Flatness Preserves Instruction Following in Vision-Language-Action Models
Pith reviewed 2026-06-26 08:04 UTC · model grok-4.3
The pith
Sharpness-aware minimization during VLA finetuning improves instruction following by over 60% on the same data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
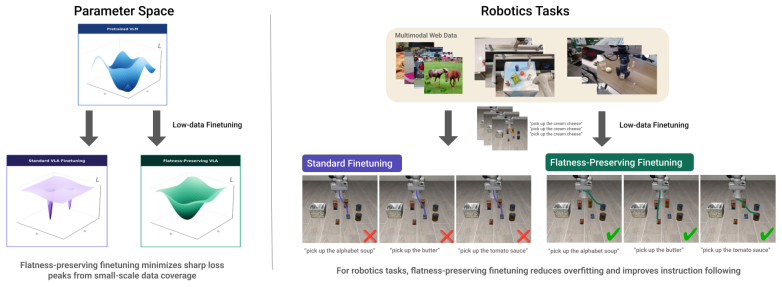
The authors claim that instruction blindness arises from high-curvature minima induced by standard gradient descent on sparse robot data, and that flatness-preserving optimization via sharpness-aware minimization during finetuning on the exact same data restores robust instruction following, yielding over 60% improvement without additional resources.
What carries the argument
sharpness-aware minimization applied during VLA finetuning, which perturbs parameters to locate flatter regions of the loss landscape and thereby maintains language grounding.
If this is right
- The identical limited robot data produces policies that respect language instructions rather than visual shortcuts.
- Gains appear consistently across multiple simulation environments and real-world robot tasks.
- The flatness method combines with existing guidance techniques for additive benefits.
- Selective application of sharpness during training allows quantification of its contribution to language preservation.
Where Pith is reading between the lines
- The same optimization change might reduce shortcut learning when finetuning other multimodal models on scarce downstream data.
- Measuring loss curvature before and after finetuning could become a practical check for whether language grounding survived the update.
- If flat regions better retain pretrained features, applying the method earlier in pretraining stages could be tested as a preventive step.
Load-bearing premise
That instruction blindness is caused specifically by sharp minima from standard optimization on sparse data rather than by data quality, model capacity, or other factors.
What would settle it
Running the same finetuning experiments and finding that sharpness-aware minimization produces no gain in instruction following, or that models with measurably flatter minima still ignore language instructions at the same rate.
Figures

read the original abstract
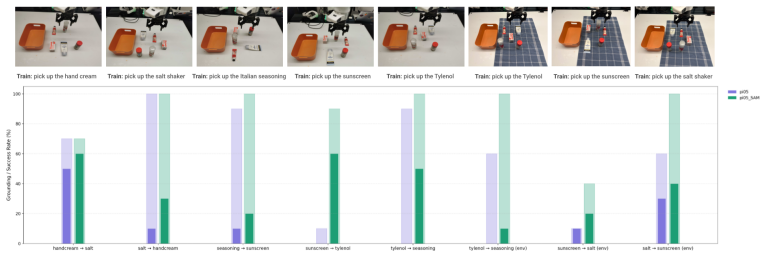
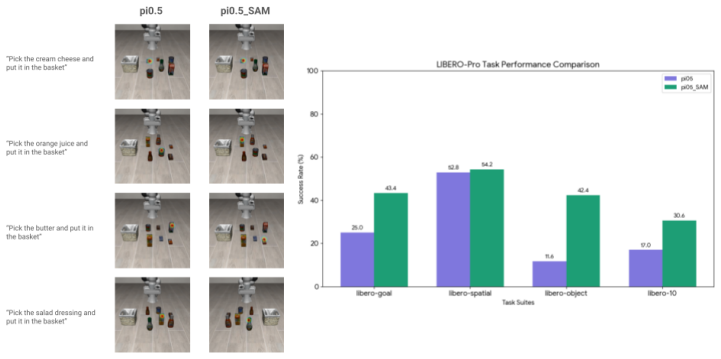
Vision-language-action (VLA) models have the potential for open-world generalization by leveraging pretrained vision-language representations, yet downstream finetuning on limited robot data often degrades these representations, leading to brittle policies that ignore language instructions in favor of visual shortcuts, a failure mode we term instruction blindness. We hypothesize that standard finetuning with limited data applies gradients to a sparse set of points, which manifests as a sharp loss landscape with high-curvature minima. We propose to address this directly through flatness-preserving optimization while finetuning on the exact same data, where learning a flatter landscape results in a model more robust to perturbations in the weight space. Specifically, we demonstrate that simply applying sharpness-aware minimization during VLA finetuning significantly improves instruction following by over 60% across multiple simulation and real-world benchmarks without additional data, architectural modification, or retraining. We further analyze the effect of selective sharpness, quantify its effects, and show that our approach is complementary to existing guidance