AtomiMed: Hierarchical Atomic Fact-Checking for Universal Clinical-Aware Medical Report Evaluation
Pith reviewed 2026-07-01 03:24 UTC · model grok-4.3
The pith
AtomiMed improves medical report evaluation by decomposing narratives into hierarchical atomic clinical facts and cross-verifying them to separate detection from description accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that breaking medical narratives into a multi-level hierarchy of Atomic Clinical Facts, with disease-level entities and attribute-level descriptors, followed by agentic cross-verification, decouples diagnostic detection accuracy from descriptive accuracy and produces evaluation scores that align more closely with human radiologist judgment than n-gram or model-based alternatives.
What carries the argument
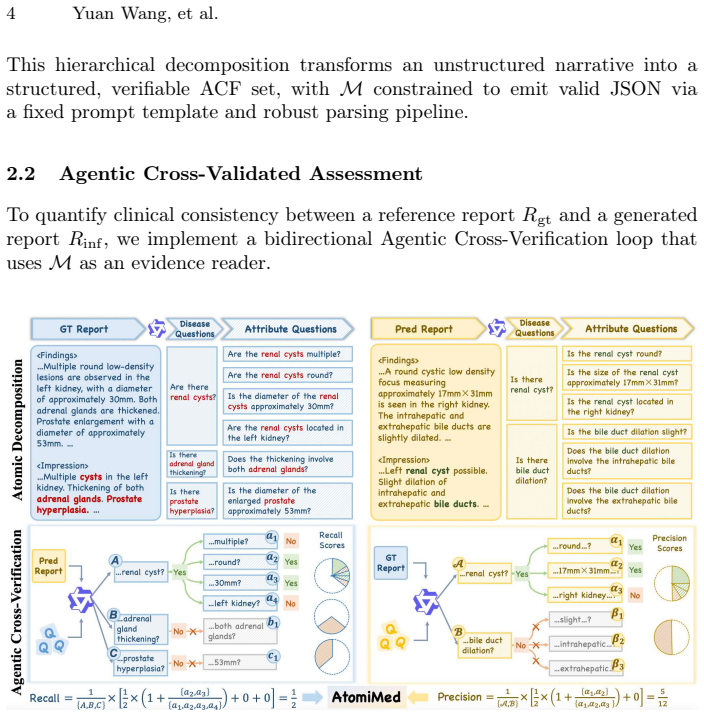
Hierarchical Atomic Clinical Facts (disease entities plus attribute descriptors) that enable decoupled scoring via an agentic cross-verification loop between reports.
If this is right
- Allows separate measurement of whether a finding is present versus how accurately its attributes are described.
- Applies the same evaluation protocol to reports from X-ray, CT, MRI, and ultrasound without modality-specific changes.
- Produces scores that correlate more strongly with expert human judgment than surface-level overlap metrics.
- Supplies an open toolkit and benchmark to run the evaluation consistently across research groups.
Where Pith is reading between the lines
- The atomic-fact breakdown could supply fine-grained reward signals for training report-generation models to reduce specific clinical errors.
- The same decomposition approach might transfer to factual verification in other technical narrative domains such as legal summaries or engineering logs.
- Automated extraction of the atomic facts from raw text could be tested for reliability as a standalone preprocessing step.
Load-bearing premise
Breaking medical narratives into a fixed multi-level hierarchy of atomic facts captures all critical clinical information without omissions or inventions.
What would settle it
A reader study on new reports where n-gram metrics or existing model-based scores show higher correlation with radiologist ratings than AtomiMed scores.
