Improved Scaling for Fast Mode of Ozaki Scheme II
Pith reviewed 2026-06-30 02:34 UTC · model grok-4.3
The pith
A revised scaling formula derived via Cauchy-Schwarz from the CRT uniqueness condition makes Ozaki Scheme II fast mode scale-invariant by construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
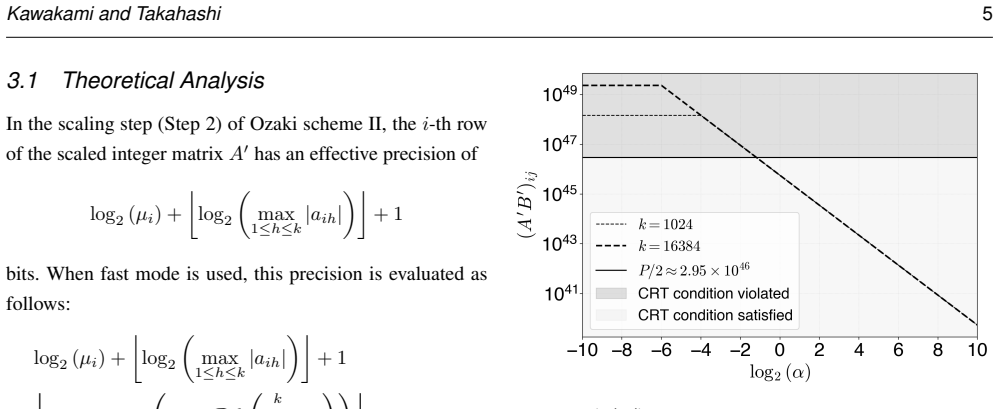
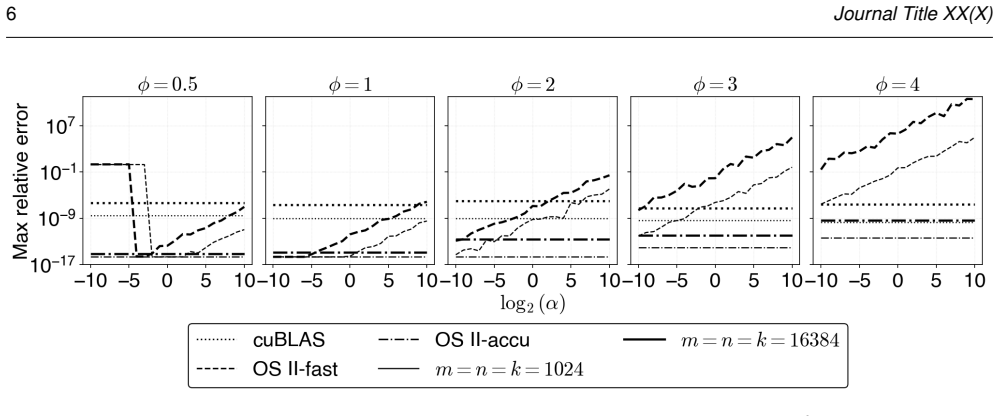
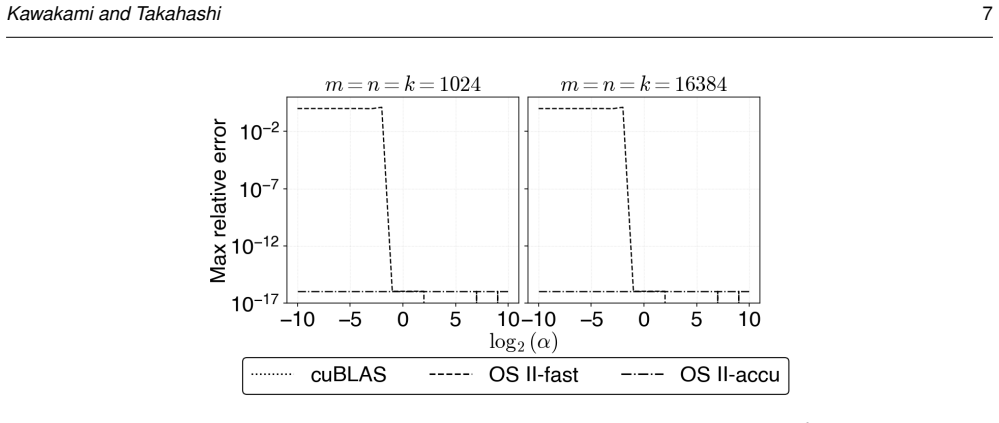
Ozaki scheme II emulates high-precision matrix multiplication using low-precision integer matrix operations based on the Chinese remainder theorem (CRT). It first scales the high-precision matrices to convert them into integer matrices. For this scaling step, Ozaki scheme II provides two modes: accurate mode, which uses INT8 matrix multiplication to estimate scaling factors, and fast mode, which applies the Cauchy-Schwarz inequality at lower computational cost. The existing fast-mode formula lacks scale invariance; multiplying the input matrices by a constant changes the effective bit width of the integer matrices in the scaling step, causing accuracy degradation or CRT recovery failure. The
