NI-ORCA: A Parallel Algorithm for Counting the Orbits of Non-Induced Graphlets up to K4
Pith reviewed 2026-06-30 07:27 UTC · model grok-4.3
The pith
NI-ORCA extends the ORCA framework with a reformulated linear system to count non-induced graphlet orbits up to size four in parallel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
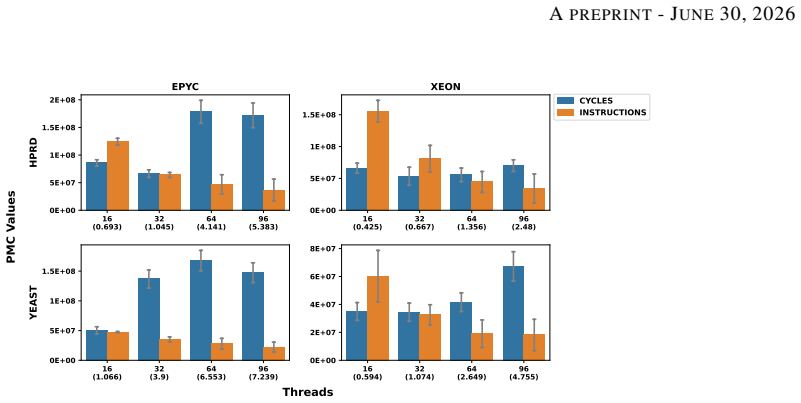
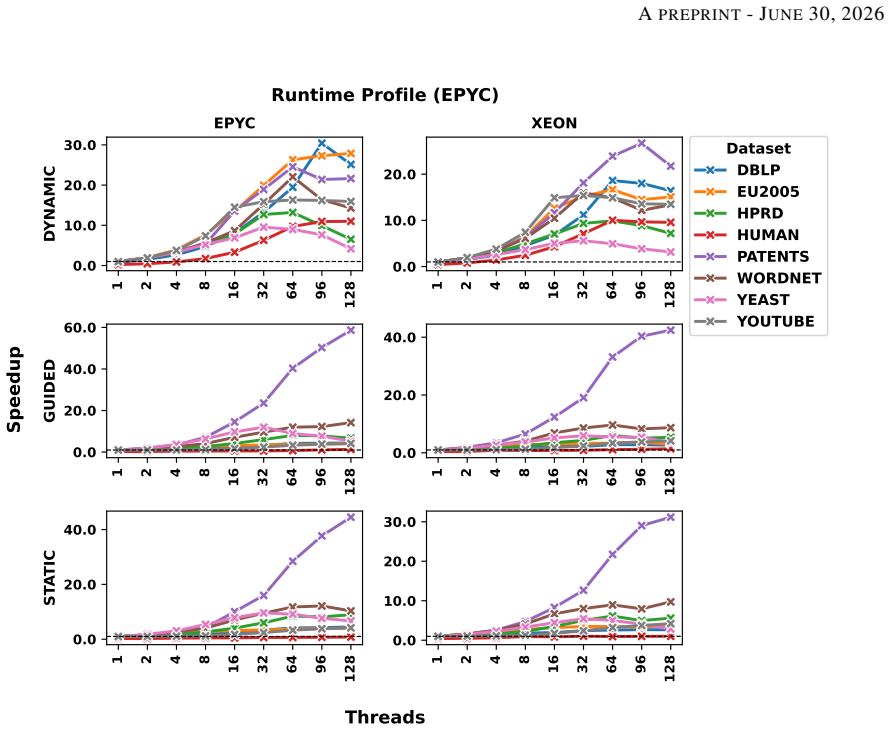
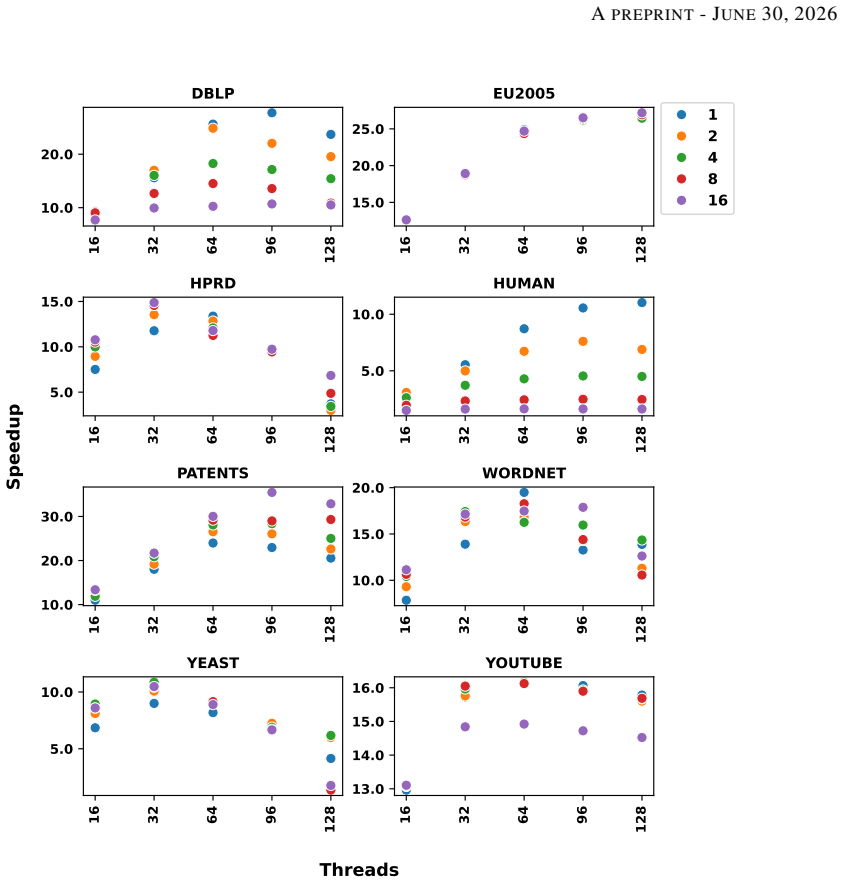
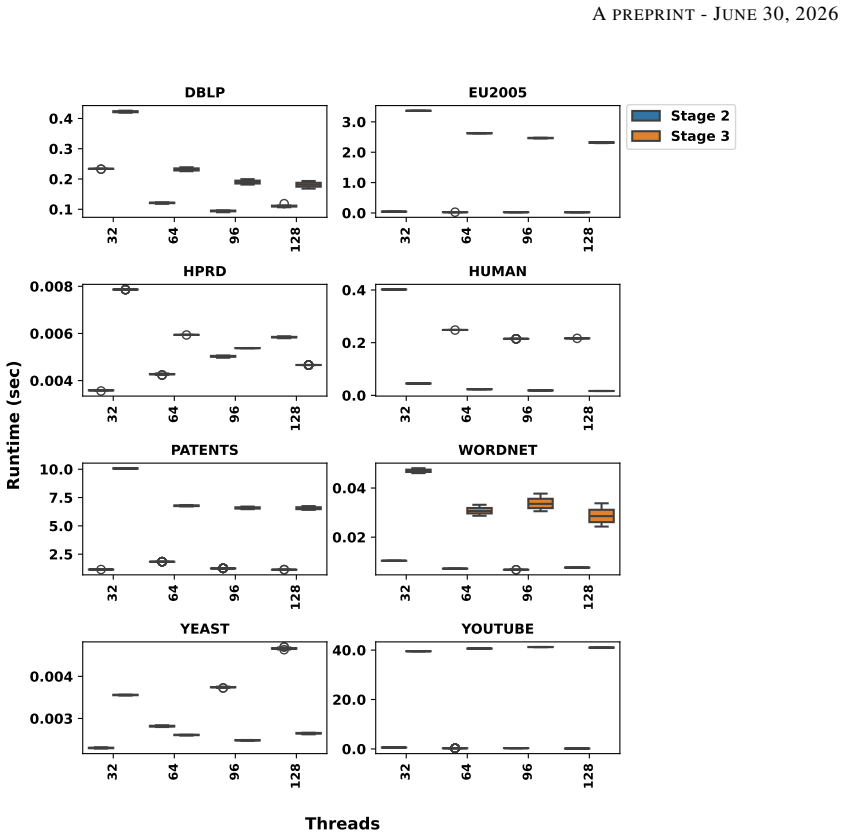
NI-ORCA computes the orbits of non-induced graphlets up to K4 by first counting triangles and enumerating 4-cliques in parallel, then solving a reformulated system of linear equations that maps those counts to the desired non-induced orbit values; stage-specific thread and vertex-local memory models together with dynamic scheduling produce the reported speedups.
