CLIP: Lightweight Cosine-Law-Based Inverted-List Pruning for IVF-Based Vector Search
Pith reviewed 2026-06-30 03:50 UTC · model grok-4.3
The pith
CLIP prunes IVF clusters in constant time using monotonic cosine-law bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
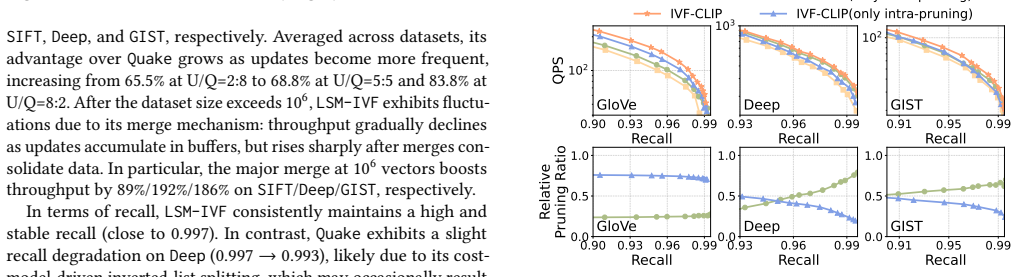
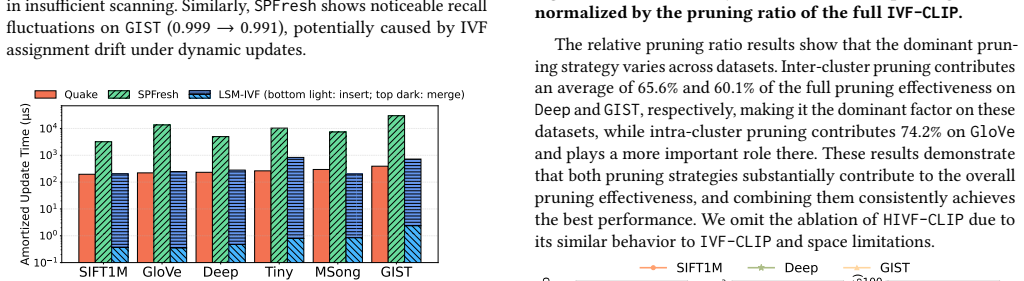
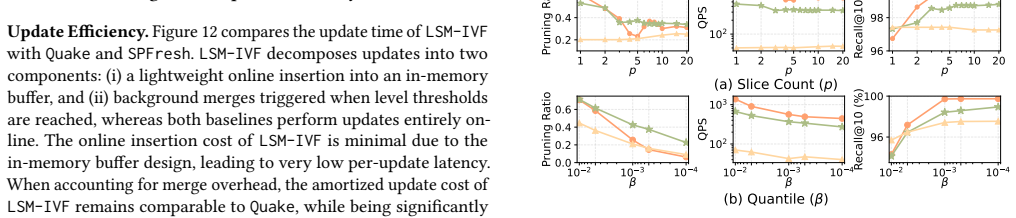
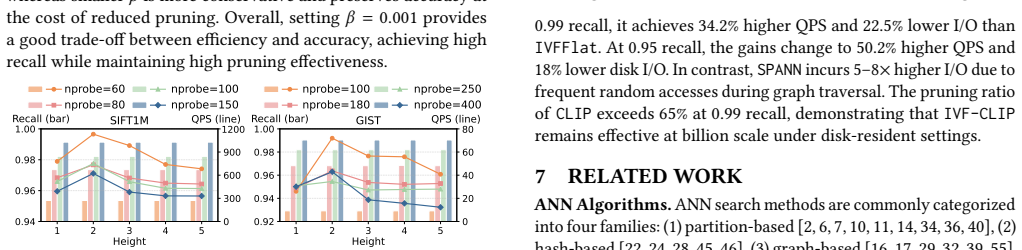
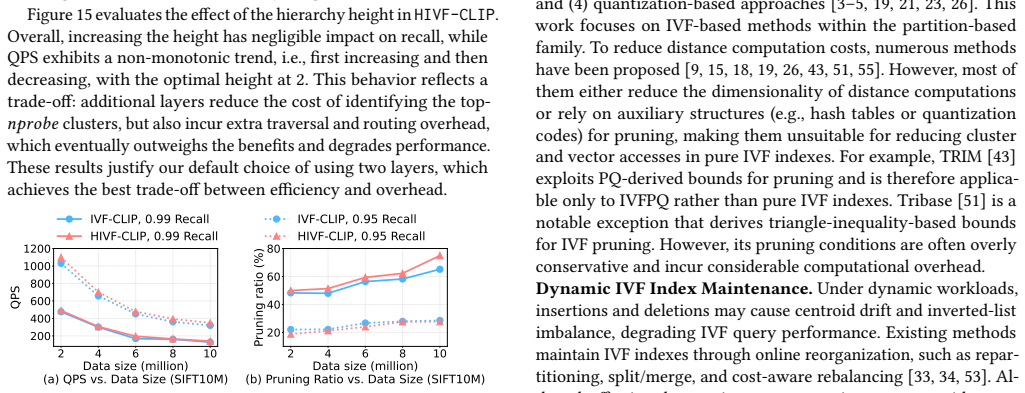
CLIP exploits the monotonicity of cosine-law-based lower bounds, enabling eliminating an undesirable cluster in O(1) time and filtering batches of irrelevant vectors in logarithmic time in the list size, with a tight analytical guarantee. This supports both inter-cluster and intra-cluster pruning inside IVF indexes while preserving correctness.
