Semantic insurance pricing with large language models
Pith reviewed 2026-06-30 02:10 UTC · model grok-4.3
The pith
Embeddings from a pre-trained large language model can replace hand-crafted features as inputs to a standard actuarial pricing model for Poisson claim-frequency regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
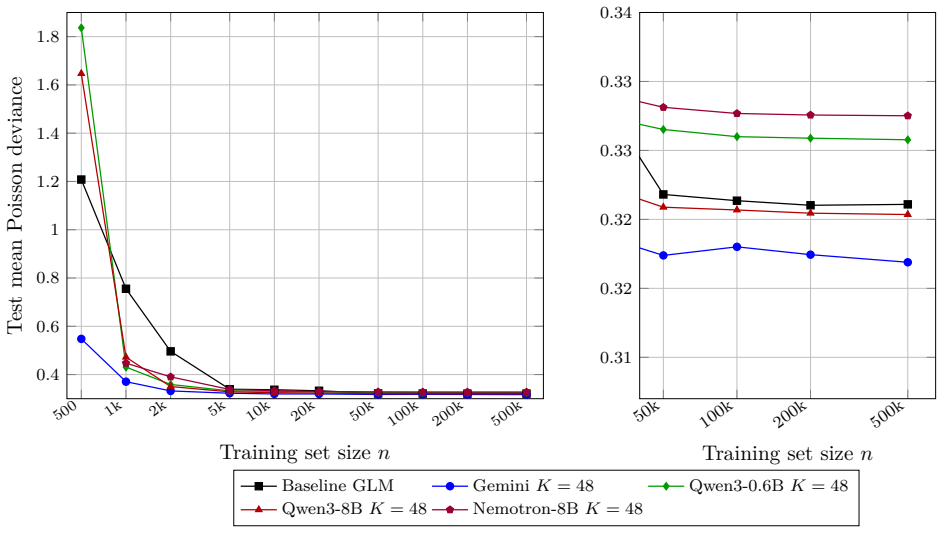
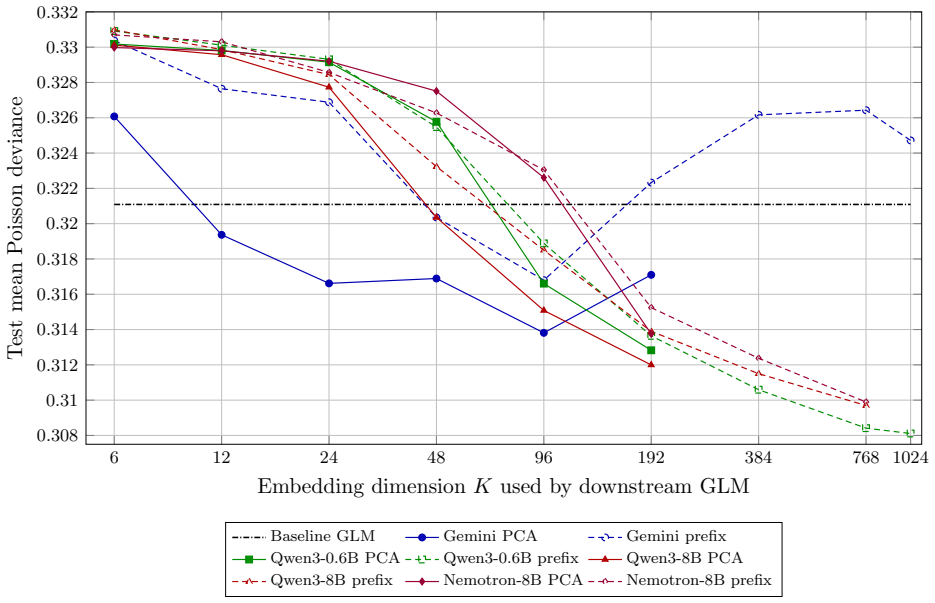
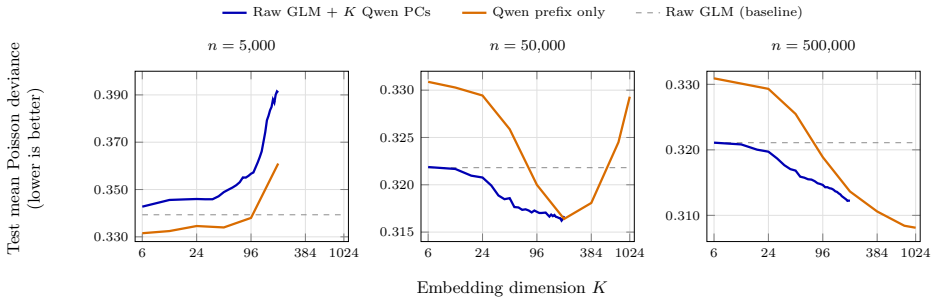
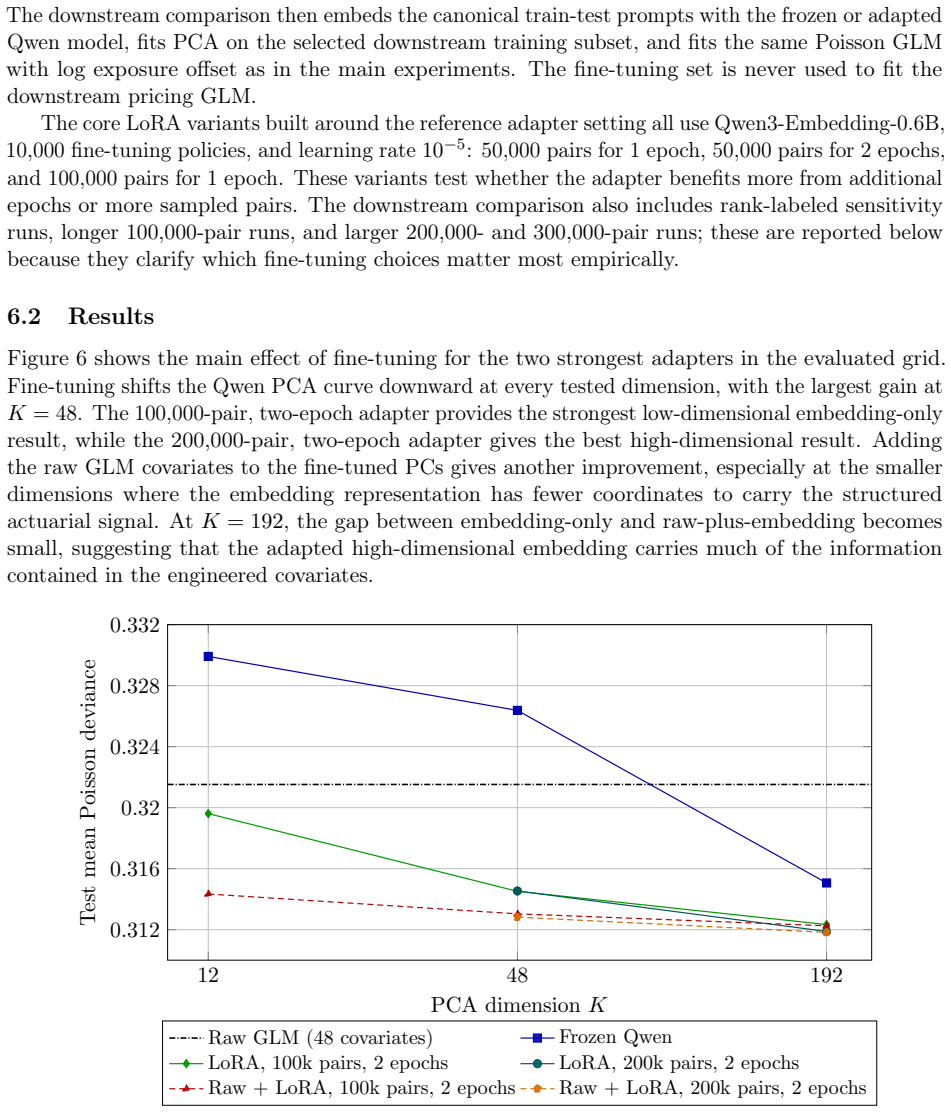
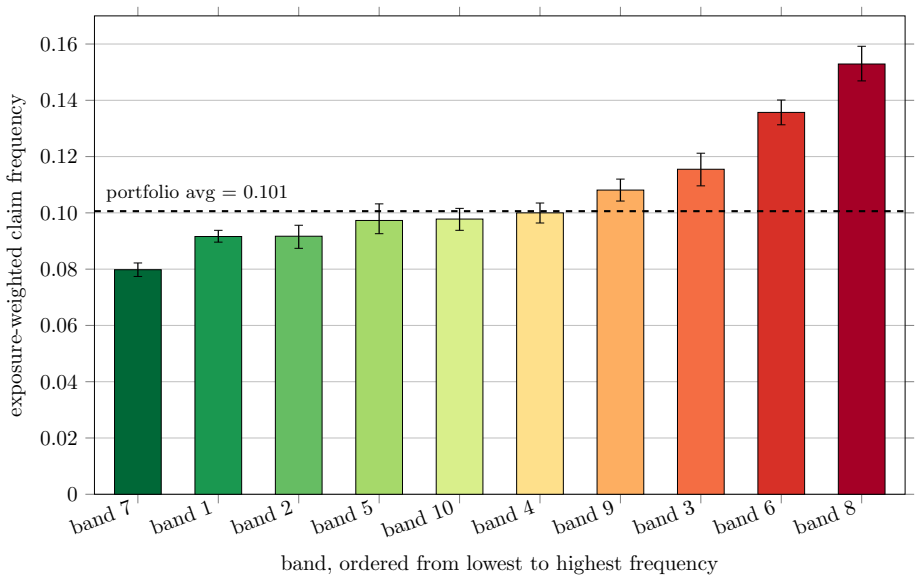
Embeddings from a pre-trained large language model, computed from a natural-language description of each policyholder, can replace hand-crafted features as inputs to a standard actuarial pricing model. Using French motor third-party liability data the embedding-based model outperforms the generalized linear model, especially when data are scarce, whereas at larger sample sizes the comparison is model- and dimension-dependent. Insurance-specific fine-tuning further improves the embeddings, and a prompt-sensitivity diagnostic shows that the pipeline reacts to any appended out-of-template field, making controlled prompts a governance requirement.
What carries the argument
