Stabilization Learning: A Paradigm Transition Bridging Control Theory and Machine Learning
Pith reviewed 2026-07-01 05:36 UTC · model grok-4.3
The pith
Stabilization learning unifies control theory and machine learning through a six-tuple framework centered on stability rather than proofs or optimality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
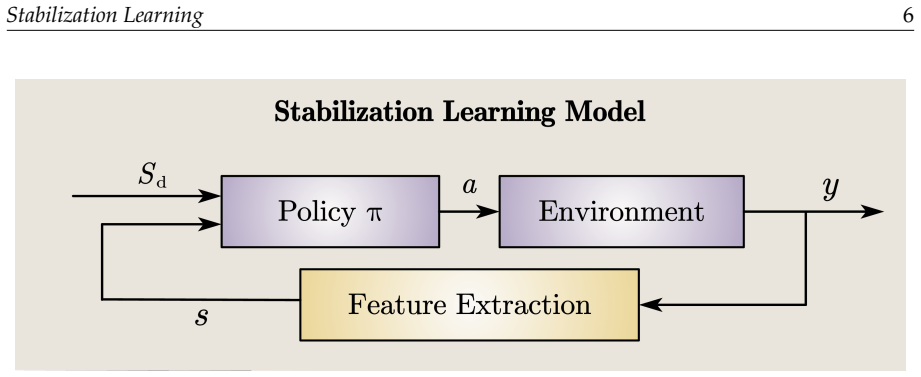
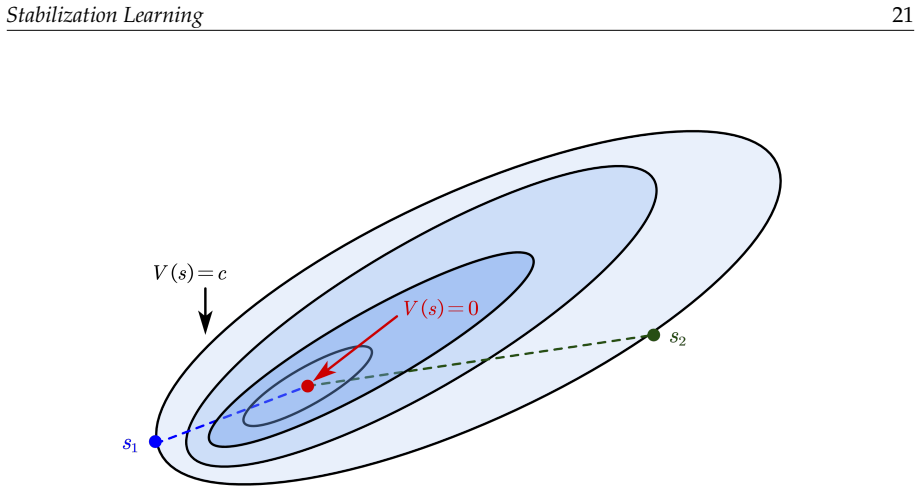
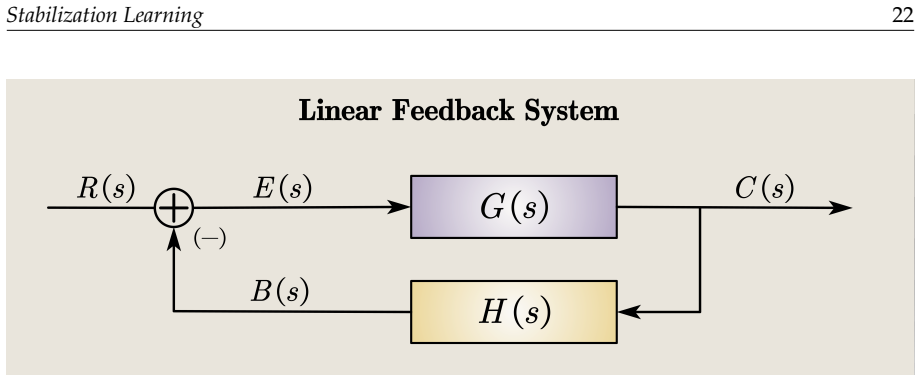
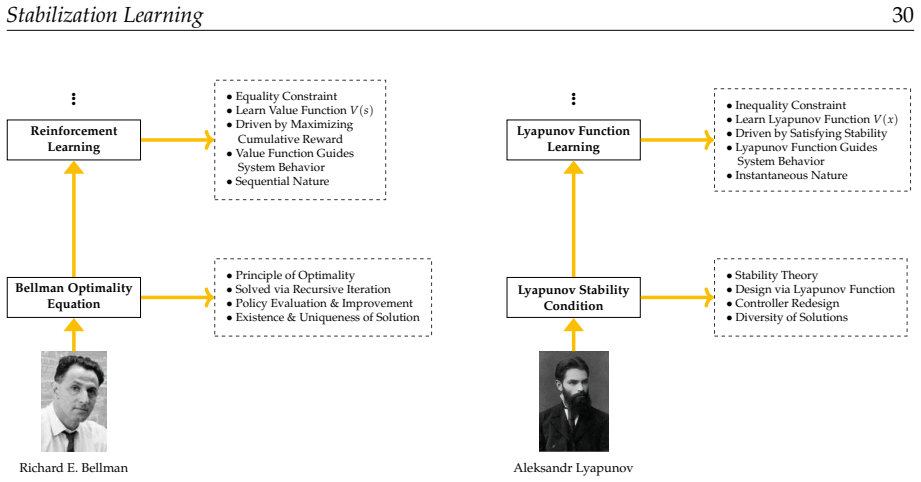
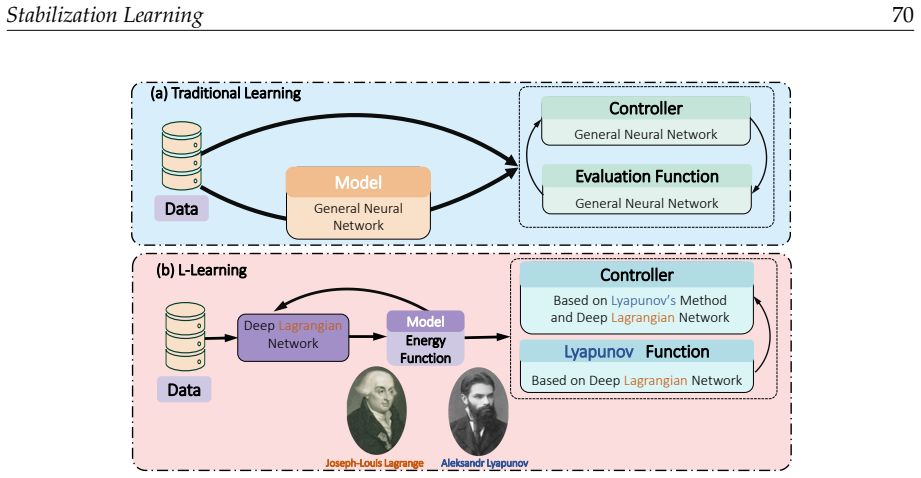
