ECHO: Learning Epistemically Adaptive Language Agents with Turn-Level Credit
Pith reviewed 2026-06-30 04:32 UTC · model grok-4.3
The pith
Belief-agnostic policies suffer exponentially compounding errors over multi-turn horizons, while ECHO assigns turn-level credit via posterior-sensitive rewards to enable epistemic adaptivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
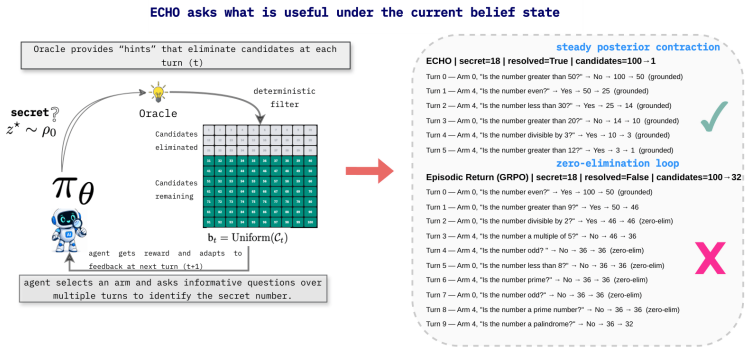
In Epistemic Decision Processes good policies select actions that are useful under the current posterior over a latent task variable rather than merely those correlated with eventual success. Belief-agnostic policies suffer errors that compound exponentially over the horizon, and aggregate trajectory returns fail to identify the per-turn Bayesian advantage needed for epistemic credit. ECHO supplies a practical clipped policy-gradient objective that assigns turn-level credit using posterior-sensitive rewards.
What carries the argument
Epistemic Decision Processes (EDPs), a belief-state formulation of information seeking in which actions update the agent's posterior over a latent task variable, together with the ECHO clipped policy-gradient objective that uses posterior-sensitive rewards for turn-level credit assignment.
If this is right
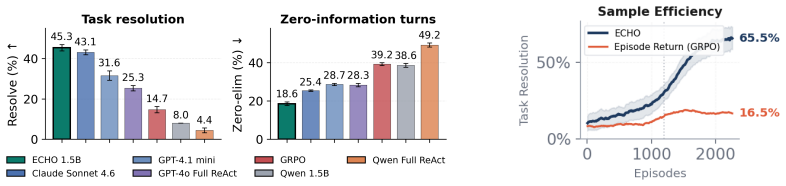
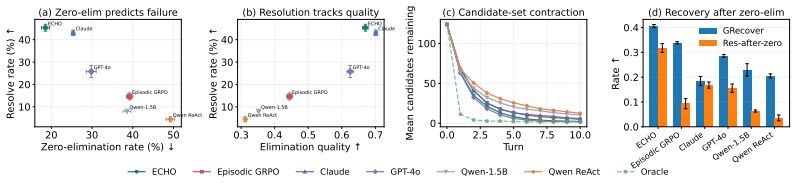
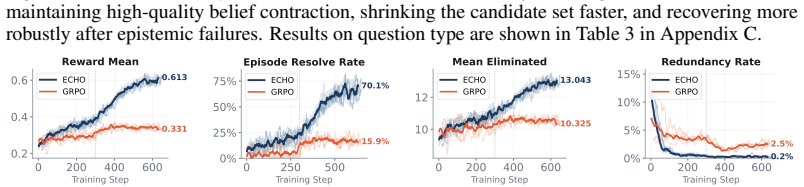
- ECHO improves resolution, information gain, and efficiency over trajectory-level GRPO in the Clue Selector Game.
- ECHO matches or exceeds frontier baselines on epistemic metrics including grounding, recovery, and calibration while producing almost no visible reasoning text.
- Turn-level posterior rewards address the inability of aggregate returns to isolate per-turn Bayesian advantages.
- The approach makes epistemic adaptivity explicit by tying action selection to current belief rather than eventual success alone.
Where Pith is reading between the lines
- The EDP formulation could extend to other multi-turn settings where agents must decide when to gather evidence versus act, such as diagnostic or planning dialogues.
