ARP: Enhancing Quantized Skill Abstractions via Visual Alignment and Iterative Refinement for Robotic Manipulation
Pith reviewed 2026-06-26 10:12 UTC · model grok-4.3
The pith
ARP improves discrete robot skills by aligning visuals to actions and iteratively refining outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
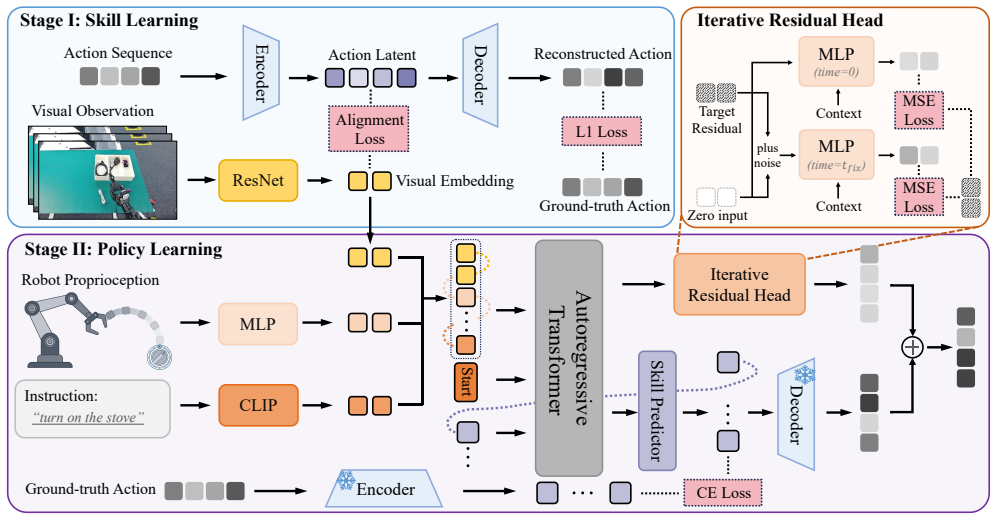
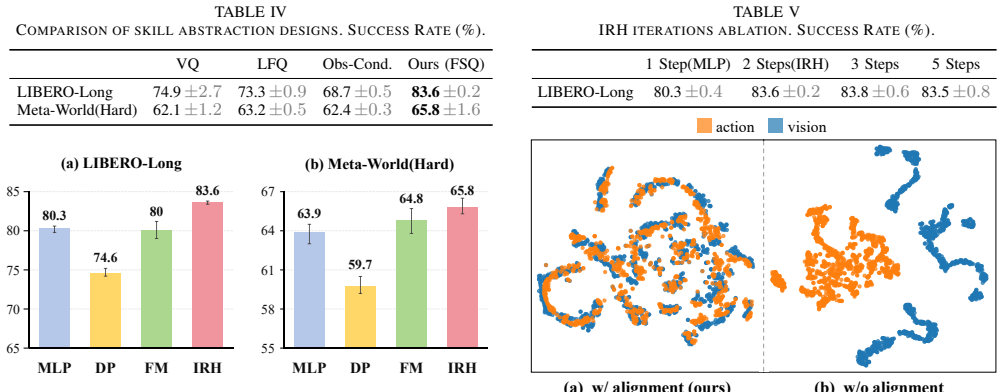
ARP is a discrete-skill framework that couples semantic grounding with execution-level refinement: a visual-action alignment objective contrastively aligns visual embeddings with pre-quantized action representations in a shared latent space, and a lightweight Iterative Residual Head performs two-step refinement to recover fine-grained control, yielding state-of-the-art results on LIBERO and Meta-World while showing gains on real-robot tasks.
What carries the argument
The visual-action alignment objective together with the Iterative Residual Head (IRH), which together ground skill selection in vision and correct quantization errors during continuous action generation.
If this is right
- Quantized skill policies can achieve higher success rates on long-horizon manipulation benchmarks without switching to fully continuous representations.
- Skill selection becomes more reliable when visual observations are explicitly aligned with action codes in latent space.
- Fine-grained control can be restored post-quantization via lightweight iterative correction rather than heavier model changes.
- Real-robot deployment of discrete skills becomes more viable when both grounding and precision issues are addressed together.
Where Pith is reading between the lines
- The same alignment-plus-refinement pattern could apply to other discrete representation problems where perception must guide action selection.
