CORE Planner: Contextual-memory Oriented Reinforcement-learning in Unknown Environments for Robot Navigation
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
The CORE planner integrates sparse visibility graphs with Transformer contextual memory in reinforcement learning to navigate unknown environments and achieve zero-shot sim-to-real transfer without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
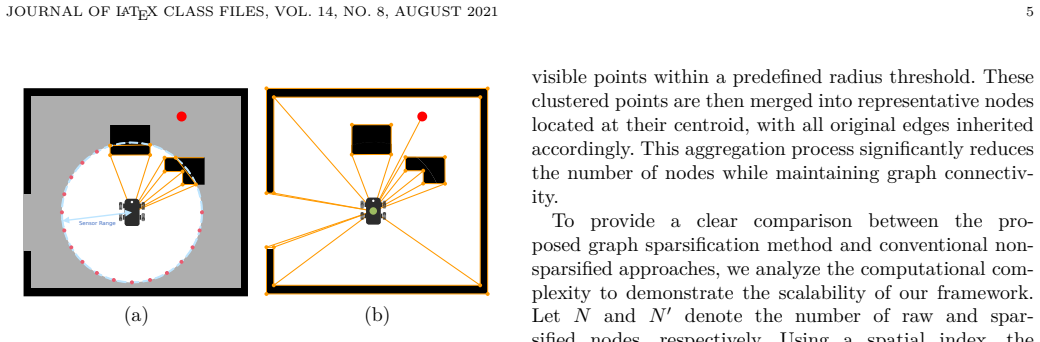
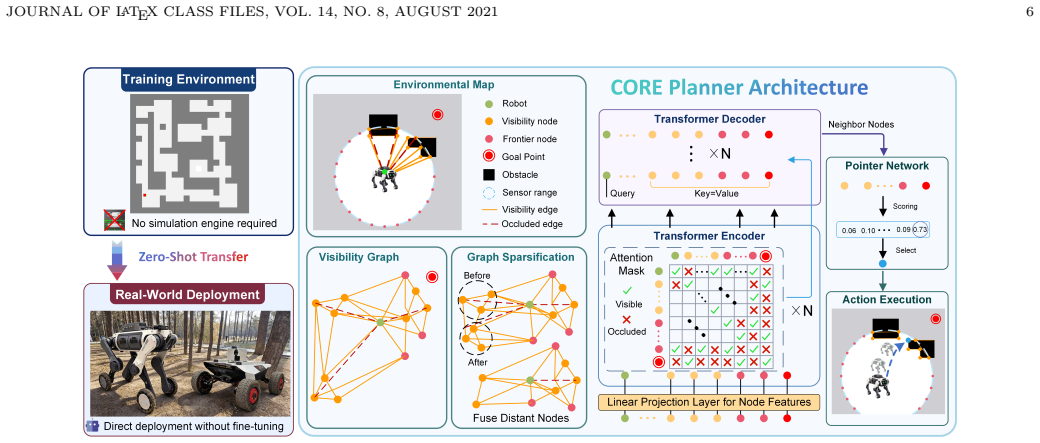
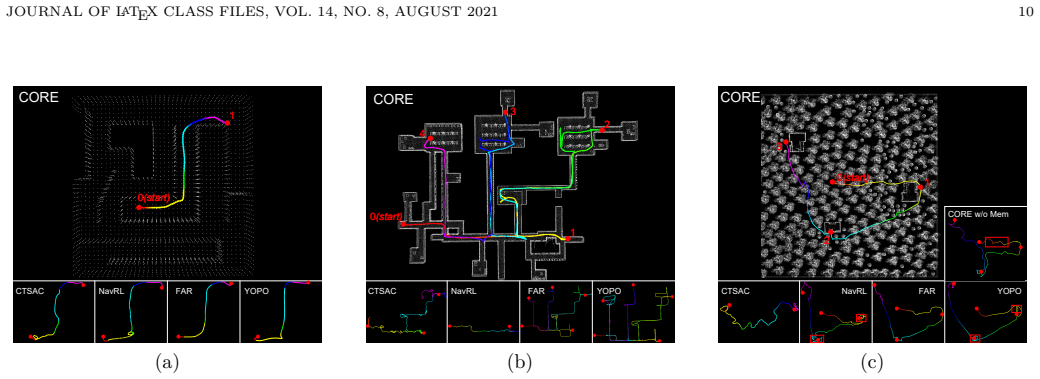
The CORE planner uses a visibility graph for structured environment representation together with graph sparsification and a contextual memory mechanism inside a reinforcement learning policy. A Transformer network processes the memory to produce a holistic understanding that improves decision making. This combination yields lower travel distances than the FAR Planner or learning baselines and supports direct transfer from image-only simulation training to real-robot execution without any fine-tuning or human intervention in representative environments.
