Monosemanticity in Recommender Systems
Pith reviewed 2026-06-30 02:23 UTC · model grok-4.3
The pith
Matryoshka sparse autoencoders recover hierarchical interpretable factors from collaborative filtering embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
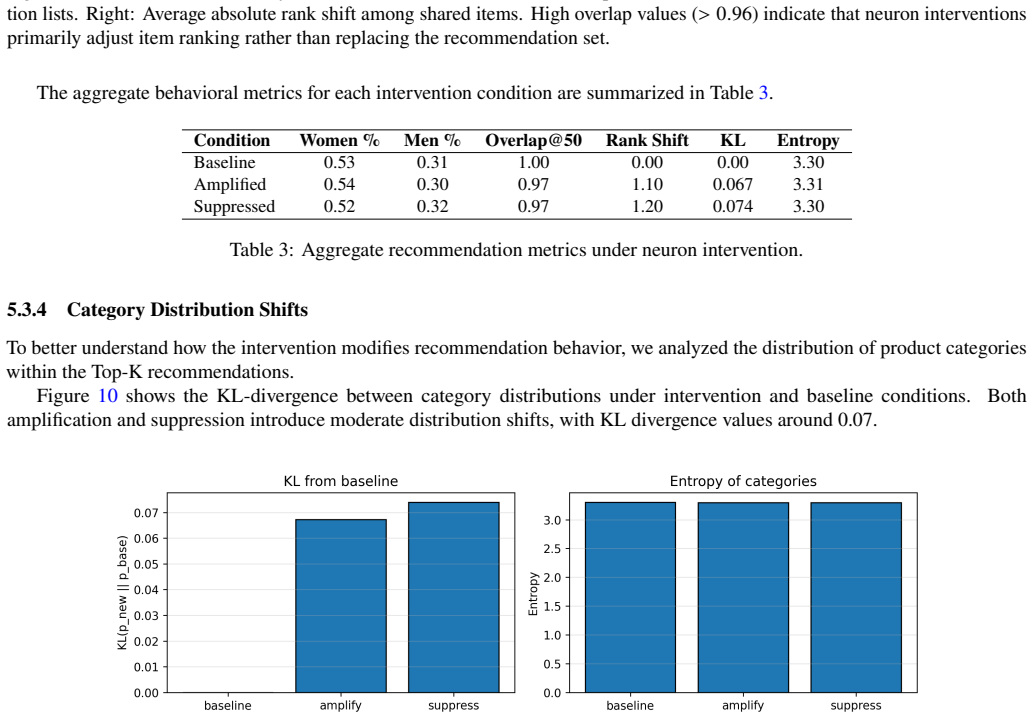
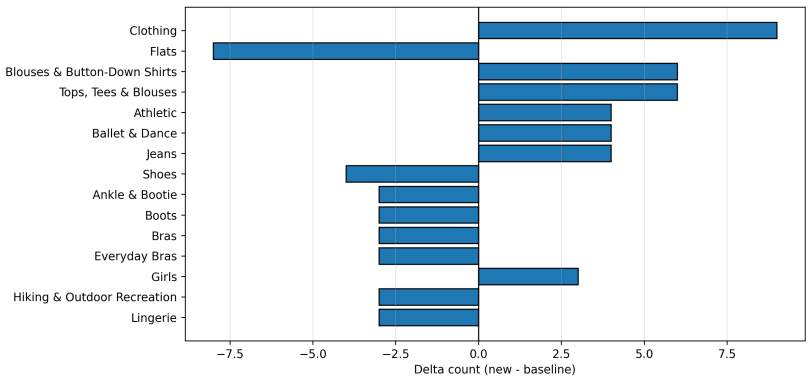
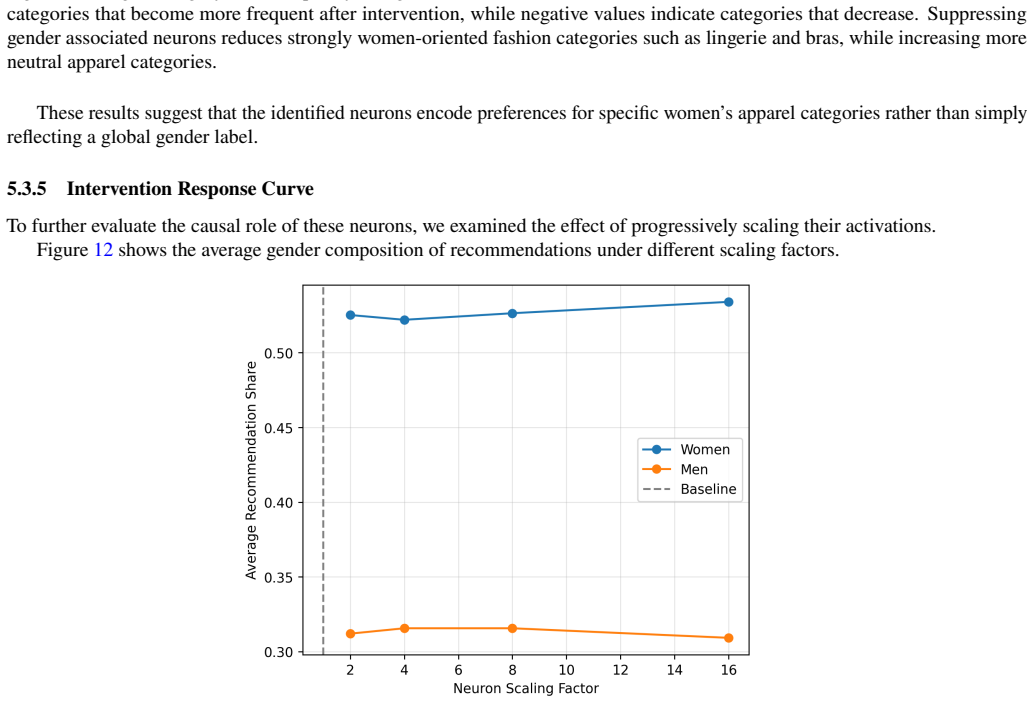
