GBC: Gradient-Based Connections for Optimizing Multi-Agent Systems
Pith reviewed 2026-06-29 01:36 UTC · model grok-4.3
The pith
Token-level gradients from task loss quantify each agent's influence in multi-agent LLM systems and guide targeted prompt fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
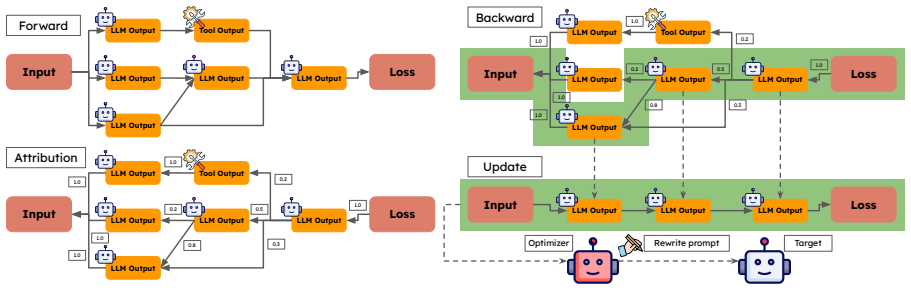
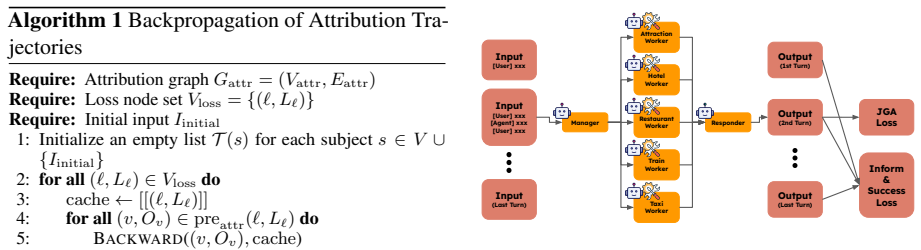
The paper claims that modeling a multi-agent LLM system as a computational graph and computing gradient-based connection weights at the token level allows precise attribution of task loss to individual agent outputs, which in turn supports targeted prompt optimization that improves overall performance.
What carries the argument
Gradient-Based Connections: token-level gradient weights that quantify the influence of each agent's output on downstream agents inside an attribution graph.
If this is right
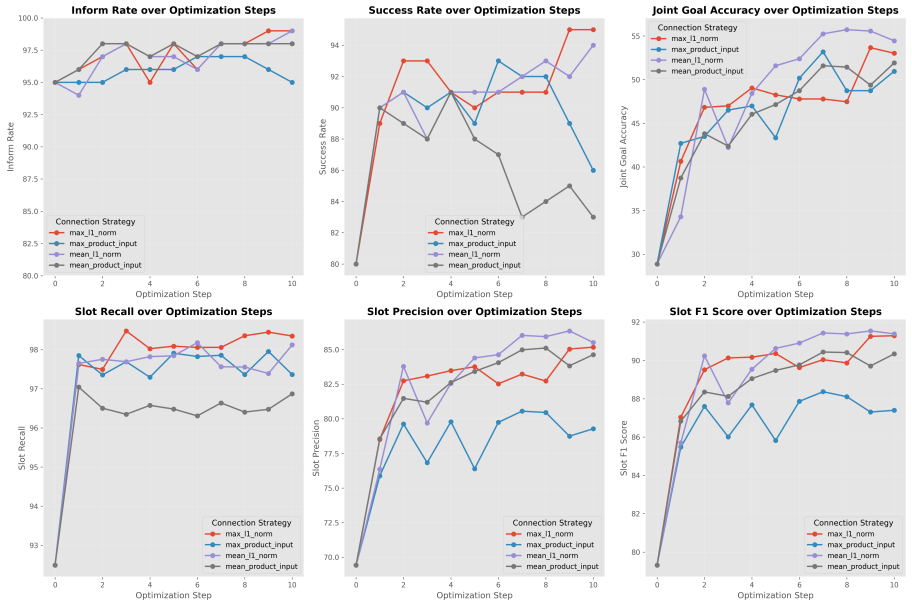
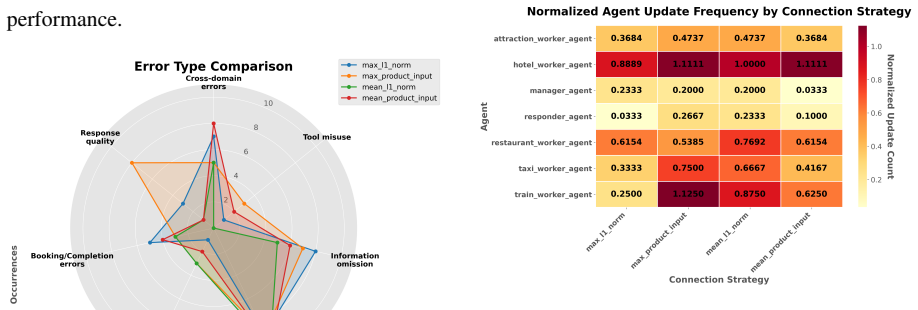
- GBC improves multi-agent performance over strong single-agent and multi-agent baselines on MultiWOZ and τ-bench.
