Supervise What Survives: Geometry-Guided VLA Adaptation from Synthetic Robot Videos
Pith reviewed 2026-06-25 23:55 UTC · model grok-4.3
The pith
Synthetic robot videos can improve real-robot VLA policies by supervising only the vision backbone with extracted 2D geometry while training actions exclusively on real demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
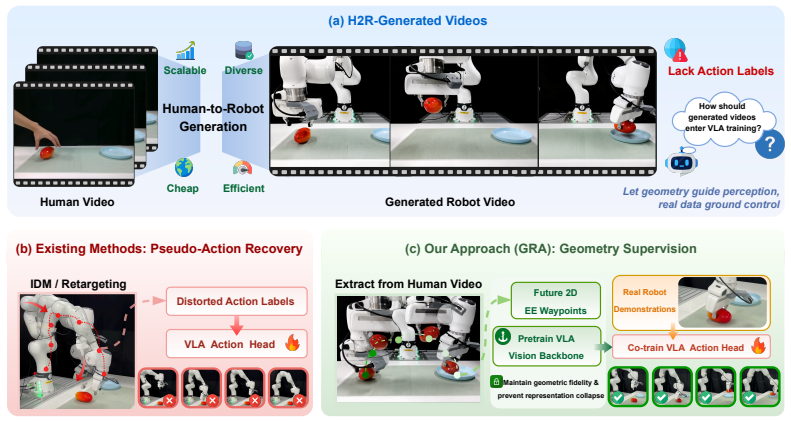
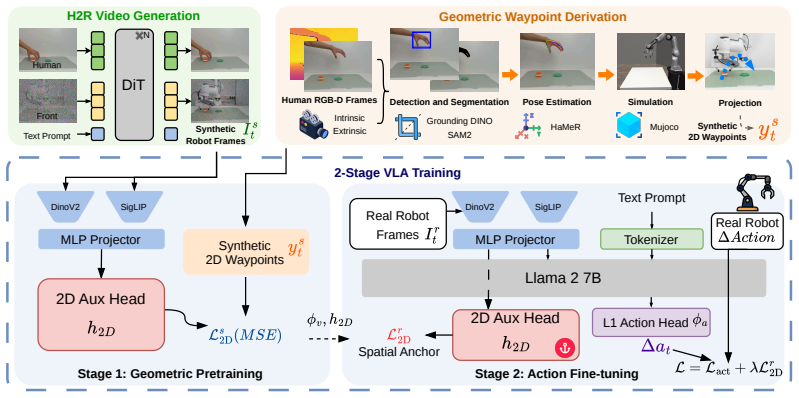
Following the Asymmetric Preservation Principle, GRA extracts future 2D end-effector waypoints from synthetic videos through pose estimation, retargeting, simulation, and calibrated projection, then routes them to the VLA vision backbone via an auxiliary 2D head; the action head is trained on real demonstrations only, and the waypoint loss persists during fine-tuning as a spatial representation anchor.
What carries the argument
The Asymmetric Preservation Principle, which states that generated videos retain geometric trajectories (the where) while losing control signals (the how), allowing geometry to supervise perception separately from action learning.
If this is right
- GRA outperforms pseudo-action baselines under matched data budgets on real-robot tasks.
- The method narrows the gap between policies trained with limited real demonstrations and those trained with substantially more real data.
- The persisting waypoint loss prevents the vision backbone from losing geometric grounding during fine-tuning.
- Geometry supervision is applied only to perception; control learning remains isolated to real demonstrations.
Where Pith is reading between the lines
- The same separation of geometry and control signals could be tested on other VLA architectures or with different video-generation pipelines to check whether the benefit generalizes.
- If the waypoint extraction pipeline introduces systematic bias in certain environments, the auxiliary head might need an uncertainty-weighted loss to avoid harming the backbone.
- Extending the anchor to 3D keypoints or scene affordances might further stabilize representation learning when 2D projections become ambiguous.
Load-bearing premise
The 2D waypoints recovered from synthetic videos supply a clean, domain-consistent supervision signal for the vision backbone that does not require the action head to reconcile conflicting information.
What would settle it
If, on the same real-robot tasks and data budgets, a policy trained with GRA waypoint supervision achieves success rates no higher than or lower than a pseudo-action baseline trained on the identical synthetic videos, the central claim would be falsified.