What carries the argument
The CORE planner, which fuses a sparse visibility graph representation and graph sparsification with a Transformer-driven contextual memory module inside reinforcement learning.
If this is right
- Travel distance drops 13 percent relative to the traditional FAR Planner across tested environments.
- Performance gains reach up to 48 percent over learning-based baselines, with larger improvements in complex scenes.
- Zero-shot deployment succeeds in real-world navigation tasks without further training or human assistance.
- Graph sparsification keeps computation tractable even as environments grow larger.
- The same trained policy works across both simulated and physical settings without domain-specific adjustments.
Where Pith is reading between the lines
- Similar memory-augmented graph representations could reduce data requirements for other robotic skills that involve long-horizon exploration.
- The approach points to a general pattern where sparse structured inputs help reinforcement learners generalize across the simulation-reality boundary more reliably than dense image or occupancy inputs alone.
- If the memory mechanism scales, it may support deployment in progressively larger or more cluttered spaces where pure reactive policies tend to fail.
Load-bearing premise
That the visibility graph plus contextual memory learned from simulated images will continue to produce correct navigation actions on physical robots despite real sensor noise and dynamics.
What would settle it
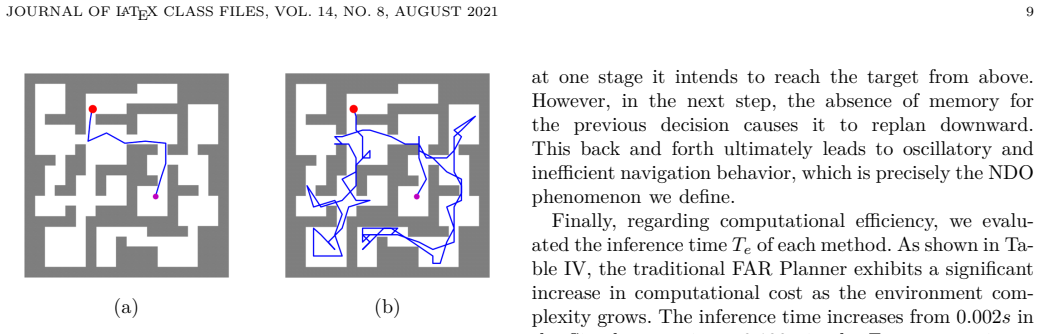
A physical robot trial in which the trained policy produces repeated collisions or entrapment in local minima when sensor readings differ from the simulated visibility graphs used in training.