Stabilization learning constructs a unified mathematical framework based on a six-tuple that encompasses Lyapunov-based analysis, deep feature extraction, and data-driven feedback synthesis, enabling formal reformulation of problems across control, observation, and recognition domains while taking stability as the primary goal.
What carries the argument
The six-tuple (state space, controlled system, metrics, policy, and associated elements) that carries the unification of stability analysis with data-driven adaptation.
If this is right
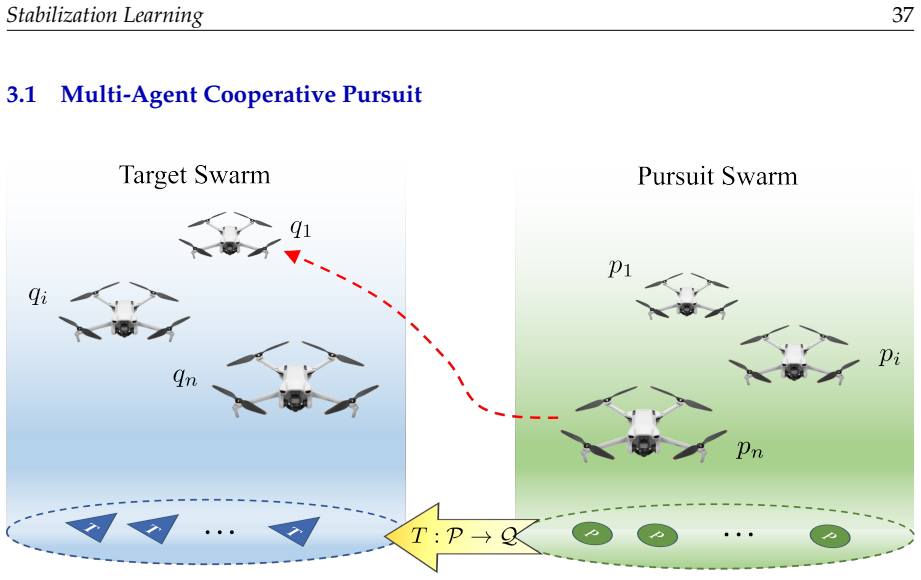
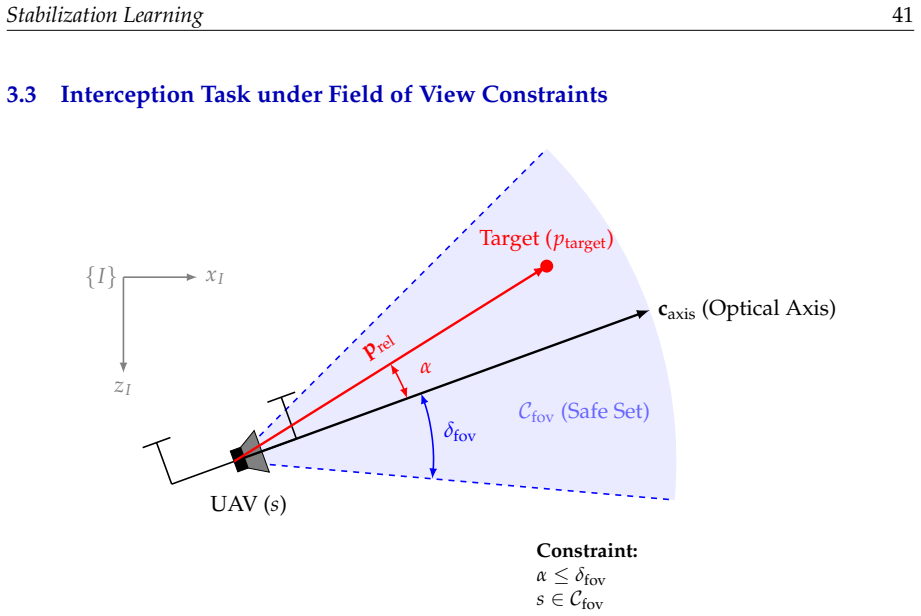
- Multi-agent cooperative tracking problems can be expressed inside the six-tuple or seven-tuple models.
