When Robots Rate Their Own Interactions: Engagement Validity and the Strangeness Failure
Pith reviewed 2026-06-26 08:08 UTC · model grok-4.3
The pith
LLM-powered robots agree with humans on engagement ratings but systematically invert strangeness assessments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
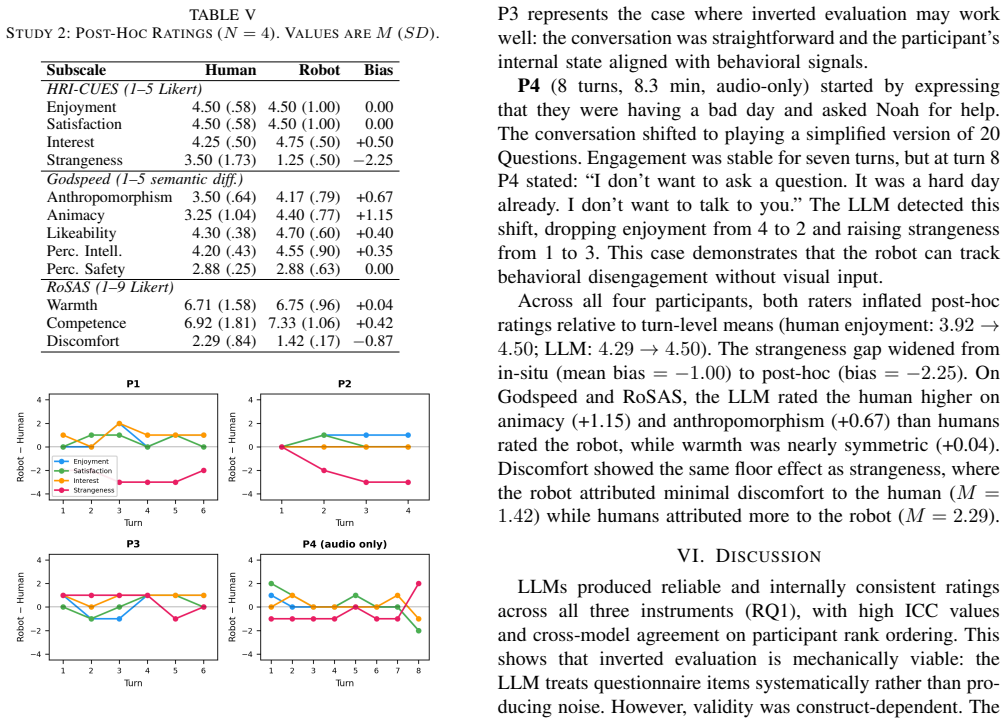
LLMs achieve moderate-to-strong agreement with humans on engagement (satisfaction r up to .65, enjoyment r up to .72) with high test-retest reliability, but invert the comfort/strangeness dimension (r = -.44 to -.67). The pattern holds across models, synthetic controls, and embodied deployment.
What carries the argument
Inverted evaluation, in which the LLM completes standardized questionnaires (HRI-CUES, Godspeed, RoSAS) from the robot's perspective for direct comparison to human ratings.
Load-bearing premise
The inversion on strangeness occurs because LLMs lack access to internal affective states rather than because of questionnaire wording or prompt artifacts.
What would settle it
Feeding the LLM physiological signals, gaze, or proxemics data during assessment and checking whether the strangeness correlation shifts from negative to positive would test the claim.