What carries the argument
The revised scaling formula obtained by applying the Cauchy-Schwarz inequality directly to the CRT uniqueness condition, ensuring scale invariance and unconditional satisfaction of the uniqueness bound.
If this is right
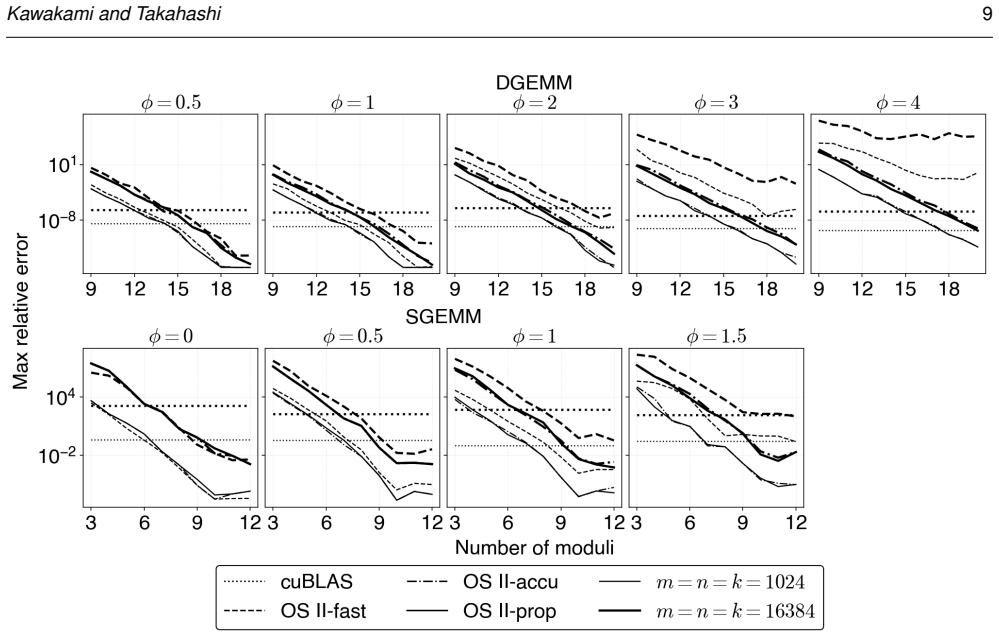
- Fast mode now achieves accuracy comparable to accurate mode while retaining its original throughput on GPU hardware.
- The accuracy-throughput trade-off of Ozaki scheme II improves because the method removes the accuracy limitation of fast mode without incurring the throughput cost of accurate mode.
- No runtime adjustments or extra matrix multiplications are required when input matrices have different magnitude ranges.
- The scheme can be applied directly to arbitrary input matrices without prior normalization steps that would otherwise be needed to avoid CRT failure.
Where Pith is reading between the lines
- The same scale-invariance defect may exist in other CRT-based high-precision emulation techniques that rely on Cauchy-Schwarz bounds, suggesting analogous fixes could be derived for them.