What carries the argument
Monotonicity of cosine-law-based lower bounds, which produces safe early rejection decisions for clusters and for vectors inside clusters.
If this is right
- IVF-CLIP applies the same bounds inside ordinary flat inverted files.
- HIVF-CLIP adds a hierarchy so that pruning can occur at multiple granularities.
- LSM-IVF defers index maintenance to background compaction while still using CLIP during queries.
- The methods report up to 78 percent pruning and 69 percent efficiency gain over static baselines and 141 percent throughput gain over dynamic baselines.
Where Pith is reading between the lines
- The same monotonic-bound idea could be tested on distance measures other than cosine.
- Because pruning decisions are cheap, the technique might allow larger probe lists without increasing latency.
- The LSM variant suggests that background compaction could be combined with other pruning rules that also avoid per-level searches.
Load-bearing premise
The cosine-law lower bounds stay monotonic and sufficiently tight on the vector distributions that arise in practice, so that no relevant result is ever pruned.
What would settle it
A concrete query and vector collection in which the lower-bound test discards a cluster that actually contains the nearest neighbor to the query.
Figures

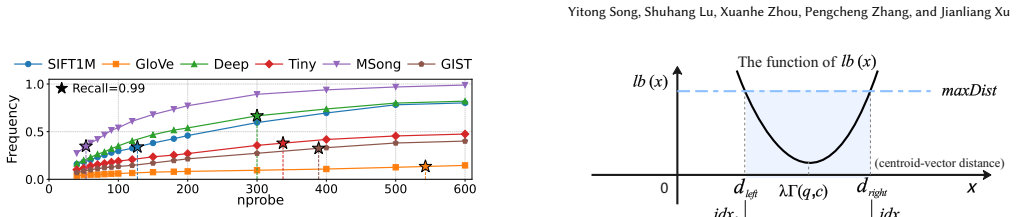
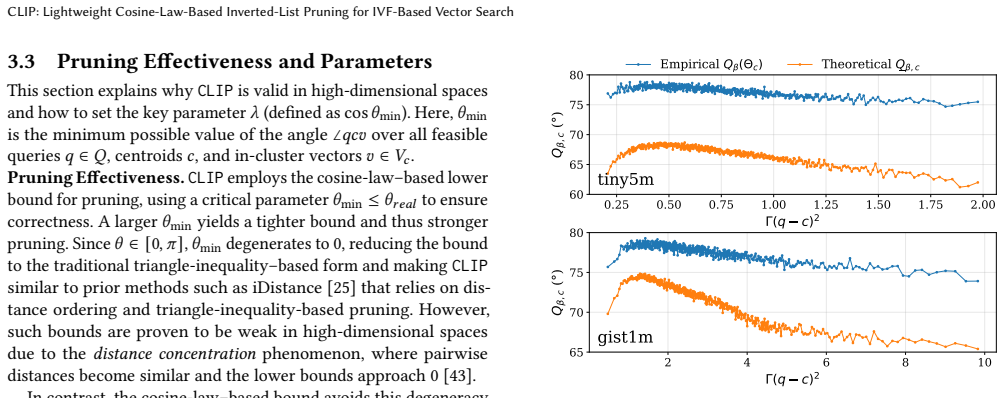
