Rethinking Fairness in LLM-Based Recommender Systems: A Survey
Pith reviewed 2026-06-30 11:17 UTC · model grok-4.3
The pith
LLM-based recommender systems create new fairness problems from pretrained knowledge, prompts, generated explanations, and feedback loops that existing approaches do not yet address systematically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing work on fairness in LLM-based recommender systems can be organized through a two-dimensional taxonomy of bias mechanisms and fairness targets, accompanied by an overview of evaluation protocols and mitigation strategies, together with explicit links to explainability, privacy, robustness, and controllability.
What carries the argument
The two-dimensional view of bias mechanisms and fairness targets, which classifies studies by source of bias (pretrained knowledge, prompts, explanations, decoding, feedback) and by fairness target (individual, group, or counterfactual equity).
If this is right
- Biases can enter at distinct points including pretrained parameters, user prompts, generated explanations, decoding choices, and closed-loop feedback.
- Fairness evaluation must be designed to cover both the new generative mechanisms and the traditional recommendation objectives.
- Mitigation methods should be evaluated jointly with related properties such as explainability and robustness rather than in isolation.
- A structured taxonomy makes it possible to identify which combinations of bias mechanism and fairness target remain under-studied.
Where Pith is reading between the lines
- Researchers could test the taxonomy by attempting to classify every new fairness paper published after the survey cutoff date.
- If the two axes prove insufficient, future work could add a third dimension such as the stage of the recommendation pipeline.
- The survey's emphasis on feedback loops suggests that long-term user-model interaction studies would be a direct next step for empirical validation.
Load-bearing premise
The published literature on LLM-based recommender systems is already mature enough to support a systematic two-dimensional organization without major missing categories.
What would settle it
A set of ten or more recent papers on fairness in LLM-based recommenders whose bias sources or fairness goals fall outside the two axes defined in the survey.
Figures
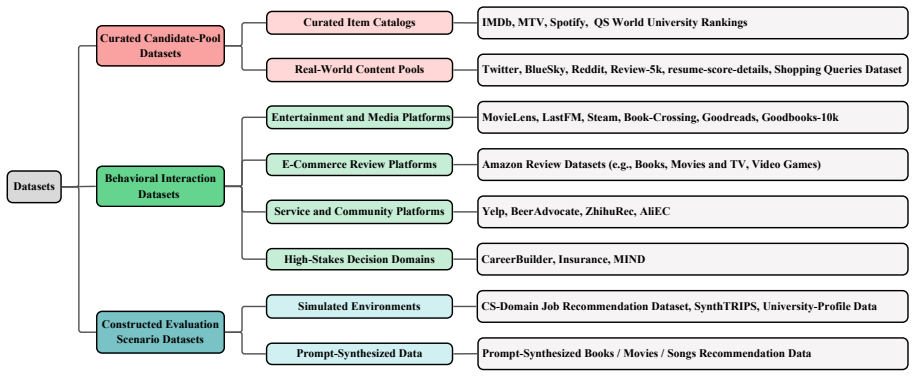
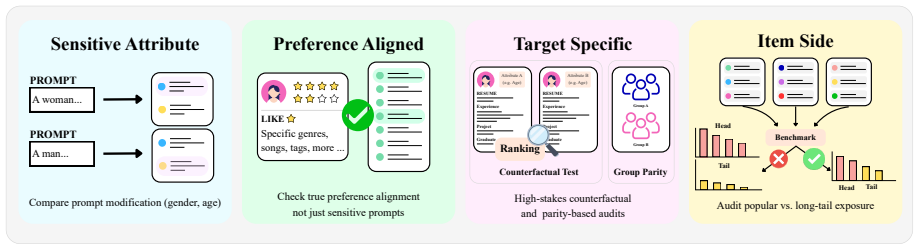
read the original abstract
Large Language Models (LLMs) are reshaping recommender systems by enabling more semantic, generative, and interactive recommendation pipelines. However, this shift also introduces new fairness challenges, as biases may arise from pretrained knowledge, prompts, generated explanations, decoding strategies, and feedback loops. This survey provides a systematic review of fairness in LLM-based recommender systems (LLM4Rec), organizing existing studies through a two-dimensional view of bias mechanisms and fairness targets, together with a structured overview of the evaluation landscape and mitigation strategies. We further connect fairness with broader trustworthy concerns, including explainability, privacy, robustness, and controllability. To the best of our knowledge, this is the first survey specifically focused on fairness in LLM4Rec, aiming to provide a structured foundation for future research on comprehensive and reliable fairness evaluation in LLM4Rec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on fairness in LLM-based recommender systems (LLM4Rec). It identifies new bias sources arising from pretrained knowledge, prompts, generated explanations, decoding strategies, and feedback loops; organizes the literature via a two-dimensional taxonomy of bias mechanisms and fairness targets; surveys evaluation methods and mitigation strategies; and links fairness to other trustworthy-AI dimensions including explainability, privacy, robustness, and controllability. The central positioning statement is that this is the first survey dedicated specifically to fairness in LLM4Rec.