Figures

read the original abstract
Human-robot interaction (HRI) evaluation relies almost exclusively on human-completed questionnaires, leaving the robot's perspective unexamined. We propose an \textit{inverted evaluation}, in which LLM-powered robots complete the same standardized instruments from their own perspective, and test whether these ratings agree with human ground truth. In Study~1, five LLMs completed HRI-CUES, Godspeed, and RoSAS questionnaires for 25~interactions ($N = 1{,}522$ evaluations) from the HRI-CUES dataset. LLMs achieved moderate-to-strong agreement on engagement dimensions (satisfaction $r$ up to $.65$ and enjoyment $r$ up to $.72$) with excellent test-retest reliability (ICC $\geq .82$), but \textit{systematically inverted} the comfort/strangeness dimension ($r = -.44$ to $-.67$, all $p < .05$), conflating engagement with comfort. In Study~2, a Nao robot running Claude~Sonnet~4.5 replicated these patterns in live interactions ($N = 4$), including real-time turn-by-turn assessment. The strangeness failure persisted across five models, synthetic controls, and embodied deployment for two participants. We argue that current LLM-based robots lack access to the internal affective states needed to assess constructs like strangeness, and that inverted evaluation requires supplementary modalities (e.g., physiological signals, gaze, proxemics) to move beyond behavioral proxies. These findings establish boundary conditions for using LLMs as interaction evaluators in HRI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an 'inverted evaluation' method in which LLM-powered robots complete standard HRI questionnaires (HRI-CUES, Godspeed, RoSAS) from the robot's perspective and compares these ratings to human ground truth. Study 1 has five LLMs rate 25 interactions from the HRI-CUES dataset (1,522 total evaluations), finding moderate-to-strong agreement on engagement dimensions (satisfaction r up to .65, enjoyment r up to .72, ICC ≥ .82) but systematic inversion on comfort/strangeness (r = -.44 to -.67, all p < .05). Study 2 replicates the pattern in live Nao robot interactions (N=4) using Claude Sonnet 4.5 with real-time assessment. The authors conclude that LLMs lack access to internal affective states for constructs like strangeness and therefore require supplementary modalities (physiological signals, gaze, proxemics) beyond behavioral proxies.
Significance. If the inversion pattern is robust, the work supplies concrete boundary conditions for deploying LLMs as interaction evaluators in HRI. The consistency across five models plus the embodied live-robot replication constitutes a strength of the empirical design. The findings could usefully caution against sole reliance on LLM self-ratings for affective dimensions and motivate multimodal extensions, provided the causal attribution is clarified.
major comments (2)
- [Abstract (argument paragraph)] Abstract (argument paragraph): The claim that the negative correlations on comfort/strangeness reflect LLMs' lack of 'access to the internal affective states' (rather than questionnaire wording, prompt construction, or training-data artifacts) is invoked to justify the recommendation for supplementary modalities. No ablation is reported that isolates this factor (e.g., prompt variants supplying simulated internal-state signals, rephrased strangeness items, or non-LLM baselines also lacking embodiment). This interpretive step is load-bearing for the central boundary-condition argument.
- [Study 2] Study 2: The live-robot replication is conducted with N=4, yet the abstract supplies no error bars, exclusion criteria, or full statistical tables for these trials. Given that the inversion pattern is asserted to persist 'across ... embodied deployment,' the small sample size and limited reporting undermine the strength of the embodied evidence relative to the larger Study 1 dataset.
minor comments (2)
- [Abstract] Abstract: The statement that the strangeness failure 'persisted across five models, synthetic controls, and embodied deployment for two participants' does not define the synthetic controls or clarify why only two of the four participants are referenced for the embodied case.
- [Abstract] Abstract: Correlation values are reported without accompanying sample sizes per dimension or confidence intervals, reducing transparency even though overall N=1,522 is stated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract (argument paragraph)] Abstract (argument paragraph): The claim that the negative correlations on comfort/strangeness reflect LLMs' lack of 'access to the internal affective states' (rather than questionnaire wording, prompt construction, or training-data artifacts) is invoked to justify the recommendation for supplementary modalities. No ablation is reported that isolates this factor (e.g., prompt variants supplying simulated internal-state signals, rephrased strangeness items, or non-LLM baselines also lacking embodiment). This interpretive step is load-bearing for the central boundary-condition argument.