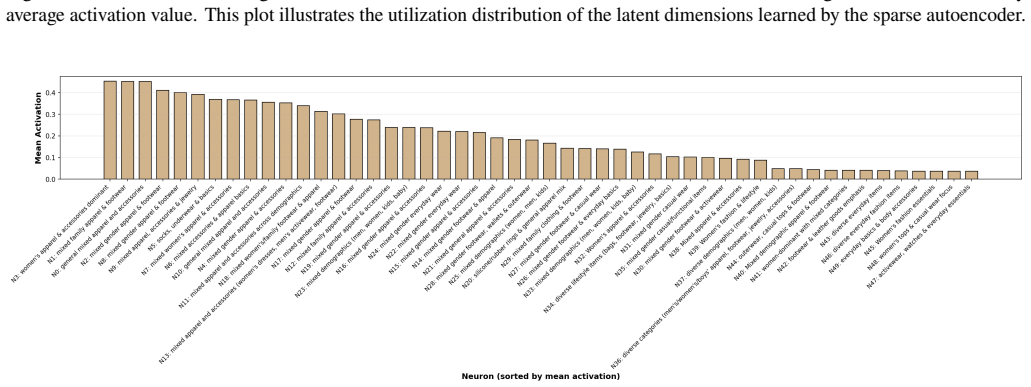
Collaborative filtering embeddings contain recoverable hierarchical structure, and Matryoshka training provides a principled mechanism for exposing interpretable latent factors in interaction-driven recommendation models, as shown by metadata alignment, LLM-generated labels, and targeted neuron interventions on an Amazon Fashion matrix factorization model.