Pre-trained language-model embeddings treated as fixed covariates inside a generalized linear model for Poisson claim-frequency regression.
Load-bearing premise
The supplied natural-language policy descriptions already contain the risk-relevant information that the embeddings extract without systematic bias or loss of actuarial signal.
What would settle it
A new motor-insurance dataset in which the embedding-based generalized linear model shows no improvement over the hand-crafted-feature version on small training samples would falsify the performance claim.
Figures


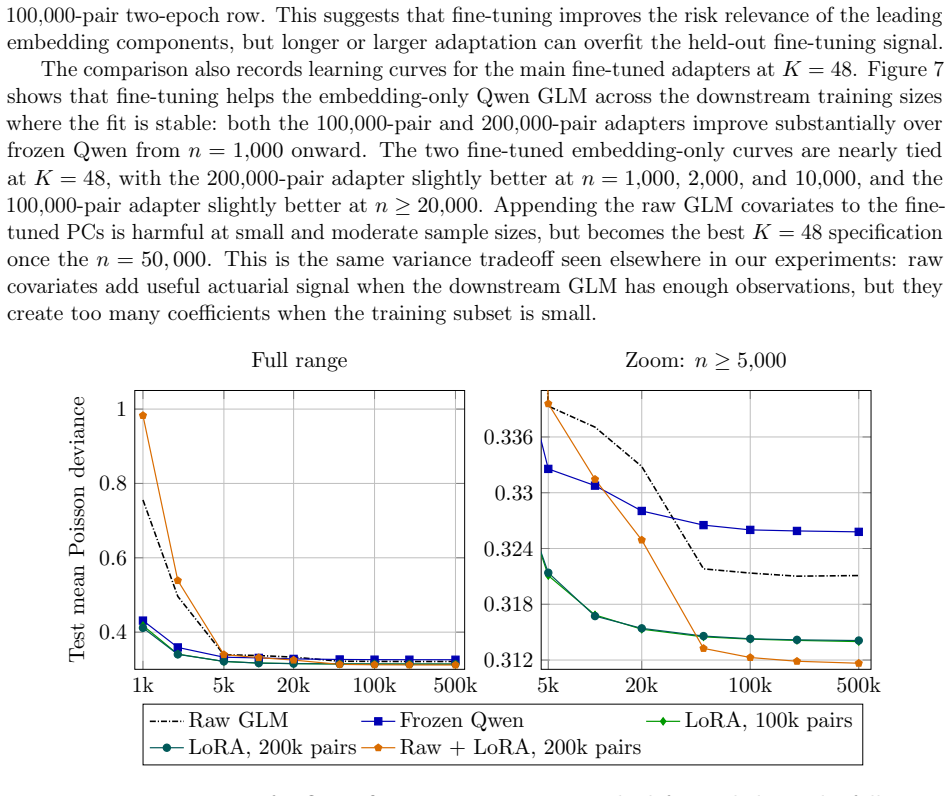
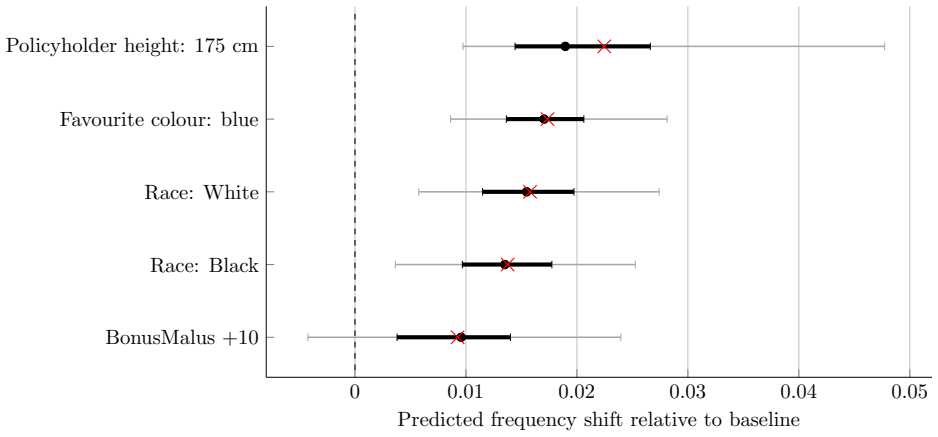
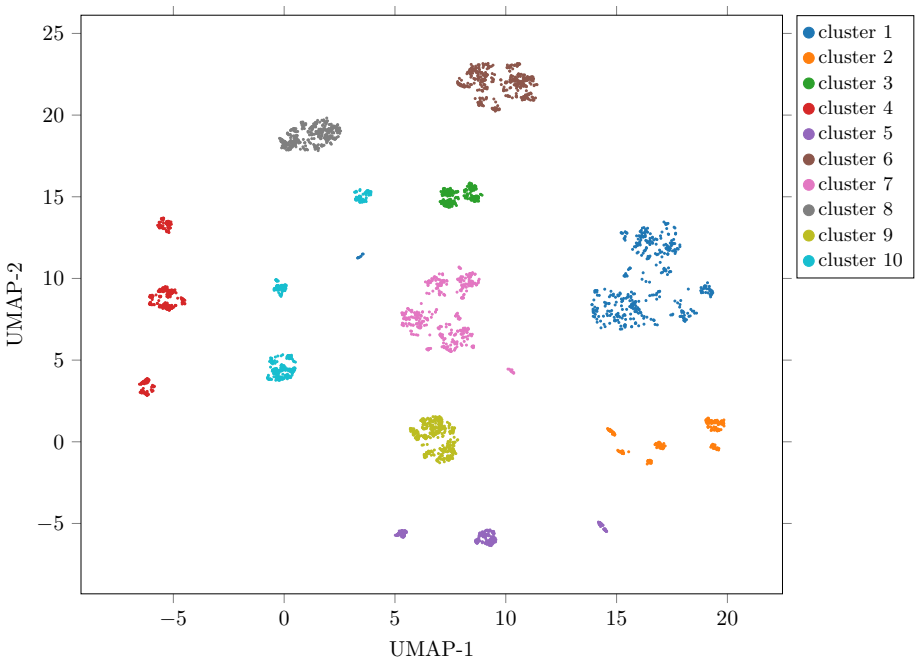
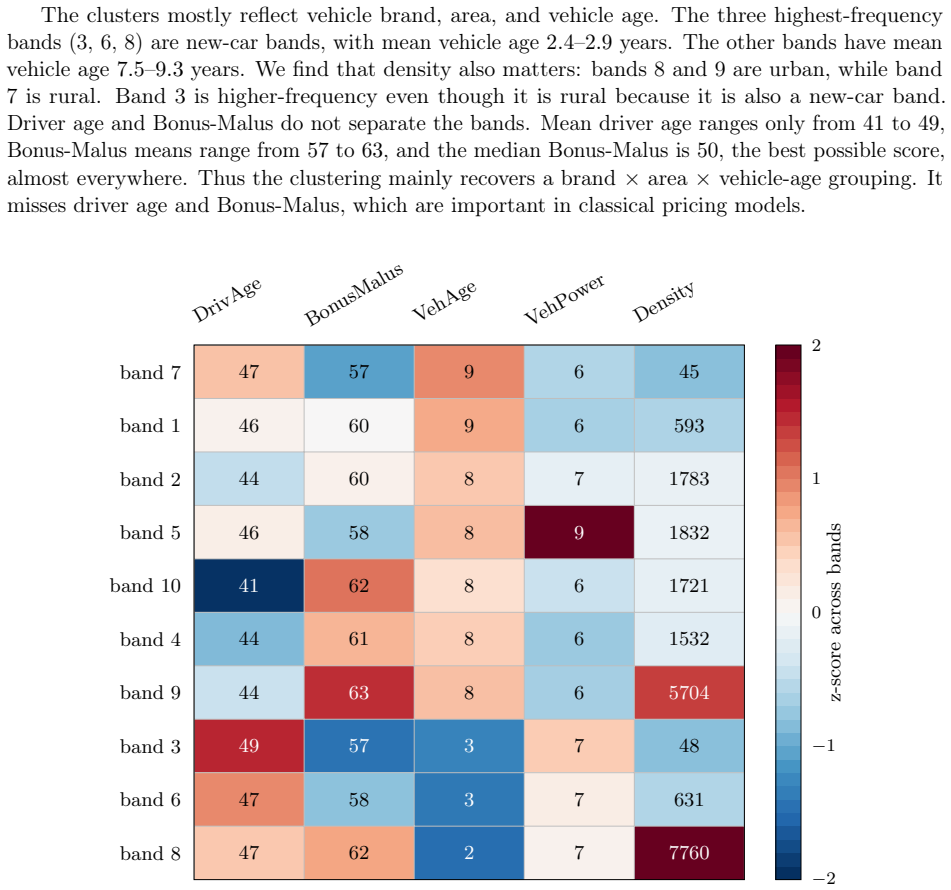




read the original abstract
Classical actuarial pricing models, such as the generalized linear model, are valued for transparency and ease of governance, but they use interactions among risk factors only when these are supplied through explicit feature engineering. We study whether embeddings from a pre-trained large language model, computed from a natural-language description of each policyholder, can replace hand-crafted features as inputs to a standard actuarial pricing model, taking Poisson claim-frequency regression as the main example. The language model is used