Drag, Infer, Reproject: Grounding LLMs through Spatial Interaction for Image Clustering
Pith reviewed 2026-07-02 21:11 UTC · model grok-4.3
The pith
Large language models can infer and refine image clustering criteria from sequences of user drag interactions to guide reprojection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
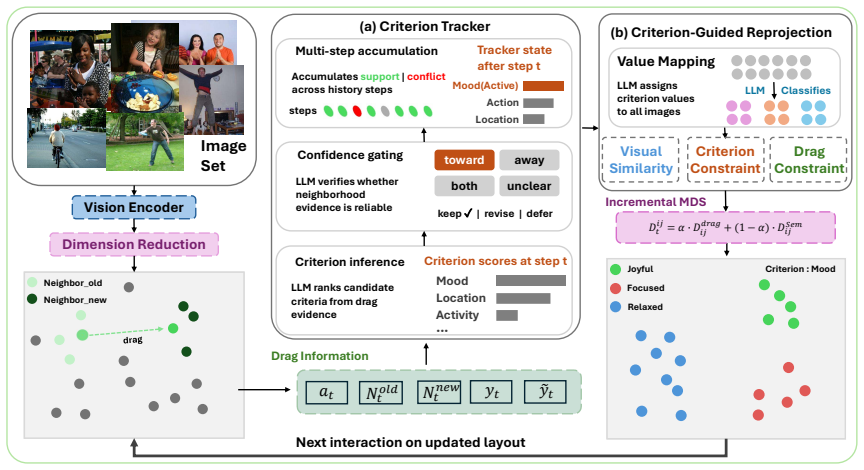
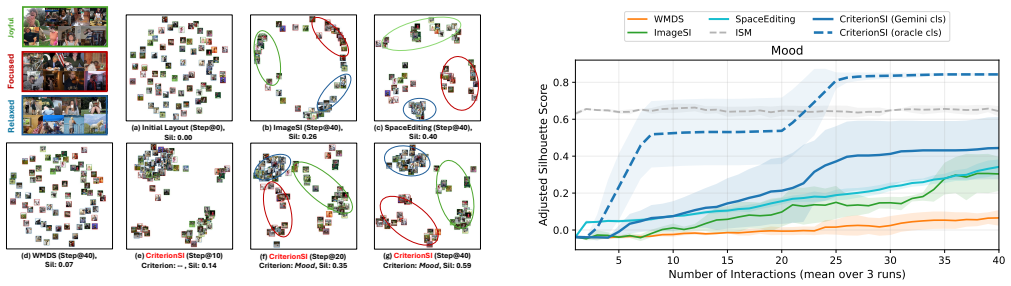
CriterionSI uses large language models to infer and refine the clustering criterion from sequential user drags, while grounding semantic interpretation in human-provided feedback rather than fixed prior assumptions. CriterionSI combines the inferred criterion with local drags to guide global reprojection. The simulation-based evaluation and usage scenario demonstrate that CriterionSI can discover and refine the target criterion from sequential interactions and progressively produce criterion-aligned clustering layouts.
What carries the argument
CriterionSI, a method that infers a user clustering criterion from sequences of drag interactions using large language models and applies the result to steer global image layout reprojection.
If this is right
- Clustering criteria can emerge and be refined gradually through interaction instead of requiring upfront specification.
- Global image layouts can be adjusted by merging an inferred high-level criterion with immediate local drag feedback.
- Semantic interpretations stay grounded in ongoing human feedback rather than static prior models.
- LLMs enable the conversion of incremental spatial drags into criterion-guided changes across the full dataset.
Where Pith is reading between the lines
- The same inference pattern could support interactive tasks in other domains where users clarify goals only by manipulating spatial arrangements, such as sorting documents or arranging charts.
- Systems built this way would need mechanisms to resolve cases where drag sequences suggest multiple or conflicting criteria at once.
- Pairing drag-based inference with additional signals like spoken descriptions could strengthen criterion accuracy in future versions.
Load-bearing premise
Large language models can reliably and accurately infer the user's intended clustering criterion from sequences of drag interactions alone, without predefined options or additional context.
What would settle it
Run the same sequence of drag interactions on identical image sets multiple times or with different users and check whether the inferred criteria and resulting layouts remain consistent and match user judgments of alignment.