Significance. If the literature selection proves comprehensive and the two-dimensional taxonomy proves stable, the survey would supply a useful organizing lens and evaluation overview for an emerging sub-area, helping future work avoid fragmented fairness assessments. The explicit linkage to broader trustworthy concerns is a constructive framing that could encourage holistic rather than isolated fairness studies.
minor comments (3)
- [Abstract, §1] Abstract and §1: the assertion that this is 'the first survey specifically focused on fairness in LLM4Rec' should be accompanied by a short, explicit enumeration of the closest prior surveys on fairness in recommender systems or on LLM4Rec in general, with a one-sentence statement of how each differs in scope.
- [§3] The two-dimensional taxonomy (bias mechanisms × fairness targets) is presented as the main organizing device; each cell should contain at least one concrete citation and a brief description of the mechanism or target so that readers can immediately map individual papers onto the grid.
- [§4, §5] Evaluation-landscape and mitigation sections would benefit from a summary table that cross-references the taxonomy cells with the metrics or techniques discussed, making the connection between taxonomy and practical guidance explicit.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation of minor revision. The assessment correctly identifies the survey's core contributions: the two-dimensional taxonomy of bias mechanisms and fairness targets, the overview of evaluation and mitigation approaches, and the explicit connections to other trustworthy-AI dimensions. No major comments were listed in the report, so we provide no point-by-point rebuttals below. We will incorporate any minor suggestions that may arise during the revision process to strengthen the manuscript.
Circularity Check
No significant circularity in survey synthesis
full rationale
This is a literature survey paper with no original derivations, equations, fitted parameters, or predictive claims. The two-dimensional taxonomy is presented as an organizing lens drawn from cited external work, and the 'first survey' statement is a coverage assertion rather than a deductive result. No self-citation chains, self-definitional loops, or reductions of outputs to inputs by construction exist. The manuscript is self-contained as a synthesis against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, Jizhi and Bao, Keqin and Zhang, Yang and Wang, Wenjie and Feng, Fuli and He, Xiangnan , title =. 2023 , isbn =. doi:10.1145/3604915.3608860 , booktitle =
-
[2]
Deldjoo, Yashar and Noia, Tommaso Di , title =. 2025 , issue_date =. doi:10.1145/3725853 , journal =
-
[3]
2024 , eprint=
A Normative Framework for Benchmarking Consumer Fairness in Large Language Model Recommender System , author=. 2024 , eprint=
2024
-
[4]
Malthouse , editor =
Xinyi Li and Yongfeng Zhang and Edward C. Malthouse , editor =. A Preliminary Study of ChatGPT on News Recommendation: Personalization, Provider Fairness, and Fake News , booktitle =. 2023 , url =
2023
-
[5]
Jiang, Meng and Bao, Keqin and Zhang, Jizhi and Wang, Wenjie and Yang, Zhengyi and Feng, Fuli and He, Xiangnan , title =. 2024 , isbn =. doi:10.1145/3589334.3648158 , booktitle =
-
[6]
Tommasel, Antonela , title =. 2024 , isbn =. doi:10.1145/3640457.3688182 , booktitle =
-
[7]
UP 5: Unbiased Foundation Model for Fairness-aware Recommendation
Hua, Wenyue and Ge, Yingqiang and Xu, Shuyuan and Ji, Jianchao and Li, Zelong and Zhang, Yongfeng. UP 5: Unbiased Foundation Model for Fairness-aware Recommendation. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.114