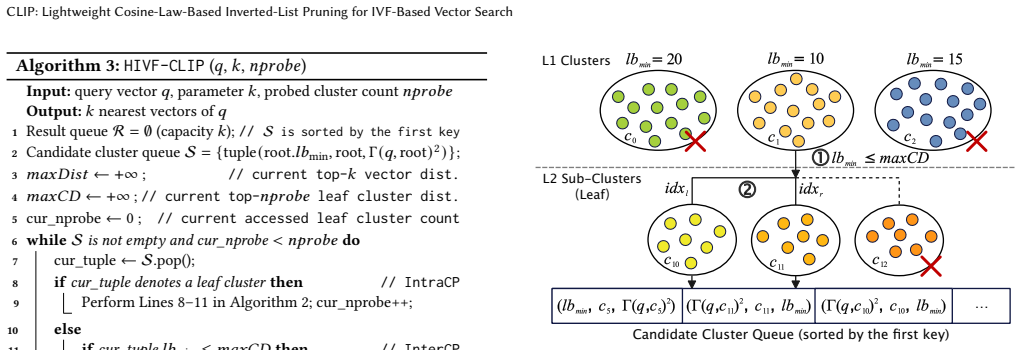
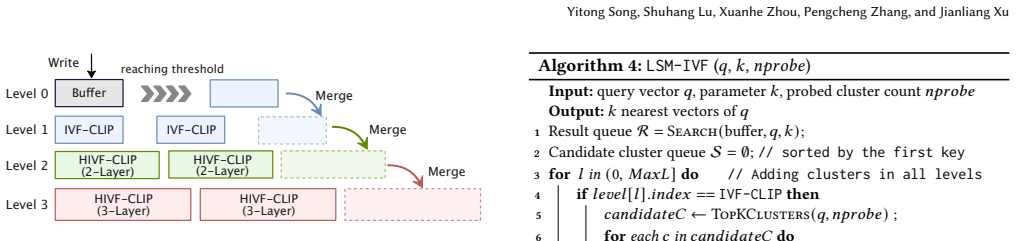


read the original abstract
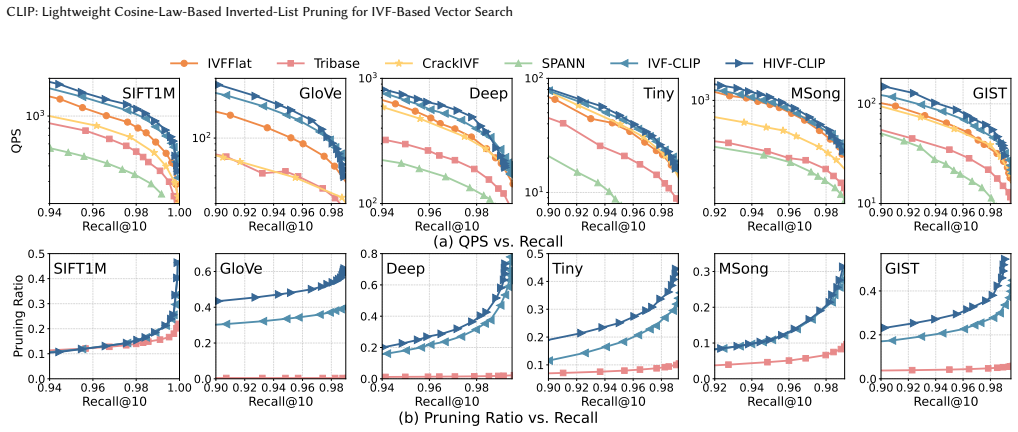
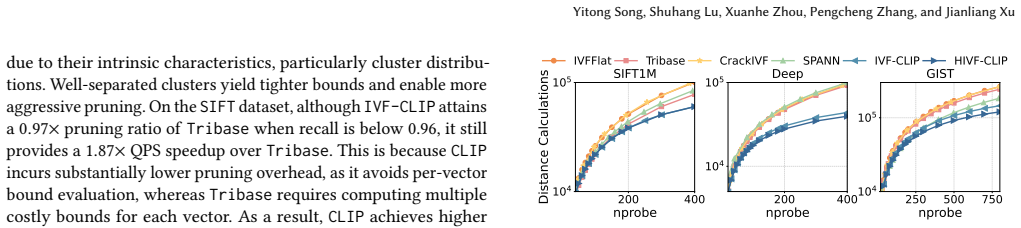
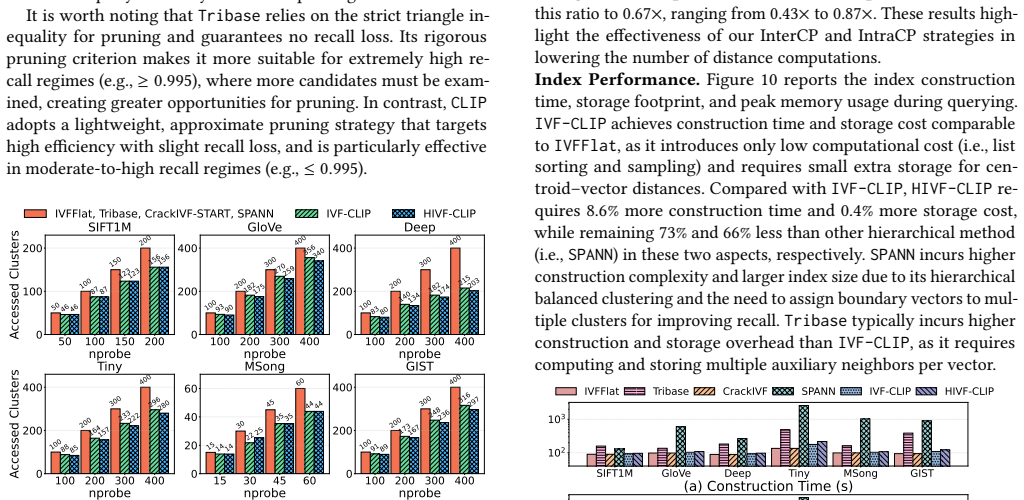
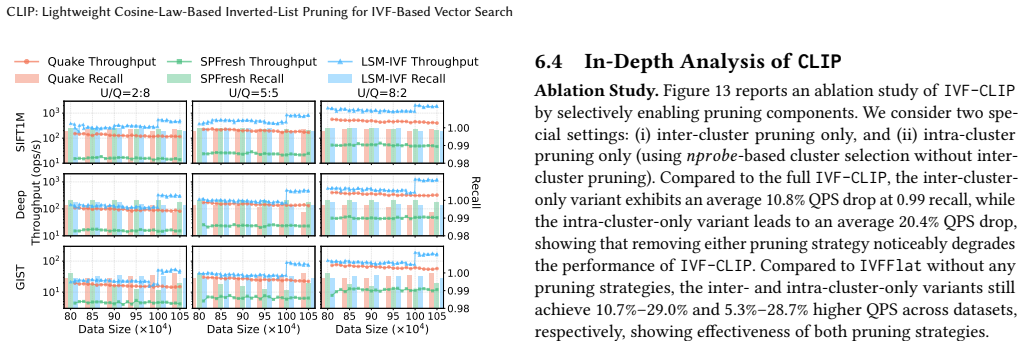
Vector search has become a core component of modern multimodal retrieval systems. Among existing methods, inverted file (IVF)-based methods are widely adopted due to their scalability, efficient updates, and hardware friendliness. However, they are fundamentally limited by coarse-grained execution: each query typically probes many clusters and exhaustively scans all vectors within them, resulting in high query latency. Prior works mitigate this using pruning strategies, but they often incur substantial extra pruning overhead, lack cluster-level pruning, and compromise update efficiency due to heavy maintenance of pruning metadata. This paper proposes CLIP, a lightweight cosine-law-based pruning technique that supports both inter- and intra-cluster pruning, substantially reducing unnecessary cluster and vector accesses with negligible overhead. First, CLIP exploits the monotonicity of cosine-law-based lower bounds, enabling eliminating an undesirable cluster in O(1) time and filtering batches of irrelevant vectors in logarithmic time in the list size, with a tight analytical guarantee. Second, building on this, we develop two IVF variants: IVF-CLIP, which integrates CLIP into IVFFlat, and HIVF-CLIP, which extends it with a hierarchical structure for adaptive sub-cluster probing. Third, for dynamic workloads, we present LSM-IVF, an LSM-inspired design that supports fast updates by deferring index maintenance to background compaction, and enables efficient queries via CLIP-based optimizations that eliminate costly level-by-level searches. Extensive experiments show that CLIP variants achieve up to 78% pruning and 69% higher efficiency over static IVF baselines, while LSM-IVF improves throughput by up to 141% over dynamic IVF baselines with comparable update efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLIP, a lightweight cosine-law-based pruning technique for IVF vector search that exploits monotonicity of lower bounds to eliminate undesirable clusters in O(1) time and filter batches of vectors in logarithmic time in the list size, backed by a tight analytical guarantee with no false negatives. It develops IVF-CLIP (integrated with IVFFlat) and HIVF-CLIP (with hierarchical sub-cluster probing), plus LSM-IVF for dynamic workloads using LSM-inspired deferred compaction and CLIP optimizations to avoid level-by-level searches. Experiments report up to 78% pruning, 69% higher efficiency over static IVF baselines, and up to 141% throughput improvement for LSM-IVF over dynamic baselines.