What carries the argument
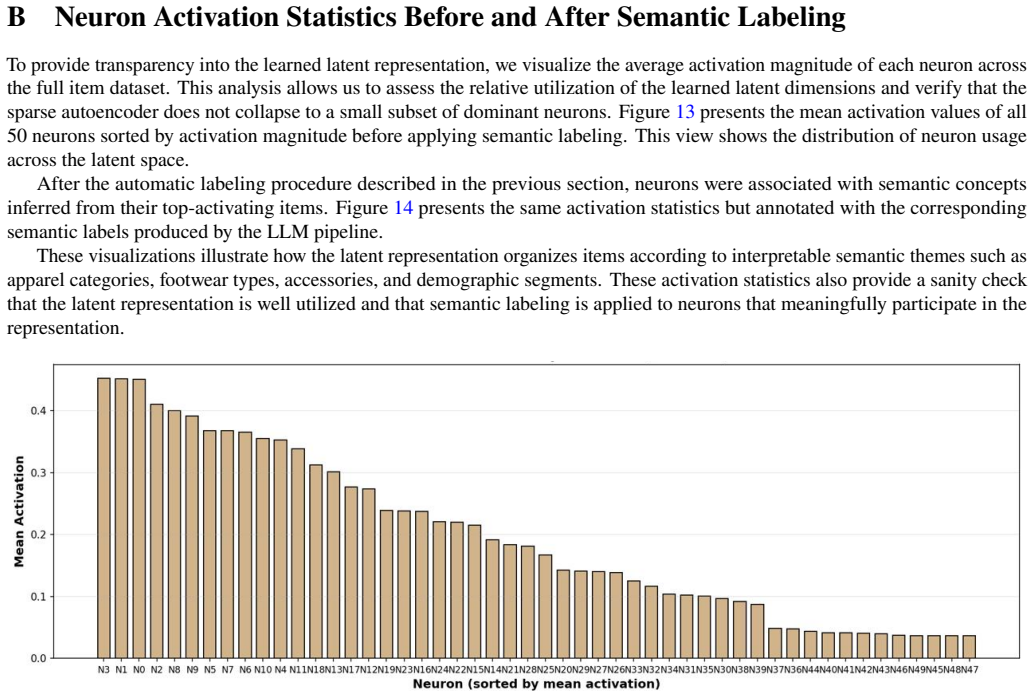
The Matryoshka Sparse Autoencoder, a hierarchical sparse autoencoder trained to produce multi-scale representations that mitigate feature splitting, absorption, and composition.
If this is right
- Existing matrix factorization models can yield interpretable factors without retraining the base recommender.
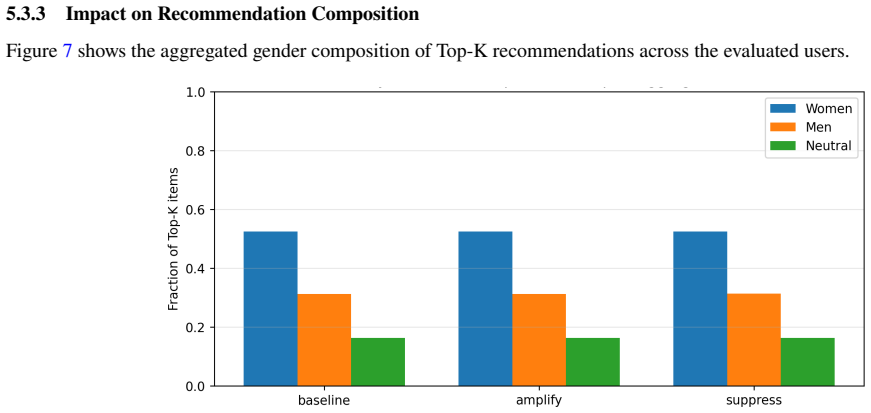
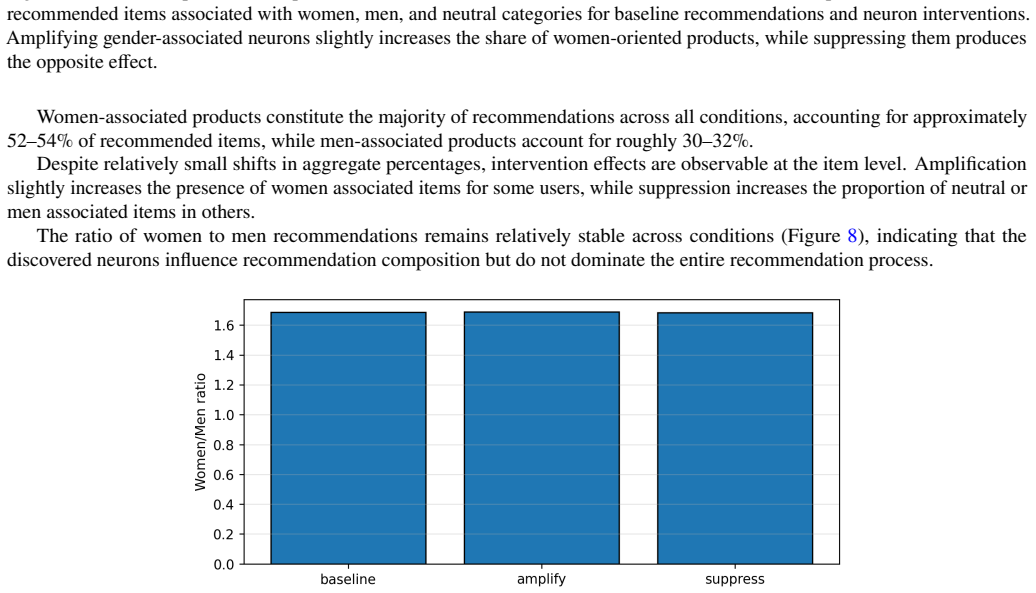
- Targeted interventions on specific latent neurons can modify recommendation behavior along metadata axes such as gender.