-
[8]
2025 , eprint=
FairEval: Evaluating Fairness in LLM-Based Recommendations with Personality Awareness , author=. 2025 , eprint=
2025
-
[9]
Proceedings of the 42nd International Conference on Machine Learning , volume =
Fayyazi, Arya and Kamal, Mehdi and Pedram, Massoud , title =. Proceedings of the 42nd International Conference on Machine Learning , volume =. 2025 , publisher =
2025
-
[10]
Li, Hanzhe and Shen, Dazhong and Wang, Chao and Liu, Yuting and Gu, Jingjing , title =. 2025 , isbn =. doi:10.1145/3726302.3729917 , pages =
-
[11]
2025 , eprint=
Improving Recommendation Fairness without Sensitive Attributes Using Multi-Persona LLMs , author=. 2025 , eprint=
2025
-
[12]
Li, Jin and Gu, Huilin and Wang, Shoujin and Zhang, Qi and Yu, Shui and Wang, Chen and Xu, Xiwei and Chen, Fang , title =. 2026 , isbn =. doi:10.1145/3774904.3793052 , booktitle =
-
[13]
Gao, Chongming and Chen, Ruijun and Yuan, Shuai and Huang, Kexin and Yu, Yuanqing and He, Xiangnan , title =. 2025 , isbn =. doi:10.1145/3696410.3714524 , booktitle =
-
[14]
Tianshu Shen and Jiaru Li and Mohamed Reda Bouadjenek and Zheda Mai and Scott Sanner , title =. Inf. Process. Manag. , volume =. 2023 , url =. doi:10.1016/J.IPM.2022.103139 , timestamp =
-
[15]
2025 , eprint=
Investigating and Mitigating Stereotype-aware Unfairness in LLM-based Recommendations , author=. 2025 , eprint=
2025
-
[16]
Hu, Yuhan and Lyu, Ziyu and Bai, Lu and Cui, Lixin , title =. 2025 , isbn =. doi:10.1145/3726302.3730145 , booktitle =
-
[17]
2026 , eprint=
Uncertainty and Fairness Awareness in LLM-Based Recommendation Systems , author=. 2026 , eprint=
2026
-
[18]
A Study of Implicit Ranking Unfairness in Large Language Models
Xu, Chen and Wang, Wenjie and Li, Yuxin and Pang, Liang and Xu, Jun and Chua, Tat-Seng. A Study of Implicit Ranking Unfairness in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.467
-
[19]
2026 , eprint=
Can Fairness Be Prompted? Prompt-Based Debiasing Strategies in High-Stakes Recommendations , author=. 2026 , eprint=
2026
-
[20]
2025 , eprint=
Revealing Potential Biases in LLM-Based Recommender Systems in the Cold Start Setting , author=. 2025 , eprint=
2025
-
[21]
2026 , eprint=
Unveiling and Mitigating Bias in Large Language Model Recommendations: A Path to Fairness , author=. 2026 , eprint=
2026
-
[22]
Lu, Sijin and Man, Zhibo and Luo, Fangyuan and Wu, Jun , title =. 2025 , isbn =. doi:10.1145/3726302.3730181 , booktitle =
-
[23]
Bowen Xu and JinYi Yoon and Zhimin Peng and Bhanu Pratap Singh Rawat and Giovanni Seni and Longfeng Wu and Tong Zeng and Dawei Zhou and Bo Ji , year=
-
[24]
Luo, Renqiang and Zhang, Dong and Gao, Yupeng and Shi, Wen and Hou, Mingliang and Liu, Jiaying and Wang, Zhe and Yu, Shuo , title =. 2026 , isbn =. doi:10.1145/3774904.3792168 , booktitle =
-
[25]
Wang, Bohao and Chen, Jiawei and Liu, Feng and Zhang, Changwang and Wang, Jun and Jin, Canghong and Chen, Chun and Wang, Can , title =. 2026 , isbn =. doi:10.1145/3774904.3792607 , booktitle =
-
[26]
Journal of Electronic Commerce Research , volume =
A Comparative Study of Fairness in AI-Enabled and LLM-Based Recommendation Systems , author =. Journal of Electronic Commerce Research , volume =. 2025 , url =
2025
-
[27]
2025 , eprint=
BiFair: A Fairness-aware Training Framework for LLM-enhanced Recommender Systems via Bi-level Optimization , author=. 2025 , eprint=
2025
-
[28]
Li, Yunzhe and Wang, Junting and Sundaram, Hari and Liu, Zhining , title =. 2025 , isbn =. doi:10.1145/3705328.3748077 , booktitle =
-