Figures

read the original abstract
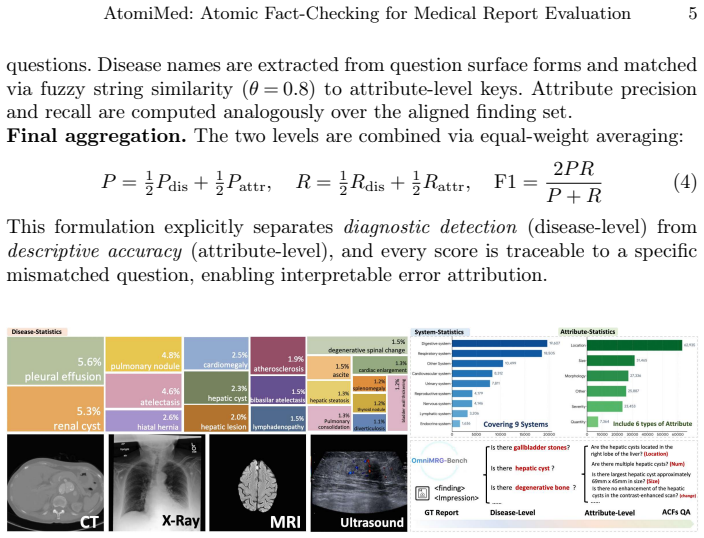
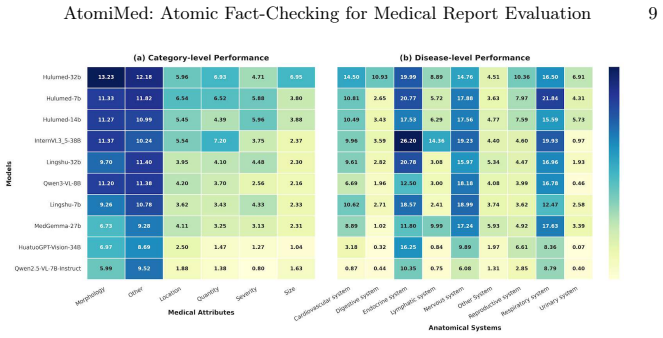
Traditional metrics for Medical Report Generation (MRG) predominantly rely on surface-level n-gram overlap, which fails to capture clinical factual accuracy and often overlooks catastrophic diagnostic errors. We address this fundamental limitation by proposing \textbf{AtomiMed}, a universal, modality-agnostic evaluation framework that decomposes complex medical narratives into a standardized, multi-level hierarchy of Atomic Clinical Facts, encompassing Disease-level entities and Attribute-level descriptors, including location, morphology, and severity. By implementing an Agentic Cross-Verification loop between ground-truth and predicted reports, AtomiMed simulates a multi-radiologist peer-review process to verify clinical consistency, thus enabling the decoupled assessment of diagnostic detection and descriptive accuracy. To facilitate standardized evaluation, we introduce \textbf{MRGEvalKit}, an open-source toolkit for automated hierarchical extraction, and curate \textbf{OmniMRG-Bench}, a comprehensive multi-modal benchmark covering X-ray, CT, MRI, and Ultrasound. Extensive experiments on multiple expert-annotated reader studies demonstrate that AtomiMed achieves significantly higher correlation with human radiologist judgment compared to traditional and model-based metrics. Our code are release at https://github.com/Venn2336/MRGEvalkit
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AtomiMed, a modality-agnostic framework for evaluating medical report generation (MRG) that decomposes reports into a multi-level hierarchy of Atomic Clinical Facts (Disease-level entities and Attribute-level descriptors for location, morphology, severity). It employs an Agentic Cross-Verification loop to simulate multi-radiologist review for decoupled assessment of diagnostic detection and descriptive accuracy. The work also introduces the open-source MRGEvalKit toolkit for hierarchical extraction and the OmniMRG-Bench multi-modal benchmark (X-ray, CT, MRI, Ultrasound), claiming via experiments on expert-annotated reader studies that AtomiMed yields significantly higher correlation with radiologist judgments than traditional n-gram or model-based metrics.
Significance. If the central claims hold after validation, AtomiMed could meaningfully advance MRG evaluation by moving beyond surface-level overlap to clinically grounded fact-checking, with the open-source toolkit and benchmark offering reusable infrastructure for the community. The decoupled scoring approach addresses a recognized gap in detecting catastrophic diagnostic errors.
major comments (2)
- [Abstract] Abstract: The central claim that 'AtomiMed achieves significantly higher correlation with human radiologist judgment compared to traditional and model-based metrics' supplies no quantitative results, dataset sizes, statistical tests (e.g., Pearson/Spearman coefficients, p-values), or implementation details, making it impossible to judge whether the data support the claim.
- [Abstract / decomposition description] Decomposition step and Agentic Cross-Verification loop: The framework's validity rests on the assumption that automated extraction into the Atomic Clinical Facts hierarchy faithfully captures clinical meaning without omitting or fabricating critical information (e.g., severity modifiers or location details). No quantitative check such as inter-rater agreement between the automated facts and independent radiologist re-annotation is reported; this is load-bearing for the subsequent decoupled scores and correlation results.
minor comments (2)
- [Abstract] The abstract lists modalities covered by OmniMRG-Bench but provides no information on the number of reports, readers, or annotation protocol used in the expert studies.
- [Abstract] The GitHub link is provided, but the manuscript does not specify the exact versions of any underlying LLMs or extraction models used in MRGEvalKit.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below with clarifications and commitments to revision where the points identify gaps in the current presentation. Our responses focus on strengthening the evidence for the framework's validity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'AtomiMed achieves significantly higher correlation with human radiologist judgment compared to traditional and model-based metrics' supplies no quantitative results, dataset sizes, statistical tests (e.g., Pearson/Spearman coefficients, p-values), or implementation details, making it impossible to judge whether the data support the claim.