Authors: We agree that the manuscript presents no ablation studies to isolate the source of the inversion. The observed pattern is consistent across five LLMs with differing architectures and the live-robot replication, which reduces the likelihood that it arises solely from a single prompt template or wording choice. Nevertheless, this does not constitute a definitive causal demonstration. In revision we will (1) temper the causal phrasing in the abstract and discussion, (2) explicitly list the absence of ablation experiments as a limitation, and (3) frame the call for supplementary modalities as motivated by the empirical failure rather than as proven causation. No new experiments will be added at this stage. revision: partial
-
Referee: [Study 2] Study 2: The live-robot replication is conducted with N=4, yet the abstract supplies no error bars, exclusion criteria, or full statistical tables for these trials. Given that the inversion pattern is asserted to persist 'across ... embodied deployment,' the small sample size and limited reporting undermine the strength of the embodied evidence relative to the larger Study 1 dataset.
Authors: We accept that the reporting for Study 2 is inadequate. The N=4 comprises four live interactions (two per participant) with no exclusions applied. In the revised manuscript we will expand the Study 2 section to include (1) error bars on all reported correlations, (2) complete statistical tables, (3) a clearer description of the procedure and participant count, and (4) explicit qualification of the replication as preliminary. The abstract will be updated to reflect these limitations while retaining the claim that the pattern was observed in embodied deployment. revision: yes
Circularity Check
No circularity: purely empirical reporting of observed correlations
full rationale
The manuscript contains no derivation chain, equations, fitted parameters, or first-principles predictions. All reported results are direct empirical computations (Pearson r, ICC) on questionnaire responses from LLMs and human ground truth. The central pattern (negative correlations on strangeness) is presented as an observed outcome, not derived from any self-referential definition or prior self-citation. The interpretive claim about missing affective states is an untested post-hoc argument in the abstract and discussion; it does not reduce any quantitative result to its own inputs by construction. No self-citation load-bearing steps, ansatzes, or renamings of known results appear in the reported analyses.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Pearson correlation and ICC are appropriate for measuring agreement between LLM and human ratings on ordinal questionnaire scales
Reference graph
Works this paper leans on
-
[1]
Measurement in- struments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of robots,
C. Bartneck, D. Kuli ´c, E. Croft, and S. Zoghbi, “Measurement in- struments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of robots,”International Journal of Social Robotics, vol. 1, no. 1, pp. 71–81, 2009
2009
-
[2]
The robotic social attributes scale (RoSAS): Development and validation,
C. M. Carpinella, A. B. Wyman, M. A. Perez, and S. J. Stroessner, “The robotic social attributes scale (RoSAS): Development and validation,” in Proc. ACM/IEEE Int. Conf. Human-Robot Interaction (HRI), pp. 254– 262, 2017
2017
-
[3]
HRI CUES dataset (anonymized)
B. Irfanet al., “HRI CUES dataset (anonymized).” Zenodo, 2024. CC- BY 4.0
2024
-
[4]
Building knowledge from interactions: An LLM-based architecture for adaptive tutoring and social reasoning,
L. Garello, G. Belgiovine, G. Russo, F. Rea, and A. Sciutti, “Building knowledge from interactions: An LLM-based architecture for adaptive tutoring and social reasoning,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2025
2025
-
[5]
Understanding Large-Language Model (LLM)-powered human-robot interaction,
C. Y . Kim, C. P. Lee, and B. Mutlu, “Understanding Large-Language Model (LLM)-powered human-robot interaction,” inProc. ACM/IEEE Int. Conf. Human-Robot Interaction (HRI), pp. 371–380, 2024
2024
-
[6]
What people share with a robot when feeling lonely and stressed and how it helps over time,
