gains (0.59 to 0.79) rather than any reduction to inputs by construction, making the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
There’s no place like home: Under- standing users’ intentions toward securing Internet-of-Things (IoT) smart home networks,
S. J. Philip, T. J. Luu, and T. Carte, “There’s no place like home: Under- standing users’ intentions toward securing Internet-of-Things (IoT) smart home networks,”Computers in Human Behavior, vol. 139, p. 107551, 2023
2023
-
[2]
AutoIoT: Automated IoT platform using large language models,
Y . Cheng et al., “AutoIoT: Automated IoT platform using large language models,”IEEE Internet of Things Journal, 2024
2024
-
[3]
SAFE-TAP: Semantic-aware and fused embedding for TAP rule security detection,
Z. Kuang et al., “SAFE-TAP: Semantic-aware and fused embedding for TAP rule security detection,”Neurocomputing, p. 131529, 2025
2025
-
[4]
Anomaly detection in smart IoT systems based on con- textual semantics of behavior graphs,
Q. Lin et al., “Anomaly detection in smart IoT systems based on con- textual semantics of behavior graphs,”IEEE Internet of Things Journal, 2024
2024
-
[5]
Home automation in the wild: Challenges and opportunities,
A. J. B. Brush et al., “Home automation in the wild: Challenges and opportunities,” inProc. SIGCHI Conf. Human Factors in Computing Systems (CHI), pp. 2115–2124, 2011. IEEE INTERNET OF THINGS JOURNAL 16
2011
-
[6]
IoT-Praetor: Undesired behaviors detection for IoT devices,
J. Wang et al., “IoT-Praetor: Undesired behaviors detection for IoT devices,”IEEE Internet of Things Journal, vol. 8, no. 2, pp. 927–940, 2020
2020
-
[7]
Fine-grained conflict detection of IoT services,
D. Chaki and A. Bouguettaya, “Fine-grained conflict detection of IoT services,” inProc. IEEE Int. Conf. Services Computing (SCC), pp. 321– 328, 2020
2020
-
[8]
SeIoT: Detecting anomalous semantics in smart homes via knowledge graph,
R. Li et al., “SeIoT: Detecting anomalous semantics in smart homes via knowledge graph,”IEEE Trans. Information Forensics and Security, 2024
2024
-
[9]
TapChecker: A lightweight SMT-based conflict analysis for trigger-action programming,
L. Chen et al., “TapChecker: A lightweight SMT-based conflict analysis for trigger-action programming,”IEEE Internet of Things Journal, vol. 11, no. 12, pp. 21411–21426, 2024
2024
-
[10]
On the safety of IoT device physical interaction control,
W. Ding and H. Hu, “On the safety of IoT device physical interaction control,” inProc. ACM SIGSAC Conf. Computer and Communications Security (CCS), pp. 832–846, 2018
2018
-
[11]
IoTC 2: A formal method approach for detecting conflicts in large scale IoT systems,
A. Al Farooq et al., “IoTC 2: A formal method approach for detecting conflicts in large scale IoT systems,” inProc. IFIP/IEEE Symp. Integrated Network and Service Management (IM), pp. 442–447, 2019
2019
-
[12]
VISCR: Intuitive & conflict-free automation for securing the dynamic consumer IoT infrastructures,
V . Nagendra et al., “VISCR: Intuitive & conflict-free automation for securing the dynamic consumer IoT infrastructures,”arXiv:1907.13288, 2019
-
[13]
IoTSafe: Enforcing safety and security policy with real IoT physical interaction discovery,
W. Ding, H. Hu, and L. Cheng, “IoTSafe: Enforcing safety and security policy with real IoT physical interaction discovery,” inProc. Network and Distributed System Security Symp. (NDSS), 2021
2021
-
[14]
Multi-platform application interaction extraction for IoT devices,
Z. Chen et al., “Multi-platform application interaction extraction for IoT devices,” inProc. IEEE 25th Int. Conf. Parallel and Distributed Systems (ICPADS), pp. 990–995, 2019
2019
-
[15]
Detecting and handling IoT interaction threats in multi-platform multi-control-channel smart homes,
H. Chi, Q. Zeng, and X. Du, “Detecting and handling IoT interaction threats in multi-platform multi-control-channel smart homes,” inProc. 32nd USENIX Security Symposium, pp. 1559–1576, 2023
2023
-
[16]
Generating HomeAssistant automations using an LLM-based chatbot,
M. Giudici et al., “Generating HomeAssistant automations using an LLM-based chatbot,”arXiv:2505.02802, 2025
-
[17]
Leveraging large language models for en- hanced personalised user experience in smart homes,
J. Rey-Jouanchicot et al., “Leveraging large language models for en- hanced personalised user experience in smart homes,”arXiv:2407.12024, 2024
-
[18]
Leveraging retrieval-augmented generation for automated smart home orchestration,
N. Jahanbakhsh et al., “Leveraging retrieval-augmented generation for automated smart home orchestration,”Future Internet, vol. 17, no. 5, p. 198, 2025
2025
-
[19]
Y . Dong et al., “ChatIoT: Large language model-based security as- sistant for Internet of Things with retrieval-augmented generation,” arXiv:2502.09896, 2025
-
[20]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 9459–9474, 2020
2020
-
[21]
Knowledge graphs and large language models: A survey,
J. Pan et al., “Knowledge graphs and large language models: A survey,” Machine Learning, Springer, 2025
2025
-
[22]
KAG: Boosting LLMs in professional domains via knowledge augmented generation,
L. Liang et al., “KAG: Boosting LLMs in professional domains via knowledge augmented generation,” inCompanion Proc. ACM Web Con- ference 2025, pp. 334–343, 2025
2025
-
[23]