- If the state-independent decoder remains intact, the method may scale to settings with partial observability or changing environments.
- Future work could test whether the Iterative Residual Head generalizes across different quantization schemes or robot morphologies.
Load-bearing premise
The visual-action alignment improves skill selection without breaking the state-independent decoder, and the Iterative Residual Head recovers precision without introducing instability or new error modes.
What would settle it
An ablation study on the LIBERO benchmark showing that removing either the alignment objective or the Iterative Residual Head eliminates the reported performance gains over baselines would falsify the claim.
Figures



read the original abstract
Learning visuomotor policies for long-horizon manipulation remains a fundamental challenge. Recent skill-based imitation learning methods based on discrete quantization have shown promising results by representing complex behaviors as temporally extended skills. However, most existing approaches primarily encode action trajectories into latent skills, yielding weak visual-semantic grounding and limiting the ability to leverage visual observations for skill selection. Moreover, discrete tokenization inevitably incurs precision errors during continuous action generation. To alleviate these issues, we propose Aligned Refinement Policy (ARP), a discrete-skill framework that couples semantic grounding with execution-level refinement. Specifically, ARP introduces (i) a visual--action alignment objective that contrastively aligns visual embeddings with pre-quantized action representations in a shared latent space while preserving a state-independent skill decoder, and (ii) a lightweight Iterative Residual Head (IRH) that performs a two-step refinement to recover fine-grained control for precise execution. Extensive experiments show that ARP achieves state-of-the-art performance on the LIBERO and Meta-World benchmarks. Moreover, real-robot experiments on the Kuavo 4 Pro humanoid platform further validate its effectiveness, yielding consistent performance gains over several baselines on two challenging manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Aligned Refinement Policy (ARP), a discrete-skill imitation learning framework for long-horizon robotic manipulation. It augments quantized skill methods with (i) a contrastive visual-action alignment objective that grounds pre-quantized action representations in visual embeddings while preserving a state-independent skill decoder, and (ii) a lightweight Iterative Residual Head (IRH) that performs two-step residual refinement to mitigate precision loss in continuous action generation. The central empirical claims are state-of-the-art results on the LIBERO and Meta-World benchmarks plus consistent gains over baselines on two real-robot tasks using the Kuavo 4 Pro humanoid.
Significance. If the reported gains hold under rigorous controls, the work would provide a practical route to improve visual grounding and execution precision in quantized skill policies without sacrificing the modularity of state-independent decoders. The design choices (contrastive alignment in a shared latent space and residual refinement) are directly motivated by the stated limitations and could be adopted by other skill-based methods.
minor comments (2)
- [Abstract] Abstract: the phrase 'yielding consistent performance gains' would be strengthened by reporting the magnitude of improvement (e.g., success-rate deltas) rather than qualitative language.
- [Experiments] The manuscript would benefit from an explicit statement of the number of random seeds and statistical tests used for the benchmark tables to allow readers to assess the reliability of the SOTA claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and method description introduce ARP as an extension to existing quantized skill methods via two explicit additions: a contrastive visual-action alignment objective (preserving state-independent decoding) and a lightweight Iterative Residual Head for refinement. No equations, self-citations, or claims reduce a prediction or uniqueness result to a fitted parameter or prior self-work by construction. The SOTA and real-robot results are presented as empirical outcomes on external benchmarks, with no load-bearing step that renames or re-derives its own inputs. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Robotics: Science and Systems, 2023
2023
-
[3]
Improving robotic grasp detection under sparse annotations via grasp transformer with pixel-wise contrastive learning,