Figures







read the original abstract
Autonomous navigation in unknown environments requires a robot to efficiently reach a predefined goal while exploring without prior maps. Although progress has been made in this area, most existing works still rely on traditional planning methods with hand-crafted rules, while learning-based methods often suffer from limited environmental memory and challenges in simulation-to-real (sim-to-real) transfer. To overcome these limitations, we propose a Contextual-memory Oriented Reinforcement-learning (CORE) planner for robot navigation in unknown environments. The proposed CORE planner effectively combines the core advantages of traditional and learning-based methods. Specifically, our method uses a sparse visibility graph for structured environment representation, reducing the computational overhead of dense grid maps, and employs a Transformer network to achieve a holistic environmental understanding, thereby significantly improving navigation efficiency. Moreover, we introduce a visibility graph-based graph sparsification method and a contextual memory mechanism, which alleviates local optima and enhances computational performance in large-scale scenes. Finally, our approach achieves zero-shot sim-to-real transfer after training solely on image-based environments, requiring no fine-tuning. Experimental results show that CORE Planner consistently outperforms state-of-the-art methods, including the traditional FAR Planner and all learning-based baselines, across representative environments, reducing travel distance by 13\% over traditional FAR Planner and by up to 48\% relative to learning-based baselines, with larger gains observed in more complex environments. In real-world scenarios, CORE successfully navigates without human intervention, showcasing zero-shot sim-to-real transfer. Code is available at https://github.com/BBD00/core_planner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CORE Planner, a hybrid approach combining sparse visibility graphs with Transformer-based contextual memory in a reinforcement learning framework for autonomous robot navigation in unknown environments. It claims superior performance over traditional (FAR Planner) and learning-based methods, with 13% and up to 48% reductions in travel distance respectively, and demonstrates zero-shot sim-to-real transfer without fine-tuning, supported by real-world experiments.
Significance. If the performance improvements and zero-shot transfer hold under scrutiny, this work could advance the field by effectively merging the strengths of structured planning and learning-based methods, potentially improving efficiency in large-scale scenes and reducing reliance on fine-tuning for real-world deployment. The provision of code enhances the potential for reproducibility and further research.
major comments (3)
- [Abstract] Abstract: The central claim of zero-shot sim-to-real transfer after training solely on image-based environments is load-bearing, yet the manuscript supplies no quantitative characterization of the sim-to-real image gap, no noise model, and no ablation on visibility-graph quality under perturbation, leaving the robustness of the sparse graph extraction unverified.
- [§5 (Experiments)] §5 (Experiments) and real-world results paragraph: The reported 13% distance reduction over FAR Planner and up to 48% over learning baselines, plus successful real-world runs without intervention, are presented without details on trial counts, variance, statistical tests, or controls for sensor noise/calibration, undermining assessment of whether the gains generalize beyond the evaluated setups.
- [Methods] Methods section on visibility graph sparsification and contextual memory: The claim that these mechanisms alleviate local optima and enable large-scale performance is central, but without explicit equations or pseudocode showing how the Transformer memory integrates with the graph to produce noise-invariant plans, the zero-shot assertion rests on an untested assumption.
minor comments (2)
- [Abstract] Abstract: The statement 'larger gains observed in more complex environments' lacks a definition of complexity (e.g., obstacle density or map size); adding this would improve precision.
- [Abstract] The GitHub link is provided, but the manuscript does not specify which code components correspond to the graph extraction versus the RL policy, reducing immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of the zero-shot transfer claim and the experimental rigor. We respond to each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of zero-shot sim-to-real transfer after training solely on image-based environments is load-bearing, yet the manuscript supplies no quantitative characterization of the sim-to-real image gap, no noise model, and no ablation on visibility-graph quality under perturbation, leaving the robustness of the sparse graph extraction unverified.
Authors: We agree that additional quantitative support would strengthen the zero-shot claim. The manuscript demonstrates successful real-world navigation without fine-tuning, but does not currently include explicit gap metrics or ablations. In revision we will add a characterization of the sim-to-real image differences (e.g., feature distribution statistics), a basic sensor noise model, and an ablation on visibility-graph robustness under synthetic perturbations. These additions will be placed in §5 or a new appendix subsection. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments) and real-world results paragraph: The reported 13% distance reduction over FAR Planner and up to 48% over learning baselines, plus successful real-world runs without intervention, are presented without details on trial counts, variance, statistical tests, or controls for sensor noise/calibration, undermining assessment of whether the gains generalize beyond the evaluated setups.