Significance. If the monotonicity-based bounds and analytical guarantee hold across the tested distributions without introducing false negatives, CLIP would provide a practical, low-overhead improvement to IVF indexes by enabling both inter- and intra-cluster pruning while preserving update efficiency. This addresses a core scalability bottleneck in multimodal retrieval. The parameter-free character of the bounds (no data-fitted quantities) and the LSM extension for dynamic settings are notable strengths that could influence production vector database designs.
minor comments (2)
- Abstract: the reported 'up to 78% pruning' and '69% higher efficiency' figures would be more informative if accompanied by average or per-dataset values rather than peak numbers alone.
- The description of the cosine-law lower bound monotonicity (central to the O(1) and log-time claims) would benefit from an explicit early definition or small illustrative example to make the pruning logic immediately accessible.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation of minor revision. The provided summary accurately captures the core ideas, guarantees, and experimental results of CLIP, including the monotonicity-based O(1) cluster pruning, logarithmic vector filtering, parameter-free bounds, HIVF-CLIP hierarchy, and LSM-IVF dynamic design. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation relies on the stated mathematical monotonicity and tightness of cosine-law-based lower bounds for O(1) cluster elimination and logarithmic vector filtering, presented as analytical properties independent of target data fits. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The approach is self-contained against external mathematical benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monotonicity of cosine-law-based lower bounds for pruning
Reference graph
Works this paper leans on
-
[1]
Blaise Agüera y Arcas, Beat Gfeller, Ruiqi Guo, Kevin Kilgour, Sanjiv Kumar, James Lyon, Julian Odell, Marvin Ritter, Dominik Roblek, Matthew Sharifi, and Mihajlo Velimirović. 2017. Now Playing: Continuous low-power music recogni- tion.NeurIPS(2017)
2017
-
[2]
Meta AI. 2017. FAISS. https://ai.facebook.com/tools/faiss
2017
-
[3]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2016. Cache locality is not enough: High-performance nearest neighbor search with product quantization fast scan.VLDB9, 4 (2016), 12
2016
-
[4]
Artem Babenko and Victor Lempitsky. 2014. Additive quantization for extreme vector compression.CVPR(2014), 931–938
2014
-
[5]
Artem Babenko and Victor Lempitsky. 2014. The inverted multi-index.IEEE TPAMI37, 6 (2014), 1247–1260
2014
-
[6]
Jon Louis Bentley. 1975. Multidimensional binary search trees used for associative searching.ACM Communications18, 9 (1975), 509–517
1975
-
[7]
Alina Beygelzimer, Sham Kakade, and John Langford. 2006. Cover trees for nearest neighbor.ICML(2006), 97–104
2006
-
[8]
Hsieh, Deborah A
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wal- lach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. 2006. Bigtable: A Distributed Storage System for Structured Data.OSDI(2006), 205– 218
2006
-
[9]
Patrick Chen, Wei-Cheng Chang, Jyun-Yu Jiang, Hsiang-Fu Yu, Inderjit Dhillon, and Cho-Jui Hsieh. 2023. Finger: Fast inference for graph-based approximate nearest neighbor search. InProceedings of the ACM Web Conference 2023. 3225– 3235
2023
-
[10]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. Spann: Highly-efficient billion-scale approximate nearest neighborhood search.NeurIPS34, 5199–5212
2021
-
[11]