What carries the argument
Reformulated linear system that converts triangle and 4-clique counts into exact non-induced orbit counts, executed after parallel enumeration stages.
If this is right
- Exact non-induced orbit counts become feasible at larger scales than sequential methods allow.
- A combination of stage-specific data structures and dynamic scheduling with small chunks balances workload across threads on both real and random graphs.
- The three-stage pipeline separates enumeration from linear solving so that each part can be tuned independently for parallelism.
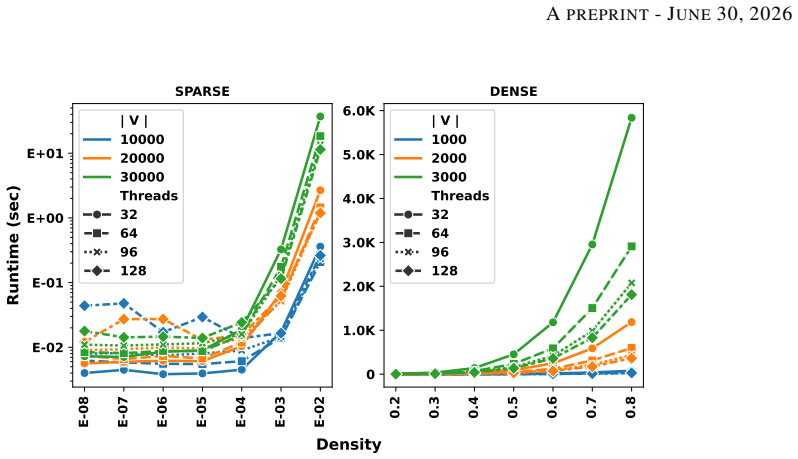
- Performance gains hold across eight real-world datasets and a range of Erdos-Renyi graphs.