G. Laban, S. Chiang, and H. Gunes, “What people share with a robot when feeling lonely and stressed and how it helps over time,” in2025 34th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), pp. 1930–1935, IEEE, 2025
1930
-
[7]
VLM-Social-Nav: Socially aware robot navigation through scoring using vision-language models,
D. Song, J. Liang, A. Payandeh, A. H. Raj, X. Xiao, and D. Manocha, “VLM-Social-Nav: Socially aware robot navigation through scoring using vision-language models,”IEEE Robotics and Automation Letters, 2024
2024
-
[8]
Out of one, many: Using language models to simulate human samples,
L. P. Argyle, E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D. Wingate, “Out of one, many: Using language models to simulate human samples,”Political Analysis, vol. 31, no. 3, pp. 337–351, 2023
2023
-
[9]
HumanStudy-Bench: Towards AI agent design for participant simu- lation,
X. Liu, H. Shang, Z. Liu, X. Liu, Y . Xiao, Y . Tu, and H. Jin, “HumanStudy-Bench: Towards AI agent design for participant simu- lation,”arXiv preprint arXiv:2602.00685, 2026
-
[10]
SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors
T. Hu, J. Baumann, L. Lupo, D. Hovy, N. Collier, and P. R ¨ottger, “SimBench: Benchmarking the ability of large language models to simulate human behaviors,”arXiv preprint arXiv:2510.17516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Towards understanding sycophancy in language models,
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. Bowman, et al., “Towards understanding sycophancy in language models,” inPro- ceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[12]
Self-assessment tests are unreliable measures of llm personality,
A. Gupta, X. Song, and G. Anumanchipalli, “Self-assessment tests are unreliable measures of llm personality,” inProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp. 301–314, 2024
2024
-
[13]
Do LLMs have distinct and consistent personality? TRAIT: Personality testset designed for LLMs with psychometrics,
S. Lee, S. Lim, S. Han, G. Oh, H. Chae, J. Chung, M. Kim, B.-w. Kwak, et al., “Do LLMs have distinct and consistent personality? TRAIT: Personality testset designed for LLMs with psychometrics,” inProc. Conf. Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[14]
Are large language models aligned with people’s social intuitions for human- robot interactions?,
L. Wachowiak, A. Coles, O. Celiktutan, and G. Canal, “Are large language models aligned with people’s social intuitions for human- robot interactions?,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2024
2024
-
[15]
On the reliability of psychological scales on large language models,
J.-t. Huang, W. Jiao, M. H. Lam, E. J. Li, W. Wang, and M. Lyu, “On the reliability of psychological scales on large language models,” inProc. Conf. Empirical Methods in Natural Language Processing (EMNLP), pp. 6152–6173, 2024
2024
-
[16]
Large language models fail on trivial alterations to theory- of-mind tasks,
T. Ullman, “Large language models fail on trivial alterations to theory- of-mind tasks,”arXiv preprint arXiv:2302.08399, 2023
-
[17]
Social robots are like real people: First impressions, attributes, and stereotyping of social robots,
B. Reeves, J. Hancock, and X. Liu, “Social robots are like real people: First impressions, attributes, and stereotyping of social robots,” Technology, Mind, and Behavior, vol. 1, no. 1, p. 76, 2020
2020
-
[18]
The social perception of humanoid and non-humanoid robots: Effects of gendered and machinelike features,
S. J. Stroessner and J. Benitez, “The social perception of humanoid and non-humanoid robots: Effects of gendered and machinelike features,” International Journal of Social Robotics, vol. 11, no. 2, pp. 305–315, 2019
2019
-
[19]
Toward grounded commonsense reasoning,
M. Kwon, H. Hu, V . Myers, S. Karamcheti, A. Dragan, and D. Sadigh, “Toward grounded commonsense reasoning,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), pp. 5463–5470, 2024
2024
-
[20]
Chat with the environment: Interactive multimodal perception using large language models,
X. Zhao, M. Li, C. Weber, M. B. Hafez, and S. Wermter, “Chat with the environment: Interactive multimodal perception using large language models,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), pp. 3590–3596, 2023
