GenPage: Towards End-to-End Generative Homepage Construction at Netflix
Pith reviewed 2026-07-01 04:49 UTC · model grok-4.3
The pith
A single transformer generates the full Netflix homepage from user context and beats the existing multi-stage recommender on engagement and latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single transformer pretrained on production homepages and post-trained via weighted binary classification or reinforcement learning can generate complete, structured Netflix homepages that deliver higher user engagement than a mature, highly optimized multi-stage production recommender while also reducing serving latency.
What carries the argument
A single transformer that receives user and request context as a prompt and autoregressively generates the structured multi-row homepage.
If this is right
- The end-to-end generative model reduces serving latency by 20 percent compared with the multi-stage stack.
- Weighted binary classification post-training produces a statistically significant 0.24 percent lift on the core engagement metric used for launch decisions.
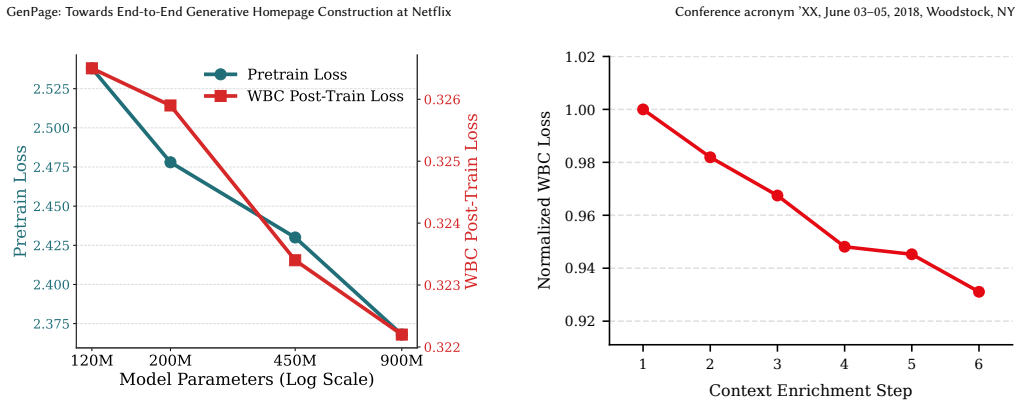
- Enriching the input prompt improves results more than increasing model capacity in the current operating regime.
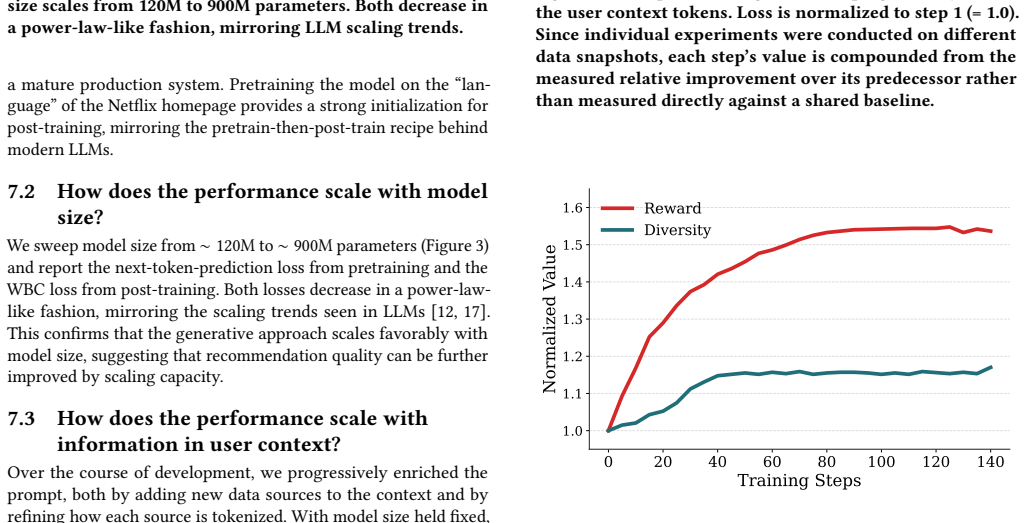
- Reinforcement learning post-training raises homepage diversity even though diversity is absent from the training objective.
Where Pith is reading between the lines
- The same prompt-plus-autoregressive-generation pattern could be tested on other personalized layouts such as search results pages or watch-next carousels.
- The business-rule enforcement methods developed for generation may transfer to other large-language-model content systems that must obey editorial constraints.
- The finding that prompt quality matters more than scale suggests production teams could prioritize data and context engineering over ever-larger models.
- Longer-horizon experiments tracking retention and complaint rates would test whether the short-term lift persists or introduces unseen trade-offs.