- Higher attribution quality is associated with greater optimization effectiveness.
- Fine-grained, token-level credit assignment replaces coarse feedback for identifying error sources.
- Prefix-based gradient computation yields an efficient implementation called AgentChord.
Where Pith is reading between the lines
- The same gradient-graph construction could be applied to other chained LLM workflows that are not explicitly multi-agent.
- If the attribution scores prove stable across different loss functions, the method might serve as a general debugging layer for any modular LLM pipeline.
- A direct test would compare GBC-selected edits against edits chosen by human experts on the same error traces.
Load-bearing premise
A multi-agent LLM system can be faithfully modeled as a computational graph in which token-level gradients from a downstream task loss meaningfully quantify the influence of each upstream agent's output on later agents.
What would settle it
If prompt changes selected by the highest GBC attribution scores produce no larger performance lift than changes selected by random or uniform attribution on the same tasks, the central claim is false.
Figures

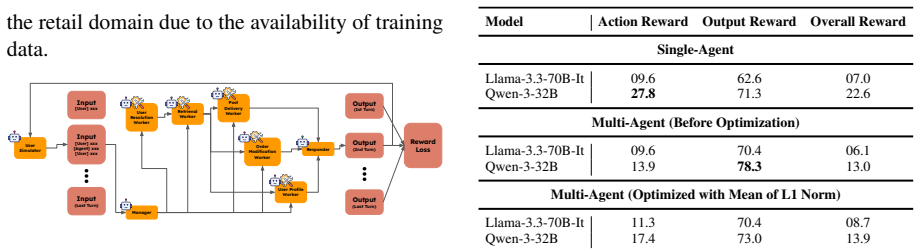

read the original abstract
Multi-agent systems (MAS) built on large language models (LLMs) provide a promising framework for solving complex tasks through role specialization and structured interaction. However, their performance is often limited by miscoordination and, more fundamentally, the lack of fine-grained credit assignment across agents. Existing approaches typically rely on coarse-grained feedback, making it difficult to identify which agents or interaction steps are responsible for errors. We propose Gradient-Based Connections (GBC), an approach for fine-grained attribution and optimization of multi-agent systems. GBC models a MAS as a computational graph and introduces gradient-based connection weights to quantify the influence of each agent's output on downstream agents at the token level. By constructing an attribution graph and propagating task-specific loss signals backward, our method enables precise identification of error sources and targeted prompt optimization. We further develop AgentChord, an efficient implementation that leverages prefix-based gradient computation. Experiments on MultiWOZ and {\tau}-bench show that GBC improves multi-agent performance and outperforms strong single-agent and multi-agent baselines, and higher attribution quality is associated with greater optimization effectiveness. Code is available at: https://github.com/yxc-cyber/AgentChord.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gradient-Based Connections (GBC) for multi-agent LLM systems. It models a MAS as a computational graph, introduces token-level gradient-based connection weights to attribute influence from each agent's output to downstream agents, constructs an attribution graph, and propagates task loss backward for error identification and targeted prompt optimization. An efficient implementation called AgentChord is presented that uses prefix-based gradient computation. Experiments on MultiWOZ and τ-bench are claimed to show performance gains over strong single-agent and multi-agent baselines, with higher attribution quality correlated to greater optimization effectiveness. Code is released.
Significance. If the gradient attribution construction is shown to be causally valid, the approach could supply a more principled alternative to coarse feedback in MAS optimization. The code release is a positive for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim of performance gains and a correlation between attribution quality and optimization success is stated without any numbers, baselines, statistical tests, or description of how gradients are obtained from LLMs, so the claim cannot be evaluated.
- [Method] Method description (throughout): no equations or derivation are supplied for the gradient-based connection weights, the attribution graph construction, or the backward propagation of task loss, which are load-bearing for the fine-grained attribution claim.
- [Method] Method: the assumption that token-level gradients from a downstream task loss meaningfully quantify causal influence across discrete LLM agent steps (via non-differentiable string concatenation and black-box forward passes) is not justified or validated; any auxiliary construction (e.g., prefix caching) must be shown to preserve actual causal effects, otherwise the attribution graph is spurious.
minor comments (1)
- [Abstract] Abstract: "{\tau}-bench" appears to be a LaTeX artifact that should be rendered as τ-bench.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting issues with the abstract, missing formalisms in the method, and the need to justify the causal interpretation of gradients. We address each point below and will incorporate revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of performance gains and a correlation between attribution quality and optimization success is stated without any numbers, baselines, statistical tests, or description of how gradients are obtained from LLMs, so the claim cannot be evaluated.