only to construct deterministic embedding covariates; pricing is performed by a standard generalized linear model. Using French motor third-party liability data, the embedding-based model outperforms the generalized linear model, especially when data are scarce, whereas at larger sample sizes the comparison is model- and dimension-dependent. Insurance-specific fine-tuning further improves the embeddings, and a prompt-sensitivity diagnostic shows that the pipeline reacts to any appended out-of-template field, making controlled prompts a governance requirement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes replacing hand-crafted features with deterministic embeddings from a pre-trained LLM applied to natural-language policyholder descriptions as covariates in a standard GLM for Poisson claim-frequency regression. On French motor third-party liability data, the embedding-based GLM outperforms the baseline GLM (especially in low-data regimes), with further gains from insurance-specific fine-tuning; a prompt-sensitivity check indicates the need for controlled prompts.
Significance. If the performance gains are robust and attributable to extractable actuarial signal in the text, the approach offers a way to incorporate unstructured data into transparent, governance-friendly pricing models without abandoning GLMs. The deterministic embedding step and retention of the GLM are strengths that keep the method within existing actuarial workflows. The low-data regime result, if confirmed with proper controls, would be particularly relevant for new lines or small portfolios.
major comments (2)
- [Abstract, §3] Abstract and §3 (data description): the central claim that embeddings 'can replace hand-crafted features' and outperform them rests on the assumption that the natural-language descriptions encode risk-relevant information not already captured by the baseline covariates. The manuscript provides no details on whether these descriptions are free-form applicant text, templated conversions of the structured fields, or richer external text; without this, outperformance cannot be unambiguously attributed to semantic extraction rather than implicit non-linear feature engineering or data leakage.
- [§4] §4 (experimental results): the abstract states outperformance 'especially when data are scarce' and 'model- and dimension-dependent' at larger sizes, yet the provided text contains no quantitative metrics, confidence intervals, data-split details, or statistical significance tests. This absence makes the load-bearing empirical claim unverifiable from the given information and requires explicit tables or figures with effect sizes.
minor comments (2)
- [Abstract] Abstract: the claim of outperformance should be accompanied by at least one quantitative metric (e.g., relative improvement in Poisson deviance or log-likelihood) even in the abstract.
- [§2] Notation: clarify whether the GLM is fit on the raw embeddings or on a reduced-dimensional projection, and state the exact dimension choice and any regularization.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for clarification and strengthening of the empirical presentation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (data description): the central claim that embeddings 'can replace hand-crafted features' and outperform them rests on the assumption that the natural-language descriptions encode risk-relevant information not already captured by the baseline covariates. The manuscript provides no details on whether these descriptions are free-form applicant text, templated conversions of the structured fields, or richer external text; without this, outperformance cannot be unambiguously attributed to semantic extraction rather than implicit non-linear feature engineering or data leakage.