S. Liu, Y . Liu, Z. Chen, Z. Zhou, Z. Zhao, Y . Xie, W. Li, and Z. Gan, “Improving robotic grasp detection under sparse annotations via grasp transformer with pixel-wise contrastive learning,”IEEE Transactions on Industrial Electronics, 2025
2025
-
[4]
S. Jin, Y . Wang, Y . Duan, D. Wu, G. Dong, X. Liu, X. Li, H. Jia, Z. Zhang, T. Wanget al., “Umi-bench 1.0: An open and reproducible real-world benchmark for tabletop robotic manipulation with umi data,” arXiv preprint arXiv:2606.10382, 2026
Pith/arXiv arXiv 2026
-
[5]
Imitation learning: Progress, taxonomies and challenges,
B. Zheng, S. Verma, J. Zhou, I. W. Tsang, and F. Chen, “Imitation learning: Progress, taxonomies and challenges,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 5, pp. 6322–6337, 2022
2022
-
[6]
Rethinking mutual information for language conditioned skill discovery on imitation learning,
Z. Ju, C. Yang, F. Sun, H. Wang, and Y . Qiao, “Rethinking mutual information for language conditioned skill discovery on imitation learning,” inProceedings of the International Conference on Auto- mated Planning and Scheduling, vol. 34, 2024, pp. 301–309
2024
-
[7]
Lisa: Learning interpretable skill abstractions from language,
D. Garg, S. Vaidyanath, K. Kim, J. Song, and S. Ermon, “Lisa: Learning interpretable skill abstractions from language,”Advances in Neural Information Processing Systems, vol. 35, pp. 21 711–21 724, 2022
2022
-
[8]
Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,
Z. Liang, Y . Mu, H. Ma, M. Tomizuka, M. Ding, and P. Luo, “Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 467–16 476
2024
-
[9]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[10]
Behavior generation with latent actions,
S. Lee, Y . Wang, H. Etukuru, H. J. Kim, N. M. M. Shafiullah, and L. Pinto, “Behavior generation with latent actions,”arXiv preprint arXiv:2403.03181, 2024
arXiv 2024
-
[11]
Quest: Self- supervised skill abstractions for learning continuous control,
A. Mete, H. Xue, A. Wilcox, Y . Chen, and A. Garg, “Quest: Self- supervised skill abstractions for learning continuous control,”Advances in Neural Information Processing Systems, vol. 37, pp. 4062–4089, 2024
2024
-
[12]
Discrete policy: Learning disentangled action space for multi-task robotic manipulation,
K. Wu, Y . Zhu, J. Li, J. Wen, N. Liu, Z. Xu, and J. Tang, “Discrete policy: Learning disentangled action space for multi-task robotic manipulation,” in2025 IEEE ICRA. IEEE, 2025, pp. 8811–8818
2025
-
[13]
Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,”Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[14]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” inConference on robot learning. PMLR, 2020, pp. 1094–1100
2020
-
[15]
Decision transformer: Reinforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,”Advances in neural information processing systems, vol. 34, pp. 15 084–15 097, 2021
2021
-
[16]
Behavior transformers: Cloningkmodes with one stone,
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto, “Behavior transformers: Cloningkmodes with one stone,”Advances in neural information processing systems, vol. 35, pp. 22 955–22 968, 2022
2022
-
[17]
Diffskill: Improving reinforcement learning through diffusion-based skill denoiser for robotic manipulation,
S. Liu, Y . Liu, L. Hu, Z. Zhou, Y . Xie, Z. Zhao, W. Li, and Z. Gan, “Diffskill: Improving reinforcement learning through diffusion-based skill denoiser for robotic manipulation,”Knowledge-Based Systems, vol. 300, p. 112190, 2024
2024
-
[18]
Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation,
Q. Zhang, Z. Liu, H. Fan, G. Liu, B. Zeng, and S. Liu, “Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 39, no. 14, 2025, pp. 14 754–14 762
2025
-
[19]
Consistency policy: Accelerated visuomotor policies via consistency distillation,
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg, “Consistency policy: Accelerated visuomotor policies via consistency distillation,”arXiv preprint arXiv:2405.07503, 2024
arXiv 2024
-
[20]
One-step diffusion policy: Fast visuomotor policies via diffusion distillation,
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y . Narang, L. Fan, Y . Zhu, Y . Balaji, M. Zhouet al., “One-step diffusion policy: Fast visuomotor policies via diffusion distillation,”arXiv preprint arXiv:2410.21257, 2024
arXiv 2024
-
[21]
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation,
J. Sheng, Z. Wang, P. Li, and M. Liu, “Mp1: Meanflow tames policy learning in 1-step for robotic manipulation,”arXiv preprint arXiv:2507.10543, 2025
arXiv 2025
-
[22]
Maniflow: A general robot manipulation policy via consistency flow training,