- If exact posterior tracking proves intractable at scale, lightweight approximations might still preserve the turn-level credit signal.
- The exponential compounding result suggests testing whether similar error growth appears in non-language POMDP tasks with evolving beliefs.
Load-bearing premise
A well-defined latent task variable exists whose posterior can be maintained and updated from observations to produce usable per-turn rewards for the policy gradient.
What would settle it
An experiment in which belief-agnostic policies exhibit no exponential error compounding across turns, or in which posterior maintenance fails to generate effective turn-level reward signals.
Figures

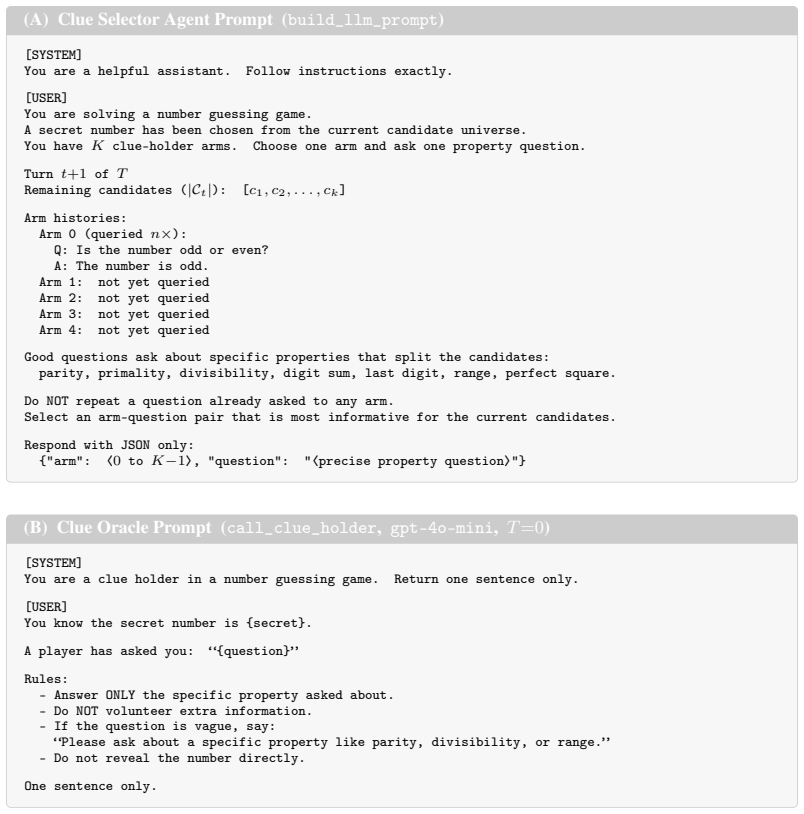
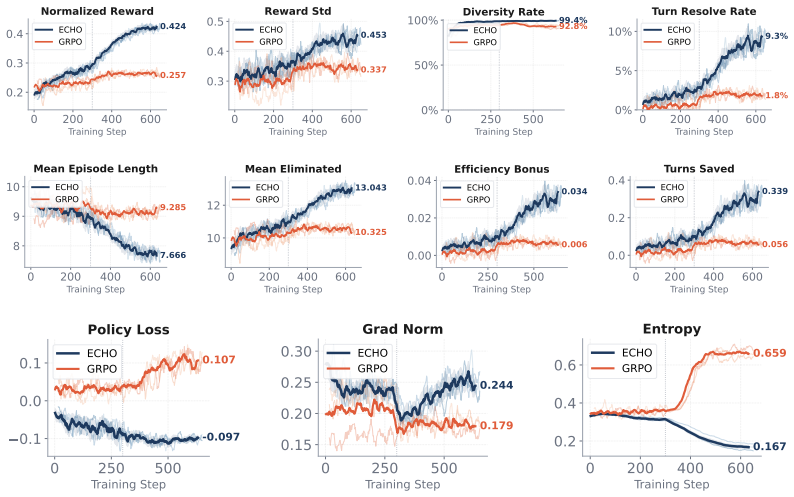
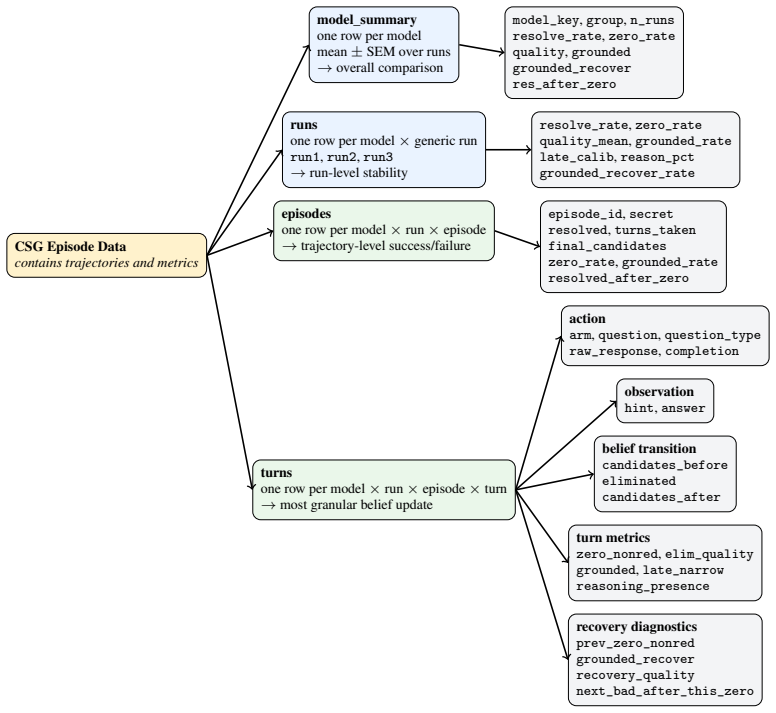
read the original abstract
What does it mean for a language agent to be adaptive? Effective multi-turn agents must decide what information to seek, how to use new evidence, and when they are certain enough to act. We introduce Epistemic Decision Processes (EDPs), a belief-state formulation of multi-turn information seeking in which actions produce external observations that update the agent's posterior over a latent task variable. EDPs make epistemic adaptivity explicit: good policies choose actions that are useful under the current belief, not merely those that correlate with eventual success. We prove that belief-agnostic policies can suffer errors that compound exponentially over the horizon, and that aggregate trajectory returns can fail to identify the per-turn Bayesian advantage needed for epistemic credit. We then introduce ECHO (Epistemic Credit for History-Conditioned Optimization), a practical clipped policy-gradient objective that assigns turn-level credit using posterior-sensitive rewards. In the Clue Selector Game, a novel controlled evidence-seeking benchmark, we show that ECHO substantially improves resolution, information gain, and efficiency over trajectory-level GRPO, and matches or exceeds frontier