Figures


read the original abstract
Vision-Language-Action (VLA) models require large-scale video-action pairs, yet real teleoperation remains scarce. While generated robot videos offer a scalable alternative, existing methods treat them as real robot data by recovering pseudo-actions from synthesized pixels. We argue that deriving low-level control from generated visuals is a mismatched abstraction. A video captures only \emph{geometry}: the spatial trajectory representing the \emph{where} of a task. A real demonstration captures \emph{control}: the exact motor commands representing the \emph{how}. Human-to-robot video generation preserves these unequally: the visible geometry survives the generation process, while the underlying control signals are lost. This \textbf{Asymmetric Preservation Principle} dictates a clean rule: this surviving geometry should solely supervise visual perception, leaving control to real demonstrations. Following this principle, we propose \textbf{GRA} (\textbf{G}eometry-guided \textbf{R}epresentation \textbf{A}lignment), which extracts the geometric content as future 2D end-effector waypoints, computed from the source human video through pose estimation, retargeting, simulation, and calibrated projection, and routes them to the VLA vision backbone via an auxiliary 2D head. The action head is trained on real demonstrations only. During fine-tuning, the waypoint loss persists as a \textbf{spatial representation anchor} that prevents the backbone from losing its geometric grounding. On real-robot tasks, GRA outperforms pseudo-action baselines under matched data budgets and narrows the gap to policies trained with substantially more real demonstrations, suggesting that correctly routed geometry bridges generated videos to robot policies more reliably than recovered actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that synthetic robot videos preserve geometry (spatial trajectories) but lose control signals, per the Asymmetric Preservation Principle. It proposes GRA, which extracts 2D end-effector waypoints from source human videos (via pose estimation, retargeting, simulation, and calibrated projection) to supervise only the VLA vision backbone via an auxiliary head, while the action head trains exclusively on real demonstrations. The waypoint loss acts as a spatial anchor during fine-tuning. Experiments reportedly show GRA outperforming pseudo-action baselines on real-robot tasks under matched data budgets and narrowing the gap to policies with more real data.
Significance. If the central results hold, the work provides a clean separation of supervision signals that could improve data efficiency for VLA adaptation from scalable synthetic videos. The explicit routing of geometry to the vision backbone and control to real actions is a principled contribution; the auxiliary 2D head as a persistent anchor is a concrete mechanism worth testing in other settings.
major comments (2)
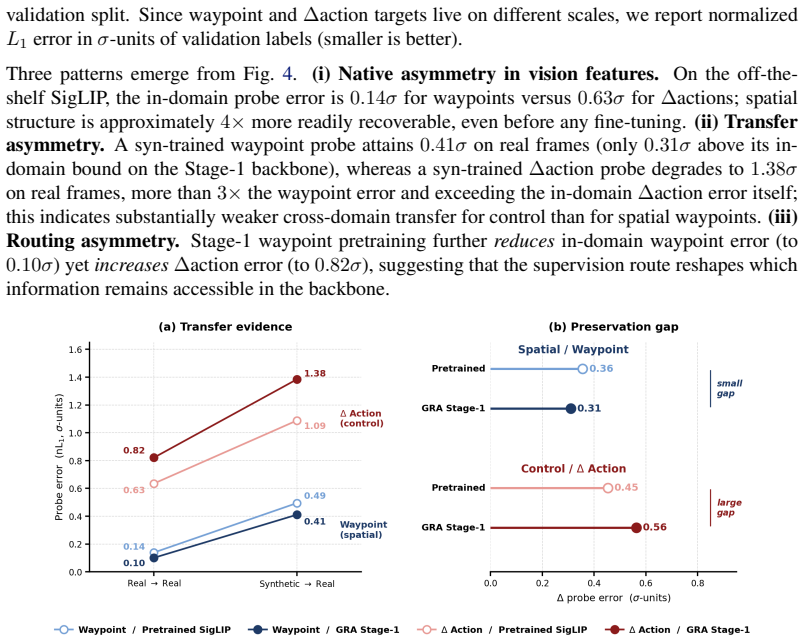
- [GRA method description (waypoint computation paragraph)] The waypoint extraction pipeline (pose estimation → retargeting → simulation → calibrated projection) is described only from the human-video source; no section verifies that the resulting 2D waypoints align with visible end-effector locations in the actual synthetic robot video frames fed to the vision backbone. This alignment is load-bearing for the claim that geometry supervision is beneficial rather than a source of domain-shift noise.