Authors: We agree that the abstract should include key quantitative support for the central claim to allow readers to assess the strength of the results immediately. The body of the manuscript reports these details from the expert-annotated reader studies (including Pearson and Spearman coefficients, dataset sizes across modalities, and statistical significance), but they are not summarized in the abstract. In the revised version, we will update the abstract to incorporate the specific correlation values, sample sizes, and p-values. revision: yes
-
Referee: [Abstract / decomposition description] Decomposition step and Agentic Cross-Verification loop: The framework's validity rests on the assumption that automated extraction into the Atomic Clinical Facts hierarchy faithfully captures clinical meaning without omitting or fabricating critical information (e.g., severity modifiers or location details). No quantitative check such as inter-rater agreement between the automated facts and independent radiologist re-annotation is reported; this is load-bearing for the subsequent decoupled scores and correlation results.
Authors: We acknowledge that a direct quantitative validation of the automated hierarchical extraction (e.g., inter-rater agreement between the LLM-based decomposition and independent radiologist re-annotations on attributes such as severity and location) is not reported in the current manuscript. The primary validation comes from the end-to-end correlation of AtomiMed scores with radiologist judgments in the reader studies, which indirectly supports the decomposition quality. However, we agree this is a load-bearing assumption and will add a dedicated analysis in the revision, including agreement metrics (e.g., Cohen's kappa or F1 on fact extraction) computed on a held-out subset of reports re-annotated by radiologists. revision: yes
Circularity Check
No circularity: framework claims rest on external human correlation benchmarks
full rationale
The paper introduces AtomiMed as a decomposition-plus-verification evaluation method whose central performance claim is higher correlation with independent radiologist judgments on expert-annotated reader studies. No equations, fitted parameters, or self-citations appear in the abstract or described framework; the decomposition step is presented as an input assumption validated externally rather than derived from the method's own outputs. The derivation chain therefore remains self-contained against the stated human benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical reports can be decomposed into a standardized hierarchy of Atomic Clinical Facts (disease entities plus location, morphology, severity attributes) that preserves all clinically relevant information.
invented entities (2)
-
Atomic Clinical Facts hierarchy
no independent evidence
-
Agentic Cross-Verification loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: May 2023
Radiopaedia.org.https://radiopaedia.org. Accessed: May 2023
2023
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
Banerjee, S., Lavie, A.: Meteor: An automatic metric for mt evaluation with im- proved correlation with human judgments. In: Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. pp. 65–72 (2005)
2005
-
[4]
PhysioNet (2024)
Calamida, A.R., Nooralahzadeh, F., Rohanian, M., Nishio, M., Fujimoto, K., Krauthammer,M.:Radiologyreportgenerationmodelsevaluationdatasetforchest x-rays (radevalx). PhysioNet (2024)
2024
-
[5]
In: Findings of the Association for Computational Linguistics: ACL 2024
Delbrouck,J.B.,Chambon,P.,Chen,Z.,Varma,M.,Johnston,A.,Blankemeier,L., Van Veen, D., Bui, T., Truong, S., Langlotz, C.: Radgraph-xl: A large-scale expert- annotated dataset for entity and relation extraction from radiology reports. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 12902– 12915 (2024) 10 Yuan Wang, et al
2024
-
[6]
arXiv preprint arXiv:2106.14463 , year=
Jain, S., Agrawal, A., Saporta, A., Truong, S.Q., Duong, D.N., Bui, T., Chambon, P., Zhang, Y., Lungren, M.P., Ng, A.Y., et al.: Radgraph: Extracting clinical enti- ties and relations from radiology reports. arXiv preprint arXiv:2106.14463 (2021)
-
[7]
arXiv preprint arXiv:2510.08668 (2025)
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
-
[8]
Omniv-med: Scaling medical vision-language model for universal visual understanding
Jiang, S., Wang, Y., Song, S., Zhang, Y., Meng, Z., Lei, B., Wu, J., Sun, J., Liu, Z.: Omniv-med: Scaling medical vision-language model for universal visual understanding. arXiv preprint arXiv:2504.14692 (2025)
-
[9]
Scientific data10(1), 1 (2023)