- Hierarchical representations support analysis at multiple levels of granularity in user-item interaction data.
- The same training approach applies to other interaction-driven models that produce dense embeddings.
Where Pith is reading between the lines
- If the hierarchical structure generalizes, the method could surface comparable factors in neural collaborative filtering or sequential recommendation models.
- The success implies that raw interaction logs already encode semantic hierarchies that standard training leaves implicit.
- Testing the same pipeline on non-fashion datasets would reveal whether the recovered factors are domain-specific or broadly recoverable.
Load-bearing premise
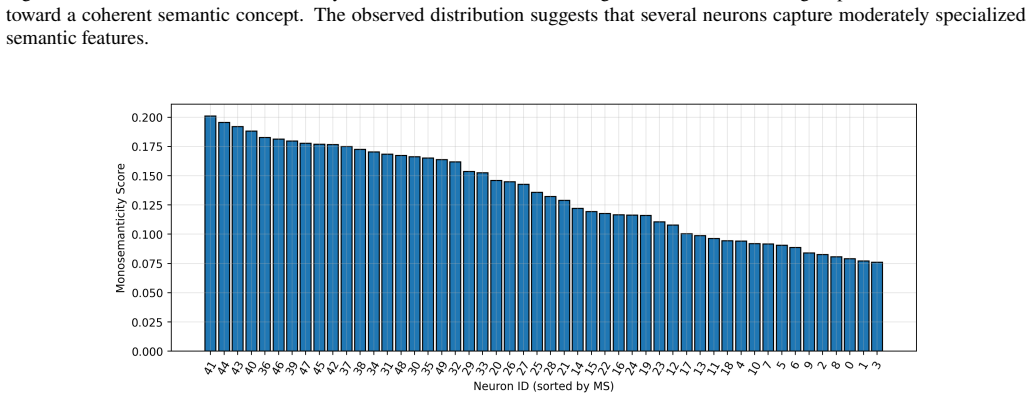
The features found by the Matryoshka Sparse Autoencoder are genuinely monosemantic and disentangled rather than still showing the splitting, absorption, or composition problems the authors note in ordinary sparse autoencoders.
What would settle it
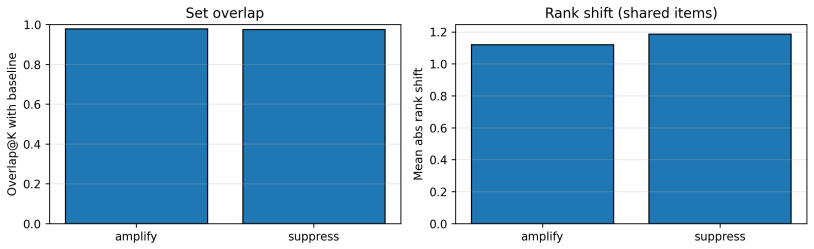
The discovered neurons show no consistent alignment with independent item metadata categories or produce no measurable change in recommendation outputs when ablated or scaled.