- [Experiments and ablations] The experimental claims rest on the auxiliary 2D head delivering reliable spatial grounding without requiring the action head to reconcile mismatched signals. No ablation or analysis is referenced that isolates whether observed gains survive when waypoint accuracy is deliberately degraded or when retargeting errors are measured.
minor comments (2)
- [Method] Notation for the auxiliary loss (waypoint loss) and its weighting relative to the main action loss should be made explicit with an equation.
- [Introduction] The abstract states that generated videos 'preserve geometry but lose control'; a short related-work paragraph situating this against prior video-to-action or geometry-from-video papers would help readers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation of major revision. The two major comments identify areas where additional verification and analysis would strengthen the presentation of GRA. We address each point below and commit to incorporating the requested elements in the revised manuscript.
read point-by-point responses
-
Referee: [GRA method description (waypoint computation paragraph)] The waypoint extraction pipeline (pose estimation → retargeting → simulation → calibrated projection) is described only from the human-video source; no section verifies that the resulting 2D waypoints align with visible end-effector locations in the actual synthetic robot video frames fed to the vision backbone. This alignment is load-bearing for the claim that geometry supervision is beneficial rather than a source of domain-shift noise.
Authors: We agree that explicit verification of alignment between the extracted 2D waypoints and the visible end-effector locations in the synthetic robot video frames is necessary to support the claim. The current manuscript describes the pipeline but does not include a dedicated verification step or quantitative comparison on the synthetic frames themselves. In the revision we will add a new subsection (and figure) that reports both qualitative overlays of projected waypoints on sample synthetic frames and quantitative alignment metrics (mean pixel error and percentage of waypoints within a 10-pixel threshold) computed on held-out synthetic robot videos. This addition will directly confirm that the geometry signal remains consistent rather than introducing domain-shift noise. revision: yes
-
Referee: [Experiments and ablations] The experimental claims rest on the auxiliary 2D head delivering reliable spatial grounding without requiring the action head to reconcile mismatched signals. No ablation or analysis is referenced that isolates whether observed gains survive when waypoint accuracy is deliberately degraded or when retargeting errors are measured.
Authors: We concur that an ablation isolating the contribution of waypoint accuracy would provide stronger evidence that the observed gains derive from reliable spatial grounding. The present experiments do not contain such a controlled degradation study or explicit reporting of retargeting error statistics. In the revised manuscript we will add an ablation that perturbs the waypoint targets with increasing levels of Gaussian noise (simulating retargeting inaccuracies) and reports the resulting policy success rates. We will also include measured retargeting error statistics from the pipeline and discuss their relationship to task performance, thereby addressing the concern about mismatched signals. revision: yes
Circularity Check
No circularity; principle is conceptual argument, method applies it without self-referential reduction
full rationale
The paper posits the Asymmetric Preservation Principle as a conceptual distinction between preserved geometry and lost control signals in generated videos, then defines GRA as extracting 2D waypoints from source human videos (via pose/retargeting/simulation/projection) to supervise only the vision backbone while training the action head on real demonstrations. No equations, fitted parameters renamed as predictions, or self-citations are present in the provided text that would make the claimed outperformance reduce to a definition or input by construction. The derivation chain consists of the posited principle plus empirical comparison to pseudo-action baselines, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Generated videos preserve geometry (spatial trajectories) but lose control signals (motor commands).