Where Pith is reading between the lines
- The same reformulation technique might allow non-induced counting for larger k if the linear dependencies can be derived without loss of exactness.
- Stage-specific parallel strategies could transfer to other graphlet or motif enumeration problems that already use linear relations among counts.
- Faster non-induced orbit counting would let downstream tasks such as role detection in networks run on bigger inputs without switching to approximate methods.
Load-bearing premise
The reformulation of the linear system for non-induced orbits preserves exactness without introducing counting errors or requiring additional post-processing corrections.
What would settle it
Execute NI-ORCA and an independent exact sequential non-induced orbit counter on the same small graph with known orbit values; any mismatch in the reported counts would falsify the claim of preserved exactness.
Figures
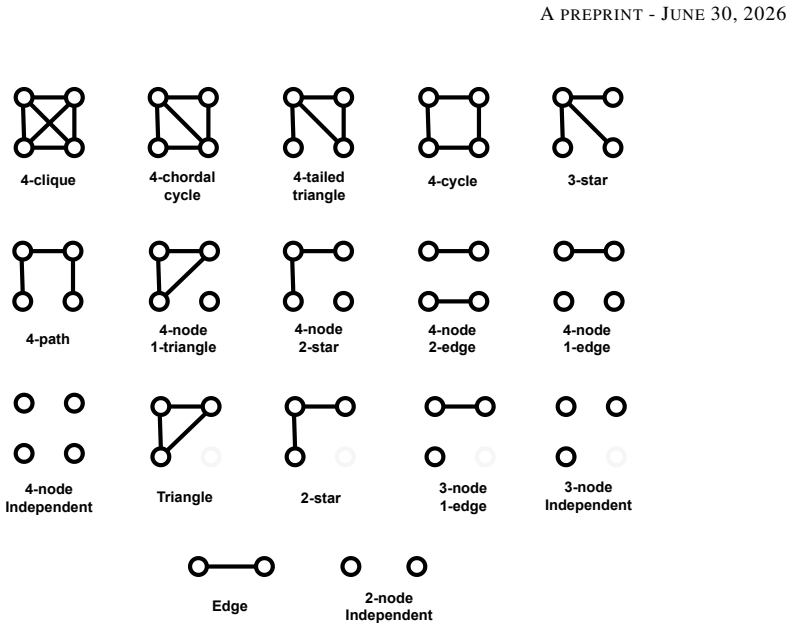
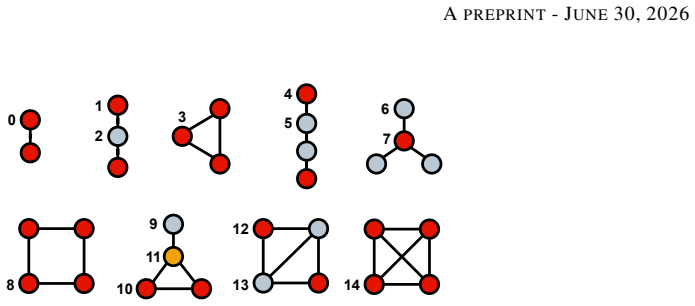
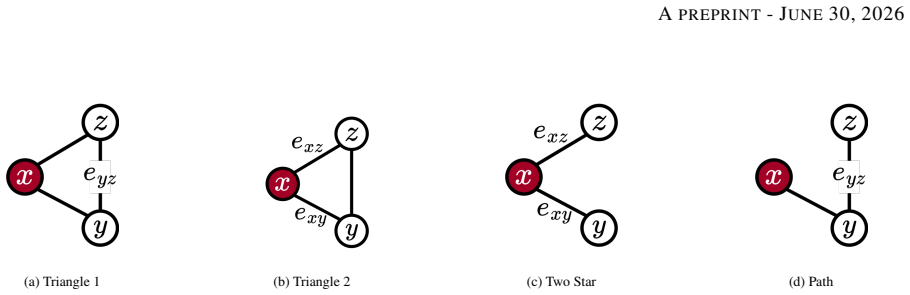
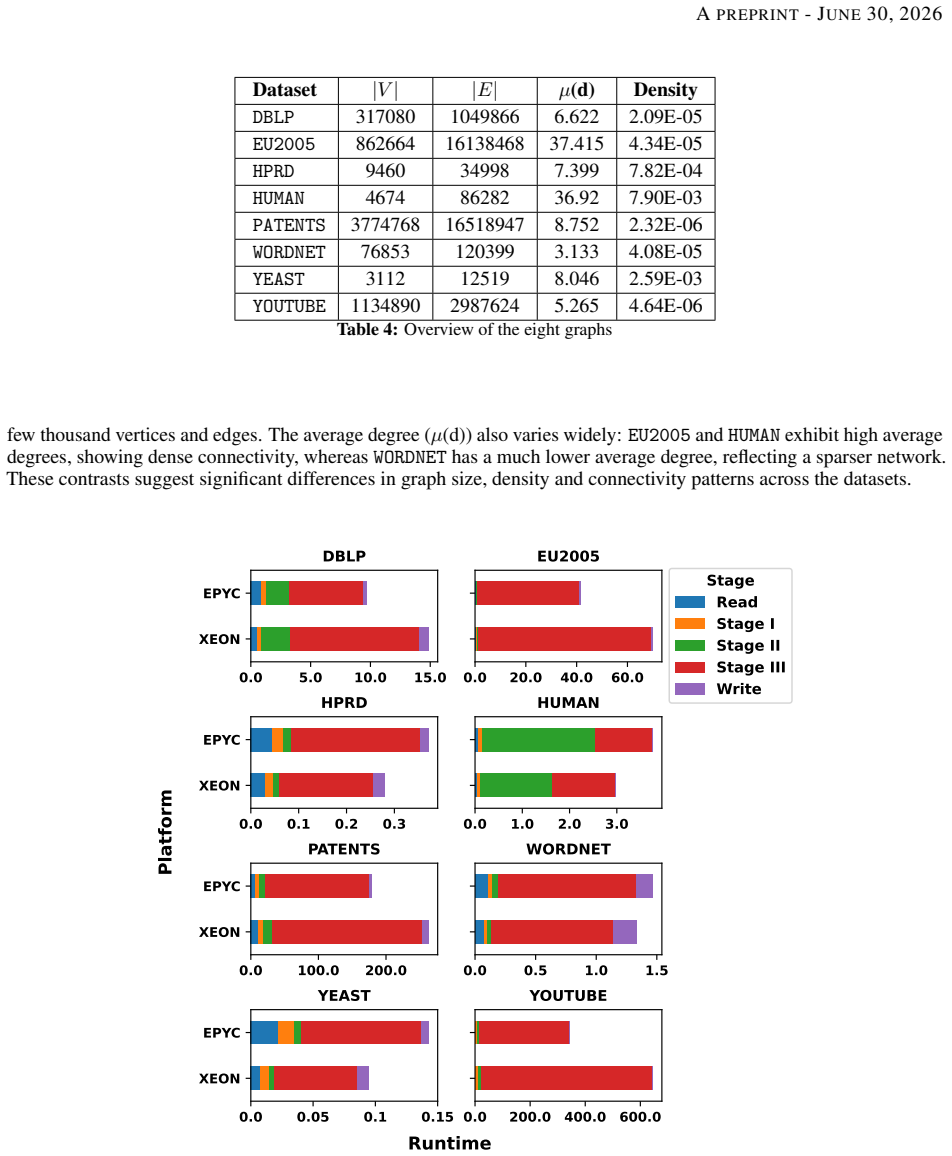