Paolo Ciaccia, Marco Patella, and Pavel Zezula. 1997. M-tree: An efficient access method for similarity search in metric spaces.VLDB97 (1997), 426–435
1997
-
[12]
SPTAG Contributors. 2021. SPTAG-Library. https://github.com/microsoft/ SPTAG
2021
-
[13]
H. S. M. Coxeter. 1969.Introduction to Geometry(2nd ed.). John Wiley & Sons
1969
-
[14]
Sanjoy Dasgupta and Yoav Freund. 2008. Random projection trees and low dimensional manifolds.STOC(2008), 537–546
2008
- [15]
-
[16]
Cong Fu, Changxu Wang, and Deng Cai. 2021. High dimensional similarity search with satellite system graph: Efficiency, scalability, and unindexed query compatibility.IEEE TPAMI44, 8 (2021), 4139–4150
2021
-
[17]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast approximate nearest neighbor search with the navigating spreading-out graph. InPVLDB, Vol. 12. VLDB Endowment, 416–474
2019
-
[18]
Jianyang Gao and Cheng Long. 2023. High-dimensional approximate nearest neighbor search: with reliable and efficient distance comparison operations.ACM SIGMOD1, 2 (2023), 1–27
2023
-
[19]
Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search.ACM SIGMOD2, 3 (2024), 1–27
2024
- [20]
-
[21]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization for approximate nearest neighbor search.IEEE TPAMI(2013), 2946– 2953
2013
-
[22]
Long Gong, Huayi Wang, Mitsunori Ogihara, and Jun Xu. 2020. iDEC: indexable distance estimating codes for approximate nearest neighbor search.PVLDB13, 9 (2020)
2020
-
[23]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization.ICML(2020), 3887–3896
2020
-
[24]
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. 2015. Query-aware locality-sensitive hashing for approximate nearest neighbor search. PVLDB9, 1 (2015), 1–12
2015
-
[25]
Hosagrahar V Jagadish, Beng Chin Ooi, Kian-Lee Tan, Cui Yu, and Rui Zhang
-
[26]
iDistance: An adaptive B+-tree based indexing method for nearest neighbor search.ACM Transactions on Database Systems (TODS)30, 2 (2005), 364–397
2005
-
[27]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE TPAMI33, 1 (2010), 117–128
2010
-
[28]
K Krishna and M Narasimha Murty. 1999. Genetic K-means algorithm.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)29, 3 (1999), 433–439
1999
-
[29]
Jinfeng Li, Xiao Yan, Jian Zhang, An Xu, James Cheng, Jie Liu, Kelvin KW Ng, and Ti-chung Cheng. 2018. A general and efficient querying method for learning to hash.ACM SIGMOD(2018), 1333–1347
2018
-
[30]
Kejing Lu, Mineichi Kudo, Chuan Xiao, and Yoshiharu Ishikawa. 2021. HVS: hierarchical graph structure based on voronoi diagrams for solving approximate nearest neighbor search.PVLDB15, 2 (2021), 246–258
2021
-
[31]
Vasilis Mageirakos, Bowen Wu, and Gustavo Alonso. 2025. Cracking Vector Search Indexes.VLDB(2025), 3951–3964
2025
-
[32]
Vasilis Mageirakos, Bowen Wu, and Gustavo Alonso. 2025. crackivf-Library. https://github.com/mageirakos/crack-ivf-vldb
2025
-
[33]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE TPAMI42, 4 (2018), 824–836
2018
-
[34]
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Umar Farooq Minhas, Jeffery Pound, Cedric Renggli, Nima Reyhani, Ihab F Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman. 2024. Incremental IVF Index Maintenance for Streaming Vector Search.arXiv preprint arXiv:2411.00970(2024)
- [35]
-
[36]
Jason Mohoney, Devesh Sarda, Mengze Tang, Shihabur Rahman Chowdhury, Anil Pacaci, Ihab F Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman
-
[37]
https://github.com/marius-team/quake
Quake-Library. https://github.com/marius-team/quake
-
[38]
Marius Muja and David G Lowe. 2014. Scalable nearest neighbor algorithms for high dimensional data.IEEE TPAMI36, 11 (2014), 2227–2240