techniques. Project page can be found at https://haochenz11.github.io/papers/flatness-vla/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that finetuning vision-language-action (VLA) models on limited robot data produces sharp, high-curvature minima that cause 'instruction blindness' (ignoring language in favor of visual shortcuts); it proposes that applying sharpness-aware minimization (SAM) during the same finetuning finds flatter minima that preserve language grounding, yielding >60% gains in instruction following on simulation and real-world benchmarks without extra data, architecture changes, or retraining. It further analyzes selective sharpness and complementarity with guidance methods.
Significance. If the reported gains are robust and the flatness mechanism is substantiated, the result would offer a lightweight, optimizer-only intervention that improves VLA robustness on sparse data, with potential impact on reliable language-conditioned robot policies.
major comments (2)
- [Abstract / analysis of selective sharpness] Abstract and analysis sections: the central mechanistic claim—that SAM improves performance specifically by producing flatter minima that preserve instruction following—is not supported by any reported curvature measurements (Hessian trace, maximum eigenvalue, or SAM-style sharpness) on the final standard-gradient vs. SAM checkpoints. Without these, the observed accuracy gains could stem from SAM's two-step dynamics, implicit regularization, or other optimizer effects rather than flatness.
- [Experimental evaluation] Experimental sections: the abstract states a >60% improvement 'across multiple simulation and real-world benchmarks' but supplies no details on baselines, number of runs, statistical tests, ablation controls (e.g., other regularizers), or exact task definitions, preventing verification that the data support the stated claim.
minor comments (1)
- [Abstract] The term 'selective sharpness' is introduced in the abstract but its precise definition and quantification method are not stated in the provided summary, which could be clarified for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract / analysis of selective sharpness] Abstract and analysis sections: the central mechanistic claim—that SAM improves performance specifically by producing flatter minima that preserve instruction following—is not supported by any reported curvature measurements (Hessian trace, maximum eigenvalue, or SAM-style sharpness) on the final standard-gradient vs. SAM checkpoints. Without these, the observed accuracy gains could stem from SAM's two-step dynamics, implicit regularization, or other optimizer effects rather than flatness.
Authors: We agree that direct curvature measurements would provide stronger substantiation for the flatness mechanism. The manuscript currently supports the claim via performance improvements and the established properties of SAM, but does not report Hessian trace, maximum eigenvalue, or equivalent sharpness metrics on the final checkpoints. In the revision we will add these measurements comparing standard-gradient and SAM checkpoints to directly test the flatness hypothesis. revision: yes
-
Referee: Experimental sections: the abstract states a >60% improvement 'across multiple simulation and real-world benchmarks' but supplies no details on baselines, number of runs, statistical tests, ablation controls (e.g., other regularizers), or exact task definitions, preventing verification that the data support the stated claim.