Authors: We agree the abstract is too high-level. In revision we will add concrete numbers (e.g., absolute gains on MultiWOZ and τ-bench versus the listed baselines), note the use of statistical significance testing, and briefly state that gradients are obtained via the prefix-caching mechanism in AgentChord. revision: yes
-
Referee: [Method] Method description (throughout): no equations or derivation are supplied for the gradient-based connection weights, the attribution graph construction, or the backward propagation of task loss, which are load-bearing for the fine-grained attribution claim.
Authors: The observation is correct; the current text relies on prose. We will insert a dedicated subsection with the required equations and derivations: the token-level connection weight w_{i→j} = ∂L/∂o_i (via back-propagation through the attribution graph), the adjacency matrix construction for the attribution graph, and the loss-propagation rule. revision: yes
-
Referee: [Method] Method: the assumption that token-level gradients from a downstream task loss meaningfully quantify causal influence across discrete LLM agent steps (via non-differentiable string concatenation and black-box forward passes) is not justified or validated; any auxiliary construction (e.g., prefix caching) must be shown to preserve actual causal effects, otherwise the attribution graph is spurious.
Authors: We acknowledge that a rigorous causal proof is absent. We will add a paragraph deriving the gradient approximation under the computational-graph view and an ablation showing that AgentChord’s prefix caching yields numerically identical gradients to full forward passes on the evaluated tasks. A limitations paragraph will also be added noting that the method provides a useful proxy rather than a strict causal intervention. revision: partial
Circularity Check
No circularity: GBC is an empirical modeling proposal validated on benchmarks
full rationale
The paper introduces GBC as a new method that models MAS as a computational graph and uses token-level gradients for attribution, then optimizes prompts. Claims rest on experimental results (MultiWOZ, τ-bench) showing performance gains over baselines, not on any closed derivation or first-principles chain. No equations are presented that reduce predictions to fitted inputs by construction, no self-citation load-bearing uniqueness theorems, and no ansatz smuggled via prior work. The gradient attribution is a modeling assumption whose validity is tested empirically rather than derived tautologically. This is the common case of a self-contained algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
GAAPO: Genetic Algorithmic Applied to Prompt Optimization , author=. 2025 , eprint=
2025
-
[2]
The Eleventh International Conference on Learning Representations , year=
Large Language Models are Human-Level Prompt Engineers , author=. The Eleventh International Conference on Learning Representations , year=
-
[3]
ChatDev: Communicative agents for software development
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative Agents for Software Development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[4]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[5]
Pryzant, Reid and Iter, Dan and Li, Jerry and Lee, Yin and Zhu, Chenguang and Zeng, Michael. Automatic Prompt Optimization with ``Gradient Descent'' and Beam Search. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.494
-
[6]
2024 , eprint=
Large Language Models as Optimizers , author=. 2024 , eprint=
2024
-
[7]
Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , booktitle=
Omar Khattab and Arnav Singhvi and Paridhi Maheshwari and Zhiyuan Zhang and Keshav Santhanam and Sri Vardhamanan A and Saiful Haq and Ashutosh Sharma and Thomas T. Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , booktitle=. 2024 , url=
2024
-
[8]
GPTSwarm: language agents as optimizable graphs , year =
Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J\". GPTSwarm: language agents as optimizable graphs , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[9]
Dong, Yubo and Zhu, Xukun and Pan, Zhengzhe and Zhu, Linchao and Yang, Yi. V illager A gent: A Graph-Based Multi-Agent Framework for Coordinating Complex Task Dependencies in M inecraft. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.964
-
[10]
The Thirteenth International Conference on Learning Representations , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[11]
Differentiation
TextGrad: Automatic "Differentiation" via Text , author=. 2024 , eprint=
2024
-
[12]
2025 , eprint=
Multi-Agent Collaboration via Cross-Team Orchestration , author=. 2025 , eprint=
2025
-
[13]
Fine-Tuning and Prompt Optimization: Two Great Steps that Work Better Together
Soylu, Dilara and Potts, Christopher and Khattab, Omar. Fine-Tuning and Prompt Optimization: Two Great Steps that Work Better Together. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.597
-
[14]
2025 , url=
Research Town: Simulator of Research Community , author=. 2025 , url=
2025
-
[15]
2025 ,URL =
Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies ,author =. 2025 ,URL =
2025
-
[16]
Self-Supervised Prompt Optimization
Xiang, Jinyu and Zhang, Jiayi and Yu, Zhaoyang and Liang, Xinbing and Teng, Fengwei and Tu, Jinhao and Ren, Fashen and Tang, Xiangru and Hong, Sirui and Wu, Chenglin and Luo, Yuyu. Self-Supervised Prompt Optimization. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.479
-
[17]
Lewis Hammond and Alan Chan and Jesse Clifton and Jason Hoelscher-Obermaier and Akbir Khan and Euan McLean and Chandler Smith and Wolfram Barfuss and Jakob Foerster and Tomáš Gavenčiak and The Anh Han and Edward Hughes and Vojtěch Kovařík and Jan Kulveit and Joel Z. Leibo and Caspar Oesterheld and Christian Schroeder de Witt and Nisarg Shah and Michael We...