- Because the formula is parameter-free and derived from the uniqueness condition alone, it may extend without modification to higher-precision integer formats or to matrix multiplications performed on different low-precision hardware.
- Applications that feed matrices of unknown or varying dynamic range into Ozaki multiplication can now rely on the fast path without separate magnitude analysis.
Load-bearing premise
The derivation via Cauchy-Schwarz inequality applied to the CRT uniqueness condition produces a scaling formula that remains valid and sufficient for all possible input matrix values and scalings without requiring additional runtime checks or adjustments.
What would settle it
Execute the revised fast-mode scaling on the same matrix pair multiplied by constants of widely different magnitudes (for example 1, 10, 100, and 1000) and confirm that the recovered product accuracy stays comparable to accurate mode and that CRT recovery never fails, whereas the original formula produces failures or accuracy loss for some of those scalings.
Figures
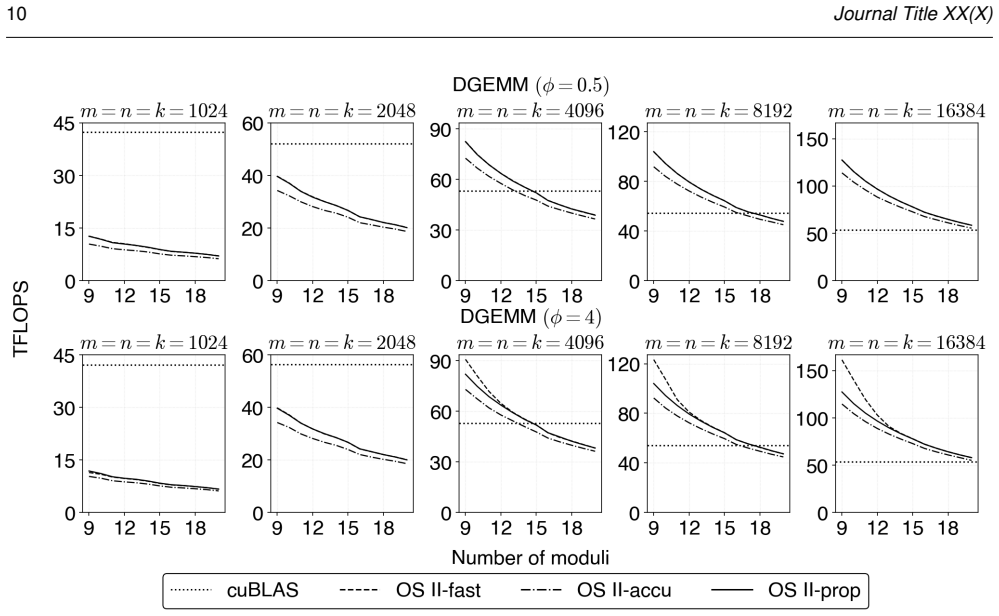
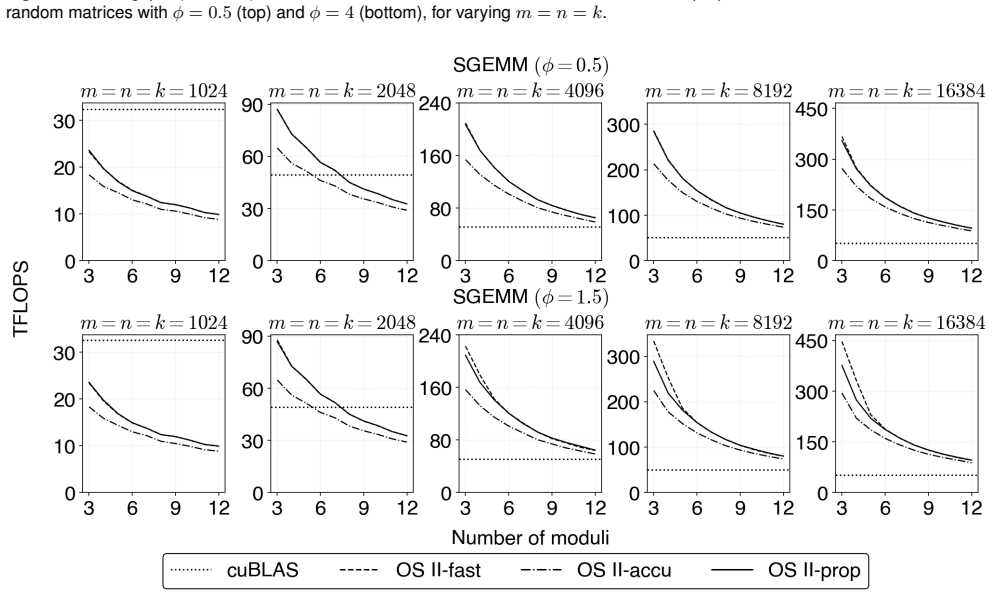
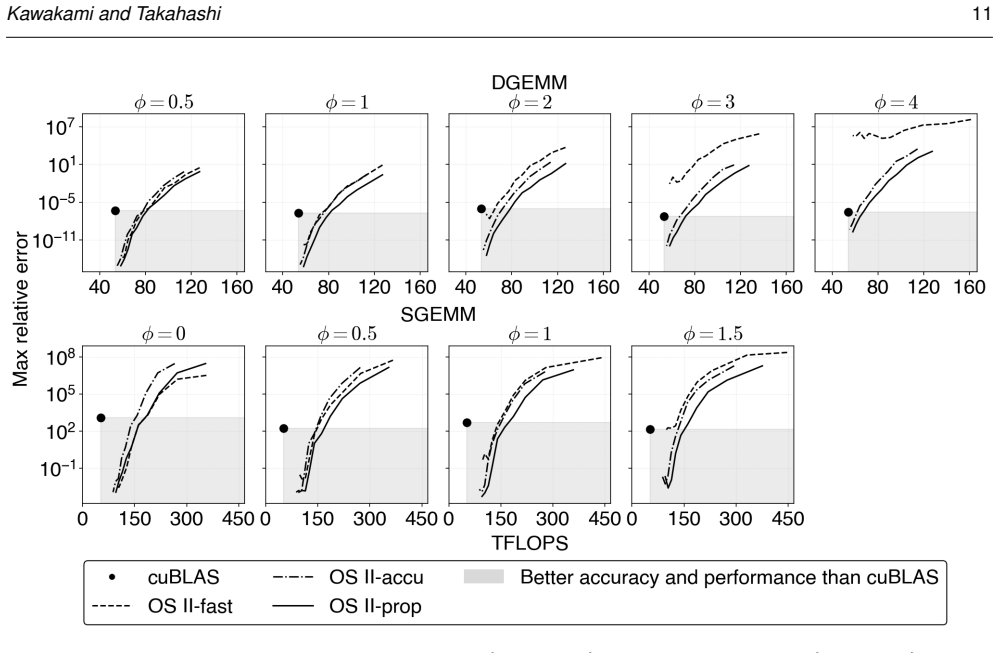
read the original abstract
Ozaki scheme II emulates high-precision matrix multiplication using low-precision integer matrix operations based on the Chinese remainder theorem (CRT). It first scales the high-precision matrices to convert them into integer matrices. For this scaling step, Ozaki scheme II provides two modes: accurate mode, which uses INT8 matrix multiplication to estimate scaling factors, and fast mode, which applies the Cauchy--Schwarz inequality at lower computational cost. We show that the existing formula lacks