Figures
read the original abstract
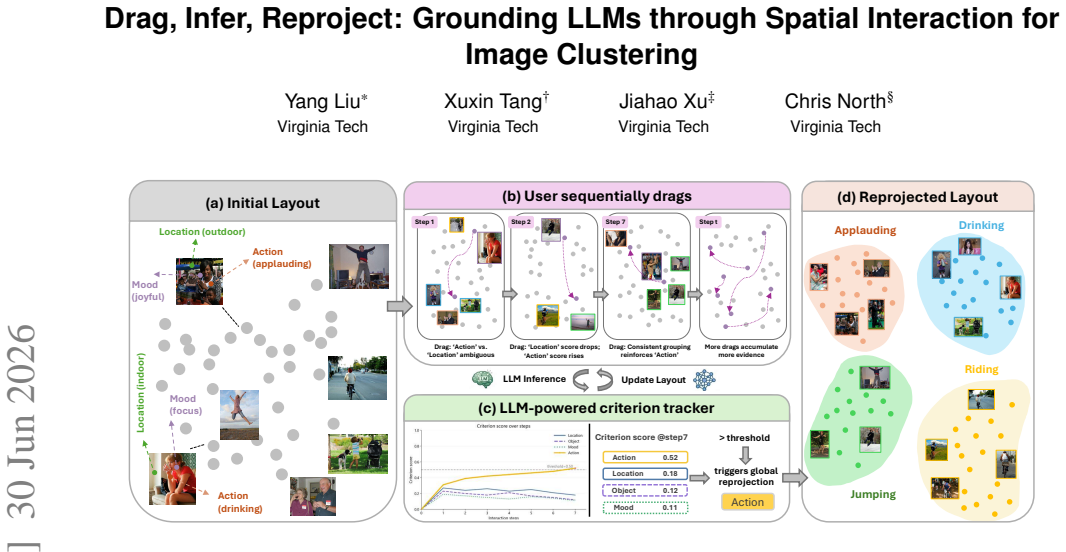
Dimension reduction and semantic interaction support image clustering by making similarity structure visible and manipulable. Existing semantic interaction methods encode users' clustering criterion (a user-interpretable semantic dimension, e.g., action, location, or mood) from direct manipulation to steer reprojection, giving users direct control over the resulting layout. Yet they typically depend on learned embeddings or a predefined criterion. In practice, users' clustering criterion often emerges gradually and becomes refined through interaction rather than being fully clear at the outset. In this work, we present CriterionSI (Criterion-guided Semantic Interaction), a method that translates incremental drag interactions into criterion-guided reprojection. CriterionSI uses large language models to infer and refine the clustering criterion from sequential user drags, while grounding semantic interpretation in human-provided feedback rather than fixed prior assumptions. CriterionSI combines the inferred criterion with local drags to guide global reprojection. The simulation-based evaluation and usage scenario demonstrate that CriterionSI can discover and refine the target criterion from sequential interactions and progressively produce criterion-aligned clustering layouts. Our code and data are available at: https://github.com/4C79/CriterionSI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CriterionSI, a semantic interaction technique for image clustering. It translates incremental user drag interactions into an inferred clustering criterion (e.g., action, location, mood) via large language models, grounds the inference in human feedback rather than fixed priors or embeddings, and combines the criterion with local drags to steer global reprojection. The central claim is that simulation-based evaluation and a usage scenario demonstrate the method can discover and refine an unknown target criterion from sequential interactions to produce progressively criterion-aligned layouts.
Significance. If the central claim holds, CriterionSI would advance semantic interaction methods by supporting emergent, user-refined criteria without predefined options, increasing flexibility in visual analytics and HCI for image data. The open-source code and data at the provided GitHub link are a clear strength for reproducibility and further testing.
major comments (2)
- [Abstract] Abstract: the assertion that 'simulation-based evaluation ... demonstrate[s] that CriterionSI can discover and refine the target criterion from sequential interactions' is load-bearing for the central claim, yet the described evaluation supplies a hidden target criterion to generate drags and then measures recovery; this does not test LLM inference reliability on real, noisy, inconsistent human drags where the criterion truly emerges during interaction.
- [Abstract] Abstract (and Evaluation section): no details are supplied on simulation design, metrics, baselines, statistical controls, or how 'correct' drags are generated, so the degree of empirical support for the inference step cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and abstract. We address the two major comments point by point below and will revise the manuscript to improve clarity and detail on the simulation design.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'simulation-based evaluation ... demonstrate[s] that CriterionSI can discover and refine the target criterion from sequential interactions' is load-bearing for the central claim, yet the described evaluation supplies a hidden target criterion to generate drags and then measures recovery; this does not test LLM inference reliability on real, noisy, inconsistent human drags where the criterion truly emerges during interaction.