Authors: The reported improvements are averages over repeated trials, yet the manuscript indeed omits explicit counts, variance, and statistical tests. We will revise §5 to report the exact number of trials per environment, include standard deviations, add statistical significance tests (paired t-tests), and describe sensor calibration and noise-handling procedures used in both simulation and real-world experiments. revision: yes
-
Referee: [Methods] Methods section on visibility graph sparsification and contextual memory: The claim that these mechanisms alleviate local optima and enable large-scale performance is central, but without explicit equations or pseudocode showing how the Transformer memory integrates with the graph to produce noise-invariant plans, the zero-shot assertion rests on an untested assumption.
Authors: The methods section describes the sparsification and Transformer memory integration in prose. To improve clarity we will add formal equations for the sparsification step and the memory-conditioned policy update, together with pseudocode for the full planning loop. These additions will make explicit how the contextual memory contributes to noise-invariant plan generation. revision: yes
Circularity Check
No circularity detected; method and claims rest on independent empirical results
full rationale
The provided abstract and description outline a hybrid planner using sparse visibility graphs, Transformer contextual memory, and graph sparsification for RL-based navigation, with zero-shot sim-to-real transfer asserted via experimental outcomes (13% and 48% gains). No equations, derivations, or self-citations appear that would reduce any prediction or uniqueness claim to fitted inputs or prior author work by construction. Performance metrics are presented as measured results rather than tautological consequences of the architecture definition, and no load-bearing self-referential steps are identifiable from the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A compre- hensive review on autonomous navigation,
S. Nahavandi, R. Alizadehsani, D. Nahavandi, S. Mohamed, N. Mohajer, M. Rokonuzzaman, and I. Hossain, “A compre- hensive review on autonomous navigation,” ACM Computing Surveys, vol. 57, no. 9, pp. 1–67, 2025
2025
-
[2]
Advancements and challenges in mobile robot nav- igation: A comprehensive review of algorithms and potential for self-learning approaches,
S. Al Mahmud, A. Kamarulariffin, A. M. Ibrahim, and A. J. H. Mohideen, “Advancements and challenges in mobile robot nav- igation: A comprehensive review of algorithms and potential for self-learning approaches,” Journal of Intelligent & Robotic Systems, vol. 110, no. 3, p. 120, 2024
2024
-
[3]
Online robot naviga- tion using discrete waypoints via time-varying guidance vector fields,
J. Wang, L. Zhao, F. Liu, and K. Xia, “Online robot naviga- tion using discrete waypoints via time-varying guidance vector fields,” IEEE Transactions on Industrial Electronics, 2024
2024
-
[4]
F AR plan- ner: Fast, attemptable route planner using dynamic visibility update,
F. Yang, C. Cao, H. Zhu, J. Oh, and J. Zhang, “F AR plan- ner: Fast, attemptable route planner using dynamic visibility update,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS). IEEE, 2022, pp. 9–16
2022
-
[5]
NavRL: Learning safe flight in dynamic environments,
Z. Xu, X. Han, H. Shen, H. Jin, and K. Shimada, “NavRL: Learning safe flight in dynamic environments,” IEEE Robotics and Automation Letters, 2025
2025
-
[6]
You only plan once: A learning-based one-stage planner with guidance learning,
J. Lu, X. Zhang, H. Shen, L. Xu, and B. Tian, “You only plan once: A learning-based one-stage planner with guidance learning,” IEEE Robotics and Automation Letters, vol. 9, no. 7, pp. 6083–6090, 2024
2024
-
[7]
Goal-driven au- tonomous exploration through deep reinforcement learning,
R. Cimurs, I. H. Suh, and J. H. Lee, “Goal-driven au- tonomous exploration through deep reinforcement learning,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 730– 737, 2021
2021
-
[8]