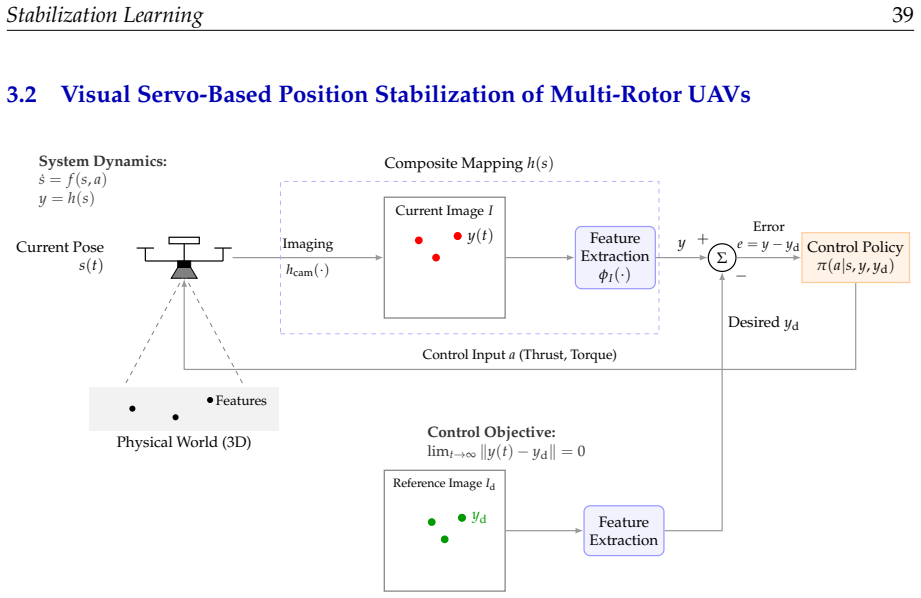
- Visual servo robot position stabilization admits a data-driven treatment that retains stability guarantees.
- Recognition tasks such as chess games become amenable to stability-focused reformulation.
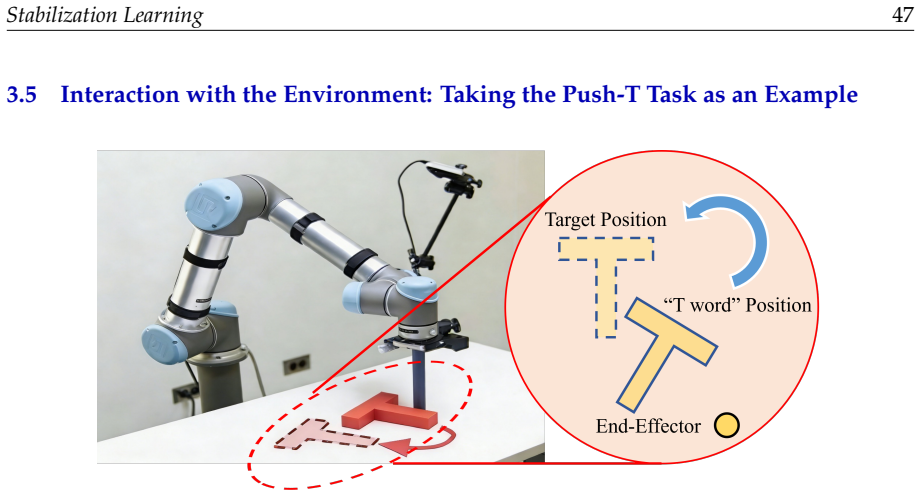
- Push-T tasks and similar manipulation problems receive a common stability-oriented treatment.
