Optimal-Time Contextual Pattern Matching in Compressed Space
Pith reviewed 2026-07-01 03:43 UTC · model grok-4.3
The pith
Contextual pattern matching now runs in optimal O(m + occ) time using only the compressed space of a symmetric CDAWG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a symmetric CDAWG of T, together with an improved linear-space distance-sensitive weighted ancestor data structure, solves contextual pattern matching in optimal O(m + occ) time and permits enumeration of the occ solutions with O(log log λ) delay after O(m)-time preprocessing of P.
What carries the argument
The symmetric CDAWG (SCDAWG) of T, which encodes the text compactly and turns contextual matching into weighted ancestor queries answered by the new distance-sensitive structure.
If this is right
- Any text collection that already stores a symmetric CDAWG can answer contextual queries without extra asymptotic space.
- The occ distinct contexts around a pattern can be listed after only linear work in the pattern length.
- The improved ancestor structure is presented as a general tool that the matching reduction relies on.
Where Pith is reading between the lines
- The same SCDAWG-plus-ancestor combination may extend to other context-sensitive queries that reduce to path or ancestor navigation.
- If the ancestor structure generalizes beyond CDAWGs, it could improve compressed solutions for related string problems such as approximate matching with contexts.
Load-bearing premise
The new linear-space weighted ancestor data structure delivers the query times required when run on the SCDAWG.
What would settle it
An input where the ancestor queries on the SCDAWG take more than O(1) or O(log log λ) time per output, causing the overall solution to exceed O(m + occ) or the stated enumeration delay.
Figures
read the original abstract
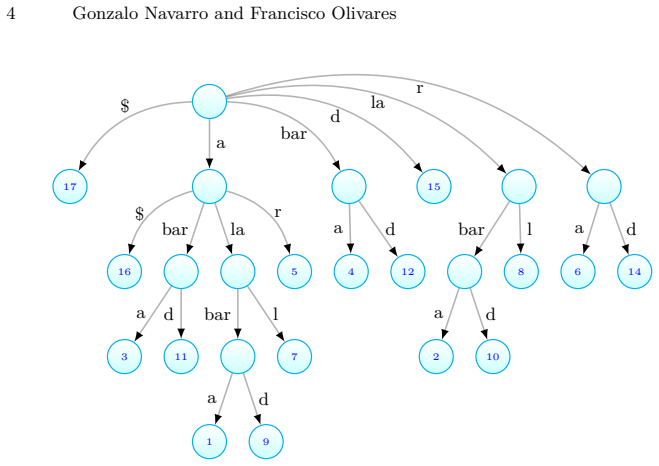
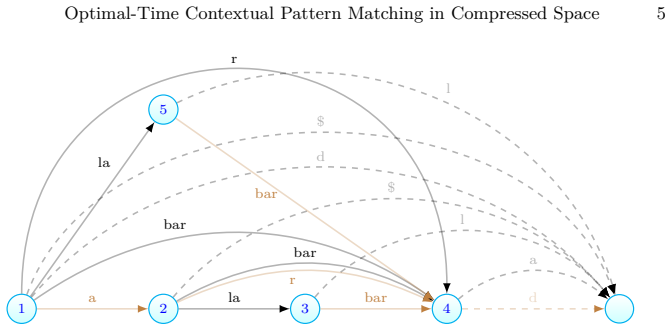
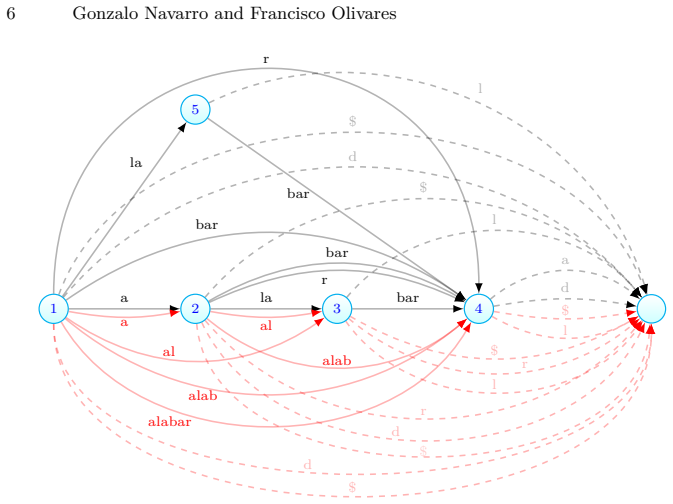
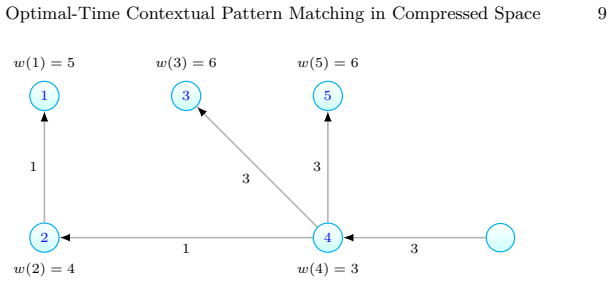
Contextual pattern matching is the task of, given a pattern $P[1,m]$, a context length $\lambda$, and a text $T[1,n]$, find all the $occ$ distinct contexts in which $P$ occurs in $T$, the context being the $\lambda$ symbols preceding and the $\lambda$ symbols following the occurrence; a text position where each context occurs must be output. While the problem can be solved in optimal time $O(m+occ)$ using $O(n)$-space precomputed data structures on $T$, this type of search is particularly relevant on large repetitive text collections, where $O(n)$ space can be prohibitive. We present the first optimal-time solution that runs in