Retrieval augmented language model pre-training,
K. Guu et al., “Retrieval augmented language model pre-training,” in Proc. Int. Conf. Machine Learning (ICML), pp. 3929–3938, 2020
2020
-
[24]
Knowledge graph prompting for multi-document question answering,
Y . Wang et al., “Knowledge graph prompting for multi-document question answering,” inProc. AAAI Conf. Artificial Intelligence, vol. 38, pp. 19206–19214, 2024
2024
-
[25]
Principles of smart home control,
S. Davidoff et al., “Principles of smart home control,” inProc. 8th Int. Conf. Ubiquitous Computing (UbiComp), 2006
2006
-
[26]
Supporting mental model accuracy in trigger-action programming,
J. Huang and M. Cakmak, “Supporting mental model accuracy in trigger-action programming,” inProc. ACM Int. Joint Conf. Pervasive and Ubiquitous Computing (UbiComp), 2015
2015
-
[27]
Supporting end users to control their smart home,
D. Caivano et al., “Supporting end users to control their smart home,” Journal of Systems and Software, 2019
2019
-
[28]
When smart devices are stupid: Negative experiences using home smart devices,
W. He et al., “When smart devices are stupid: Negative experiences using home smart devices,” inProc. IEEE Security and Privacy Workshops (SafeThings), 2019
2019
-
[29]
How users interpret bugs in trigger-action programming,
W. Brackenbury et al., “How users interpret bugs in trigger-action programming,” inProc. CHI Conf. Human Factors in Computing Systems, 2019
2019
-
[30]
‘We just use what they give us’: Understanding passenger user perspectives in smart homes,
V . Koshy et al., “‘We just use what they give us’: Understanding passenger user perspectives in smart homes,” inProc. CHI Conf. Human Factors in Computing Systems, 2021
2021
-
[31]
Helping users debug trigger-action programs,
L. Zhang et al., “Helping users debug trigger-action programs,”Proc. ACM on IMWUT, vol. 6, no. 4, p. 196, 2022
2022
-
[32]
Complexity of smart home setups,
E. Becks et al., “Complexity of smart home setups,”Technologies, vol. 11, no. 1, p. 9, 2023
2023
-
[33]
A user-centric evaluation of smart home resolution approaches for conflicts between routines,
Z. Zaidi et al., “A user-centric evaluation of smart home resolution approaches for conflicts between routines,”Proc. ACM on IMWUT, vol. 7, no. 1, p. 45, 2023
2023
-
[34]
From frustration to function: A study on usability challenges in smart home IoT devices,
L. Y . Hao et al., “From frustration to function: A study on usability challenges in smart home IoT devices,” inProc. IEEE Consumer Com- munications and Networking Conf. (CCNC), 2024
2024
-
[35]
Connecting the dots: How users understand and diagnose smart home ecosystems,
M. P. Wo ´zniak et al., “Connecting the dots: How users understand and diagnose smart home ecosystems,”Int. Journal of Human-Computer Studies, vol. 203, p. 103559, 2025
2025
-
[36]
Exploring end users’ perceptions of smart lock automation,
H. Hazazi and M. Shehab, “Exploring end users’ perceptions of smart lock automation,” inProc. European Symp. Usable Security (EuroUSEC), pp. 112–124, 2024
2024
-
[37]
Language models are few-shot learners,
T. B. Brown et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1877–1901, 2020
1901
-
[38]
Zero- and few-shot NLP with pretrained language models,
I. Beltagy et al., “Zero- and few-shot NLP with pretrained language models,” inProc. 60th Annual Meeting of ACL: Tutorial Abstracts, pp. 1– 7, 2022
2022
-
[39]
A survey of graph retrieval-augmented generation for customized large language models,
Q. Zhang, S. Chen, Y . Bei, Z. Yuan, H. Zhou, Z. Hong, H. Chen, Y . Xiao, C. Zhou, J. Dong et al., “A survey of graph retrieval-augmented generation for customized large language models,”arXiv preprint arXiv:2501.13958, 2025
-
[40]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
A. Singh, A. Ehtesham, S. Kumar, T. T. Khoei, and A. V . Vasilakos, “Agentic retrieval-augmented generation: A survey on agentic RAG,” arXiv preprint arXiv:2501.09136, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Model Context Protocol: An open standard for connecting AI assistants to tools and data sources,
Anthropic, “Model Context Protocol: An open standard for connecting AI assistants to tools and data sources,”Anthropic Technical Documen- tation, 2024. [Online]. Available: https://modelcontextprotocol.io
2024
-
[42]
HomeAssistantExamples: Home Assistant automations and examples,
T. Wald, “HomeAssistantExamples: Home Assistant automations and examples,” GitHub repository,airtouch4-deprecated directory. [Online]. Available: https://github.com/tomwaldnz/ HomeAssistantExamples/tree/main/automations/airtouch4-deprecated. [Accessed: 20-Jun-2026]
2026
-
[43]
Automations in Y AML,
Home Assistant, “Automations in Y AML,” Home Assistant Documenta- tion. [Online]. Available: https://www.home-assistant.io/docs/automation/ yaml/. [Accessed: 20-Jun-2026]
2026
-
[44]
Sample-RulesAPI,
SmartThings Developers, “Sample-RulesAPI,” GitHub repository, Sam- sung SmartThings Developer Programs. [Online]. Available: https: //github.com/SmartThingsDevelopers/Sample-RulesAPI. [Accessed: 20- Jun-2026]. PLACE PHOTO HERE Leena A. Marghalanireceived her M.S. degree in Security and Information Assurance from King Fahd University of Petroleum and Miner...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.