- Constrained learning with barrier spaces and target-tracking problems are captured by the seven-tuple extensions.
Where Pith is reading between the lines
- The framework could be tested on high-dimensional nonlinear systems where separate Lyapunov or learning methods currently lack joint guarantees.
- If the six-tuple works as claimed, it might allow stability considerations to be added to existing deep-learning pipelines in robotics without separate certificate steps.
- The emphasis on real-time adaptation suggests possible extensions to time-varying environments not explicitly treated in the eleven examples.
Load-bearing premise
The six-tuple structure and its seven-tuple extensions supply a non-trivial unification that adds engineering practicality beyond separate uses of Lyapunov theory and data-driven methods.
What would settle it
An example problem from control or recognition that cannot be expressed inside the six-tuple or whose resulting policy fails to maintain stability under the perturbations the framework claims to handle.
Figures





read the original abstract
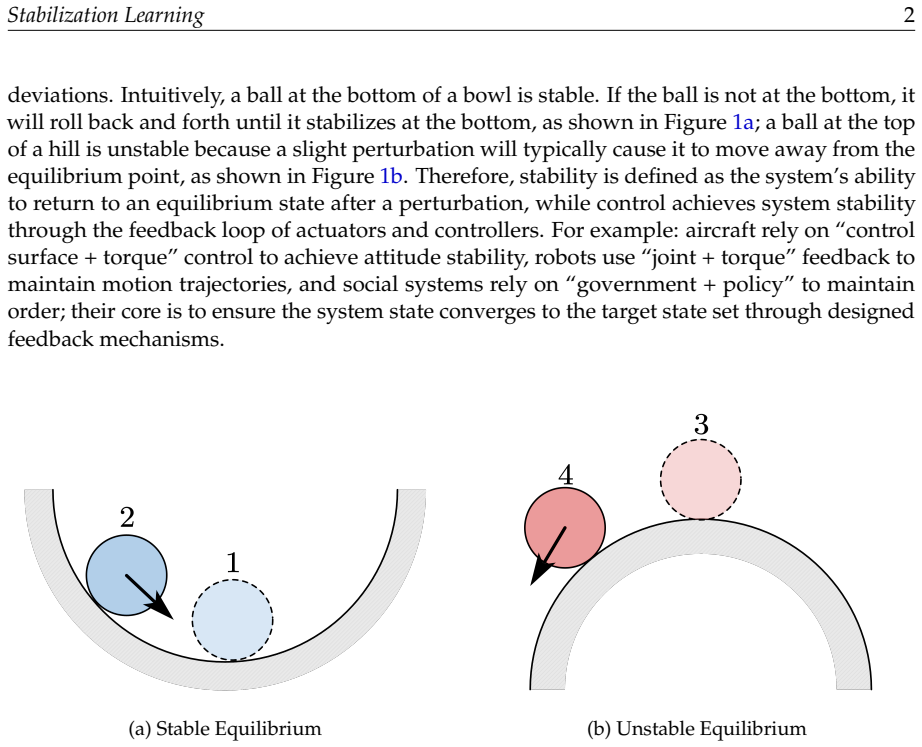
Stabilization learning is an interdisciplinary paradigm that bridges control theory and machine learning. Its core idea is to enable systems to adjust their policies under perturbations or environmental changes through real-time feedback and adaptive mechanisms. It takes stability as its primary goal, distinguishing itself from certificate learning, which focuses on formal proofs, and reinforcement learning, which pursues optimality. It encompasses a range of methods, including Lyapunov-based analysis and design, deep feature extraction, and data-driven feedback synthesis, and is applicable to complex high-dimensional, nonlinear systems. This paper elaborates on the two major categories of stability in stabilization learning, as well as three typical application scenarios: control, observation, and recognition. It constructs a unified mathematical framework based on a six-tuple, and expands into two types of seven-tuple models: constrained learning with barrier spaces and tracking problems with targets. It also analyzes the roles, meanings, and implementation choices of key elements such as state space, controlled system, metrics, and policy. Through the formal reformulation of 11 types of problems, including multi-agent cooperative tracking, visual servo robot position stabilization, chess games, and Push-T tasks, this paper illustrates the potential applicability of the framework across multiple domains. Finally, it points out that future stabilization learning will focus on two major directions: constructing a unified problem framework and achieving efficient and robust learning, providing solutions for complex system control that combine theoretical rigor with engineering practicality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces stabilization learning as a paradigm bridging control theory and machine learning, with stability as the primary goal rather than optimality (as in RL) or formal certificates (as in certificate learning). It proposes a unified mathematical framework centered on a six-tuple (encompassing state space, controlled system, metrics, policy, and two additional elements) that integrates Lyapunov-based analysis, deep feature extraction, and data-driven feedback synthesis. This is extended to seven-tuple models for constrained problems (with barrier spaces) and tracking problems (with targets). The framework is illustrated via formal reformulations of 11 problems across control, observation, and recognition, including multi-agent cooperative tracking, visual servo position stabilization, chess, and Push-T tasks. Future work is directed toward unified frameworks and efficient robust learning for complex nonlinear systems.