Autonomous navigation by mobile robot with sensor fusion based on deep reinforcement learning,
Y. Ou, Y. Cai, Y. Sun, and T. Qin, “Autonomous navigation by mobile robot with sensor fusion based on deep reinforcement learning,” Sensors, vol. 24, no. 12, p. 3895, 2024
2024
-
[9]
Voronoi- based multi-robot autonomous exploration in unknown environ- ments via deep reinforcement learning,
J. Hu, H. Niu, J. Carrasco, B. Lennox, and F. Arvin, “Voronoi- based multi-robot autonomous exploration in unknown environ- ments via deep reinforcement learning,” IEEE Transactions on Vehicular Technology, vol. 69, no. 12, pp. 14 413–14 423, 2020
2020
-
[10]
Goal-guided transformer-enabled reinforcement learning for efficient au- tonomous navigation,
W. Huang, Y. Zhou, X. He, and C. Lv, “Goal-guided transformer-enabled reinforcement learning for efficient au- tonomous navigation,” IEEE Transactions on Intelligent Trans- portation Systems, vol. 25, no. 2, pp. 1832–1845, 2023
2023
-
[11]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[12]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 1877–1901
2020
-
[13]
CTSAC: Curriculum- based transformer soft actor-critic for goal-oriented robot ex- ploration,
C. Yang, S. Bi, Y. Xu, and X. Zhang, “CTSAC: Curriculum- based transformer soft actor-critic for goal-oriented robot ex- ploration,” arXiv preprint arXiv:2503.14254, 2025
-
[14]
Context-aware deep reinforcement learning for au- tonomous robotic navigation in unknown area,
J. Liang, Z. Wang, Y. Cao, J. Chiun, M. Zhang, and G. A. Sartoretti, “Context-aware deep reinforcement learning for au- tonomous robotic navigation in unknown area,” in Proc. Conf. Robot Learn. (CoRL). PMLR, 2023, pp. 1425–1436
2023
-
[15]
3D-Mem: 3D scene memory for embodied exploration and reasoning,
Y. Yang, H. Yang, J. Zhou, P. Chen, H. Zhang, Y. Du, and C. Gan, “3D-Mem: 3D scene memory for embodied exploration and reasoning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pat- tern Recognit. (CVPR), 2025, pp. 17 294–17 303
2025
-
[16]
Move to understand a 3D scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation,
Z. Zhu, X. Wang, Y. Li, Z. Zhang, X. Ma, Y. Chen, B. Jia, W. Liang, Q. Yu, Z. Deng et al., “Move to understand a 3D scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2025, pp. 8120–8132
2025
-
[17]
A note on two problems in connexion with graphs,
E. W. Dijkstra, “A note on two problems in connexion with graphs,” in Edsger Wybe Dijkstra: His Life, Work, and Legacy, 2022, pp. 287–290
2022
-
[18]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[19]
Optimal and efficient path planning for partially- known environments,
A. Stentz, “Optimal and efficient path planning for partially- known environments,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 1994, pp. 3310–3317
1994
-
[20]
Lifelong planning A*,
S. Koenig, M. Likhachev, and D. Furcy, “Lifelong planning A*,” Artificial Intelligence, vol. 155, no. 1-2, pp. 93–146, 2004
2004
-
[21]
Fast replanning for navigation in unknown terrain,
S. Koenig and M. Likhachev, “Fast replanning for navigation in unknown terrain,” IEEE Transactions on Robotics, vol. 21, no. 3, pp. 354–363, 2005
2005
-
[22]
Sampling-based algorithms for op- timal motion planning,
S. Karaman and E. Frazzoli, “Sampling-based algorithms for op- timal motion planning,” The International Journal of Robotics Research, vol. 30, no. 7, pp. 846–894, 2011
2011
-
[23]
RRT-connect: An efficient approach to single-query path planning,
J. J. Kuffner and S. M. LaValle, “RRT-connect: An efficient approach to single-query path planning,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA), vol. 2. IEEE, 2000, pp. 995– 1001
2000
-
[24]
Batch informed trees (BIT*): Sampling-based optimal planning via the heuristically guided search of implicit random geometric graphs,
J. D. Gammell, S. S. Srinivasa, and T. D. Barfoot, “Batch informed trees (BIT*): Sampling-based optimal planning via the heuristically guided search of implicit random geometric graphs,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2015, pp. 3067–3074
2015
-
[25]
Chase and track: Toward safe and smooth trajectory planning for robotic navigation in dynamic environments,