baselines on epistemic metrics such as grounding, recovery, and calibration while producing almost no visible reasoning text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Epistemic Decision Processes (EDPs) as a belief-state formulation of multi-turn information-seeking tasks where actions yield observations that update a posterior over a latent task variable θ. It proves that belief-agnostic policies incur exponentially compounding errors over the horizon and that aggregate trajectory returns fail to isolate per-turn Bayesian advantages. It then defines the ECHO clipped policy-gradient objective that incorporates posterior-sensitive rewards r_t(θ) for turn-level credit assignment. Empirical evaluation on the Clue Selector Game benchmark shows ECHO improving resolution, information gain, efficiency, grounding, recovery, and calibration relative to trajectory-level GRPO while producing minimal visible reasoning text.
Significance. If the central claims hold, the work supplies a formal framework and practical objective for training language agents that explicitly optimize for epistemic adaptivity rather than end-of-trajectory success. The theoretical separation between belief-agnostic and belief-aware policies, together with the controlled Clue Selector Game benchmark, would be a useful contribution to the literature on multi-turn RL for LLMs. The paper receives credit for defining EDPs, stating the exponential-compounding result, and releasing a reproducible benchmark comparison.
major comments (3)
- [Abstract / EDP formulation] Abstract and EDP definition: the central claims (exponential error compounding and the necessity of posterior-sensitive rewards) rest on the existence of a well-defined latent θ whose posterior p(θ|h) can be maintained and updated from language-model observations; no identifiability conditions, approximation-error bounds, or robustness analysis for cases in which observations do not cleanly separate θ are supplied, which directly affects whether the claimed separation from GRPO is realizable.