Significance. If the six-tuple and seven-tuple constructions yield non-trivial stability certificates, convergence bounds, or synthesis procedures that are not recoverable from standard combinations of Lyapunov theory and data-driven control, the framework could provide a useful organizing perspective for high-dimensional systems. However, the manuscript presents the unification at a conceptual level through enumeration and reformulation claims without new derivations, algorithms, or comparative analysis demonstrating engineering practicality or formal power beyond existing separate methods.
major comments (3)
- [Abstract / unified mathematical framework] Abstract and unified framework section: The central claim that the six-tuple 'enables formal reformulation of problems across control, observation, and recognition domains' rests on the tuple acting as a container for existing components (Lyapunov analysis plus data-driven synthesis), but no equation or derivation is supplied showing a stability certificate, convergence bound, or policy synthesis step that is unavailable from standard Lyapunov + data-driven control.
- [seven-tuple models for constrained and tracking cases] Section on seven-tuple models: The extensions to constrained learning (barrier spaces) and tracking (targets) are described as expansions of the six-tuple, yet no explicit mapping or proof is given that these preserve or improve upon the stability properties already obtainable from standard barrier Lyapunov functions or reference-tracking controllers.
- [formal reformulation of 11 types of problems] Reformulation of 11 problems (e.g., multi-agent tracking, visual servo, chess, Push-T): The paper states that these are formally reformulated within the framework, but supplies no concrete tuple assignments, stability analysis, or comparison to baseline methods that would substantiate the claim of added applicability or rigor.
minor comments (2)
- [Abstract] The abstract refers to 'two major categories of stability' and 'three typical application scenarios' without defining them explicitly before invoking the six-tuple; adding a brief enumeration or reference to later sections would improve readability.
- [unified mathematical framework] Notation for the six-tuple elements (state space, controlled system, metrics, policy) is introduced conceptually but would benefit from a single defining equation or table that lists all six components with their mathematical roles.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We agree that the manuscript is primarily conceptual and would benefit from greater explicitness in the framework descriptions and reformulations. We will revise to add concrete mappings and example derivations while preserving the paper's focus on unification rather than novel technical results.
read point-by-point responses
-
Referee: Abstract / unified mathematical framework] Abstract and unified framework section: The central claim that the six-tuple 'enables formal reformulation of problems across control, observation, and recognition domains' rests on the tuple acting as a container for existing components (Lyapunov analysis plus data-driven synthesis), but no equation or derivation is supplied showing a stability certificate, convergence bound, or policy synthesis step that is unavailable from standard Lyapunov + data-driven control.
Authors: The six-tuple is intended as an organizing abstraction to bridge domains using existing components, not as a generator of new certificates unavailable from standard methods. To improve clarity, the revised manuscript will include an explicit worked example deriving a Lyapunov-based stability certificate from the six-tuple elements for one control problem (visual servo stabilization). revision: yes
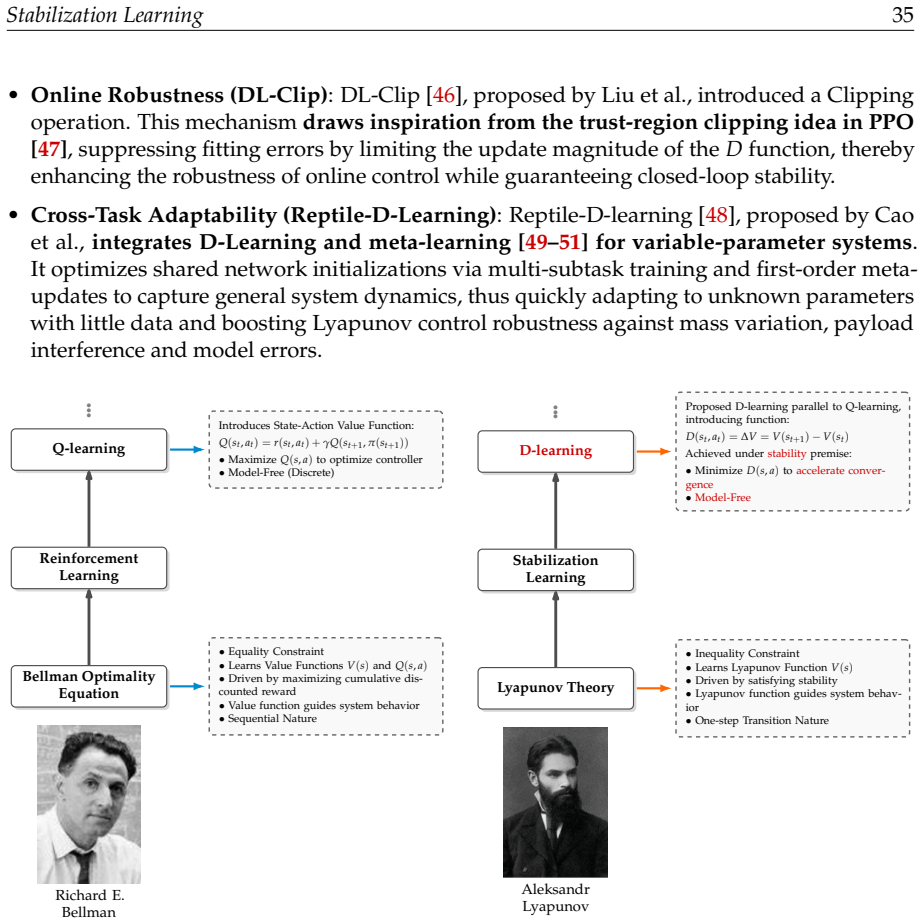
-
Referee: [seven-tuple models for constrained and tracking cases] Section on seven-tuple models: The extensions to constrained learning (barrier spaces) and tracking (targets) are described as expansions of the six-tuple, yet no explicit mapping or proof is given that these preserve or improve upon the stability properties already obtainable from standard barrier Lyapunov functions or reference-tracking controllers.