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[2]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[3]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[4]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[5]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[6]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–
-
[7]
Y . Song, C. Liu, W. Mao, and M. Z. Shou. Mitty: Diffusion-based human-to-robot video generation.arXiv preprint arXiv:2512.17253, 2025
arXiv 2025
-
[8]
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025
Pith/arXiv arXiv 2025
-
[9]
H. Li, I. Zhang, R. Ouyang, X. Wang, Z. Zhu, Z. Yang, Z. Zhang, B. Wang, C. Ni, W. Qin, et al. Mimicdreamer: Aligning human and robot demonstrations for scalable vla training. arXiv preprint arXiv:2509.22199, 2025
arXiv 2025
-
[10]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[11]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[12]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Pith/arXiv arXiv 2025
-
[13]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[14]
Z. Bai, C. Gao, and M. Z. Shou. Evolve-vla: Test-time training from environment feedback for vision-language-action models.arXiv preprint arXiv:2512.14666, 2025
arXiv 2025
-
[15]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge. Advances in Neural Information Processing Systems, 38:24195–24228, 2026. 9
2026
-
[16]
H. Yuan, Z. Liang, A. Chen, Y . Wang, H. Li, P. Lin, Y . Huang, Z. Lei, T. Zhang, J. Zhang, et al. Qwen-robotmanip technical report: Alignment unlocks scale for robotic manipulation foundation models.arXiv preprint arXiv:2606.17846, 2026
Pith/arXiv arXiv 2026
-
[17]
P. Yang, H. Ci, Y . Chen, Q. Lv, H. Cai, and M. Z. Shou. Actionmap: Robot policy learning via voxel action heatmap.arXiv preprint arXiv:2606.06904, 2026
Pith/arXiv arXiv 2026
-
[18]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[19]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[20]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[21]
Y . Chen, K. Y . Ma, Q. Lv, Y . Lin, Z. Bai, C. Gao, and M. Z. Shou. Escaping the diversity trap in robotic manipulation via anchor-centric adaptation.arXiv preprint arXiv:2605.07381, 2026
Pith/arXiv arXiv 2026
-
[22]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[23]
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023
Pith/arXiv arXiv 2023
-
[24]
A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 3(4):6, 2025
Pith/arXiv arXiv 2025
-
[25]
H. Ci, X. Liu, P. Yang, Y . Song, and M. Z. Shou. H2r-grounder: A paired-data-free paradigm for translating human interaction videos into physically grounded robot videos.arXiv preprint arXiv:2512.09406, 2025
arXiv 2025
-
[26]
Z. Chen, Y . Li, Z. Liang, X. Chen, et al. Moto: Latent motion token as the bridging language for robot manipulation.arXiv preprint arXiv:2412.04445, 2024
arXiv 2024
-
[27]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, L. Liden, K. Lee, J. Gao, L. Zettlemoyer, D. Fox, and M. Seo. Latent action pretraining from videos. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 28213–28239, 2025
2025
-
[28]
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Pith/arXiv arXiv 2025
-
[29]
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control.arXiv preprint arXiv:2505.03729, 2025
arXiv 2025
-
[30]
M. Lepert, J. Fang, and J. Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025
Pith/arXiv arXiv 2025
-
[31]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, C. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, et al. Hamster: Hierarchical action models for open-world robot manipulation. InInternational Conference on Learning Representations, volume 2025, pages 24040–24068, 2025. 10
2025
-
[32]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
Pith/arXiv arXiv 2024
-
[33]
H. Luo, Y . Feng, W. Zhang, S. Zheng, Y . Wang, H. Yuan, J. Liu, C. Xu, Q. Jin, and Z. Lu. Being-h0: vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
arXiv 2025
-
[34]
X. Qiu, Y . Wang, J. Cai, Z. Chen, C. Lin, T.-H. Wang, and C. Gan. Lucibot: Automated robot policy learning from generated videos.arXiv preprint arXiv:2503.09871, 2025
arXiv 2025
-
[35]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[36]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[37]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
Pith/arXiv arXiv 2022
-
[38]
S. Karamcheti, S. Nair, A. S. Chen, T. Kollar, C. Finn, D. Sadigh, and P. Liang. Language- driven representation learning for robotics.arXiv preprint arXiv:2302.12766, 2023
arXiv 2023
-
[39]
Radosavovic, T
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learning with masked visual pre-training. InConference on Robot Learning, pages 416–426. PMLR, 2023
2023
-
[40]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, et al. Internvla- m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
Pith/arXiv arXiv 2025
-
[41]
Y . Chen, K. Q. Lin, and M. Z. Shou. Code2video: A code-centric paradigm for educational video generation.arXiv preprint arXiv:2510.01174, 2025
arXiv 2025
-
[42]
N. Kachaev, M. Kolosov, D. Zelezetsky, A. K. Kovalev, and A. I. Panov. Don’t blind your vla: Aligning visual representations for ood generalization.arXiv preprint arXiv:2510.25616, 2025
arXiv 2025
-
[43]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision, pages 38–55. Springer, 2024
2024
-
[44]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Confer- ence on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[45]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3d with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
2024
-
[46]
pick up X and place on Y
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012. 11 A Implementation Details Table 4 consolidates the settings for the two stages ofGRAand the three baselines (Real-only, DreamGen-style, MimicDreamer-style). All five runs use the same ...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.