Authors: We agree that the simulation supplies a known target criterion to generate the drag sequences and then measures how well CriterionSI recovers and refines it. This controlled design isolates the performance of the LLM inference step without confounding factors from real-user variability. The usage scenario section illustrates the system in an open-ended interaction where the criterion is not pre-specified to the system. We will revise the abstract to describe the simulation more precisely as a controlled recovery experiment rather than a direct demonstration of criterion emergence from noisy human input. A multi-participant user study measuring inference on inconsistent drags would strengthen the claim but is outside the current scope. revision: partial
-
Referee: [Abstract] Abstract (and Evaluation section): no details are supplied on simulation design, metrics, baselines, statistical controls, or how 'correct' drags are generated, so the degree of empirical support for the inference step cannot be assessed.
Authors: We acknowledge that the current manuscript does not provide sufficient detail on these aspects. We will expand the Evaluation section with a complete description of the simulation design, including the procedure for generating 'correct' drags from the target criterion, the quantitative metrics (e.g., criterion alignment over iterations), any baselines, and statistical controls or significance testing. This revision will allow readers to evaluate the empirical support for the inference component. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a procedural method (CriterionSI) that uses LLMs to infer clustering criteria from sequential drag interactions and combines them with local drags for reprojection. No equations, fitted parameters, or mathematical derivations are present in the provided text. The central claim rests on the LLM inference step and simulation-based demonstration rather than any self-definitional reduction, fitted-input prediction, or load-bearing self-citation chain. The evaluation setup (simulation with target criteria) raises questions about external validity but does not constitute circularity in the method's derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can infer and refine user clustering criteria from sequences of drag interactions
Reference graph
Works this paper leans on
-
[1]
Y . Bian, R. Faust, and C. North. NeuralSI: Neural design of se- mantic interaction for interactive deep learning.arXiv preprint arXiv:2402.17178, 2024. doi: 10.48550/arXiv.2402.17178 1
-
[2]
Y . Bian and C. North. DeepSI: Interactive deep learning for semantic interaction. InProceedings of the 26th International Conference on Intelligent User Interfaces, pp. 197–207. ACM, 2021. doi: 10.1145/ 3397481.3450670 1, 2
-
[3]
M. Cavallo and C ¸ . Demiralp. Clustrophile 2: Guided visual clustering analysis.IEEE Transactions on Visualization and Computer Graphics, 25(1):267–276, 2019. doi: 10.1109/TVCG.2018.2864477 1
-
[4]
Endert, P
A. Endert, P. Fiaux, and C. North. Semantic interaction for sensemak- ing: inferring analytical reasoning for model steering.IEEE Trans- actions on Visualization and Computer Graphics, 18(12):2879–2888,
-
[5]
doi: 10.1109/TVCG.2012.260 1, 2
-
[6]
M. Espadoto, R. M. Martins, A. Kerren, N. S. Hirata, and A. C. Telea. Toward a quantitative survey of dimension reduction techniques.IEEE Transactions on Visualization and Computer Graphics, 27(3):2153– 2173, 2021. doi: 10.1109/TVCG.2019.2944182 1
-
[7]
A. K. Jain. Data clustering: 50 years beyond k-means.Pattern Recog- nition Letters, 31(8):651–666, 2010. doi: 10.1016/j.patrec.2009.09. 011 1, 2
-
[8]
D. A. Keim, F. Mansmann, J. Schneidewind, J. Thomas, and H. Ziegler. Visual analytics: Scope and challenges. InVisual data mining: Theory, techniques and tools for visual analytics, pp. 76–90. Springer, 2008. doi: 10.1007/978-3-540-71080-6 6 1
-
[9]
B. C. Kwon, B. Eysenbach, J. Verma, K. Ng, C. De Filippi, W. F. Stewart, and A. Perer. Clustervision: Visual supervision of unsuper- vised clustering.IEEE Transactions on Visualization and Computer Graphics, 24(1):142–151, 2018. doi: 10.1109/TVCG.2017.2745085 1
-
[10]
S. Kwon, J. Park, M. Kim, J. Cho, E. K. Ryu, and K. Lee. Image clus- tering conditioned on text criteria. InProceedings of the International Conference on Learning Representations (ICLR), 2024. 1, 2, 4