Authors: We agree explicit mappings are needed. The revision will add detailed element-by-element mappings for both seven-tuple cases, showing integration with barrier Lyapunov functions and tracking controllers, along with a short argument that stability properties are preserved under the extension. No improvement beyond unification is claimed. revision: yes
-
Referee: [formal reformulation of 11 types of problems] Reformulation of 11 problems (e.g., multi-agent tracking, visual servo, chess, Push-T): The paper states that these are formally reformulated within the framework, but supplies no concrete tuple assignments, stability analysis, or comparison to baseline methods that would substantiate the claim of added applicability or rigor.
Authors: The current text provides descriptive reformulations. The revision will supply explicit six-tuple or seven-tuple assignments and brief stability sketches for three representative problems (multi-agent tracking, visual servo, Push-T). Full baseline comparisons lie outside the conceptual scope and will be flagged as future work. revision: partial
- Requests for stability certificates, convergence bounds, or synthesis procedures unavailable from standard combinations of Lyapunov theory and data-driven control, as these exceed the conceptual unification scope of the manuscript.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lyapunov stability analysis provides a valid foundation for assessing system behavior under perturbations
- domain assumption Data-driven feedback synthesis can be combined with stability analysis without loss of rigor
invented entities (2)
-
six-tuple mathematical framework
no independent evidence
-
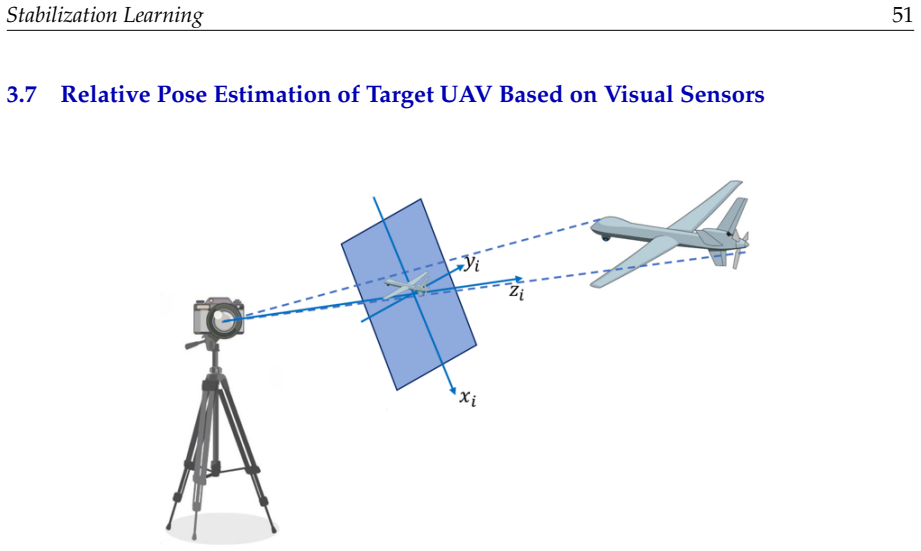
seven-tuple models for constrained and tracking cases
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wiener,Cybernetics: Or Control and Communication in the Animal and the Machine
N. Wiener,Cybernetics: Or Control and Communication in the Animal and the Machine. Cam- bridge, MA: The MIT Press, 2nd ed., 1961
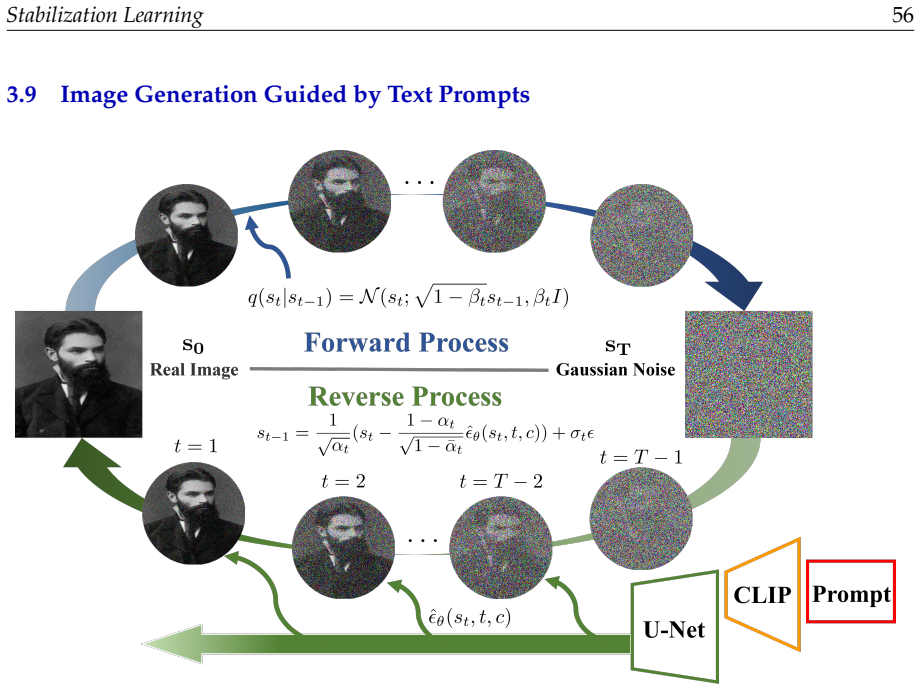
1961
-
[2]
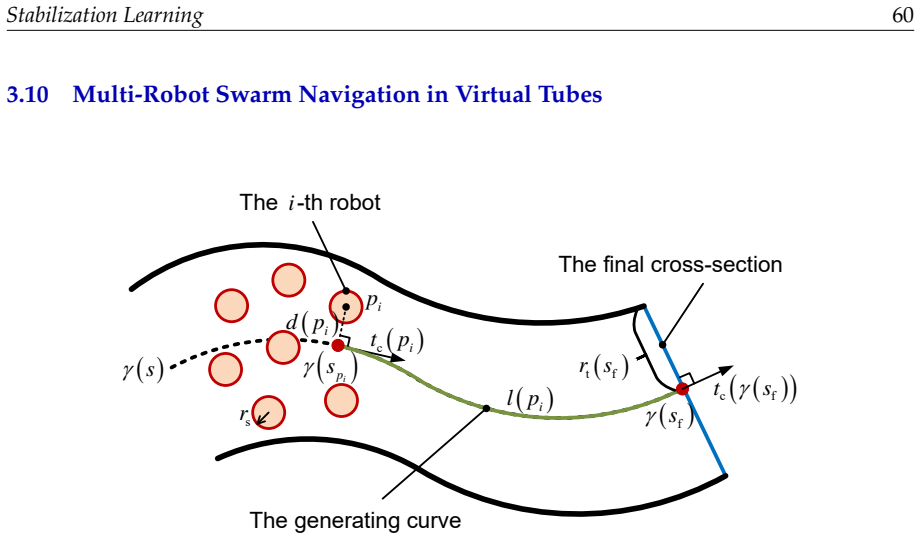
H. K. Khalil,Nonlinear Systems. Upper Saddle River, NJ: Prentice Hall, 3rd ed., 2002
2002
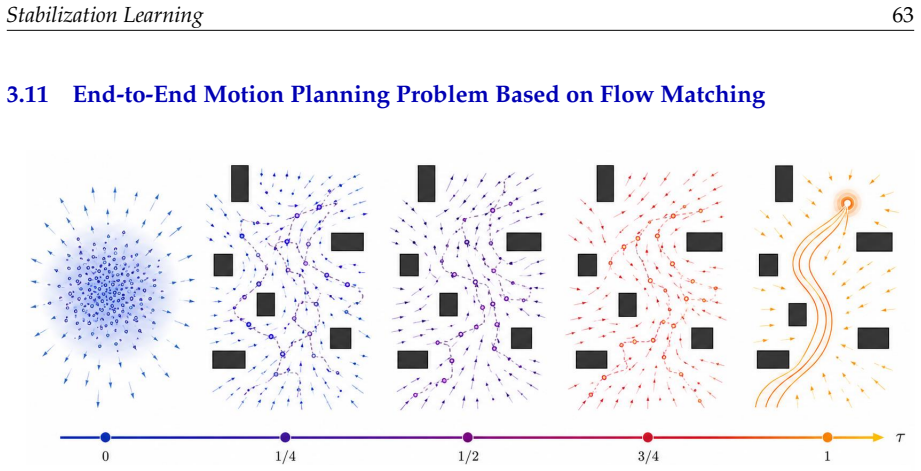