C. Wang, X. Chen, C. Li, R. Song, Y. Li, and M. Q.-H. Meng, “Chase and track: Toward safe and smooth trajectory planning for robotic navigation in dynamic environments,” IEEE Transactions on Industrial Electronics, vol. 70, no. 1, pp. 604–613, 2022
2022
-
[26]
Rapidly-exploring random trees: Progress and prospects,
S. M. LaValle and J. J. Kuffner, “Rapidly-exploring random trees: Progress and prospects,” Algorithmic and Computational Robotics, pp. 303–307, 2001
2001
-
[27]
E-Planner: An efficient path planner on a visibility graph in unknown environments,
C. Zhang, G. Wang, M. Chen, Y. Lin, K. Li, M. Wu, Z. Li, and Q. Wang, “E-Planner: An efficient path planner on a visibility graph in unknown environments,” IEEE Transactions on Instrumentation and Measurement, 2024
2024
-
[28]
FPS: Fast path planner algorithm based on sparse visibility graph and bidirectional breadth-first search,
Q. Li, F. Xie, J. Zhao, B. Xu, J. Yang, X. Liu, and H. Suo, “FPS: Fast path planner algorithm based on sparse visibility graph and bidirectional breadth-first search,” Remote Sensing, vol. 14, no. 15, p. 3720, 2022
2022
-
[29]
A review of convolutional neural network architectures and their optimizations,
S. Cong and Y. Zhou, “A review of convolutional neural network architectures and their optimizations,” Artificial Intelligence Review, vol. 56, no. 3, pp. 1905–1969, 2023
1905
-
[30]
Velma: Verbalization embodiment of LLM agents for vision and language navigation in street view,
R. Schumann, W. Zhu, W. Feng, T.-J. Fu, S. Riezler, and W. Y. Wang, “Velma: Verbalization embodiment of LLM agents for vision and language navigation in street view,” in Proc. AAAI Conf. Artif. Intell. (AAAI), vol. 38, no. 17, 2024, pp. 18 924– 18 933
2024
-
[31]
J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Explore until confident: Efficient exploration for em- bodied question answering,
A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh, “Explore until confident: Efficient exploration for em- bodied question answering,” arXiv preprint arXiv:2403.15941, 2024
-
[33]
N. Wang, W. Chen, L. Chen, H. Ji, Z. Guo, X. Zhang, and H. Sun, “Expand your SCOPE: Semantic cognition over JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 potential-based exploration for embodied visual navigation,” arXiv preprint arXiv:2511.08935, 2025
-
[34]
Pointer networks,
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015
2015
-
[35]
ARiADNE: A reinforcement learning approach using attention-based deep networks for exploration,
Y. Cao, T. Hou, Y. Wang, X. Yi, and G. Sartoretti, “ARiADNE: A reinforcement learning approach using attention-based deep networks for exploration,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2023, pp. 10 219–10 225
2023
-
[36]
Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2018, pp. 1861–1870
2018
-
[37]
Self-learning explo- ration and mapping for mobile robots via deep reinforcement learning,
F. Chen, S. Bai, T. Shan, and B. Englot, “Self-learning explo- ration and mapping for mobile robots via deep reinforcement learning,” in Proc. AIAA Scitech Forum, 2019, p. 0396
2019
-
[38]
Autonomous exploration development environment and the planning algorithms,
C. Cao, H. Zhu, F. Yang, Y. Xia, H. Choset, J. Oh, and J. Zhang, “Autonomous exploration development environment and the planning algorithms,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2022, pp. 8921–8928. Jintao Kong received the B.E. degree in Con- trol Science and Engineering from the College of Automation Engineering, Nanjing Univer- sity o...
2022
-
[39]
candidate in the College of Artificial Intelligence at Xi’an Jiao- tong University
He is currently a Ph.D. candidate in the College of Artificial Intelligence at Xi’an Jiao- tong University. His research interests include LLM-based RAG and VLM. Hongbin Sun (M’11-SM’19) received the B.S. and Ph.D. degree in electrical engineering from Xi’an Jiaotong University, Xi’an, China in 2003 and 2009, respectively. Currently he is a Professor of t...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.