2024
-
[11]
J. Lin, R. Faust, and C. North. ImageSI: Semantic interaction for deep learning image projections. In2024 IEEE Visualization and Visual Analytics (VIS), pp. 91–95. IEEE, 2024. doi: 10.1109/VIS55277.2024 .00026 1, 2, 4
-
[12]
L. G. Nonato and M. Aupetit. Multidimensional projection for visual analytics: Linking techniques with distortions, tasks, and layout en- richment.IEEE Transactions on Visualization and Computer Graph- ics, 25(8):2650–2673, 2019. doi: 10.1109/TVCG.2018.2846735 1
- [13]
-
[14]
Pirolli and S
P. Pirolli and S. Card. The Sensemaking Process and Leverage Points for Analyst Technology as Identified through Cognitive Task Analy- sis. InProceedings of the International Conference on Intelligence Analysis, pp. 2–4. McLean, V A, USA, 2005. 1
2005
-
[15]
D. Sacha, A. Stoffel, F. Stoffel, B. C. Kwon, G. Ellis, and D. A. Keim. Knowledge generation model for visual analytics.IEEE Transactions on Visualization and Computer Graphics, 20(12):1604–1613, 2014. doi: 10.1109/TVCG.2014.2346481 1
-
[16]
D. Sacha, L. Zhang, M. Sedlmair, J. A. Lee, J. Peltonen, D. Weiskopf, S. C. North, and D. A. Keim. Visual interaction with dimensional- ity reduction: A structured literature analysis.IEEE Transactions on Visualization and Computer Graphics, 23(1):241–250, 2017. doi: 10. 1109/TVCG.2016.2598495 1
-
[17]
J. Z. Self, M. Dowling, J. Wenskovitch, I. Crandell, M. Wang, L. House, S. Leman, and C. North. Observation-level and parametric interaction for high-dimensional data analysis.ACM Transactions on Interactive Intelligent Systems (TiiS), 8(2):1–36, 2018. doi: 10.1145/ 3158230 2, 4
2018
-
[18]
Q. Sun, Y . Fang, L. Wu, X. Wang, and Y . Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.48550/arXiv.2303.15389 3, 4
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.15389
-
[20]
X. Tang, I. Tahmid, E. Krokos, K. Whitley, X. Wang, and C. North. Semantic prompting: Agentic incremental narrative refinement through spatial semantic interaction.arXiv preprint arXiv:2604.19971, 2026. doi: 10.48550/arXiv.2604.19971 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.19971 2026
-
[21]
Ware.Information visualization: perception for design
C. Ware.Information visualization: perception for design. Morgan Kaufmann, 2019. 1
2019
-
[22]
J. Wei, D. Xia, H. Xie, C.-M. Chang, C. Li, and X. Yang. SpaceEdit- ing: A latent space editing interface for integrating human knowledge into deep neural networks. InProceedings of the 29th International Conference on Intelligent User Interfaces, pp. 489–503. ACM, 2024. doi: 10.1145/3640543.3645211 1, 2, 4
-
[23]
Wenskovitch, M
J. Wenskovitch, M. Dowling, and C. North. Toward addressing am- biguous interactions and inferring user intent with dimension reduc- tion and clustering combinations in visual analytics.ACM Transac- tions on Interactive Intelligent Systems, 14(1):1–35, 2024. doi: 10. 1145/3588565 1, 2
2024
-
[24]
J. Xia, Y . Zhang, J. Song, Y . Chen, Y . Wang, and S. Liu. Revisiting dimensionality reduction techniques for visual cluster analysis: An empirical study.IEEE Transactions on Visualization and Computer Graphics, 28(1):529–539, 2022. doi: 10.1109/TVCG.2021.3114694 1
-
[25]
B. Yao, X. Jiang, A. Khosla, A. L. Lin, L. Guibas, and L. Fei-Fei. Human action recognition by learning bases of action attributes and parts. InProceedings of the IEEE International Conference on Com- puter Vision (ICCV), pp. 1331–1338. IEEE, 2011. doi: 10.1109/ICCV .2011.6126386 4
-
[26]
J. Yao, Q. Qian, and J. Hu. Multi-modal proxy learning towards per- sonalized visual multiple clustering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14066– 14075. IEEE, 2024. doi: 10.1109/CVPR52733.2024.01334 2
-
[27]
J. Zhang, J. Huang, S. Jin, and S. Lu. Vision-language models for vision tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5625–5644, 2024. doi: 10.1109/TPAMI. 2024.3369699 1
-
[28]
Y . Zhao, Y . Zhang, Y . Zhang, X. Zhao, J. Wang, Z. Shao, C. Turkay, and S. Chen. LEV A: Using large language models to enhance visual analytics.IEEE Transactions on Visualization and Computer Graph- ics, 31(3):1830–1847, 2025. doi: 10.1109/TVCG.2024.3368060 1, 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.