read the original abstract
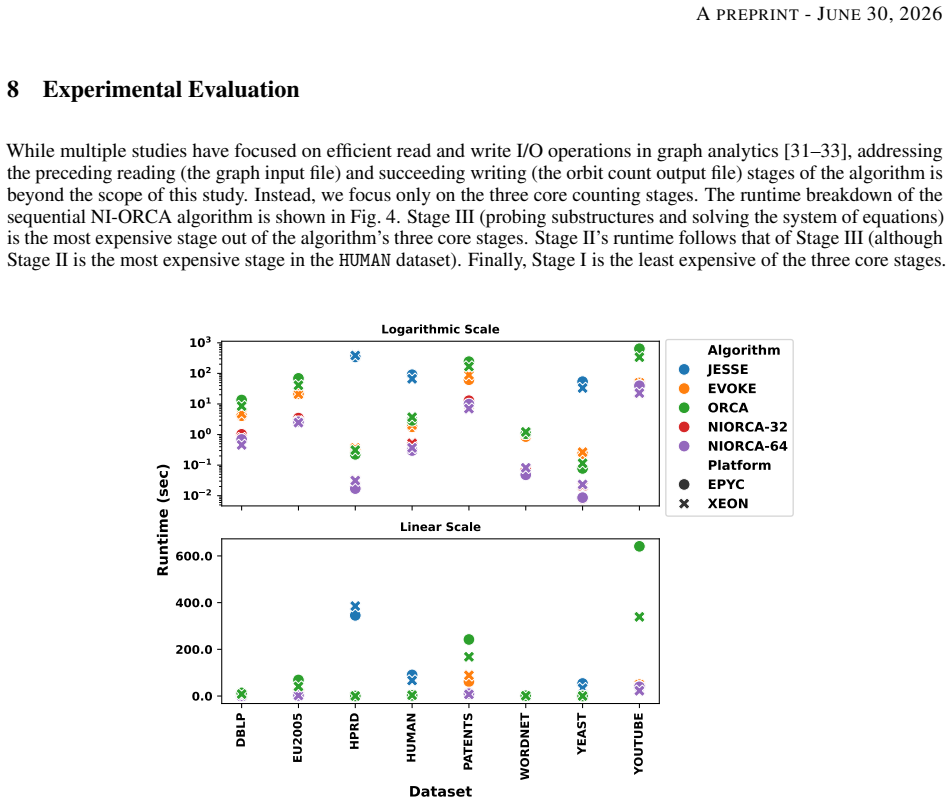
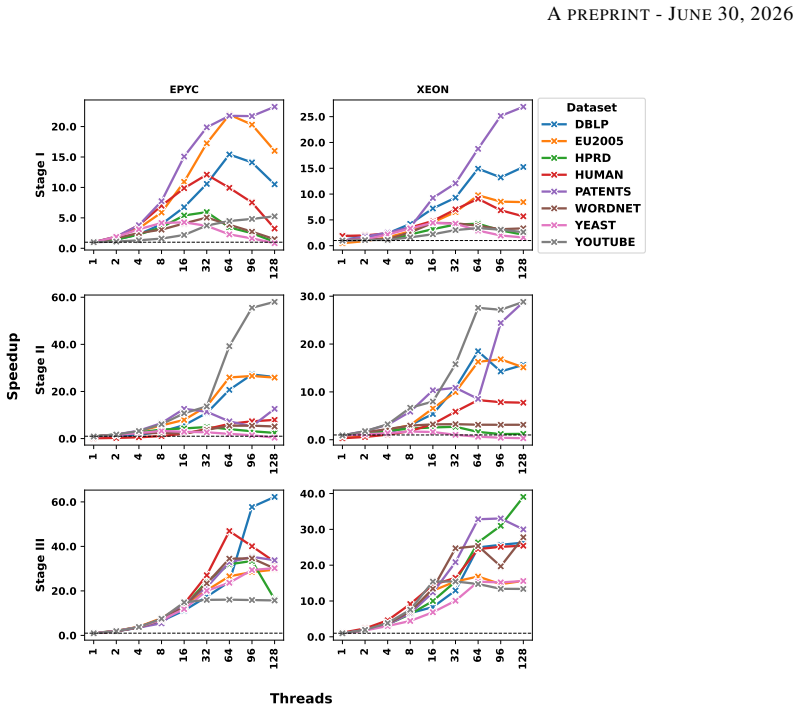
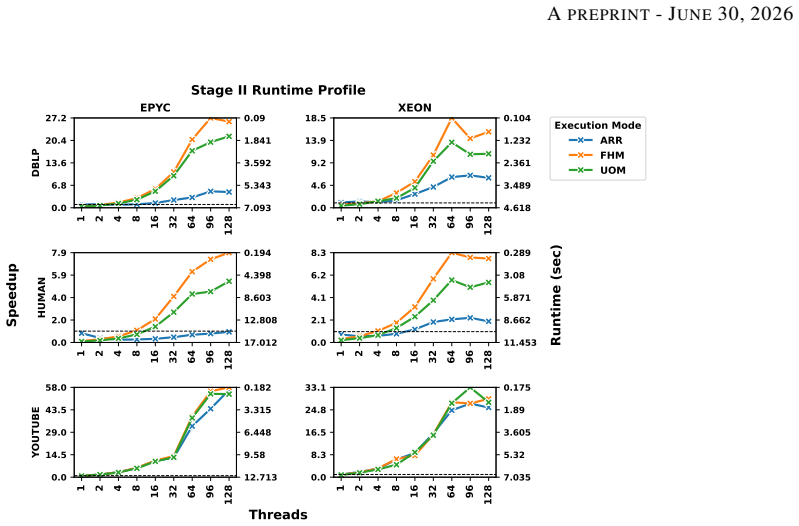
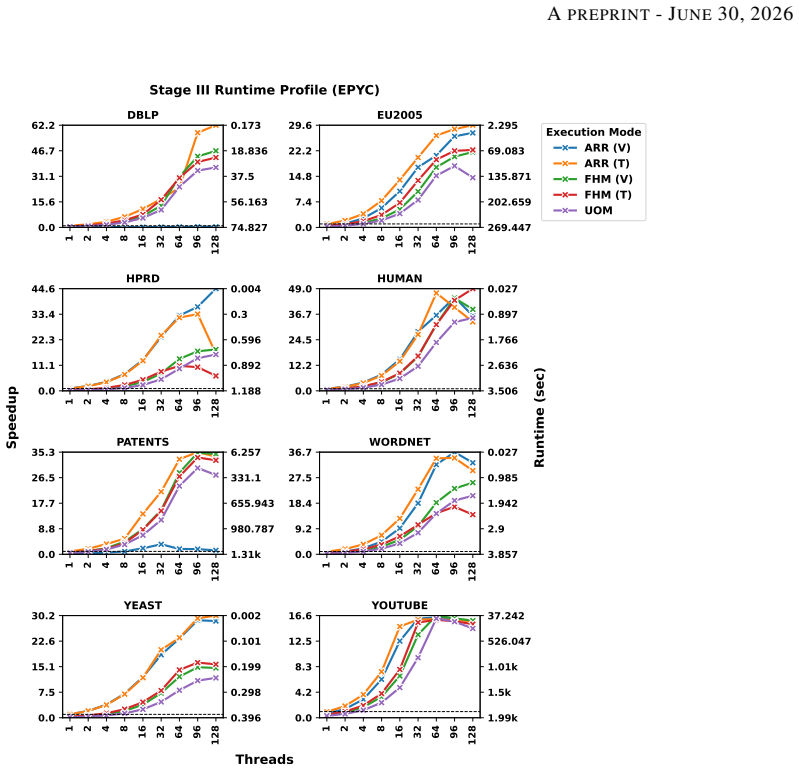
Counting the orbits of graphlets in a network is a vital tool for understanding the structural roles of vertices in various graph analytics tasks. While existing algorithms efficiently compute orbits of induced graphlets, many real-world applications require non-induced orbit counts. However, no current method offers exact, scalable, and parallel support for non-induced orbit counting. This paper presents NI-ORCA, a parallel algorithm to efficiently compute the orbits of non-induced graphlets up to size four (4-clique). NI-ORCA extends the ORCA framework for non-induced orbit counting by reformulating a system of linear equations. The algorithm consists of three stages: triangle counting, 4-clique enumeration, and orbit solving. We design and implement stage-specific parallelisation strategies using thread and vertex-local memory models and data structures, minimising contention and balancing workload. We further analyse the impact of scheduling policies, chunk sizes, and affinity strategies on performance. Experimental analysis on eight real-world datasets and a series of synthetic Erddos-Renyi graphs demonstrates that a mixed mode combining stage-specific data structure, with dynamic scheduling with small chunk sizes, delivers consistent speedup and effective load balancing. Our results show that NI-ORCA significantly outperforms state-of-the-art sequential algorithms, achieving up to 30x speedups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present NI-ORCA, a parallel algorithm extending the ORCA framework for exact counting of non-induced graphlet orbits up to K4 by reformulating a system of linear equations. It consists of triangle counting, 4-clique enumeration, and orbit solving stages with custom parallelization strategies using thread/vertex-local memory models, and reports up to 30x speedups over sequential methods on eight real-world datasets and Erdős-Rényi graphs, along with analysis of scheduling policies and chunk sizes.