Johnson, A.E., Bulgarelli, L., Shen, L., Gayles, A., Shammout, A., Horng, S., Pollard, T.J., Hao, S., Moody, B., Gow, B., et al.: Mimic-iv, a freely accessible electronic health record dataset. Scientific data10(1), 1 (2023)
2023
-
[10]
In: Text Sum- marization Branches Out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text Sum- marization Branches Out. pp. 74–81 (2004)
2004
-
[11]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Liu, J., Wang, Y., Du, J., Zhou, J.T., Liu, Z.: Medcot: Medical chain of thought via hierarchical expert. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 17371–17389 (2024)
2024
-
[12]
Miura, Y., Zhang, Y., Tsai, E., Langlotz, C., Jurafsky, D.: Improving factual com- pletenessandconsistencyofimage-to-textradiologyreportgeneration.In:Proceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 5288–5304 (2021)
2021
-
[13]
Na- ture616(7956), 259–265 (2023)
Moor, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Leskovec, J., Topol, E.J., Rajpurkar, P.: Foundation models for generalist medical artificial intelligence. Na- ture616(7956), 259–265 (2023)
2023
-
[14]
In: Proceedings of the ACM conference on health, inference, and learning
Oakden-Rayner, L., Dunnmon, J., Carneiro, G., Ré, C.: Hidden stratification causes clinically meaningful failures in machine learning for medical imaging. In: Proceedings of the ACM conference on health, inference, and learning. pp. 151–159 (2020)
2020
-
[15]
In: Findings of the association for computational linguistics: EMNLP 2024
Ostmeier, S., Xu, J., Chen, Z., Varma, M., Blankemeier, L., Bluethgen, C., Md, A.E.M., Moseley, M., Langlotz, C., Chaudhari, A.S., et al.: Green: Generative radiology report evaluation and error notation. In: Findings of the association for computational linguistics: EMNLP 2024. pp. 374–390 (2024)
2024
-
[16]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[17]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Smit, A., Jain, S., Rajpurkar, P., Pareek, A., Ng, A.Y., Lungren, M.: Combining automatic labelers and expert annotations for accurate radiology report labeling using bert. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 1500–1519 (2020)
2020
-
[19]
PhysioNet (2023)
Tian, K., Hartung, S.J., Li, A.A., Jeong, J., Behzadi, F., Calle-Toro, J., Adithan, S., Pohlen, M., Osayande, D., Rajpurkar, P.: Refisco: Report fix and score dataset for radiology report generation. PhysioNet (2023)
2023
-
[20]
NEJM AI1(3), AIoa2300138 (2024)
Tu, T., Azizi, S., Driess, D., Schaekermann, M., Amin, M., Chang, P.C., Carroll, A., Lau, C., Tanno, R., Ktena, I., et al.: Towards generalist biomedical ai. NEJM AI1(3), AIoa2300138 (2024)
2024
-
[21]
In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). pp. 4566–4575 (2015) AtomiMed: Atomic Fact-Checking for Medical Report Evaluation 11
2015
-
[22]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
arXiv preprint arXiv:2512.02710 (2025)
Wang, Y., Gao, S., Liu, J., Jiang, S., Xia, H., Zhang, X., Kang, Z., Wang, Y., Liu, Z.: Beyond n-grams: A hierarchical reward learning framework for clinically-aware medical report generation. arXiv preprint arXiv:2512.02710 (2025)
-
[24]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Wang, Y., Liu, J., Gao, S., Feng, B., Tang, Z., Gai, X., Wu, J., Liu, Z.: V2t- cot: From vision to text chain-of-thought for medical reasoning and diagnosis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 658–668. Springer (2025)
2025
-
[25]
Wu, C., Zhang, X., Zhang, Y., Wang, Y., Xie, W.: Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data. arXiv preprint arXiv:2308.02463 (2023)
-
[26]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Yu, F., Endo, M., Krishnan, R., Pan, I., Tsai, A., Reis, E.P., Fonseca, E., Lee, H., Shakeri, Z., Ng, A., et al.: Radiology report expert evaluation (rexval) dataset (2023)
2023
-
[28]
In: Findings of the association for computational linguistics: EMNLP 2023
Zhang, H., Chen, J., Jiang, F., Yu, F., Chen, Z., Chen, G., Li, J., Wu, X., Zhiyi, Z., Xiao, Q., et al.: Huatuogpt, towards taming language model to be a doctor. In: Findings of the association for computational linguistics: EMNLP 2023. pp. 10859–10885 (2023)
2023
-
[29]
In: International Conference on Learning Representa- tions (2020)
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. In: International Conference on Learning Representa- tions (2020)
2020
-
[30]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Zhao,W.,Wu,C.,Zhang,X.,Zhang,Y.,Wang,Y.,Xie,W.:Ratescore:Ametricfor radiology report generation. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 15004–15019 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.