- [Theoretical results on belief-agnostic policies] Proof of exponential error compounding: the derivation presupposes observable updates to p(θ|h) that yield usable per-turn Bayesian advantages; without explicit conditions on the observation model or bounds on posterior estimation error, it is unclear whether the exponential-compounding result transfers to the language-agent setting where the posterior model may differ from the policy.
- [ECHO objective and Clue Selector Game experiments] ECHO objective and experimental section: the clipped policy-gradient uses posterior-sensitive rewards r_t(θ); if the posterior estimator introduces bias or noise (as is likely when the model used for p(θ|h) differs from the policy), the turn-level credit signal may not reliably outperform trajectory-level baselines, yet no ablation on posterior accuracy or statistical significance tests with error bars are reported.
minor comments (2)
- [Method] Notation for the posterior-sensitive reward r_t(θ) and the clipping parameter in the ECHO objective should be defined explicitly with reference to the standard PPO/GRPO formulation to aid readability.
- [Experiments] The claim of 'almost no visible reasoning text' is interesting but would benefit from a quantitative metric or example traces in the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the EDP formulation, theoretical results, and experimental validation. We address each major comment below, clarifying the assumptions in our framework and noting planned revisions to enhance robustness.
read point-by-point responses
-
Referee: [Abstract / EDP formulation] Abstract and EDP definition: the central claims (exponential error compounding and the necessity of posterior-sensitive rewards) rest on the existence of a well-defined latent θ whose posterior p(θ|h) can be maintained and updated from language-model observations; no identifiability conditions, approximation-error bounds, or robustness analysis for cases in which observations do not cleanly separate θ are supplied, which directly affects whether the claimed separation from GRPO is realizable.
Authors: The EDP formulation explicitly defines a latent task variable θ with observations that update the posterior p(θ|h). The theoretical claims are derived under this model assuming the observation process allows for posterior updates. In the Clue Selector Game benchmark, θ is the hidden clue, which is fully identifiable, allowing exact posterior maintenance. We do not provide general identifiability conditions for arbitrary language observations, as the work focuses on the controlled setting where the separation is demonstrated. We will revise the manuscript to include a discussion of the identifiability assumption and potential approximation errors in more general settings. revision: partial
-
Referee: [Theoretical results on belief-agnostic policies] Proof of exponential error compounding: the derivation presupposes observable updates to p(θ|h) that yield usable per-turn Bayesian advantages; without explicit conditions on the observation model or bounds on posterior estimation error, it is unclear whether the exponential-compounding result transfers to the language-agent setting where the posterior model may differ from the policy.
Authors: The proof is conducted within the EDP framework, which by definition includes observable updates to the belief state p(θ|h). The exponential compounding result is a mathematical property of belief-agnostic policies in this setting and does not rely on a specific posterior estimator. In the language-agent experiments, the benchmark ensures that the posterior is computed consistently with the observations. We will add explicit statements on the observation model assumptions to the theoretical section in the revision. revision: partial
-
Referee: [ECHO objective and Clue Selector Game experiments] ECHO objective and experimental section: the clipped policy-gradient uses posterior-sensitive rewards r_t(θ); if the posterior estimator introduces bias or noise (as is likely when the model used for p(θ|h) differs from the policy), the turn-level credit signal may not reliably outperform trajectory-level baselines, yet no ablation on posterior accuracy or statistical significance tests with error bars are reported.