Figures
read the original abstract
Latent factor models such as matrix factorization are widely used in recommender systems, yet the learned embedding dimensions typically lack explicit semantic interpretation. This opacity limits transparency, explainability, and principled intervention in recommendation behavior. While sparse autoencoders (SAEs) have recently been used to extract monosemantic features from dense neural representations, standard SAEs suffer from scaling pathologies including feature splitting, feature absorption, and feature composition, which degrade interpretability as dictionary size increases. In this work, we investigate whether hierarchical sparse representations can reveal interpretable structure in collaborative filtering embeddings. We train a large-scale matrix factorization recommender system on the Amazon Fashion dataset and apply a Matryoshka Sparse Autoencoder (MSAE) to the learned embeddings. We analyze the resulting latent features through metadata alignment and LLM-generated labeling to assess semantic coherence and disentanglement. Finally, we show an intervention on a subset of gender associated latent neurons that emerged from the analysis. Our findings suggest that collaborative filtering embeddings contain recoverable hierarchical structure, and that Matryoshka training provides a principled mechanism for exposing interpretable latent factors in interaction-driven recommendation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that collaborative filtering embeddings from matrix factorization on the Amazon Fashion dataset contain recoverable hierarchical structure when analyzed with a Matryoshka Sparse Autoencoder (MSAE). The MSAE is said to mitigate scaling pathologies of standard SAEs, with features assessed for semantic coherence via metadata alignment and LLM labeling, and an intervention on gender-associated neurons is demonstrated.
Significance. If validated, this could offer a new method for achieving monosemanticity and interpretability in recommender system embeddings, enabling better transparency and targeted interventions. The use of hierarchical representations is a promising direction for addressing feature pathologies in sparse autoencoders applied to recommendation models.
major comments (2)
- Abstract: The central claims regarding the recovery of hierarchical structure and successful gender intervention lack supporting quantitative results, ablation studies, or error analysis, making it impossible to assess whether the MSAE features are genuinely monosemantic or if the intervention holds after controls for multiple testing.
- Abstract: The assumption that the discovered features are disentangled rather than exhibiting feature-splitting or composition is not empirically verified in the provided description, which is load-bearing for the claim that Matryoshka training provides a principled mechanism.
minor comments (1)
- Abstract: Consider adding specific details on the scale of the dataset, the dimensions of the embeddings, and the dictionary size of the MSAE to provide context for the experiments.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below, clarifying the support present in the manuscript while agreeing to strengthen the presentation of quantitative evidence and empirical verification where needed.
read point-by-point responses
-
Referee: Abstract: The central claims regarding the recovery of hierarchical structure and successful gender intervention lack supporting quantitative results, ablation studies, or error analysis, making it impossible to assess whether the MSAE features are genuinely monosemantic or if the intervention holds after controls for multiple testing.
Authors: The abstract summarizes results that are quantified in the body of the manuscript through metadata alignment metrics and measured changes in recommendation outputs following the gender-neuron intervention. We acknowledge, however, that the abstract itself does not report these numbers, ablations, or multiple-testing corrections, which limits immediate assessment. We will revise the abstract to include key quantitative highlights and add explicit ablation studies plus error analysis (including controls) to the experimental section. revision: yes
-
Referee: Abstract: The assumption that the discovered features are disentangled rather than exhibiting feature-splitting or composition is not empirically verified in the provided description, which is load-bearing for the claim that Matryoshka training provides a principled mechanism.