compressed space, namely that of a symmetric CDAWG (SCDAWG) of $T$. Further, we show how the set of $occ$ solutions can be enumerated with $O(\log\log\lambda)$ delay after $O(m)$-time preprocessing of $P$. To achieve this, we develop an improved linear-space distance-sensitive weighted ancestor data structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to give the first optimal-time O(m + occ) algorithm for contextual pattern matching (reporting distinct λ-contexts around occurrences of P in T, together with a witness position per context) that uses only the compressed space of a symmetric CDAWG of T. The solution reduces the problem to a sequence of weighted-ancestor queries on the SCDAWG; an improved linear-space distance-sensitive weighted-ancestor structure is introduced to realize the stated time bounds. In addition, the occ solutions can be enumerated with O(log log λ) delay after O(m) preprocessing of P.
Significance. If the claimed time and space bounds hold, the result would be a notable advance in compressed stringology: it matches the uncompressed optimal time for a problem that is natural on large repetitive collections while staying within the space of the SCDAWG. The new distance-sensitive weighted-ancestor structure is presented as a reusable primitive and could have independent value.
minor comments (1)
- The abstract states that the SCDAWG occupies 'compressed space' but does not explicitly recall its asymptotic size in terms of the number of right- and left-contexts; a one-sentence reminder would help readers who are not already familiar with CDAWGs.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and for recommending acceptance. We are pleased that the contribution is viewed as a notable advance in compressed stringology and that the new weighted-ancestor structure is recognized as potentially reusable.
Circularity Check
No significant circularity
full rationale
The paper describes an algorithmic construction reducing contextual pattern matching to weighted ancestor queries on an SCDAWG plus a new linear-space distance-sensitive data structure. No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear in the abstract or described claims. The derivation is a standard algorithmic reduction to existing string data structures and one new primitive; it does not reduce any central claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The symmetric CDAWG of T supports the required ancestor and context queries in the time bounds needed for optimality.
- domain assumption An improved linear-space distance-sensitive weighted ancestor structure exists and can be built on the SCDAWG.