G. Yan, J. Zhu, Y . Deng, S. Yang, R.-Z. Qiu, X. Cheng, M. Memmel, R. Krishna, A. Goyal, X. Wanget al., “Maniflow: A general robot manipulation policy via consistency flow training,”arXiv preprint arXiv:2509.01819, 2025
arXiv 2025
-
[23]
Much ado about noising: Dispelling the myths of generative robotic control,
C. Pan, G. Anantharaman, N.-C. Huang, C. Jin, D. Pfrommer, C. Yuan, F. Permenter, G. Qu, N. Boffi, G. Shiet al., “Much ado about noising: Dispelling the myths of generative robotic control,”arXiv preprint arXiv:2512.01809, 2025
arXiv 2025
-
[24]
Efficient planning in a compact latent action space,
Z. Jiang, T. Zhang, M. Janner, Y . Li, T. Rockt ¨aschel, E. Grefenstette, and Y . Tian, “Efficient planning in a compact latent action space,” arXiv preprint arXiv:2208.10291, 2022
arXiv 2022
-
[25]
H-gap: Humanoid control with a gener- alist planner,
Z. Jiang, Y . Xu, N. Wagener, Y . Luo, M. Janner, E. Grefenstette, T. Rockt¨aschel, and Y . Tian, “H-gap: Humanoid control with a gener- alist planner,”arXiv preprint arXiv:2312.02682, 2023
arXiv 2023
-
[26]
Prise: Llm-style sequence compression for learning temporal action abstractions in control,
R. Zheng, C.-A. Cheng, H. Daum ´e III, F. Huang, and A. Kolobov, “Prise: Llm-style sequence compression for learning temporal action abstractions in control,”arXiv preprint arXiv:2402.10450, 2024
arXiv 2024
-
[27]
Oat: Ordered action tokenization,
C. Liu, X. Han, J. Gao, Y . Zhao, H. Chen, and Y . Du, “Oat: Ordered action tokenization,”arXiv preprint arXiv:2602.04215, 2026
arXiv 2026
-
[28]
Star: Learning diverse robot skill abstractions through rotation-augmented vector quantization,
H. Li, Q. Lv, R. Shao, X. Deng, Y . Li, J. Hao, and L. Nie, “Star: Learning diverse robot skill abstractions through rotation-augmented vector quantization,”arXiv preprint arXiv:2506.03863, 2025
Pith/arXiv arXiv 2025
-
[29]
Masked generative policy for robotic control,
L. Zhuang, S. Fan, F. P. Audonnet, Y . Ru, G. A. Camarasa, and P. Henderson, “Masked generative policy for robotic control,”arXiv preprint arXiv:2512.09101, 2025
arXiv 2025
-
[30]
Primary-fine de- coupling for action generation in robotic imitation,
X. Lei, M. Wang, W. Zhou, X. Lu, and H. Li, “Primary-fine de- coupling for action generation in robotic imitation,”arXiv preprint arXiv:2602.21684, 2026
arXiv 2026
-
[31]
Carp: Visuomotor policy learning via coarse-to-fine autore- gressive prediction,
Z. Gong, P. Ding, S. Lyu, S. Huang, M. Sun, W. Zhao, Z. Fan, and D. Wang, “Carp: Visuomotor policy learning via coarse-to-fine autore- gressive prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13 460–13 470
2025
-
[32]
Learning semantic atomic skills for multi-task robotic manipulation,
Y . Zhu, W. Wang, S. Wu, Y . Shi, and J. Wang, “Learning semantic atomic skills for multi-task robotic manipulation,”arXiv preprint arXiv:2512.18368, 2025
arXiv 2025
-
[33]
Finite scalar quantization: Vq-vae made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Finite scalar quantization: Vq-vae made simple,”arXiv preprint arXiv:2309.15505, 2023
Pith/arXiv arXiv 2023
-
[34]
Vq-vla: Improving vision-language-action models via scaling vector-quantized action tokenizers,
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He, “Vq-vla: Improving vision-language-action models via scaling vector-quantized action tokenizers,”arXiv preprint arXiv:2507.01016, 2025
arXiv 2025
-
[35]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[36]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[37]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[38]
Octo: An open-source generalist robot policy,
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[39]
Open- vla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Open- vla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[40]
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang, “Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies,”arXiv preprint arXiv:2412.10345, 2024
Pith/arXiv arXiv 2024
-
[41]
Spatialvla: Exploring spatial representations for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wanget al., “Spatialvla: Exploring spatial representations for visual-language-action model,”arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[42]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,”arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[43]
Language model beats diffusion–tokenizer is key to visual generation,
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y . Cheng, V . Birodkar, A. Gupta, X. Guet al., “Language model beats diffusion–tokenizer is key to visual generation,”arXiv preprint arXiv:2310.05737, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.