Significance. If the reformulation is shown to preserve exact non-induced counts, the work would be significant for filling the gap in scalable parallel non-induced orbit counting up to K4, a task relevant to graph analytics. The stage-specific parallelization and empirical study of scheduling/affinity strategies would provide practical implementation guidance.
major comments (2)
- [Abstract (orbit solving stage)] Abstract (orbit solving stage): The reformulation of the linear system for non-induced orbits is stated as a direct algebraic change extending ORCA, but neither the explicit new matrix nor a proof that it matches the non-induced embedding definition is supplied. This is load-bearing for the correctness of all downstream counts and the 30x speedup claim.
- [Abstract (experimental analysis)] Abstract (experimental analysis): No validation of non-induced counts against a ground-truth sequential implementation, no error-bar analysis, and no numerical stability discussion for the linear solver are described, leaving the exactness of the reformulation unverified.
minor comments (1)
- The abstract is dense; clearer separation between the algorithmic extension, parallelization details, and performance claims would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit details on the orbit-solving reformulation and additional experimental validation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (orbit solving stage)] The reformulation of the linear system for non-induced orbits is stated as a direct algebraic change extending ORCA, but neither the explicit new matrix nor a proof that it matches the non-induced embedding definition is supplied. This is load-bearing for the correctness of all downstream counts and the 30x speedup claim.
Authors: We agree that the manuscript does not supply the explicit reformulated matrix or a formal proof of equivalence to the non-induced embedding definition. This omission weakens the presentation of correctness. In the revised version we will include the full new matrix (derived from the original ORCA system by adjusting for non-induced embeddings) together with a step-by-step algebraic derivation showing that the solution vector yields the exact non-induced orbit counts. This addition will directly support the correctness of all reported counts. revision: yes
-
Referee: [Abstract (experimental analysis)] No validation of non-induced counts against a ground-truth sequential implementation, no error-bar analysis, and no numerical stability discussion for the linear solver are described, leaving the exactness of the reformulation unverified.
Authors: We acknowledge that the current experimental section lacks direct validation of the non-induced counts against a ground-truth sequential implementation, error-bar reporting, and discussion of numerical stability. In the revision we will add (i) side-by-side comparisons on small graphs against a verified sequential non-induced counter, (ii) confirmation that all counts are exact integers (hence error bars are zero), and (iii) a brief note on the linear solver: because the system is solved over integers with exact arithmetic (no floating-point operations), numerical stability is not a concern. These changes will verify the exactness of the reformulation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents NI-ORCA as an algorithmic extension of the existing ORCA framework via direct algebraic reformulation of a linear system for non-induced orbits, followed by standard parallelization of three computational stages (triangle counting, 4-clique enumeration, orbit solving). No equations or claims reduce a derived quantity to its own inputs by construction, no parameters are fitted to data and then relabeled as predictions, and the reformulation is not justified by self-citation chains or uniqueness theorems from the same authors. The derivation chain consists of independent algorithmic steps whose correctness is asserted via algebraic change rather than empirical fitting or renaming of known results. This is a self-contained algorithmic description with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions of induced vs. non-induced subgraph embeddings and orbit equivalence under automorphism
Reference graph
Works this paper leans on
-
[1]
SNAP Datasets: Stanford large network dataset collection
Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collection. http://snap. stanford.edu/data, June 2014
2014
-
[2]
Rossi and Nesreen K
Ryan A. Rossi and Nesreen K. Ahmed. The network data repository with interactive graph analytics and visualization. InAAAI, 2015
2015
-
[3]
Machine learning-based per-instance algorithm selection for high-performance subgraph isomorphism enumeration
Syed Ibtisam Tauhidi, Arindam Karmakar, Thai Son Mai, and Hans Vandierendonck. Machine learning-based per-instance algorithm selection for high-performance subgraph isomorphism enumeration. InInternational Conference on Metaheuristics and Nature Inspired Computing, pages 214–229. Springer, 2023
2023
-
[4]
Motif-based graph self-supervised learning for molecular property prediction.Advances in Neural Information Processing Systems, 34:15870–15882, 2021
Zaixi Zhang, Qi Liu, Hao Wang, Chengqiang Lu, and Chee-Kong Lee. Motif-based graph self-supervised learning for molecular property prediction.Advances in Neural Information Processing Systems, 34:15870–15882, 2021
2021
-
[5]
Motif-driven contrastive learning of graph representations.IEEE Transactions on Knowledge and Data Engineering, 36(8):4063–4075, 2024
Shichang Zhang, Ziniu Hu, Arjun Subramonian, and Yizhou Sun. Motif-driven contrastive learning of graph representations.IEEE Transactions on Knowledge and Data Engineering, 36(8):4063–4075, 2024
2024
-
[6]
On analyzing graphs with motif-paths.Proceedings of the VLDB Endowment, 14(6), 2021
Xiaodong Li, Reynold Cheng, Kevin Chen-Chuan Chang, Caihua Shan, Chenhao Ma, and Hongtai Cao. On analyzing graphs with motif-paths.Proceedings of the VLDB Endowment, 14(6), 2021. 18 APREPRINT- JUNE30, 2026 E-08 E-07 E-06 E-05 E-04 E-03 E-02 E-02 E-01 E+00 E+01Runtime (sec) SPARSE | V | 10000 20000 30000 Threads 32 64 96 128 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 1...