Authors: In the Clue Selector Game, the posterior p(θ|h) is computed exactly from the game state and observations without any estimation bias or noise, as the latent θ is known to the environment. Thus, the posterior-sensitive rewards are precise, and the policy and posterior are not from differing models. We agree that reporting statistical significance and error bars would strengthen the results. We will include these in the revised experimental section. revision: yes
Circularity Check
No significant circularity; derivation is self-contained within introduced EDP framework
full rationale
The paper defines EDPs as a new belief-state formulation, proves properties of belief-agnostic policies under that model, and derives the ECHO objective from posterior-sensitive rewards within the same framework. These steps rely on the modeling choice of a latent task variable and its posterior updates, which are external to the derivation rather than self-referential. No equations reduce predictions or advantages to fitted parameters defined from the same data, and no load-bearing self-citations or ansatzes are invoked. The central claims remain independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Actions produce external observations that update the agent's posterior over a latent task variable via standard Bayesian updating.
invented entities (2)
-
Epistemic Decision Processes (EDPs)
no independent evidence
-
ECHO objective
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Marwa Abdulhai, Isadora White, Charlie Victor Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models. InForty-second International Conference on Machine Learning, 2023
2023
-
[2]
Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational...
-
[3]
STaR- GATE: Teaching Language Models to Ask Clarifying Questions
Chinmaya Andukuri, Jan-Philipp Fränken, Tobias Gerstenberg, and Noah Goodman. STaR- GATE: Teaching Language Models to Ask Clarifying Questions. InFirst Conference on Language Modeling, 2024
2024
-
[4]
Optimal control of markov processes with incomplete state information i
Karl Johan Åström. Optimal control of markov processes with incomplete state information i. Journal of mathematical analysis and applications, 10:174–205, 1965. 10
1965
-
[5]
Align while search: Belief- guided exploratory inference for world-grounded embodied agents, 2025
Seohui Bae, Jeonghye Kim, Youngchul Sung, and Woohyung Lim. Align while search: Belief- guided exploratory inference for world-grounded embodied agents, 2025. URL https:// arxiv.org/abs/2512.24461
-
[6]
Recent advances in hierarchical reinforcement learning.Discrete event dynamic systems, 13(1-2):41–77, 2003
Andrew G Barto and Sridhar Mahadevan. Recent advances in hierarchical reinforcement learning.Discrete event dynamic systems, 13(1-2):41–77, 2003
2003
-
[7]
A problem in the sequential design of experiments.Sankhy ¯a: The Indian Journal of Statistics (1933-1960), 16(3/4):221–229, 1956
Richard Bellman. A problem in the sequential design of experiments.Sankhy ¯a: The Indian Journal of Statistics (1933-1960), 16(3/4):221–229, 1956
1933
-
[8]
Chatgpt’s information seeking strategy: Insights from the 20-questions game
Leonardo Bertolazzi, Davide Mazzaccara, Filippo Merlo, and Raffaella Bernardi. Chatgpt’s information seeking strategy: Insights from the 20-questions game. InProceedings of the 16th International Natural Language Generation Conference, pages 153–162, 2023
2023
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Ma- teusz Litwin, S...