Reference graph
Works this paper leans on
-
[1]
Computing matching statistics on wheeler dfas
Abedin, P., Chubet, O., Gibney, D., Thankachan, S.V.: Contextual pattern match- ing in less space. In: 2023 Data Compression Conference (DCC). pp. 160–167 (2023). https://doi.org/10.1109/DCC55655.2023.00024
-
[2]
In: Proc
Adamson, D., Gawrychowski, P., Manea, F.: Enumerating m-length walks in di- rected graphs with constant delay. In: Proc. 16th Latin American Symposium on Theoretical Informatics, Part I. pp. 35–50 (2024)
2024
-
[3]
Predecessor search with distance-sensitive query time
Belazzougui, D., Boldi, P., Vigna, S.: Predecessor search with distance-sensitive query time. CoRR 1209.5441 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
In: Fici, G., Sciortino, M., Venturini, R
Belazzougui, D., Cunial, F.: Fast label extraction in the cdawg. In: Fici, G., Sciortino, M., Venturini, R. (eds.) String Processing and Information Retrieval. pp. 161–175. Springer International Publishing, Cham (2017)
2017
-
[5]
Belazzougui, D., Kosolobov, D., Puglisi, S.J., Raman, R.: Weighted ancestors in suffix trees revisited. In: Proc. 32nd Annual Symposium on Combinatorial Pattern Matching (CPM). pp. 8:1–8:15 (2021). https://doi.org/10.4230/LIPIcs.CPM.2021. 8
-
[6]
Journal of the ACM 34(3), 578–595 (1987)
Blumer, A., Blumer, J., Haussler, D., McConnell, R.M., Ehrenfeucht, A.: Complete inverted files for efficient text retrieval and analysis. Journal of the ACM 34(3), 578–595 (1987)
1987
-
[7]
In: Proc
Farach, M., Muthukrishnan, S.: Perfect hashing for strings: Formalization and al- gorithms. In: Proc. 7th Annual Symposium on Combinatorial Pattern Matching (CPM). pp. 130–140 (1996)
1996
-
[8]
Journal of Computer and Systems Science 47(3), 424–436 (1993)
Fredman, M., Willard, D.: Surpassing the information theoretic bound with fusion trees. Journal of Computer and Systems Science 47(3), 424–436 (1993)
1993
-
[9]
Journal of the ACM 31(3), 538–544 (1984)
Fredman, M.L., Komlós, J., Szemerédi, E.: Storing a sparse table with O(1) worst case access time. Journal of the ACM 31(3), 538–544 (1984)
1984
-
[10]
Gawrychowski, P., Lewenstein, M., Nicholson, P.: Weighted ancestors in suffix trees. In: Proc. 22nd Annual European Symposium on Algorithms (ESA). pp. 455–466 (2014). https://doi.org/10.1007/978-3-662-44777-2_38 Optimal-Time Contextual Pattern Matching in Compressed Space 13
-
[11]
Inenaga, S., Hoshino, H., Shinohara, A., Takeda, M., Arikawa, S.: On-line con- struction of symmetric compact directed acyclic word graphs. In: Proc. 8th Sympo- sium on String Processing and Information Retrieval (SPIRE). pp. 96–110 (2001). https://doi.org/10.1109/SPIRE.2001.989743
-
[12]
Kopelowitz, T., Lewenstein, M.: Dynamic weighted ancestors. pp. 565–574 (2007)
2007
-
[13]
Manber, U., Myers, E.W.: Suffix arrays: A new method for on-line string searches. SIAM J. Comput. 22(5), 935–948 (1993). https://doi.org/10.1137/0222058
-
[14]
Journal of the ACM 23(2), 262–272 (1976)
McCreight, E.: A space-economical suffix tree construction algorithm. Journal of the ACM 23(2), 262–272 (1976)
1976
-
[15]
SIAM Journal on Computing 31(3), 762–776 (2001)
Munro, J.I., Raman, V.: Succinct representation of balanced parentheses and static trees. SIAM Journal on Computing 31(3), 762–776 (2001)
2001
-
[16]
ACM Computing Surveys 54(2), article 26 (2021)
Navarro, G.: Indexing highly repetitive string collections, part II: Compressed in- dexes. ACM Computing Surveys 54(2), article 26 (2021)
2021
-
[17]
In: Proc
Navarro, G.: Contextual pattern matching. In: Proc. String Processing and Infor- mation Retrieval. pp. 3–10 (2020)
2020
-
[18]
CoRR 2010.07076 (2020), https:// arxiv.org/abs/2010.07076
Navarro, G.: Contextual pattern matching. CoRR 2010.07076 (2020), https:// arxiv.org/abs/2010.07076
-
[19]
ACM Computing Surveys 54(2), article 29 (2021)
Navarro, G.: Indexing highly repetitive string collections, part I: Repetitiveness measures. ACM Computing Surveys 54(2), article 29 (2021)
2021
-
[20]
Algorithmica 14(3), 249–260 (1995)
Ukkonen, E.: On-line construction of suffix trees. Algorithmica 14(3), 249–260 (1995)
1995
-
[21]
In: Proc
Weiner, P.: Linear pattern matching algorithm. In: Proc. 14th Annual IEEE Sym- posium on Switching and Automata Theory. pp. 1–11 (1973)
1973
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.