2021
-
[7]
Efficient graphlet counting for large networks
Nesreen K Ahmed, Jennifer Neville, Ryan A Rossi, and Nick Duffield. Efficient graphlet counting for large networks. In2015 IEEE International Conference on Data Mining, pages 1–10. IEEE, 2015
2015
-
[8]
Motif finding algorithms: A performance comparison
Emanuele Martorana, Roberto Grasso, Giovanni Micale, Salvatore Alaimo, Dennis Shasha, Rosalba Giugno, and Alfredo Pulvirenti. Motif finding algorithms: A performance comparison. InFrom Computational Logic to Computational Biology: Essays Dedicated to Alfredo Ferro to Celebrate His Scientific Career, pages 250–267. Springer, 2024
2024
-
[9]
Investigating statistical analysis for network motifs
Zican Li and Wooyoung Kim. Investigating statistical analysis for network motifs. InProceedings of the 12th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, pages 1–6, 2021
2021
-
[10]
Efficiently counting vertex orbits of all 5-vertex subgraphs, by evoke
Noujan Pashanasangi and C Seshadhri. Efficiently counting vertex orbits of all 5-vertex subgraphs, by evoke. In Proceedings of the 13th International Conference on Web Search and Data Mining, pages 447–455, 2020
2020
-
[11]
Link prediction based on orbit counting and graph auto-encoder.IEEE Access, 8:226773–226783, 2020
Jian Feng and Shaojian Chen. Link prediction based on orbit counting and graph auto-encoder.IEEE Access, 8:226773–226783, 2020
2020
-
[12]
Graphlet correlation distance to compare small graphs.Plos one, 18(2):e0281646, 2023
J´erˆome Roux, Nicolas Bez, Paul Rochet, Roc´ıo Joo, and St´ephanie Mah´evas. Graphlet correlation distance to compare small graphs.Plos one, 18(2):e0281646, 2023
2023
-
[13]
A survey on subgraph counting: concepts, algorithms, and applications to network motifs and graphlets.ACM Computing Surveys (CSUR), 54(2):1–36, 2021
Pedro Ribeiro, Pedro Paredes, Miguel EP Silva, David Aparicio, and Fernando Silva. A survey on subgraph counting: concepts, algorithms, and applications to network motifs and graphlets.ACM Computing Surveys (CSUR), 54(2):1–36, 2021
2021
-
[14]
A combinatorial approach to graphlet counting.Bioinformatics, 30(4):559–565, 2014
Tomaˇz Hoˇcevar and Janez Demˇsar. A combinatorial approach to graphlet counting.Bioinformatics, 30(4):559–565, 2014
2014
-
[15]
An algorithm to automati- cally generate the combinatorial orbit counting equations.PloS one, 11(1):e0147078, 2016
Ine Melckenbeeck, Pieter Audenaert, Tom Michoel, Didier Colle, and Mario Pickavet. An algorithm to automati- cally generate the combinatorial orbit counting equations.PloS one, 11(1):e0147078, 2016
2016
-
[16]
Combimotif: A new algorithm for network motifs discovery in protein–protein interaction networks.Physica A: Statistical Mechanics and its Applications, 416:309–320, 2014
Jiawei Luo, Guanghui Li, Dan Song, and Cheng Liang. Combimotif: A new algorithm for network motifs discovery in protein–protein interaction networks.Physica A: Statistical Mechanics and its Applications, 416:309–320, 2014
2014
-
[17]
Orbitsi: An orbit-based algorithm for the subgraph isomorphism search problem
Syed Ibtisam Tauhidi, Arindam Karmakar, Thai Son Mai, and Hans Vandierendonck. Orbitsi: An orbit-based algorithm for the subgraph isomorphism search problem. In2024 IEEE International Conference on Knowledge Graph (ICKG), pages 360–369. IEEE, 2024
2024
-
[18]
Efficient orbit-aware triad and quad census in directed and undirected graphs
Mark Ortmann and Ulrik Brandes. Efficient orbit-aware triad and quad census in directed and undirected graphs. Applied network science, 2:1–17, 2017
2017
-
[19]
Escape: Efficiently counting all 5-vertex subgraphs
Ali Pinar, Comandur Seshadhri, and Vaidyanathan Vishal. Escape: Efficiently counting all 5-vertex subgraphs. In Proceedings of the 26th international conference on world wide web, pages 1431–1440, 2017