1901
-
[10]
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Deepro Choudhury, Sinead Williamson, Adam Goli´nski, Ning Miao, Freddie Bickford Smith, Michael Kirchhof, Yizhe Zhang, and Tom Rainforth. Bed-llm: Intelligent information gathering with llms and bayesian experimental design.arXiv preprint arXiv:2508.21184, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Process reward models for llm agents: Practical framework and directions,
Sanjiban Choudhury. Process reward models for llm agents: Practical framework and directions,
- [12]
-
[13]
Children’s questions: A mecha- nism for cognitive development.Monographs of the society for research in child development, pages i–129, 2007
Michelle M Chouinard, Paul L Harris, and Michael P Maratsos. Children’s questions: A mecha- nism for cognitive development.Monographs of the society for research in child development, pages i–129, 2007
2007
-
[14]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[15]
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
University of Massachusetts Amherst, 2002
Michael O’Gordon Duff.Optimal Learning: Computational procedures for Bayes-adaptive Markov decision processes. University of Massachusetts Amherst, 2002
2002
-
[17]
BALAR : A Bayesian Agentic Loop for Active Reasoning
Aymen Echarghaoui, Dongxia Wu, and Emily B Fox. Balar: A bayesian agentic loop for active reasoning.arXiv preprint arXiv:2605.05386, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Is in-context learning in large language models bayesian? a martingale perspective
Fabian Falck, Ziyu Wang, and Christopher C Holmes. Is in-context learning in large language models bayesian? a martingale perspective. InInternational Conference on Machine Learning, pages 12784–12805. PMLR, 2024
2024
-
[19]
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies, 2021
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies, 2021. URLhttps://arxiv.org/abs/2101.02235
-
[21]
Mohammad Ghavamzadeh, Shie Mannor, Joelle Pineau, and Aviv Tamar. Bayesian rein- forcement learning: A survey.Foundations and Trends® in Machine Learning, 8(5-6): 359–483, November 2015. ISSN 1935-8245. doi: 10.1561/2200000049. URL http: //dx.doi.org/10.1561/2200000049. 11
-
[22]
Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 5(Nov): 1471–1530, 2004
Evan Greensmith, Peter L Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 5(Nov): 1471–1530, 2004
2004
-
[23]
Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, and Shuang Qiu. Segment policy optimization: Ef- fective segment-level credit assignment in rl for large language models.arXiv preprint arXiv:2505.23564, 2025
-
[24]
Information value theory.IEEE Transactions on systems science and cybernetics, 2(1):22–26, 1966
Ronald A Howard. Information value theory.IEEE Transactions on systems science and cybernetics, 2(1):22–26, 1966
1966
-
[25]
Playing 20 question game with policy-based reinforcement learning, 2026
Huang Hu, Xianchao Wu, Bingfeng Luo, Chongyang Tao, Can Xu, Wei Wu, and Zhan Chen. Playing 20 question game with policy-based reinforcement learning, 2026. URL https: //arxiv.org/abs/1808.07645
-
[26]
Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization
Xingyuan Hua, Sheng Yue, and Ju Ren. Learning to explore: Scaling agentic reasoning via exploration-aware policy optimization, 2026. URLhttps://arxiv.org/abs/2605.08978
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Mysteries of mode collapse
janus. Mysteries of mode collapse. https://www.lesswrong.com/posts/ t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse , November 2022. LessWrong post. Accessed: 2026-05-12
2022
-
[28]
Reflect- then-plan: Offline model-based planning through a doubly bayesian lens
Jihwan Jeong, Xiaoyu Wang, Jingmin Wang, Scott Sanner, and Pascal Poupart. Reflect- then-plan: Offline model-based planning through a doubly bayesian lens. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=pQYEMwHd6c
2025
-
[29]
Search-r1: Training llms to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling
-
[30]
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Hongbo Jin, Rongpeng Zhu, Zhongjing Du, Xu Jiang, Jingqi Tian, Qiaoman Zhang, and Jiayu Ding. Dgpo: Distribution guided policy optimization for fine grained credit assignment.arXiv preprint arXiv:2605.03327, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
1998
-
[32]
Vineppo: Refining credit assignment in rl training of llms, 2025
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in rl training of llms, 2025. URLhttps://arxiv.org/abs/2410.01679
-
[33]
