Logistic Gaussian process density regression: a generalized Bayesian approach
Pith reviewed 2026-06-26 07:48 UTC · model grok-4.3
The pith
Hyvarinen score loss lets logistic Gaussian process density regression skip all normalizing constant calculations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a generalized Bayesian posterior constructed from the Hyvarinen score supplies valid inference for logistic Gaussian process density regression while completely removing the need to compute the normalizing constant of the density for every observation; sparse variational approximations then render the method feasible for large datasets.
What carries the argument
Hyvarinen score loss function, which depends only on derivatives of the log density with respect to the response.
If this is right
- The model can be centered on a parametric base density so that the Gaussian process component acts as an interpretable correction for model criticism.
- Computation scales to hundreds of thousands of observations once inducing-point and variational approximations are applied.
- The same loss construction applies to any density model whose log-density derivatives are tractable even when the normalizing constant is not.
- Posterior predictive checks and uncertainty quantification remain available in the generalized Bayesian framework.
Where Pith is reading between the lines
- The method could be tested on problems where the response is multivariate or the covariate dimension is high to see whether the derivative-only property continues to dominate.
- Alternative proper scoring rules that also avoid normalizing constants might be substituted for the Hyvarinen score to compare calibration properties.
- Because the approach separates the prior from the loss, it offers a route to robustify logistic GP density regression against misspecification of the base density.
Load-bearing premise
The Hyvarinen score supplies a loss that is informative enough to produce a useful generalized posterior for the density regression parameters.
What would settle it
On a small dataset where exact normalizing constants can be computed by quadrature, the generalized posterior obtained from the Hyvarinen score differs materially from the exact Bayesian posterior in location or spread of the predictive distributions.
Figures
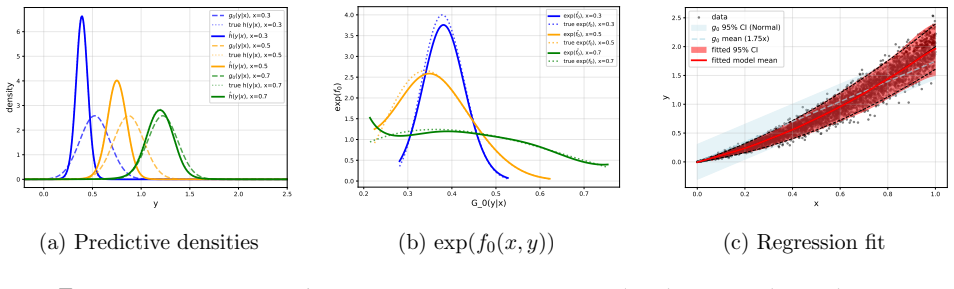
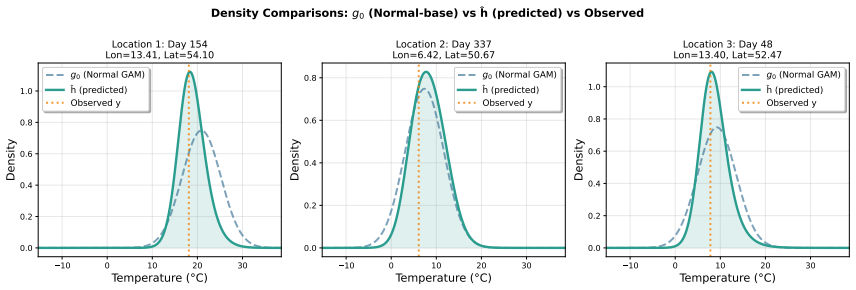
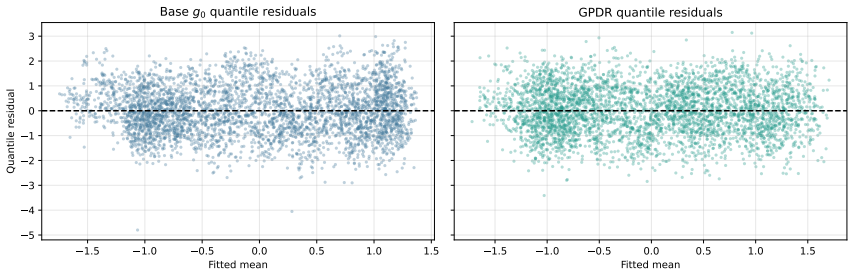
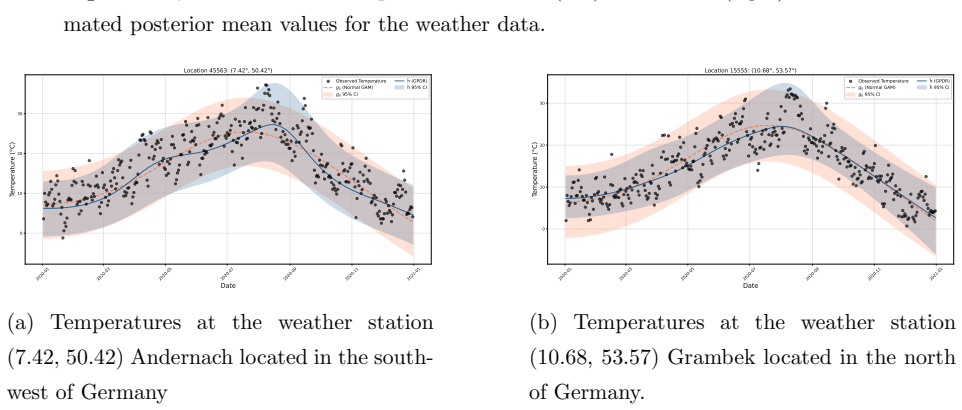
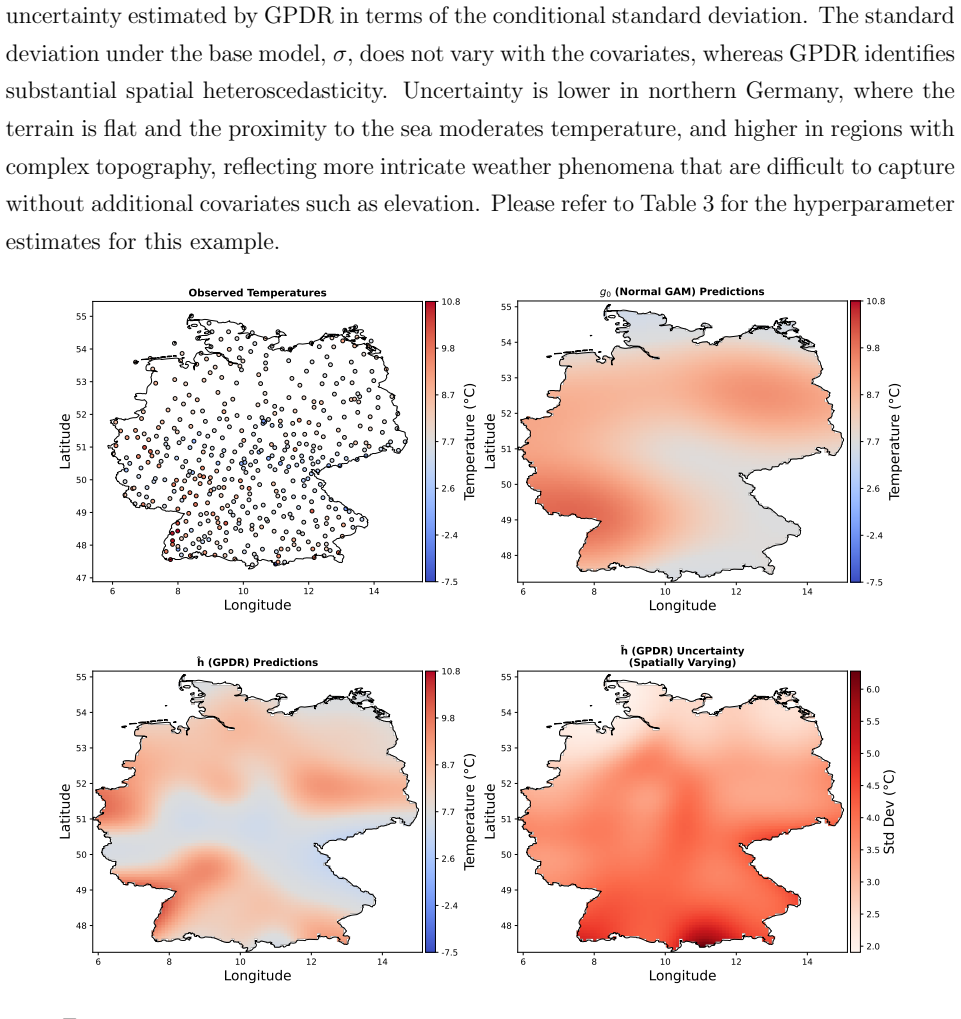
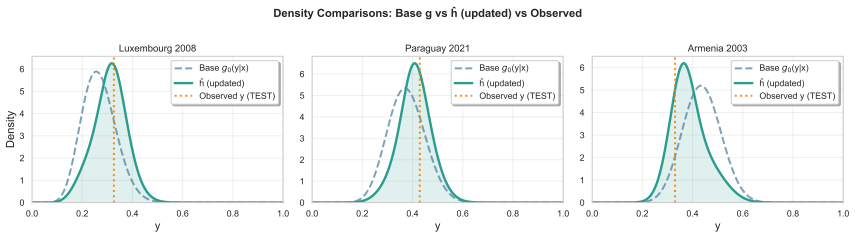
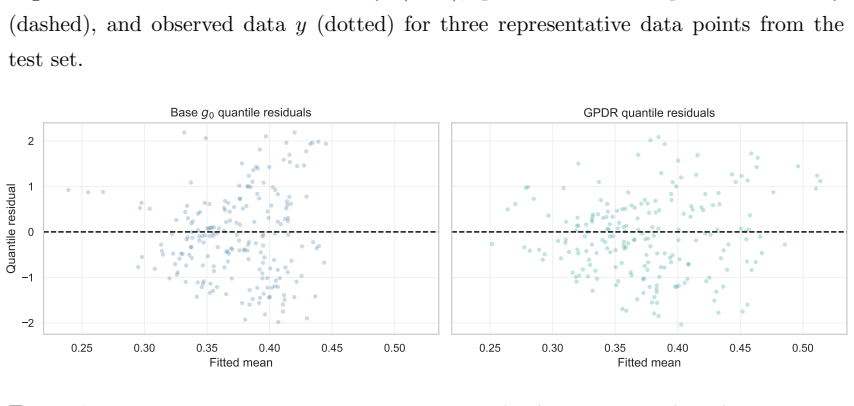
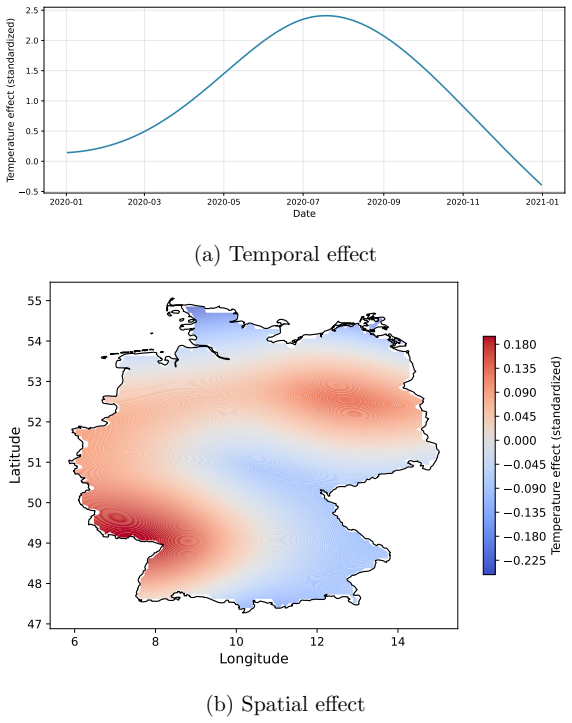
read the original abstract
Density regression extends conventional parametric regression by allowing the entire distribution of the response to vary flexibly with covariates rather than just low-order moments. In the Bayesian setting, logistic Gaussian process (GP) priors have been widely used for density estimation and extend naturally to density regression. The prior can be centred on a base density model, with the nonparametric component providing an interpretable correction that is useful for model criticism. However, logistic GP density regression models have seen limited use, since they require computation of a normalizing constant for every observation, typically via numerical integration. We address this difficulty by proposing a generalized Bayesian approach using a loss function based on the Hyvarinen score. The Hyvarinen score depends only on derivatives of the log density with respect to the response, eliminating the need to compute normalizing constants. Since GP computations remain expensive, we also employ sparse inducing point approximations and variational inference to develop a scalable approach. We demonstrate the method on one simulated and two real datasets, including a German weather dataset with more than 150,000 observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generalized Bayesian approach to logistic Gaussian process density regression that replaces the standard likelihood with a loss based on the Hyvarinen score. This score depends only on derivatives of the log-density with respect to the response variable, thereby eliminating the need to evaluate the normalizing constant for each observation. The method further incorporates sparse inducing-point approximations and variational inference to achieve scalability and is illustrated on one simulated dataset together with two real datasets, one of which contains more than 150,000 observations.