-
[3]
B. D. O. Anderson and J. B. Moore,Optimal Control: Linear Quadratic Methods. Mineola, NY: Dover Publications, 2007
2007
-
[4]
Safe control with learned certificates: A survey of neural Lyapunov, barrier, and contraction methods for robotics and control,
C. Dawson, S. Gao, and C. Fan, “Safe control with learned certificates: A survey of neural Lyapunov, barrier, and contraction methods for robotics and control,”IEEE Transactions on Robotics, vol. 39, no. 3, pp. 1749–1767, 2023
2023
-
[5]
Kailath,Linear Systems
T. Kailath,Linear Systems. Englewood Cliffs, NJ: Prentice Hall, 1980
1980
-
[6]
Score-based generative modeling through stochastic differential equations,
Y. Song, J. Sohl-Dickstein, D. P . Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inProceedings of the 2021 International Conference on Learning Representations (ICLR), 2021
2021
-
[7]
Blind video temporal consistency,
N. Bonneel, J. Tompkin, K. Sunkavalli, D. Sun, S. Paris, and H. Pfister, “Blind video temporal consistency,”ACM Transactions on Graphics (TOG), vol. 34, no. 6, p. 196, 2015
2015
-
[8]
Safe nonlinear control using robust neural Lyapunov-Barrier functions,
C. Dawson, Z. Qin, S. Gao, and C. Fan, “Safe nonlinear control using robust neural Lyapunov-Barrier functions,” inProceedings of the 2021 Conference on Robot Learning (CoRL), vol. 164, pp. 1724–1735, 2022
2021
-
[9]
R. W. Beard and T. W. McLain,Small Unmanned Aircraft: Theory and Practice. Princeton, NJ: Princeton University Press, 2012
2012
-
[10]
Stable inversion of SISO nonminimum phase linear systems through output planning: An experimental application to the one-link flexible manipulator,
M. Benosman and G. Le Vey, “Stable inversion of SISO nonminimum phase linear systems through output planning: An experimental application to the one-link flexible manipulator,” IEEE Transactions on Control Systems Technology, vol. 11, no. 4, pp. 588–597, 2003
2003
-
[11]
The internal model principle of control theory,
B. A. Francis and W. M. Wonham, “The internal model principle of control theory,”Auto- matica, vol. 12, no. 5, pp. 457–465, 1976. Stabilization Learning75
1976
-
[12]
Nonlinear internal models for output regulation,