Authors: The experimental section reports comparisons against standard finetuning on defined simulation (LIBERO, MetaWorld) and real-world tasks, includes selective-sharpness ablations, and states the >60% aggregate gain. To improve verifiability we will expand the text with explicit reporting of random seeds, statistical tests, and additional ablation controls against other regularizers. revision: yes
Circularity Check
No significant circularity; empirical claim with independent validation
full rationale
The paper advances a hypothesis that standard finetuning produces sharp minima leading to instruction blindness, then reports an empirical result from applying SAM during finetuning on the same data, with >60% gains on benchmarks. No derivation chain, fitted parameter renamed as prediction, or self-citation load-bearing step is present in the provided text. The central claim rests on direct experimental comparison rather than any reduction to inputs by construction or imported uniqueness. This is the normal case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flatter minima in the loss landscape improve robustness to perturbations and preserve pretrained capabilities during fine-tuning.
Reference graph
Works this paper leans on
-
[1]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
- [2]
-
[3]
J. Zhang, X. Chen, Q. Wang, M. Li, Y . Guo, Y . Hu, J. Zhang, S. Bai, J. Lin, and J. Chen. Vlm4vla: Revisiting vision-language-models in vision-language-action models.arXiv preprint arXiv:2601.03309, 2026
Pith/arXiv arXiv 2026
- [4]
-
[5]
J. Guo, Z. Wu, C. Tu, Y . Ma, X. Kong, Z. Liu, J. Ji, S. Zhang, Y . Chen, K. Chen, et al. On robustness of vision-language-action model against multi-modal perturbations.arXiv preprint arXiv:2510.00037, 2025
arXiv 2025
-
[6]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[7]
G. Wang, C. Zhang, Q. Liu, J. Zhang, J. Cai, J. Liu, and X. Liu. Libero-x: Robustness litmus for vision-language-action models.arXiv preprint arXiv:2602.06556, 2026
arXiv 2026
-
[8]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: To- wards robust and fair evaluation of vision-language-action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[9]
Y . Fang, Y . Feng, D. Jing, J. Liu, Y . Yang, Z. Wei, D. Szafir, and M. Ding. When vision overrides language: Evaluating and mitigating counterfactual failures in vlas.arXiv preprint arXiv:2602.17659, 2026
arXiv 2026
-
[10]
K. Xu, Z. Zhu, A. Chen, S. Zhao, Q. Huang, Y . Yang, H. Lu, R. Xiong, M. Tomizuka, and Y . Wang. Seeing to act, prompting to specify: A bayesian factorization of vision language action policy.arXiv preprint arXiv:2512.11218, 2025
arXiv 2025
-
[11]
S. Huang, J. Shao, K. Wang, Q. Chen, J. Sun, Y . Guo, M. Schwager, and J. Bohg. Breaking lock-in: Preserving steerability under low-data vla post-training.arXiv preprint arXiv:2604.23121, 2026
Pith/arXiv arXiv 2026
-
[12]
Z. Zhan, Y . Chen, J. Zhou, Q. Lv, H. Liu, K. Wang, L. Lin, and G. Wang. Stable language guidance for vision-language-action models.arXiv preprint arXiv:2601.04052, 2026
Pith/arXiv arXiv 2026
-
[13]
S. Lian, B. Yu, X. Lin, L. T. Yang, Z. Shen, C. Wu, Y . Miao, C. Huang, and K. Chen. Bayesian- vla: Bayesian decomposition of vision language action models via latent action queries.arXiv preprint arXiv:2601.15197, 2026. 9
Pith/arXiv arXiv 2026
-
[14]
S. Yang, H. Li, B. Wang, Y . Chen, Y . Tian, T. Wang, H. Wang, F. Zhao, Y . Liao, and J. Pang. Instructvla: Vision-language-action instruction tuning from understanding to manipulation. arXiv preprint arXiv:2507.17520, 2025
arXiv 2025
-
[15]
A. J. Hancock, X. Wu, L. Zha, O. Russakovsky, and A. Majumdar. Actions as language: Fine-tuning vlms into vlas without catastrophic forgetting.arXiv preprint arXiv:2509.22195, 2025
arXiv 2025
- [16]
-
[17]