Load-bearing premise
The A/B test environment and metric capture long-term user value without hidden negative effects on content quality, business-rule compliance, or user retention that would appear outside the test window.
What would settle it
A follow-up measurement showing lower user retention or degraded content-quality signals after the A/B test window closes would show the reported engagement lift does not translate to sustained value.
Figures
read the original abstract
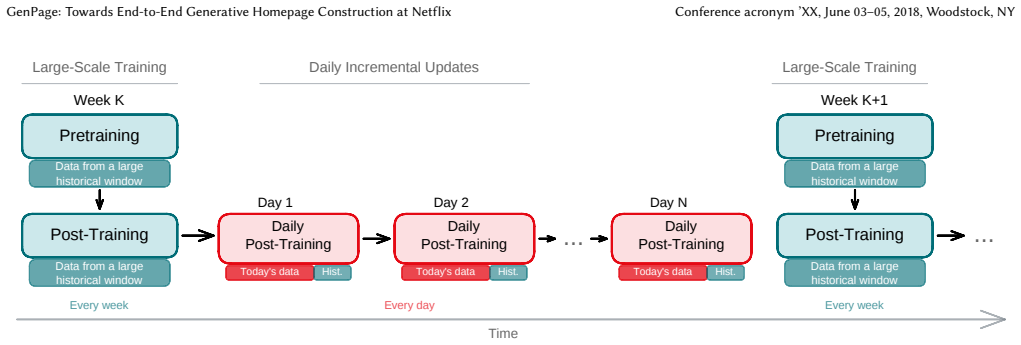
We present GenPage, an end-to-end generative approach to Netflix homepage construction that replaces the traditional multi-stage recommender stack with a single transformer. GenPage treats the user and request context as a prompt, and autoregressively generates the entire structured, multi-row homepage as the response. We adapt the LLM training recipe: pretraining on production pages, followed by post-training via weighted binary classification (WBC) or reinforcement learning (RL). For industry-scale deployment, we introduce techniques addressing cold start, model freshness, business-rule enforcement, and serving efficiency. In online A/B tests against a mature, highly optimized production homepage recommender, the WBC variant of GenPage delivered a +0.24% lift on the core user engagement metric we use for launch decisions (p < 0.001), while reducing end-to-end serving latency by 20%. Offline, two findings stand out: enriching the prompt yields a larger improvement than scaling model capacity in our current regime, and RL post-training increases homepage diversity even though diversity is not part of the objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GenPage, an end-to-end generative system that replaces Netflix's multi-stage homepage recommender with a single transformer. User/request context is treated as a prompt; the model autoregressively generates the full structured, multi-row page. Training consists of pretraining on production pages followed by post-training via weighted binary classification (WBC) or reinforcement learning (RL). Deployment techniques address cold-start, freshness, business-rule compliance, and latency. The central empirical claim is that the WBC variant yields a +0.24% lift (p<0.001) on the core engagement metric used for launch decisions and a 20% reduction in end-to-end serving latency versus the production baseline; two offline observations are also reported concerning prompt enrichment versus model scale and RL-induced diversity.
Significance. If the A/B result is robust, the work demonstrates that a single generative model can match or exceed a mature multi-stage production recommender while cutting latency, which would be a meaningful simplification for industrial recommendation systems. The offline finding that prompt quality outweighs capacity scaling in the current regime is also of practical interest. No machine-checked proofs or fully reproducible artifacts are provided.
major comments (2)
- [§5] §5 (Online Experiments): The headline claim of a +0.24% lift (p<0.001) on the core engagement metric is load-bearing for the paper's assertion of superiority over production, yet the section supplies no test duration, cohort size, variance estimates, exclusion criteria, or auxiliary metrics (e.g., retention, content-quality proxies, or business-rule violations). Without these, the mapping from short-term metric to launch decision cannot be evaluated.
- [§5.1] §5.1 (WBC variant results): The manuscript does not report whether the engagement metric was monitored for negative correlations with long-term retention or downstream business outcomes outside the test window; this assumption is required to treat the observed lift as sufficient evidence for deployment.
minor comments (2)
- [Abstract / §4] The abstract and §4 would benefit from a concise table summarizing the two post-training methods (WBC vs. RL) and their respective objectives and observed effects.