Significance. If the generalized posterior induced by the Hyvarinen score is shown to be well-calibrated and the variational approximations accurate, the work would make logistic GP density regression practically usable on large data sets where repeated numerical integration has previously been prohibitive. The approach builds on an established property of the Hyvarinen score (its independence from the partition function) and applies it to a model class that has seen limited adoption precisely because of that computational obstacle.
minor comments (2)
- [Abstract] The abstract states that the method is demonstrated on simulated and real data, but the manuscript should explicitly report calibration diagnostics (e.g., posterior predictive checks or coverage of credible intervals) for the generalized posterior to substantiate that the Hyvarinen-score loss yields reliable inference.
- Clarify the precise form of the variational family used for the inducing-point approximation when the loss is the Hyvarinen score rather than a standard likelihood; this detail is needed to assess whether the ELBO remains a valid lower bound under the generalized-Bayesian formulation.
Simulated Author's Rebuttal
We thank the referee for the positive summary of the manuscript, the recognition of its significance for scalable logistic GP density regression, and the recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central move replaces the intractable normalizing constant with the Hyvarinen score, an externally defined loss that depends only on derivatives of the log-density. This is a standard property of the score function and does not reduce to any fitted parameter or self-referential definition within the logistic GP model. The sparse inducing-point approximation and variational inference are applied as standard computational tools; no derivation step equates a claimed prediction to its own inputs by construction, nor does the argument rest on a load-bearing self-citation chain. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Holmes, Chris , TITLE =
Jewson, Jack and Smith, Jim Q. and Holmes, Chris , TITLE =. Entropy , VOLUME =. 2018 , NUMBER =
2018
-
[2]
Multi-Output Robust and Conjugate
Rooijakkers, Joshua and R. Multi-Output Robust and Conjugate. arXiv preprint arXiv:2510.26401 , year=
-
[3]
Robust and Conjugate
Altamirano, Matias and Briol, Francois-Xavier and Knoblauch, Jeremias , booktitle =. Robust and Conjugate. 2024 , editor =
2024
-
[4]
Barp, Alessandro and Briol, Francois-Xavier and Duncan, Andrew and Girolami, Mark and Mackey, Lester , booktitle =. Minimum
-
[5]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Jewson, Jack and Rossell, David , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
-
[6]
arXiv preprint arXiv:2602.11325 , year=
Amortised and provably-robust simulation-based inference , author=. arXiv preprint arXiv:2602.11325 , year=
-
[7]
and Knoblauch, Jeremias and Briol, Francois-Xavier , booktitle =
Laplante, William and Altamirano, Matias and Duncan, Andrew B. and Knoblauch, Jeremias and Briol, Francois-Xavier , booktitle =. Robust and Conjugate Spatio-Temporal. 2025 , editor =
2025
-
[8]
Robust and Scalable
Altamirano, Matias and Briol, Francois-Xavier and Knoblauch, Jeremias , booktitle =. Robust and Scalable. 2023 , editor =
2023
-
[9]
, title =
Matsubara, Takuo and Knoblauch, Jeremias and Briol, François-Xavier and Oates, Chris J. , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
-
[10]
Takuo Matsubara and Jeremias Knoblauch and François-Xavier Briol and Chris. J. Oates , title =. Journal of the American Statistical Association , volume =
-
[11]
, journal =
Alquier, P. , journal =. User-friendly introduction to
-
[12]
Wu and R
P.-S. Wu and R. Martin , journal =
-
[13]
Knoblauch and J
J. Knoblauch and J. Jewson and T. Damoulas , journal =. An Optimization-centric View on
-
[14]
and Dunson, D
Kundu, S. and Dunson, D. B. , journal =. Latent factor models for density estimation , volume =
-
[15]
De Iorio, Maria and M. An. Journal of the American Statistical Association , volume =
-
[16]
and Pillai, Natesh and Park, Ju-Hyun , title =
Dunson, David B. and Pillai, Natesh and Park, Ju-Hyun , title =. Journal of the Royal Statistical Society, Series
-
[17]