scale invariance; multiplying the input matrices by a constant changes the effective bit width of the integer matrices in the scaling step, causing accuracy degradation or CRT recovery failure. To address this, we propose a revised scaling formula derived from the CRT uniqueness condition via the Cauchy--Schwarz inequality. The proposed formula is scale-invariant by construction, guarantees that the CRT uniqueness condition is always satisfied, and introduces no additional overhead over the original fast mode. Experiments on an NVIDIA GH200 GPU show that the proposed method achieves accuracy comparable to that of accurate mode while maintaining throughput comparable to that of fast mode. In the accuracy--throughput trade-off, the proposed method overcomes the accuracy limitation of fast mode and the throughput constraint of accurate mode, offering a superior accuracy and performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies that the existing fast-mode scaling formula in Ozaki scheme II lacks scale invariance: multiplying input matrices by a constant alters the effective bit width of the resulting integer matrices, which can degrade accuracy or cause CRT recovery failure. It proposes a revised scaling formula obtained by applying the Cauchy-Schwarz inequality directly to the CRT uniqueness condition. The new formula is asserted to be scale-invariant by construction, to guarantee that the CRT uniqueness condition is always satisfied for any input scaling, and to incur no additional overhead. GPU experiments on an NVIDIA GH200 are reported to show accuracy comparable to accurate mode while preserving throughput comparable to fast mode, thereby improving the accuracy-throughput trade-off.