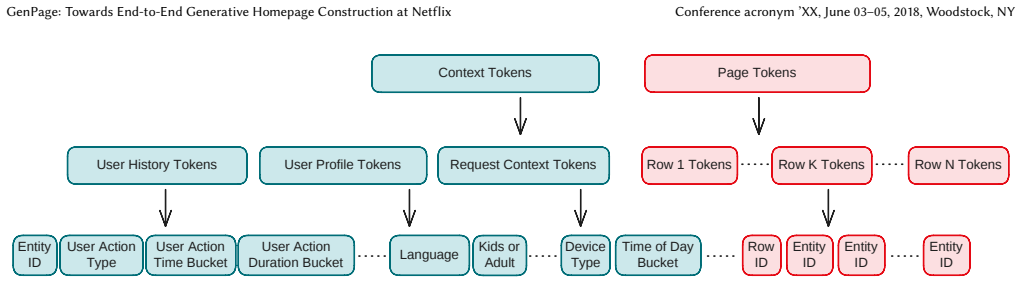
- [§3] Notation for the autoregressive generation of structured rows (e.g., row-type tokens, item tokens) is introduced without an explicit schema or example in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical evaluation. We address each major comment below and will revise the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [§5] §5 (Online Experiments): The headline claim of a +0.24% lift (p<0.001) on the core engagement metric is load-bearing for the paper's assertion of superiority over production, yet the section supplies no test duration, cohort size, variance estimates, exclusion criteria, or auxiliary metrics (e.g., retention, content-quality proxies, or business-rule violations). Without these, the mapping from short-term metric to launch decision cannot be evaluated.
Authors: We agree that §5 would benefit from additional experimental context. In the revised manuscript we will expand the section to report test duration (multi-week window), approximate cohort scale (tens of millions of users), exclusion criteria (standard filters for new or low-activity accounts), and variance estimation method (bootstrap-based standard errors for the large-scale test). We will also note that auxiliary monitoring included retention proxies and business-rule compliance, with no material negative signals observed. Precise numerical cohort and duration values remain subject to internal confidentiality limits and will be described at a high level only. revision: yes
-
Referee: [§5.1] §5.1 (WBC variant results): The manuscript does not report whether the engagement metric was monitored for negative correlations with long-term retention or downstream business outcomes outside the test window; this assumption is required to treat the observed lift as sufficient evidence for deployment.
Authors: We acknowledge the importance of this check. Internal post-test analyses did examine correlations between the core engagement lift and retention metrics over the available observation window; no statistically significant negative relationships were detected. In the revision we will add a brief statement in §5.1 summarizing this finding while noting that longer-horizon retention effects continue to be monitored outside the reported test window. revision: yes
Circularity Check
No circularity; empirical A/B result independent of training inputs
full rationale
The paper's central claim is a measured +0.24% lift (p<0.001) from online A/B tests of the WBC-trained GenPage model against a production recommender, plus a 20% latency reduction. Pretraining on production pages and WBC/RL post-training are standard supervised steps whose outputs are then evaluated externally; the A/B metric lift is not obtained by fitting a parameter to the same data and relabeling it a prediction, nor by any self-referential equation or uniqueness theorem. No load-bearing self-citation chain or ansatz smuggling is visible in the provided text. The result is therefore self-contained against the external benchmark of live traffic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prabhat Agarwal, Anirudhan Badrinath, Laksh Bhasin, Jaewon Yang, Edoardo Botta, Jiajing Xu, and Charles Rosenberg. 2025. PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems. arXiv:2504.10507 [cs.IR] arXiv:2504.10507
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Charles, D
Léon Bottou, Jonas Peters, Joaquin Quinonero-Candela, Denis X. Charles, D. Max Chickering, Elon Portugaly, Dipankar Ray, Patrice Simard, and Ed Snelson. 2013. Counterfactual Reasoning and Learning Systems: The Example of Computational Advertising.Journal of Machine Learning Research14 (2013), 3207–3260
2013
-
[3]
Minmin Chen, Alex Beutel, Paul Covington, Sagar Jain, Francois Belletti, and Ed H Chi. 2019. Top-k off-policy correction for a REINFORCE recommender system. InProceedings of the twelfth ACM international conference on web search and data mining. 456–464
2019
-
[4]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[5]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
-
[6]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep Reinforcement Learning from Human Preferences. In Advances in Neural Information Processing Systems (NeurIPS)
2017
-
[7]
2022.Click models for web search
Aleksandr Chuklin, Ilya Markov, and Maarten De Rijke. 2022.Click models for web search. Springer Nature
2022
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys ’16). ACM
2016
-
[9]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). InProceedings of the 16th ACM Conference on Recommender Systems (RecSys)
2022
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[11]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, Xinyang Yi, Lexi Baugher, Baykal Cakici, Ed Chi, Cristos Goodrow, Ningren Han, He Ma, Romer Rosales, Abby Van Soest, Devansh Tandon, Su-Lin Wu, Wei- long Yang, and Yilin Zheng. 2025. PLUM: Adapting Pre-trained Lang...