2017
-
[20]
Rage–a rapid graphlet enumerator for large networks.Computer Networks, 56(2):810–819, 2012
Dror Marcus and Yuval Shavitt. Rage–a rapid graphlet enumerator for large networks.Computer Networks, 56(2):810–819, 2012. 19 APREPRINT- JUNE30, 2026
2012
-
[21]
Biological network comparison using graphlet degree distribution.Bioinformatics, 23(2):e177–e183, 2007
Nataˇsa Prˇzulj. Biological network comparison using graphlet degree distribution.Bioinformatics, 23(2):e177–e183, 2007
2007
-
[22]
Graphcrunch: a tool for large network analyses.BMC bioinformatics, 9:1–11, 2008
Tijana Milenkovi´c, Jason Lai, and Nata ˇsa Pr ˇzulj. Graphcrunch: a tool for large network analyses.BMC bioinformatics, 9:1–11, 2008
2008
-
[23]
Graphcrunch 2: software tool for network modeling, alignment and clustering.BMC bioinformatics, 12:1–13, 2011
Oleksii Kuchaiev, Aleksandar Stevanovi´c, Wayne Hayes, and Nataˇsa Prˇzulj. Graphcrunch 2: software tool for network modeling, alignment and clustering.BMC bioinformatics, 12:1–13, 2011
2011
-
[24]
Mohammad Matin Najafi, Xianju Zhu, Chrysanthi Kosyfaki, Laks VS Lakshmanan, and Reynold Cheng. Beacon: A benchmark for efficient and accurate counting of subgraphs.arXiv preprint arXiv:2504.10948, 2025
-
[25]
Provably powerful graph networks
Haggai Maron, Heli Ben-Hamu, Hadar Serviansky, and Yaron Lipman. Provably powerful graph networks. Advances in neural information processing systems, 32, 2019
2019
-
[26]
Ordered subgraph aggrega- tion networks.Advances in Neural Information Processing Systems, 35:21030–21045, 2022
Chendi Qian, Gaurav Rattan, Floris Geerts, Mathias Niepert, and Christopher Morris. Ordered subgraph aggrega- tion networks.Advances in Neural Information Processing Systems, 35:21030–21045, 2022
2022
-
[27]
Cardinality estimation over knowledge graphs with embeddings and graph neural networks.Proceedings of the ACM on Management of Data, 2(1):1–26, 2024
Tim Schwabe and Maribel Acosta. Cardinality estimation over knowledge graphs with embeddings and graph neural networks.Proceedings of the ACM on Management of Data, 2(1):1–26, 2024
2024
-
[28]
Distributed subgraph counting: a general approach.Proceedings of the VLDB Endowment, 13(12):2493–2507, 2020
Hao Zhang, Jeffrey Xu Yu, Yikai Zhang, Kangfei Zhao, and Hong Cheng. Distributed subgraph counting: a general approach.Proceedings of the VLDB Endowment, 13(12):2493–2507, 2020
2020
-
[29]
Fast local subgraph counting.Proceedings of the VLDB Endowment, 17(8):1967–1980, 2024
Qiyan Li and Jeffrey Xu Yu. Fast local subgraph counting.Proceedings of the VLDB Endowment, 17(8):1967–1980, 2024
1967
-
[30]
Exploring network structure, dynamics, and function using networkx
Aric Hagberg, Pieter J Swart, and Daniel A Schult. Exploring network structure, dynamics, and function using networkx. Technical report, Los Alamos National Laboratory (LANL), Los Alamos, NM (United States), 2008
2008
-
[31]
Mohsen Koohi Esfahani, Marco D’Antonio, Syed Ibtisam Tauhidi, Thai Son Mai, and Hans Vandierendonck. Selective parallel loading of large-scale compressed graphs with paragrapher.arXiv preprint arXiv:2404.19735, 2024
-
[32]
Xue Li, Weibin Zeng, Zhibin Wang, Diwen Zhu, Jingbo Xu, Wenyuan Yu, and Jingren Zhou. Graphar: An efficient storage scheme for graph data in data lakes.arXiv preprint arXiv:2312.09577, 2023
-
[33]
Hongzheng Li, Yingxia Shao, Junping Du, Bin Cui, and Lei Chen. An i/o-efficient disk-based graph system for scalable second-order random walk of large graphs.arXiv preprint arXiv:2203.16123, 2022
-
[34]
Performance application programming interface.Sun, Baruah and Kaeli, 12:2022, 2022
Anthony Danalis and Heike Jagode. Performance application programming interface.Sun, Baruah and Kaeli, 12:2022, 2022. 20
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.