2014
-
[39]
Zhaojie Niu, Xinhui Tian, Xindong Peng, and Xing Chen. 2025. BlendHouse: A Cloud-Native Vector Database System in ByteHouse.IEEE ICDE(2025), 4332– 4345
2025
-
[40]
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. 1996. The log-structured merge-tree (LSM-tree).Acta informatica33, 4 (1996), 351–385
1996
-
[41]
Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases. ACM SIGMOD1, 1 (2023), 1–27
2023
-
[42]
Jeffrey Pound, Floris Chabert, Arjun Bhushan, Ankur Goswami, Anil Pacaci, and Shihabur Rahman Chowdhury. 2025. MicroNN: An On-device Disk-resident Updatable Vector Database. InCompanion of the 2025 International Conference on Management of Data. 608–621
2025
-
[43]
Yong Rui, Thomas S Huang, and Shih-Fu Chang. 1999. Image retrieval: Current techniques, promising directions, and open issues.Journal of visual communica- tion and image representation10, 1 (1999), 39–62
1999
-
[44]
Russell Sears and Raghu Ramakrishnan. 2012. bLSM: a general purpose log structured merge tree.ACM SIGMOD(2012), 217–228
2012
-
[45]
Yitong Song, Pengcheng Zhang, Chao Gao, Bin Yao, Kai Wang, Zongyuan Wu, and Lin Qu. 2025. TRIM: Accelerating High-Dimensional Vector Similarity Search with Enhanced Triangle-Inequality-Based Pruning.ACM SIGMOD(2025), 1–26
2025
-
[46]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.PVLDB18, 12 (2025), 4951–4963
2025
-
[47]
Yifang Sun, Wei Wang, Jianbin Qin, Ying Zhang, and Xuemin Lin. 2014. SRS: solving c-approximate nearest neighbor queries in high dimensional euclidean space with a tiny index.PVLDB(2014)
2014
-
[48]
Yufei Tao, Ke Yi, Cheng Sheng, and Panos Kalnis. 2010. Efficient and accurate nearest neighbor and closest pair search in high-dimensional space.ACM TODS 35, 3 (2010), 1–46
2010
-
[49]
2018.High-Dimensional Probability: An Introduction with Applications in Data Science
Roman Vershynin. 2018.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, Cambridge, UK
2018
-
[50]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system.ACM SIGMOD(2021), 2614–2627
2021
- [51]
-
[52]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. Analyticdb-v: A hybrid analytical engine towards query fusion for structured and unstructured data.PVLDB13, 12 (2020), 3152–3165
2020
-
[53]
Qian Xu, Juan Yang, Feng Zhang, Junda Pan, Kang Chen, Youren Shen, Amelie Chi Zhou, and Xiaoyong Du. 2025. Tribase: A Vector Data Query Engine for Reliable and Lossless Pruning Compression using Triangle Inequalities.ACM SIGMOD3, 1 (2025), 1–28
2025
-
[54]
Qian Xu, Juan Yang, Feng Zhang, Junda Pan, Kang Chen, Youren Shen, Amelie Chi Zhou, and Xiaoyong Du. 2025. Tribase-Library. https://github. com/xuqianmamba/Tribase
2025
-
[55]
Yuming Xu, Hengyu Liang, Jin Li, Shuotao Xu, Qi Chen, Qianxi Zhang, Cheng Li, Ziyue Yang, Fan Yang, Yuqing Yang, et al. 2023. Spfresh: Incremental in-place update for billion-scale vector search.SOSP(2023), 545–561
2023
-
[56]
Rex Ying, Ruining He, Kaifei Chen, Pong Eksombatchai, William Hamilton, and Jure Leskovec. 2018. PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest.ACM SIGKDD(2018). Yitong Song, Shuhang Lu, Xuanhe Zhou, Pengcheng Zhang, and Jianliang Xu
2018
-
[57]
Xi Zhao, Yao Tian, Kai Huang, Bolong Zheng, and Xiaofang Zhou. 2023. Towards Efficient Index Construction and Approximate Nearest Neighbor Search in High- Dimensional Spaces.PVLDB16, 8 (2023), 1979–1991
2023
-
[58]
Shurui Zhong, Dingheng Mo, and Siqiang Luo. 2025. LSM-VEC: A Large-Scale Disk-Based System for Dynamic Vector Search.arXiv preprint arXiv:2505.17152 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.