Authors: The manuscript evaluates semantic coherence via metadata alignment and LLM labeling to argue for improved disentanglement relative to standard SAEs. We agree that direct empirical verification of reduced feature splitting or composition (e.g., via activation correlation or dictionary overlap metrics) is not detailed in the abstract and would strengthen the mechanistic claim. We will add these targeted measurements and comparisons in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical pipeline consisting of matrix factorization training on the Amazon Fashion dataset, application of a Matryoshka Sparse Autoencoder to the resulting embeddings, and post-hoc analysis of features via metadata alignment and LLM labeling, followed by a targeted intervention experiment. No mathematical derivations, predictions, or first-principles results are claimed that reduce to fitted parameters or self-citations by construction. The central findings rest on external evaluation criteria (metadata coherence, LLM labels, intervention outcomes) rather than internal self-consistency loops. Any references to prior SAE or Matryoshka work serve as methodological background and are not load-bearing for a tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rokach, and B
Ricci, F., L. Rokach, and B. Shapira. ”Introduction to Recommender Systems Handbook. Springer.” (2011): 1-35
2011
-
[2]
”Matrix factorization techniques for recommender systems.” Computer 42.8 (2009): 30-37
Koren, Yehuda, Robert Bell, and Chris Volinsky. ”Matrix factorization techniques for recommender systems.” Computer 42.8 (2009): 30-37
2009
-
[3]
”Neural collaborative filtering.” Proceedings of the 26th international conference on world wide web
He, Xiangnan, et al. ”Neural collaborative filtering.” Proceedings of the 26th international conference on world wide web. 2017
2017
-
[4]
”Modeling user rating profiles for collaborative filtering.” Advances in neural information processing systems 16 (2003)
Marlin, Benjamin M. ”Modeling user rating profiles for collaborative filtering.” Advances in neural information processing systems 16 (2003)
2003
-
[5]
”Explainable recommendation: A survey and new perspectives.” Foundations and Trends® in Information Retrieval 14.1 (2020): 1-101
Zhang, Yongfeng, and Xu Chen. ”Explainable recommendation: A survey and new perspectives.” Foundations and Trends® in Information Retrieval 14.1 (2020): 1-101
2020
-
[6]
”Explainable matrix factorization for collaborative filtering.” Proceedings of the 25th International Conference Companion on World Wide Web
Abdollahi, Behnoush, and Olfa Nasraoui. ”Explainable matrix factorization for collaborative filtering.” Proceedings of the 25th International Conference Companion on World Wide Web. 2016
2016
-
[7]
”NAIS: Neural attentive item similarity model for recommendation.” IEEE Transactions on Knowledge and Data Engineering 30.12 (2018): 2354-2366
He, Xiangnan, et al. ”NAIS: Neural attentive item similarity model for recommendation.” IEEE Transactions on Knowledge and Data Engineering 30.12 (2018): 2354-2366
2018
-
[8]
Multisided Fairness for Recommendation
Burke, Robin. ”Multisided fairness for recommendation.” arXiv preprint arXiv:1707.00093 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
”Sparse autoencoder.” CS294A Lecture notes 72.2011 (2011): 1-19
Ng, Andrew. ”Sparse autoencoder.” CS294A Lecture notes 72.2011 (2011): 1-19
2011
-
[10]
”A is for absorption: Studying feature splitting and absorption in sparse autoencoders.” Advances in Neural Information Processing Systems 38 (2026): 82318-82355
Chanin, David, et al. ”A is for absorption: Studying feature splitting and absorption in sparse autoencoders.” Advances in Neural Information Processing Systems 38 (2026): 82318-82355
2026
-
[11]
Bussmann, Bart, et al. ”Learning multi-level features with matryoshka sparse autoencoders.” arXiv preprint arXiv:2503.17547 (2025)
-
[12]
Towards A Rigorous Science of Interpretable Machine Learning
Doshi-Velez, Finale, and Been Kim. ”Towards a rigorous science of interpretable machine learning.” arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
”Zoom in: An introduction to circuits.” Distill 5.3 (2020): e00024-001
Olah, Chris, et al. ”Zoom in: An introduction to circuits.” Distill 5.3 (2020): e00024-001
2020
-
[14]
Templeton, et al., ”Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”, Transformer Circuits Thread, 2024
2024
-
[15]
”Sparse autoencoders learn monosemantic features in vision-language models.” Advances in Neural Information Processing Systems 38 (2026): 95706-95742
Pach, Mateusz, et al. ”Sparse autoencoders learn monosemantic features in vision-language models.” Advances in Neural Information Processing Systems 38 (2026): 95706-95742
2026
-
[16]
Women ’s shoes
Arviv, Dor, et al. ”Extracting Interaction-Aware Monosemantic Concepts in Recommender Systems.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 40. No. 17. 2026: 14450–14458. 15 A Automatic Neuron Labeling with Claude Opus 4.5 To scale qualitative interpretability analysis, we employed an automatic neuron-labeling pipeline using Claude...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.