[29]
2026 , eprint=
Echoes in the Loop: Diagnosing Risks in LLM-Powered Recommender Systems under Feedback Loops , author=. 2026 , eprint=
2026
-
[30]
Wei Liu and Baisong Liu and Jiangcheng Qin and Xueyuan Zhang and Weiming Huang and Yangyang Wang , title =. Scientific Reports , year =. doi:10.1038/s41598-025-89965-3 , url =
-
[31]
2026 , eprint=
Lightweight Fairness for LLM-Based Recommendations via Kernelized Projection and Gated Adapters , author=. 2026 , eprint=
2026
-
[32]
i A gent: LLM Agent as a Shield between User and Recommender Systems
Xu, Wujiang and Shi, Yunxiao and Liang, Zujie and Ning, Xuying and Mei, Kai and Wang, Kun and Zhu, Xi and Xu, Min and Zhang, Yongfeng. i A gent: LLM Agent as a Shield between User and Recommender Systems. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.928
-
[33]
Bao, Keqin and Zhang, Jizhi and Zhang, Yang and Huo, Xinyue and Chen, Chong and Feng, Fuli. Decoding Matters: Addressing Amplification Bias and Homogeneity Issue in Recommendations for Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.589
-
[34]
2026 , eprint=
Collab-REC: An LLM-based Agentic Framework for Balancing Recommendations in Tourism , author=. 2026 , eprint=
2026
-
[35]
Hou, Yimin and Kou, Yue and Shen, Derong and Zhou, Xiangmin and Li, Dong and Nie, Tiezheng and Yu, Ge , title =. 2025 , isbn =. doi:10.1145/3746252.3761126 , booktitle =
-
[36]
Shailya, Krithi and Mishra, Akhilesh Kumar and Krishnan, Gokul S and Ravindran, Balaraman. Where Should I Study? Biased Language Models Decide! Evaluating Fairness in LM s for Academic Recommendations. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association...
-
[37]
Fan, Jing and Zhu, Chen and Wu, Han and Zhuang, Fuzhen and Wang, Deqing and Zhu, Hengshu , title =. 2025 , isbn =. doi:10.1007/978-981-95-4158-4_4 , booktitle =
-
[38]
Refining Bias and Reward in
Yi Zhang and Ruihong Qiu and Jiajun Liu and Guansong Pang and Sen Wang , year=. Refining Bias and Reward in
-
[39]
2026 , eprint=
Is Your LLM-as-a-Recommender Agent Trustable? LLMs' Recommendation is Easily Hacked by Biases (Preferences) , author=. 2026 , eprint=
2026
-
[40]
2026 , eprint=
Polarization by Default: Auditing Recommendation Bias in LLM-Based Content Curation , author=. 2026 , eprint=
2026
-
[41]
2026 , eprint=
De-conflating Preference and Qualification: Constrained Dual-Perspective Reasoning for Job Recommendation with Large Language Models , author=. 2026 , eprint=
2026
-
[42]
Proceedings of KDD 2025 Workshop on Online and Adaptive Recommender Systems (OARS '25) , year=
Algorithmic Harms Associated with Generative Model-Augmented Recommendation Systems , author=. Proceedings of KDD 2025 Workshop on Online and Adaptive Recommender Systems (OARS '25) , year=
2025
-
[43]
Proceedings of the 18th ACM Web Science Conference (WebSci '26) , year=
Self-Promotion in LLM Recommendations , author=. Proceedings of the 18th ACM Web Science Conference (WebSci '26) , year=
-
[44]
Zhang, Guixian and Yuan, Guan and Cheng, Debo and Liu, Lin and Li, Jiuyong and Zhang, Shichao , title =. 2025 , issue_date =. doi:10.1145/3736404 , journal =
-
[45]
Deldjoo, Yashar , title =. 2025 , issue_date =. doi:10.1145/3690655 , journal =
-
[46]
2026 , url=
Leveraging Holistic Explanations to Mitigate Popularity Bias for Recommender Systems , author=. 2026 , url=
2026
-
[47]
2025 , eprint=
LLM as Explainable Re-Ranker for Recommendation System , author=. 2025 , eprint=
2025
-
[48]
Hasami, Arjan and Mansoury, Masoud , title =. 2025 , isbn =. doi:10.1145/3705328.3759330 , booktitle =
-
[49]
2025 , eprint=