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for effi- ciently improving generalization.arXiv preprint arXiv:2010.01412, 2020
Pith/arXiv arXiv 2010
-
[18]
J. Kwon, J. Kim, H. Park, and I. K. Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. InInternational conference on machine learning, pages 5905–5914. PMLR, 2021
2021
-
[19]
T. Sherborne, N. Saphra, P. Dasigi, and H. Peng. Tram: Bridging trust regions and sharpness aware minimization.arXiv preprint arXiv:2310.03646, 2023
arXiv 2023
-
[20]
Y . Liu, S. Mai, X. Chen, C.-J. Hsieh, and Y . You. Towards efficient and scalable sharpness- aware minimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12360–12370, 2022
2022
-
[21]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[22]
Driess, J
D. Driess, J. Springenberg, B. Ichter, L. Yu, A. Li-Bell, K. Pertsch, A. Ren, H. Walke, Q. Vuong, L. X. Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.Advances in Neural Information Processing Systems, 38:102867– 102888, 2026
2026
- [23]
-
[24]
C. Glossop, W. Chen, A. Bhorkar, D. Shah, and S. Levine. Cast: Counterfactual labels improve instruction following in vision-language-action models.arXiv preprint arXiv:2508.13446, 2025
Pith/arXiv arXiv 2025
- [25]
-
[26]
Hochreiter and J
S. Hochreiter and J. Schmidhuber. Flat minima.Neural computation, 9(1):1–42, 1997
1997
-
[27]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch train- ing for deep learning: Generalization gap and sharp minima.arXiv preprint arXiv:1609.04836, 2016
Pith/arXiv arXiv 2016
-
[28]
L. Dinh, R. Pascanu, S. Bengio, and Y . Bengio. Sharp minima can generalize for deep nets. In International Conference on Machine Learning, pages 1019–1028. PMLR, 2017
2017
- [29]
-
[30]
Bahri, H
D. Bahri, H. Mobahi, and Y . Tay. Sharpness-aware minimization improves language model generalization. 2022
2022
-
[31]
Y . Yang, Z. Zhang, R. V . Swaminathan, J. Liu, N. Susanj, and Z. Zhang. SharpZO: Hybrid sharpness-aware vision language model prompt tuning via forward-only passes. Oct. 2025. 10
2025
-
[32]
T. Li, P. Zhou, Z. He, X. Cheng, and X. Huang. Friendly sharpness-aware minimization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5631–5640, 2024
2024
-
[33]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[34]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. In9th Annual Conference on Robot Learning, 2025
2025
-
[35]
Karamcheti, S
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first Interna- tional Conference on Machine Learning, 2024
2024
-
[36]
A. Steiner, A. S. Pinto, M. Tschannen, D. Keysers, X. Wang, Y . Bitton, A. Gritsenko, M. Min- derer, A. Sherbondy, S. Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555, 2024
Pith/arXiv arXiv 2024
-
[37]
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[38]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[39]
N. Kachaev, M. Kolosov, D. Zelezetsky, A. K. Kovalev, and A. I. Panov. Don’t blind your vla: Aligning visual representations for ood generalization.arXiv preprint arXiv:2510.25616, 2025
arXiv 2025
-
[40]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[41]
P. Izmailov, D. Podoprikhin, T. Garipov, D. Vetrov, and A. G. Wilson. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407, 2018
Pith/arXiv arXiv 2018
-
[42]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 11 A Benchmark Details We utilize three counterfactual benchmarks to evaluate instruction following, all based on the LIBE...
Pith/arXiv arXiv 2024
-
[43]
pick up the and put it in the basket
The model was finetuned on 4 x NVIDIA A100 Tensor Core GPUs with 80GB memory. Table 4: Hyperparameters for finetuningπ 0.5 with SAM Hyperparameter Value Learning Rate5×10 −5 Batch Size 16 ρ(Neighborhood Size) 0.075 Weight Decay 0.1 Base Optimizer AdamW Action Horizon 10 EMA Decay 0.999 Train Steps 30,000 13 π0.5 SAM+CFG.To test the combination of using an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.