Significance. If the derivation is complete and the experimental claims hold without post-hoc adjustments, the result would strengthen the practical applicability of Ozaki scheme II for high-precision matrix multiplication on GPUs. The scale-invariant guarantee addresses a concrete robustness issue in the fast mode, and the absence of extra operations preserves the performance advantage. Reproducible GPU timing and accuracy data would constitute a useful contribution to mathematical software for mixed-precision linear algebra.
major comments (2)
- [Abstract / proposed formula] Abstract and description of the proposed formula: the manuscript states that the revised formula is derived from the CRT uniqueness condition via the Cauchy-Schwarz inequality and is scale-invariant by construction, yet the full algebraic steps that produce the explicit formula from the uniqueness bound are not supplied. Without these steps it is impossible to confirm that the inequality application yields a bound that remains valid and sufficient for arbitrary matrix entries and scalings, which is the load-bearing claim.
- [Experiments] Experiments section: the manuscript reports accuracy comparable to accurate mode and throughput comparable to fast mode on an NVIDIA GH200, but provides neither an error analysis nor the rules used to select or exclude input matrices and scalings. This omission prevents verification that the guarantee holds without post-hoc adjustments across the full range of inputs, directly affecting the weakest assumption identified in the review.
minor comments (1)
- [Abstract] The abstract would benefit from stating the explicit mathematical expression of the revised scaling formula rather than only describing its properties.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the positive assessment of the significance of our work on improving the scale invariance of the fast mode in Ozaki scheme II. Below, we provide point-by-point responses to the major comments. We will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract / proposed formula] Abstract and description of the proposed formula: the manuscript states that the revised formula is derived from the CRT uniqueness condition via the Cauchy-Schwarz inequality and is scale-invariant by construction, yet the full algebraic steps that produce the explicit formula from the uniqueness bound are not supplied. Without these steps it is impossible to confirm that the inequality application yields a bound that remains valid and sufficient for arbitrary matrix entries and scalings, which is the load-bearing claim.
Authors: We agree that the full algebraic derivation steps are not explicitly provided in the current manuscript. In the revised version, we will add a new section detailing the complete derivation: starting from the CRT uniqueness condition, applying the Cauchy-Schwarz inequality to bound the product of the scaled matrices, and arriving at the scale-invariant formula. This will demonstrate that the resulting bound is valid and sufficient for arbitrary matrix entries and input scalings, as the inequality holds independently of the scaling factor. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript reports accuracy comparable to accurate mode and throughput comparable to fast mode on an NVIDIA GH200, but provides neither an error analysis nor the rules used to select or exclude input matrices and scalings. This omission prevents verification that the guarantee holds without post-hoc adjustments across the full range of inputs, directly affecting the weakest assumption identified in the review.