LLM4Rec: Large Language Models for Multimodal Generative Recommendation with Causal Debiasing , author=. 2025 , eprint=
2025
-
[50]
Mitigating Misleadingness in LLM-Generated Natural Language Explanations for Recommender Systems: Ensuring Broad Truthfulness Through Factuality and Faithfulness , booktitle =
Ulysse Maes and Lien Michiels and Annelien Smets , editor =. Mitigating Misleadingness in LLM-Generated Natural Language Explanations for Recommender Systems: Ensuring Broad Truthfulness Through Factuality and Faithfulness , booktitle =. 2025 , url =
2025
-
[51]
Reading Between the Prompts: How Stereotypes Shape LLM ' s Implicit Personalization
Neplenbroek, Vera and Bisazza, Arianna and Fern \'a ndez, Raquel. Reading Between the Prompts: How Stereotypes Shape LLM ' s Implicit Personalization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1029
-
[52]
The Twelfth International Conference on Learning Representations , year=
Beyond Memorization: Violating Privacy via Inference with Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[53]
International Research Journal of Engineering and Technology (IRJET) , volume=
Privacy-Preserving Large Language Model-Based Recommendation Systems: Challenges, Techniques, and Opportunities , author=. International Research Journal of Engineering and Technology (IRJET) , volume=. 2025 , url=
2025
-
[54]
2025 , eprint=
Privacy-Utility-Bias Trade-offs for Privacy-Preserving Recommender Systems , author=. 2025 , eprint=
2025
-
[55]
ACM Transactions on Information Systems , volume =
Jianghao Lin and Xinyi Dai and Yunjia Xi and Weiwen Liu and Bo Chen and Hao Zhang and Yong Liu and Chuhan Wu and Xiangyang Li and Chenxu Zhu and Huifeng Guo and Yong Yu and Ruiming Tang and Weinan Zhang , title =. ACM Transactions on Information Systems , volume =. 2025 , month =. doi:10.1145/3678004 , publisher =
-
[56]
2024 , eprint =
Qi Wang and Jindong Li and Shiqi Wang and Qianli Xing and Runliang Niu and He Kong and Rui Li and Guodong Long and Yi Chang and Chengqi Zhang , title =. 2024 , eprint =
2024
-
[57]
Ren, Xubin and Wei, Wei and Xia, Lianghao and Su, Lixin and Cheng, Suqi and Wang, Junfeng and Yin, Dawei and Huang, Chao , title =. 2024 , isbn =. doi:10.1145/3589334.3645458 , booktitle =
-
[58]
Wei, Wei and Ren, Xubin and Tang, Jiabin and Wang, Qinyong and Su, Lixin and Cheng, Suqi and Wang, Junfeng and Yin, Dawei and Huang, Chao , title =. 2024 , isbn =. doi:10.1145/3616855.3635853 , pages =
-
[59]
Geng, Shijie and Liu, Shuchang and Fu, Zuohui and Ge, Yingqiang and Zhang, Yongfeng , title =. 2022 , isbn =. doi:10.1145/3523227.3546767 , booktitle =
-
[60]
2022 , eprint=
M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems , author=. 2022 , eprint=
2022
-
[61]
XR ec: Large Language Models for Explainable Recommendation
Ma, Qiyao and Ren, Xubin and Huang, Chao. XR ec: Large Language Models for Explainable Recommendation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.22
-
[62]
Lubos, Sebastian and Tran, Thi Ngoc Trang and Felfernig, Alexander and Polat Erdeniz, Seda and Le, Viet-Man , title =. 2024 , isbn =. doi:10.1145/3631700.3665185 , booktitle =
-
[63]
Hou, Yupeng and Zhang, Junjie and Lin, Zihan and Lu, Hongyu and Xie, Ruobing and McAuley, Julian and Zhao, Wayne Xin , title =. 2024 , isbn =. doi:10.1007/978-3-031-56060-6_24 , booktitle =
-
[64]
Enhancing Reranking for Recommendation with LLM s through User Preference Retrieval
Zhang, Haobo and Zhu, Qiannan and Dou, Zhicheng. Enhancing Reranking for Recommendation with LLM s through User Preference Retrieval. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.