Authors: We agree that the source and construction of the natural-language descriptions must be specified to support attribution of performance gains to semantic content rather than leakage or implicit engineering. In the revised manuscript we will expand the data description in §3 to state explicitly how the descriptions are obtained (free-form applicant text versus any templating or conversion from structured fields) and will add a short discussion of how this affects interpretation of the results. revision: yes
-
Referee: [§4] §4 (experimental results): the abstract states outperformance 'especially when data are scarce' and 'model- and dimension-dependent' at larger sizes, yet the provided text contains no quantitative metrics, confidence intervals, data-split details, or statistical significance tests. This absence makes the load-bearing empirical claim unverifiable from the given information and requires explicit tables or figures with effect sizes.
Authors: We accept that the current manuscript version does not present the quantitative results with sufficient detail for independent verification. In the revision we will add tables and figures in §4 that report the relevant performance metrics together with confidence intervals, explicit data-split and cross-validation procedures, and statistical significance tests comparing the embedding-based and baseline GLMs. revision: yes
Circularity Check
No circularity: direct empirical comparison of covariate sets in standard GLM
full rationale
The paper's central claim is an empirical performance comparison: LLM embeddings computed from natural-language policy descriptions are substituted as covariates into an otherwise standard Poisson GLM and evaluated against a baseline GLM using hand-crafted features on French motor data. No equations, uniqueness theorems, or predictions are derived; the pipeline is a deterministic embedding step followed by off-the-shelf GLM fitting and out-of-sample evaluation. No self-citations are load-bearing for the result, no fitted parameters are relabeled as predictions, and no ansatz is smuggled via prior work. The derivation chain is self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
British Actuarial Journal , volume =
Balona, Caesar , year =. British Actuarial Journal , volume =. doi:10.1017/S1357321724000102 , urldate =
-
[2]
Annals of Actuarial Science , volume =
Richman, Ronald , year =. Annals of Actuarial Science , volume =. doi:10.1017/S1748499520000238 , urldate =
-
[3]
Annals of Actuarial Science , volume =
Richman, Ronald , year =. Annals of Actuarial Science , volume =. doi:10.1017/S174849952000024X , urldate =
-
[4]
Non-Life Insurance Risk Classification Using Categorical Embedding , author =. 2023 , journal =. doi:10.1080/10920277.2022.2123361 , urldate =
-
[5]
Enhancing Actuarial Non-Life Pricing Models via Transformers , author =. 2024 , month = dec, journal =. doi:10.1007/s13385-024-00388-2 , urldate =
-
[6]
Machine Learning in. 2021 , month = jan, journal =. doi:10.3390/risks9010004 , urldate =
-
[7]
arXiv preprint arXiv:2102.05784 , year =
Rethinking Representations in. arXiv preprint arXiv:2102.05784 , year =
-
[8]
High-cardinality categorical covariates in network regressions , author =. 2024 , journal =. doi:10.1007/s42081-024-00243-4 , urldate =
-
[9]
Avanzi, Benjamin and Taylor, Greg and Wang, Melantha and Wong, Bernard , year =. Machine. ASTIN Bulletin: The Journal of the IAA , volume =. doi:10.1017/asb.2024.7 , urldate =
-
[10]
Lee, Jinhyuk and Dai, Zhuyun and Ren, Xiaoqi and Chen, Blair and Cer, Daniel and Cole, Jeremy R. and Hui, Kai and Boratko, Michael and Kapadia, Rajvi and Ding, Wen and Luan, Yi and Duddu, Sai Meher Karthik and Abrego, Gustavo Hernandez and Shi, Weiqiang and Gupta, Nithi and Kusupati, Aditya and Jain, Prateek and Jonnalagadda, Siddhartha Reddy and Chang, M...