Authors: We acknowledge that the manuscript lacks a formal error analysis and explicit rules for input matrix selection. The experiments used randomly generated matrices with entries drawn from uniform distributions and tested multiple scaling factors to illustrate the issue with the original formula and the robustness of the new one. In the revision, we will include an error analysis deriving the expected error from the theoretical bound and specify the input generation procedure, including the ranges and number of trials. This will enable independent verification of the claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives a revised scaling formula by applying the Cauchy-Schwarz inequality directly to the CRT uniqueness condition, producing a scale-invariant expression that satisfies the condition by construction. This is a standard first-principles derivation from the stated mathematical constraint rather than a fit, self-definition, or self-citation chain. No load-bearing step reduces to its own inputs by construction, and the abstract and reader's summary describe an independent guarantee without fitted parameters or renamed empirical patterns. The derivation is self-contained against the external CRT condition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The CRT uniqueness condition must hold for the integer matrices produced by the scaling step in order to recover the correct high-precision result.
Reference graph
Works this paper leans on
-
[1]
Katsuhisa Ozaki and Yuki Uchino and Toshiyuki Imamura , title =. , volume =. 2025 , month =. 2504.08009 , eprintclass =
-
[2]
Ozaki,Katsuhisa and Ogita,Takeshi and Oishi,Shin'ichi and Rump,Siegfried M. , title =. Numer. Algorithms , booktitle =. 2012 , month =. doi:10.1007/s11075-011-9478-1 , url =
-
[3]
, booktitle =
NVIDIA , title =. , booktitle =. 2024 , month =. doi:, url =
2024
-
[4]
Double-Precision Matrix Multiplication Emulation via Ozaki-II Scheme with FP8 Quantization
Yuki Uchino and Katsuhisa Ozaki and Toshiyuki Imamura , title =. , volume =. 2026 , month =. 2603.10634 , url =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Uchino, Yuki and Ozaki, Katsuhisa and Imamura, Toshiyuki , title =. , booktitle =. 2025 , month =. doi:10.1145/3731599.3767539 , url =
-
[6]
Yuki Uchino and Katsuhisa Ozaki and Toshiyuki Imamura , title =. , volume =. 2026 , month =. 2602.02549 , eprintclass =
-
[7]
2026 , month=
Uchino, Yuki and Ma, Qianxiang and Imamura, Toshiyuki and Ozaki, Katsuhisa and Gutsche, Patrick Lars , booktitle=. 2026 , month=
2026
-
[8]
2026 , month =
Shota Kawakami , title =. 2026 , month =
2026
-
[9]
, booktitle =
Yuki Uchino , title =. , booktitle =. 2026 , month =. doi:, url =
2026
-
[10]
, booktitle =
NVIDIA , title =. , booktitle =. 2023 , month =. doi:, url =
2023
-
[11]
, booktitle =
NVIDIA , title =. , booktitle =. 2025 , month =. doi:, url =
2025
-
[12]
, booktitle =
NVIDIA , title =. , booktitle =. 2026 , month =. doi:, url =
2026
-
[13]
, booktitle =
AMD , title =. , booktitle =. 2026 , month =. doi:, url =
2026
-
[14]
Mukunoki, Daichi and Ozaki, Katsuhisa and Ogita, Takeshi and Imamura, Toshiyuki , booktitle =. 2020 , month =. doi:10.1007/978-3-030-50743-5_12 , keywords =
-
[15]
2024 , month =
Ootomo, Hiroyuki and Ozaki, Katsuhisa and Yokota, Rio , journal =. 2024 , month =
2024
-
[16]
Higham, Nicholas J. and Mary, Theo , year=. Mixed precision algorithms in numerical linear algebra , volume=. doi:10.1017/S0962492922000022 , journal=
-
[17]
Jack Dongarra and John Gunnels and Harun Bayraktar and Azzam Haidar and Dan Ernst , year=. 2411.12090 , url=
-
[18]
Mixed-precision ab initio tensor network state methods adapted for nvidia blackwell technology via emulated fp64 arithmetic , author=. J. Chem. Theory Comput. , year=
-
[19]
William Dawson and Katsuhisa Ozaki and Jens Domke and Takahito Nakajima , year=. 2407.13299 , url=
-
[20]
Mukunoki, Daichi , booktitle =. 2026 , pages =. doi:10.1145/3784828.3785017 , numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.