Estimation of Non-Normalized Statistical Models by Score Matching , journal =
Aapo Hyv. Estimation of Non-Normalized Statistical Models by Score Matching , journal =. 2005 , volume =
2005
-
[18]
, title =
MacEachern, Steven N. , title =. Proceedings of the Section on Bayesian Statistical Science , publisher =
-
[19]
, title =
MacEachern, Steven N. , title =
-
[20]
and Steel, Mark F
Griffin, Jim E. and Steel, Mark F. J. , title =. Journal of the American Statistical Association , volume =
-
[21]
Ferguson , title =
Thomas S. Ferguson , title =. The Annals of Statistics , number =
-
[22]
Journal of the Royal Statistical Society: Series B (Methodological) , year=
Density Estimation, Stochastic Processes and Prior Information , author=. Journal of the Royal Statistical Society: Series B (Methodological) , year=
-
[23]
Murray, Iain and MacKay, David and Adams, Ryan P , booktitle =. The
-
[24]
In: IEEE International Conference on Big Data (BigData)
Paisley, John and Zhang, Wei and Barr, Brian , booktitle =. Gaussian Process Tilted Nonparametric Density Estimation Using. 2025 , volume =. doi:10.1109/BigData66926.2025.11402378 , url =
-
[25]
Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence (UAI) , editor =
Christian Donner and Manfred Opper , title =. Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence (UAI) , editor =. 2018 , url =
2018
-
[26]
Lenk , title =
Peter J. Lenk , title =. Journal of the American Statistical Association , volume =
-
[27]
Laplace Approximation for Logistic
Jaakko Riihim. Laplace Approximation for Logistic. Bayesian Analysis , number =
-
[28]
The Annals of Statistics , number =
Isabella Verdinelli and Larry Wasserman , title =. The Annals of Statistics , number =
-
[29]
, title =
Lenk, Peter J. , title =. Biometrika , volume =
-
[30]
Journal of Computational and Graphical Statistics , volume =
Surya T Tokdar , title =. Journal of Computational and Graphical Statistics , volume =
-
[31]
Journal of Statistical Planning and Inference , volume =
Posterior consistency of logistic. Journal of Statistical Planning and Inference , volume =. 2007 , author =
2007
-
[32]
Variational Learning of Inducing Variables in Sparse
Titsias, Michalis , booktitle =. Variational Learning of Inducing Variables in Sparse
-
[33]
Scalable Inference for
Dezfouli, Amir and Bonilla, Edwin V , booktitle =. Scalable Inference for
-
[34]
Bissiri, P. G. and Holmes, C. C. and Walker, S. G. , date-added =. A general framework for updating belief distributions , volume =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , number =
-
[35]
Tokdar and Yu M
Surya T. Tokdar and Yu M. Zhu and Jayanta K. Ghosh , date-added =. Bayesian Analysis , number =
-
[36]
An Optimization-centric View on
Jeremias Knoblauch and Jack Jewson and Theodoros Damoulas , date-added =. An Optimization-centric View on. Journal of Machine Learning Research , number =. 2022 , bdsk-url-1 =
2022
-
[37]
Objective
Giummol. Objective. TEST , number =. 2019 , bdsk-url-1 =
2019
-
[38]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Probabilistic forecasts, calibration and sharpness , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2007 , publisher=
2007
-
[39]
doi:10.5281/zenodo.1208723 , url =
Daniel Servén and Charlie Brummitt , title =. doi:10.5281/zenodo.1208723 , url =
-
[40]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[41]
2025 , note =
WDI: World Development Indicators and Other World Bank Data , author =. 2025 , note =
2025
-
[42]
Beta regression in
Cribari-Neto, Francisco and Zeileis, Achim , journal=. Beta regression in
-
[43]
Journal of Applied Statistics , volume =
Silvia Ferrari and Francisco Cribari-Neto , title =. Journal of Applied Statistics , volume =. 2004 , publisher =
2004
-
[44]
Variabilit
Gini, Corrado , year=. Variabilit
-
[45]
Approximating the
Hershey, John R and Olsen, Peder A , booktitle=. Approximating the. 2007 , organization=
2007
-
[46]
International conference on machine learning , pages=
Variational boosting: Iteratively refining posterior approximations , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[47]
arXiv preprint arXiv:1611.05148 , year=
Variational deep embedding: An unsupervised and generative approach to clustering , author=. arXiv preprint arXiv:1611.05148 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.