-
[18]
ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
Why Do Multiagent Systems Fail? , author=. ICLR 2025 Workshop on Building Trust in Language Models and Applications , year=
2025
-
[19]
Which Agent Causes Task Failures and When? On Automated Failure Attribution of
Shaokun Zhang and Ming Yin and Jieyu Zhang and Jiale Liu and Zhiguang Han and Jingyang Zhang and Beibin Li and Chi Wang and Huazheng Wang and Yiran Chen and Qingyun Wu , booktitle=. Which Agent Causes Task Failures and When? On Automated Failure Attribution of. 2025 , url=
2025
-
[20]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
metaTextGrad: Automatically optimizing language model optimizers , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[21]
Forty-second International Conference on Machine Learning , year=
MetaAgent: Automatically Constructing Multi-Agent Systems Based on Finite State Machines , author=. Forty-second International Conference on Machine Learning , year=
-
[22]
2025 , eprint=
Agent Lightning: Train ANY AI Agents with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory , author=. 2025 , eprint=
2025
-
[24]
NeurIPS 2024 Workshop on Open-World Agents , year=
An Efficient Open World Benchmark for Multi-Agent Reinforcement Learning , author=. NeurIPS 2024 Workshop on Open-World Agents , year=
2024
-
[25]
2026 , url=
Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alex Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , booktitle=. 2026 , url=
2026
-
[26]
Interpreting Language Models with Contrastive Explanations
Yin, Kayo and Neubig, Graham. Interpreting Language Models with Contrastive Explanations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.14
-
[27]
Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =
Shrikumar, Avanti and Greenside, Peyton and Kundaje, Anshul , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[28]
Ye, Fanghua and Manotumruksa, Jarana and Yilmaz, Emine. M ulti WOZ 2.4: A Multi-Domain Task-Oriented Dialogue Dataset with Essential Annotation Corrections to Improve State Tracking Evaluation. Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2022. doi:10.18653/v1/2022.sigdial-1.34
-
[29]
-bench: A Benchmark for
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik R Narasimhan , booktitle=. -bench: A Benchmark for. 2025 , url=
2025
-
[30]
R e S p A ct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents
Dongre, Vardhan and Yang, Xiaocheng and Acikgoz, Emre Can and Dey, Suvodip and Tur, Gokhan and Hakkani-Tur, Dilek. R e S p A ct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents. Proceedings of the 15th International Workshop on Spoken Dialogue Systems Technology. 2025
2025
-
[31]
M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling
Budzianowski, Pawe and Wen, Tsung-Hsien and Tseng, Bo-Hsiang and Casanueva, I \ n igo and Ultes, Stefan and Ramadan, Osman and Ga s i \'c , Milica. M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/...
-
[32]
M ulti WOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines
Eric, Mihail and Goel, Rahul and Paul, Shachi and Sethi, Abhishek and Agarwal, Sanchit and Gao, Shuyang and Kumar, Adarsh and Goyal, Anuj and Ku, Peter and Hakkani-Tur, Dilek. M ulti WOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. Proceedings of the Twelfth Language Resources and Evaluation Confer...
2020
-
[33]
Zang, Xiaoxue and Rastogi, Abhinav and Sunkara, Srinivas and Gupta, Raghav and Zhang, Jianguo and Chen, Jindong. M ulti WOZ 2.2 : A Dialogue Dataset with Additional Annotation Corrections and State Tracking Baselines. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI. 2020. doi:10.18653/v1/2020.nlp4convai-1.13
-
[34]
Han, Ting and Liu, Ximing and Takanabu, Ryuichi and Lian, Yixin and Huang, Chongxuan and Wan, Dazhen and Peng, Wei and Huang, Minlie , title =. Natural Language Processing and Chinese Computing: 10th CCF International Conference, NLPCC 2021, Qingdao, China, October 13–17, 2021, Proceedings, Part II , pages =. 2021 , isbn =. doi:10.1007/978-3-030-88483-3_1...
-
[35]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
Large Language Model Based Multi-agents: A Survey of Progress and Challenges , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , month =. doi:10.24963/ijcai.2024/890 , url =
-
[36]
2024 , eprint=
DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.