-
[11]
Gemini Embedding: Generalizable Embeddings from Gemini
Lee, Jinhyuk and Chen, Feiyang and Dua, Sahil and Cer, Daniel and Shanbhogue, Madhuri and Naim, Iftekhar and. Gemini Embedding: Generalizable Embeddings from. arXiv preprint arXiv:2503.07891 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking through Foundation Models , author =. arXiv preprint arXiv:2506.05176 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Text and Code Embeddings by Contrastive Pre-Training
Text and Code Embeddings by Contrastive Pre-Training , author =. arXiv preprint arXiv:2201.10005 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Attention Is All You Need , booktitle =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention Is All You Need , booktitle =
-
[15]
Geographic Ratemaking with Spatial Embeddings , author =. ASTIN Bulletin , volume =. doi:10.1017/asb.2021.25 , urldate =
-
[16]
ASTIN Bulletin: The Journal of the IAA , volume =
A Representation-Learning Approach for Insurance Pricing with Images , author =. ASTIN Bulletin: The Journal of the IAA , volume =. doi:10.1017/asb.2024.9 , urldate =
-
[17]
arXiv preprint arXiv:2511.17954 , doi =
A Multi-View Contrastive Learning Framework for Spatial Embeddings in Risk Modelling , author =. arXiv preprint arXiv:2511.17954 , doi =
-
[18]
North American Actuarial Journal , doi =
Neural Networks for Insurance Pricing with Frequency and Severity Data: A Benchmark Study from Data Preprocessing to Technical Tariff , author =. North American Actuarial Journal , doi =
-
[19]
Actuarial Applications of Word Embedding Models , author =. ASTIN Bulletin , volume =. doi:10.1017/asb.2019.28 , urldate =
-
[20]
doi:10.1016/j.insmatheco.2022.07.013 , urldate =
Xu, Shuzhe and Zhang, Chuanlong and Hong, Don , year = 2022, month = nov, journal =. doi:10.1016/j.insmatheco.2022.07.013 , urldate =
-
[21]
Mining Actuarial Risk Predictors in Accident Descriptions Using Recurrent Neural Networks , author =. 2021 , journal =. doi:10.3390/risks9010007 , urldate =
-
[22]
Dong, Panyi and Quan, Zhiyu , journal =
-
[23]
Lee, Chankyu and Roy, Rajarshi and Xu, Mengyao and Raiman, Jonathan and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei , journal =
-
[24]
Babakhin, Yauhen and Osmulski, Radek and Ak, Ronay and Moreira, Gabriel and Xu, Mengyao and Schifferer, Benedikt and Liu, Bo and Oldridge, Even , journal =. Llama-
-
[25]
Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin...
-
[26]
The use of autoencoders for training neural networks with mixed categorical and numerical features , author =. 2023 , journal =. doi:10.1017/asb.2023.15 , urldate =
-
[27]
Text Mining in Insurance: From Unstructured Data to Meaning , shorttitle =
Zappa, Diego and Borrelli, Mattia and Clemente, Gian Paolo and Savelli, Nino , year = 2021, journal =. Text Mining in Insurance: From Unstructured Data to Meaning , shorttitle =
2021
-
[28]
Annals of Actuarial Science , volume =
On Clustering Levels of a Hierarchical Categorical Risk Factor , author =. Annals of Actuarial Science , volume =. doi:10.1017/S1748499523000283 , urldate =
-
[29]
Advanced Applications of Generative
Hatzesberger, Simon and Nonneman, Iris , journal =. Advanced Applications of Generative
-
[30]
arXiv preprint arXiv:2206.02014 , year =
Actuarial Applications of Natural Language Processing Using Transformers , author =. arXiv preprint arXiv:2206.02014 , year =
-
[31]
Operationalizing
Balona, Caesar , year = 2025, pages =. Operationalizing
2025
-
[32]
Hegselmann, Stefan and Buendia, Alejandro and Lang, Hunter and Agrawal, Monica and Jiang, Xiaoyi and Sontag, David , booktitle=. Tab. 2023 , publisher=
2023
-
[33]
Dinh, Tuan and Zeng, Yuchen and Zhang, Ruisu and Lin, Ziqian and Gira, Michael and Rajput, Shashank and Sohn, Jy-yong and Papailiopoulos, Dimitris and Lee, Kangwook , booktitle=
-
[34]
Large Language Models (
Fang, Xi and Xu, Weijie and Tan, Fiona Anting and Zhang, Jiani and Hu, Ziqing and Qi, Yanjun and Nickleach, Scott and Sber, Diego and Gorbachev, Artem and Hou, Ellie , journal=. Large Language Models (
-
[35]
, title =
Ono, Kyoka and Lee, Simon A. , title =. Proceedings of the 41st International Conference on Machine Learning,. 2024 , eprint =
2024
-
[36]
Koloski, Boshko and Perdih, Timen and Pollak, Senja , journal=
- [37]
-
[38]
Enriching Tabular Data with Contextual
Kasneci, Enkelejda and Kasneci, Gjergji , journal=. Enriching Tabular Data with Contextual
-
[39]
Latte: Transferring
Shi, Han and Gao, Jiahui and Xu, Hang and Liang, Xiaodan and Li, Zhenguo , journal=. Latte: Transferring