-
[12]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[13]
In International Conference on Learning Representations (ICLR)
Session-Based Recommendations with Recurrent Neural Networks. In International Conference on Learning Representations (ICLR)
-
[14]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models.arXiv preprint arXiv:2203.1555610 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Yanhua Huang, Yuqi Chen, Xiong Cao, Rui Yang, Mingliang Qi, Yinghao Zhu, Qingchang Han, Yaowei Liu, Zhaoyu Liu, Xuefeng Yao, Yuting Jia, Leilei Ma, Yinqi Zhang, Taoyu Zhu, Liujie Zhang, Lei Chen, Weihang Chen, Min Zhu, Ruiwen Xu, and Lei Zhang. 2025. Towards Large-Scale Generative Ranking. arXiv:2505.04180 [cs.IR] arXiv:2505.04180; Xiaohongshu RankGPT Team
-
[16]
Hakan Inan, Khashayar Khosravi, and Richard Socher. 2016. Tying word vectors and word classifiers: A loss framework for language modeling.arXiv preprint arXiv:1611.01462(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Thorsten Joachims, Ben London, Yi Su, Adith Swaminathan, and Lequn Wang
-
[18]
Recommendations as treatments.AI Magazine42, 3 (2021), 19–30
2021
-
[19]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. InIEEE International Conference on Data Mining (ICDM)
2018
-
[20]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
-
[22]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conserva- tive q-learning for offline reinforcement learning.Advances in neural information processing systems33 (2020), 1179–1191
2020
-
[23]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InACM Symposium on Operating Systems Principles (SOSP)
2023
-
[24]
Mingfu Liang, Yufei Li, Jay Xu, Kavosh Asadi, Xi Liu, Shuo Gu, Kaushik Rangadu- rai, Frank Shyu, Shuaiwen Wang, Song Yang, et al. 2026. Generative Reasoning Re-ranker.arXiv preprint arXiv:2602.07774(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. Understanding r1-zero-like training: A critical perspective. InConference on Language Modeling (COLM)
2025
-
[26]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training Language Models to Follow Instructions with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[27]
Ofir Press and Lior Wolf. 2017. Using the output embedding to improve language models. InProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. 157–163
2017
-
[28]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[29]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[30]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[31]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Rad- ford, Mark Chen, and Ilya Sutskever. 2021. Zero-Shot Text-to-Image Generation. InInternational Conference on Machine Learning (ICML)
2021
-
[32]
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, et al . 2021. Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences.Proceedings of the National Academy of Sciences118, 15 (2021), e2016239118
2021
-
[33]
Hunter, Costas Bekas, and Alpha A
Philippe Schwaller, Teodoro Laino, Théophile Gaudin, Peter Bolgar, Christo- pher A. Hunter, Costas Bekas, and Alpha A. Lee. 2019. Molecular Transformer: A Model for Uncertainty-Calibrated Chemical Reaction Prediction.ACS Central Science5, 9 (2019), 1572–1583
2019
-
[34]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. HybridFlow: A Flexible and Effi- cient RLHF Framework. InEuropean Conference on Computer Systems (EuroSys)
2025
-
[35]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. AI Models Collapse When Trained on Recursively Generated Data.Nature631, 8022 (2024), 755–759
2024
-
[36]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[37]
InACM International Conference on Information and Knowledge Management (CIKM)
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Repre- sentations from Transformer. InACM International Conference on Information and Knowledge Management (CIKM)
-
[38]
Adith Swaminathan and Thorsten Joachims. 2015. Batch learning from logged bandit feedback through counterfactual risk minimization.The Journal of Machine Learning Research16, 1 (2015), 1731–1755. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Wang et al
2015
-
[39]
Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dudik, John Langford, Damien Jose, and Imed Zitouni. 2017. Off-Policy Evaluation for Slate Recommendation. InAdvances in Neural Information Processing Systems (NeurIPS)
2017
-
[40]
Gary Tang, Jiangwei Pan, Henry Wang, and Justin Basilico. 2023. Reward In- novation for Long-Term Member Satisfaction. InProceedings of the 17th ACM Conference on Recommender Systems (RecSys ’23). ACM
2023
-
[41]
Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W
Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer Memory as a Differentiable Search Index. In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[42]
2009.Discrete choice methods with simulation
Kenneth E Train. 2009.Discrete choice methods with simulation. Cambridge university press
2009
-
[43]
Alicia Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed H Chi, and Xinyang Yi. 2024. Leveraging llm reasoning enhances personalized recommender systems. InFindings of the Asso- ciation for Computational Linguistics: ACL 2024. 13176–13188
2024
-
[44]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InInternational Conference on Machine Learning (ICML)
2024
-
[45]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. OneRec-V2 Technical Report.arXiv preprint arXiv:2508.20900(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.