Active task disambiguation with llms, 2025
Katarzyna Kobalczyk, Nicolas Astorga, Tennison Liu, and Mihaela van der Schaar. Active task disambiguation with llms, 2025. URLhttps://arxiv.org/abs/2502.04485
-
[34]
In-context learning learns label relationships but is not conventional learning
Jannik Kossen, Yarin Gal, and Tom Rainforth. In-context learning learns label relationships but is not conventional learning. InThe Twelfth International Conference on Learning Representations,
-
[35]
URLhttps://openreview.net/forum?id=YPIA7bgd5y
-
[36]
LLMs get lost in multi- turn conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi- turn conversation. InThe Fourteenth International Conference on Learning Representations,
-
[37]
URLhttps://openreview.net/forum?id=VKGTGGcwl6
-
[38]
PRInTS: Reward Modeling for Long-Horizon Information Seeking
Jaewoo Lee, Archiki Prasad, Justin Chih-Yao Chen, Zaid Khan, Elias Stengel-Eskin, and Mohit Bansal. Prints: Reward modeling for long-horizon information seeking.arXiv preprint arXiv:2511.19314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Alfa: Aligning llms to ask good questions a case study in clinical reasoning
Shuyue Stella Li, Jimin Mun, Faeze Brahman, Pedram Hosseini, Bryceton G Thomas, Jessica M Sin, Bing Ren, Jonathan S Ilgen, Yulia Tsvetkov, and Maarten Sap. Alfa: Aligning llms to ask good questions a case study in clinical reasoning. InSecond Conference on Language Modeling
-
[40]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638. URLhttps://aclanthology.org/2024.tacl-1.9/. 12
-
[41]
Reason- ing models can be effective without thinking, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reason- ing models can be effective without thinking, 2025. URL https://arxiv.org/abs/2504. 09858
2025
-
[42]
Bayesian decision problems and markov chains.(No Title), 1967
James John Martin. Bayesian decision problems and markov chains.(No Title), 1967
1967
-
[43]
Learning to ask informative questions: Enhancing LLMs with preference optimization and expected information gain
Davide Mazzaccara, Alberto Testoni, and Raffaella Bernardi. Learning to ask informative questions: Enhancing LLMs with preference optimization and expected information gain. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5064–5074, Miami, Florida, USA, November
2024
-
[44]
doi: 10.18653/v1/2024.findings-emnlp.291
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.291. URLhttps://aclanthology.org/2024.findings-emnlp.291/
-
[45]
Stepwise versus globally optimal search in children and adults.Cognition, 191:103965, 2019
Björn Meder, Jonathan D Nelson, Matt Jones, and Azzurra Ruggeri. Stepwise versus globally optimal search in children and adults.Cognition, 191:103965, 2019
2019
-
[46]
Owen-Shapley Policy Optimization: A Principled RL Algorithm for Generative Search LLMs
Abhijnan Nath, Alireza Bagheri Garakani, Tianchen Zhou, Fan Yang, and Nikhil Krishnaswamy. Owen-shapley policy optimization (ospo): A principled rl algorithm for generative search llms. arXiv preprint arXiv:2601.08403, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Pearson Education India, 1999
Alan V Oppenheim.Discrete-time signal processing. Pearson Education India, 1999
1999
-
[49]
Performative thinking? the brittle correlation between cot length and problem complexity
Vardhan Palod, Karthik Valmeekam, Kaya Stechly, and Subbarao Kambhampati. Performative thinking? the brittle correlation between cot length and problem complexity. InNeurIPS 2025 Workshop on Efficient Reasoning
2025
-
[50]
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[51]
The threshold approach to clinical decision making
Stephen G Pauker and Jerome P Kassirer. The threshold approach to clinical decision making. New England Journal of Medicine, 302(20):1109–1117, 1980
1980
-
[52]
Information foraging.Psychological review, 106(4):643, 1999
Peter Pirolli and Stuart Card. Information foraging.Psychological review, 106(4):643, 1999
1999
-
[53]
Stochastic backpropagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. InInternational conference on machine learning, pages 1278–1286. PMLR, 2014
2014
-
[54]
Do people ask good questions? Computational Brain & Behavior, 1(1):69–89, 2018
Anselm Rothe, Brenden M Lake, and Todd M Gureckis. Do people ask good questions? Computational Brain & Behavior, 1(1):69–89, 2018
2018
-
[55]
Local coherence or global validity? investigating rlvr traces in math domains,
Soumya Rani Samineni, Durgesh Kalwar, Vardaan Gangal, Siddhant Bhambri, and Subbarao Kambhampati. Local coherence or global validity? investigating rlvr traces in math domains,