2023
-
[21]
Between reality and delusion: Challenges of applying large language models to companion robots for open-domain dialogues with older adults,
B. Irfan, S. Kuoppam ¨aki, A. Hosseini, and G. Skantze, “Between reality and delusion: Challenges of applying large language models to companion robots for open-domain dialogues with older adults,” Autonomous Robots, vol. 49, no. 1, p. 9, 2025
2025
-
[22]
Infusing Theory of Mind into Socially Intelligent LLM Agents
E. Hwanget al., “Infusing theory of mind into socially intelligent LLM agents,”arXiv preprint arXiv:2509.22887, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
SOTOPIA: Interactive evaluation for social intelligence in language agents,
X. Zhou, H. Zhu, L. Mathur, R. Zhang, H. Yu, Z. Qi, L.-P. Morency, Y . Bisk, D. Fried, G. Neubig,et al., “SOTOPIA: Interactive evaluation for social intelligence in language agents,” inProc. Int. Conf. Learning Representations (ICLR), 2024
2024
-
[24]
Personallm: Investigating the ability of large language models to ex- press personality traits,
H. Jiang, X. Zhang, X. Cao, C. Breazeal, D. Roy, and J. Kabbara, “Personallm: Investigating the ability of large language models to ex- press personality traits,” inFindings of the association for computational linguistics: NAACL 2024, pp. 3605–3627, 2024
2024
-
[25]
Y . Zhuet al., “Can LLM “self-report”? exploring the validity of LLM-based self-rating in conversational agents,”arXiv preprint arXiv:2412.00207, 2024
-
[26]
Human-robot interaction conversational user enjoyment scale (HRI CUES),
B. Irfan, J. Miniota, S. Thunberg, E. Lagerstedt, S. Kuoppam ¨aki, G. Skantze, and A. Pereira, “Human-robot interaction conversational user enjoyment scale (HRI CUES),”IEEE Transactions on Affective Computing, 2025
2025
-
[27]
Reporting guidelines for large language models in human–robot interaction,
C. Matuszek, T. Williams, N. DePalma, R. Mead, R. Wen, E. Schneiders, C. Kennington, and A. Bezabih, “Reporting guidelines for large language models in human–robot interaction,”J. Hum.-Robot Interact., vol. 15, Jan. 2026
2026
-
[28]
Scientists rise up against statistical significance,
V . Amrhein, S. Greenland, and B. McShane, “Scientists rise up against statistical significance,”Nature, vol. 567, no. 7748, pp. 305–307, 2019
2019
-
[29]
10 years of human-NAO interaction research: A scoping review,
A. Amirova, N. Rakhymbayeva, E. Yadollahi, A. Sandygulova, and W. Johal, “10 years of human-NAO interaction research: A scoping review,”Frontiers in Robotics and AI, vol. 8, p. 744526, 2021
2021
-
[30]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inProceedings of the 40th International Conference on Machine Learning (ICML), pp. 28492–28518, 2023
2023
-
[31]
Academically intelligent LLMs are not necessarily socially intelligent,
R. Xuet al., “Academically intelligent LLMs are not necessarily socially intelligent,”arXiv preprint arXiv:2403.06591, 2024
-
[32]
Affective state estimation for human-robot interaction,
D. Kuli ´c and E. A. Croft, “Affective state estimation for human-robot interaction,”IEEE Transactions on Robotics, vol. 23, no. 5, pp. 991– 1000, 2007
2007
-
[33]
Addressing data scarcity in multimodal user state recognition by combining semi-supervised and supervised learning,
H. V oß, H. Wersing, and S. Kopp, “Addressing data scarcity in multimodal user state recognition by combining semi-supervised and supervised learning,” inCompanion Publication of the Int. Conf. on Multimodal Interaction (ICMI), 2021
2021
-
[34]
V ADER: A parsimonious rule-based model for sentiment analysis of social media text,
C. Hutto and E. Gilbert, “V ADER: A parsimonious rule-based model for sentiment analysis of social media text,” inProceedings of the International AAAI Conference on Web and Social Media, vol. 8, pp. 216–225, 2014
2014
-
[35]
Regulating modal- ity utilization within multimodal fusion networks,
S. Singh, E. Saber, P. P. Markopoulos, and J. Heard, “Regulating modal- ity utilization within multimodal fusion networks,”Sensors, vol. 24, no. 18, p. 6054, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.