-
[40]
arXiv preprint arXiv:2406.12031 , year=
Large Scale Transfer Learning for Tabular Data via Language Modeling , author=. arXiv preprint arXiv:2406.12031 , year=
-
[41]
arXiv preprint arXiv:2602.15844 , year=
Language Model Representations for Efficient Few-Shot Tabular Classification , author=. arXiv preprint arXiv:2602.15844 , year=
-
[42]
Wang, Ruijie and Wang, Yumo and Li, Ondrej , journal=. Uni
-
[43]
arXiv preprint arXiv:2310.07338 , year=
From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models , author=. arXiv preprint arXiv:2310.07338 , year=
-
[44]
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science , author=. arXiv preprint arXiv:2403.20208 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Haque, Radiah and Goh, Hui-Ngo and Ting, Choo-Yee and Quek, Albert and Hasan, M. D. Rakibul , title =. Computers and Education: Artificial Intelligence , year =
-
[46]
Large Language Models for Automated Data Science: Introducing
Hollmann, Noah and M. Large Language Models for Automated Data Science: Introducing. NeurIPS 2023 Workshop on Synthetic Data Generation with Generative AI , year=
2023
-
[47]
Proceedings of the 41st International Conference on Machine Learning , year=
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning , author=. Proceedings of the 41st International Conference on Machine Learning , year=
-
[48]
, title =
Abhyankar, Nikhil and Shojaee, Parshin and Reddy, Chandan K. , title =. 2025 , eprint =
2025
-
[49]
Nature , volume=
Accurate Predictions on Small Data with a Tabular Foundation Model , author=. Nature , volume=. 2025 , publisher=
2025
-
[50]
Ma, Junwei and Nie, Valentin Thomas and Ri, Taro and Dyer, Chris , journal=. Tab
-
[51]
Huang, Xin and Khetan, Ashish and Cella, Milan and Dhir, Sarthak , booktitle=. Tab
-
[52]
Advances in Neural Information Processing Systems , volume=
Revisiting Deep Learning Models for Tabular Data , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
Why Do Tree-Based Models Still Outperform Deep Learning on Typical Tabular Data? , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Wang, Zifeng and Sun, Jimeng , journal=. Trans
-
[55]
Kim, Myung Jun and Feuerriegel, Stefan and Hatt, Tobias , journal=
-
[56]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle=. Sentence-
-
[57]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
One Embedder, Any Task: Instruction-Finetuned Text Embeddings , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[59]
Advances in Neural Information Processing Systems , volume=
Matryoshka Representation Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
, journal=
Huang, Xiang and Peng, Hao and Zou, Dongcheng and Liu, Zhiwei and Li, Jianxin and Liu, Kay and Wu, Jia and Su, Jianlin and Yu, Philip S. , journal=. Co
-
[61]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[62]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , journal=
-
[63]
Available at SSRN 3491790 , year=
From Generalized Linear Models to Neural Networks, and Back , author=. Available at SSRN 3491790 , year=
-
[64]
2023 , publisher=
Statistical Foundations of Actuarial Learning and its Applications , author=. 2023 , publisher=
2023
-
[65]
Entity Embeddings of Categorical Variables
Entity Embeddings of Categorical Variables , author=. arXiv preprint arXiv:1604.06737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
arXiv preprint arXiv:1910.03072 , year=
Sequence Embeddings Help to Identify Fraudulent Cases in Healthcare Insurance , author=. arXiv preprint arXiv:1910.03072 , year=
-
[67]
Dutang, Christophe and Charpentier, Arthur , journal=. fre. 2020 , note=
2020
-
[68]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Representation Learning: A Review and New Perspectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[69]
Enhancing Auto Insurance Risk Evaluation with Transformer and
Sun, Fengyi and Chen, Rui and Wang, Yanyan , journal=. Enhancing Auto Insurance Risk Evaluation with Transformer and
-
[70]
arXiv preprint , year=
Large Language Models for Insurance Intelligence , author=. arXiv preprint , year=
-
[71]
arXiv preprint , year=
Assessing Insurers' Litigation Risk: Claim Dispute Prediction with Actionable Interpretations Using Machine Learning , author=. arXiv preprint , year=
-
[72]
Proceedings of the Fourth ACM International Conference on AI in Finance , pages=
Large language models in finance: A survey , author=. Proceedings of the Fourth ACM International Conference on AI in Finance , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.