- [56]
-
[57]
Rl in name only? analyzing the structural assumptions in rl post-training for llms, 2026
Soumya Rani Samineni, Durgesh Kalwar, Karthik Valmeekam, Kaya Stechly, and Subbarao Kambhampati. Rl in name only? analyzing the structural assumptions in rl post-training for llms, 2026. URLhttps://arxiv.org/abs/2505.13697
-
[58]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
2023
-
[59]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015. 13
2015
-
[60]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Active learning literature survey
Burr Settles. Active learning literature survey. 2009
2009
-
[62]
Communication in the presence of noise.Proceedings of the IRE, 37(1): 10–21, 2006
Claude E Shannon. Communication in the presence of noise.Proceedings of the IRE, 37(1): 10–21, 2006
2006
-
[63]
Jiaqi Shao, Yuxiang Lin, Munish Prasad Lohani, Yufeng Miao, and Bing Luo. Do llm agents know how to ground, recover, and assess? a benchmark for epistemic competence in information- seeking agents.arXiv preprint arXiv:2509.22391, 2025
-
[64]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
The optimal control of partially observable markov processes over a finite horizon.Operations research, 21(5):1071–1088, 1973
Richard D Smallwood and Edward J Sondik. The optimal control of partially observable markov processes over a finite horizon.Operations research, 21(5):1071–1088, 1973
1973
-
[66]
Large language model reasoning failures
Peiyang Song, Pengrui Han, and Noah Goodman. Large language model reasoning failures. arXiv preprint arXiv:2602.06176, 2026
-
[67]
Policy learning with a language bottleneck.arXiv preprint arXiv:2405.04118, 2024
Megha Srivastava, Cédric Colas, Dorsa Sadigh, and Jacob Andreas. Policy learning with a language bottleneck.arXiv preprint arXiv:2405.04118, 2024
-
[68]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018
2018
-
[69]
University of Massachusetts Amherst, 1984
Richard Stuart Sutton.Temporal credit assignment in reinforcement learning. University of Massachusetts Amherst, 1984
1984
-
[70]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist re- inforcement learning.Mach. Learn., 8(3–4):229–256, may 1992. ISSN 0885-6125. doi: 10.1007/BF00992696. URLhttps://doi.org/10.1007/BF00992696
-
[71]
Analyzing and mitigating interference in neural architecture search, 2021
Jin Xu, Xu Tan, Kaitao Song, Renqian Luo, Yichong Leng, Tao Qin, Tie-Yan Liu, and Jian Li. Analyzing and mitigating interference in neural architecture search, 2021
2021
-
[72]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[73]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[74]
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R Tomz, Christopher D Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity.arXiv preprint arXiv:2510.01171, 2025
-
[75]
Beyond markovian: Reflective exploration via bayes-adaptive rl for llm reasoning, 2025
Shenao Zhang, Yaqing Wang, Yinxiao Liu, Tianqi Liu, Peter Grabowski, Eugene Ie, Zhaoran Wang, and Yunxuan Li. Beyond markovian: Reflective exploration via bayes-adaptive rl for llm reasoning, 2025. URLhttps://arxiv.org/abs/2505.20561
-
[76]
BELLE: A bi-level multi-agent reasoning framework for multi-hop question answering
Taolin Zhang, Dongyang Li, Qizhou Chen, Chengyu Wang, and Xiaofeng He. BELLE: A bi-level multi-agent reasoning framework for multi-hop question answering. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[77]
Probing the multi-turn planning capabili- ties of LLMs via 20 question games
Yizhe Zhang, Jiarui Lu, and Navdeep Jaitly. Probing the multi-turn planning capabili- ties of LLMs via 20 question games. In Lun-Wei Ku, Andre Martins, and Vivek Sriku- mar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 1495–1516, Bangkok, Thailand, August
-
[78]
doi: 10.18653/v1/2024.acl-long.82
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.82. URL https://aclanthology.org/2024.acl-long.82/
-
[79]
The entity-deduction arena: A playground for probing the conversational reasoning and planning capabilities of LLMs, 2024
Yizhe Zhang, Jiarui Lu, and Navdeep Jaitly. The entity-deduction arena: A playground for probing the conversational reasoning and planning capabilities of LLMs, 2024. URL https://openreview.net/forum?id=PfrpYGKGPL
2024
-
[80]
Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning
Tiancheng Zhao and Maxine Eskenazi. Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning. InProceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 1–10, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.