C. I. Byrnes and A. Isidori, “Nonlinear internal models for output regulation,”IEEE Transactions on Automatic Control, vol. 49, no. 12, pp. 2244–2247, 2004
2004
-
[13]
Internal models in control, bioengineering, and neuroscience,
M. Bin, J. Huang, A. Isidori, L. Marconi, M. Mischiati, and E. Sontag, “Internal models in control, bioengineering, and neuroscience,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. 1, pp. 55–79, 2022
2022
-
[14]
Unstructured Data: An overview of the data of Big Data,
A. C. Eberendu, “Unstructured Data: An overview of the data of Big Data,”International Journal of Computer Trends and Technology, vol. 38, no. 1, pp. 46–50, 2016
2016
-
[15]
A survey on image data augmentation for deep learning,
C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,”Journal of Big Data, vol. 6, p. 60, 2019
2019
-
[16]
Dimensionality reduction by learning an invariant mapping,
R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” inProceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, pp. 1735–1742, 2006
2006
-
[17]
Dimensionality reduction: A compar- ative review,
L. Van der Maaten, E. Postma, and J. Van den Herik, “Dimensionality reduction: A compar- ative review,” Tech. Rep. TiCC TR 2009-005, Tilburg University, 2009
2009
-
[18]
Fundamental limits and tradeoffs in invariant representation learning,
H. Zhao, C. Dan, B. Aragam, T. S. Jaakkola, G. J. Gordon, and P . Ravikumar, “Fundamental limits and tradeoffs in invariant representation learning,”Journal of Machine Learning Research, vol. 23, p. 340, 2022
2022
-
[19]
Representation learning: A review and new perspectives,
Y. Bengio, A. Courville, and P . Vincent, “Representation learning: A review and new perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
2013
-
[20]
Auto-Encoding variational bayes,
D. P . Kingma and M. Welling, “Auto-Encoding variational bayes,” inProceedings of the 2014 International Conference on Learning Representations (ICLR), 2014
2014
-
[21]
A unifying review of linear Gaussian models,
S. Roweis and Z. Ghahramani, “A unifying review of linear Gaussian models,”Neural Computation, vol. 11, no. 2, pp. 305–345, 1999
1999
-
[22]
Mixture Kalman filters,
R. Chen and J. S. Liu, “Mixture Kalman filters,”Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 62, no. 3, pp. 493–508, 2000
2000
-
[23]
Hybrid dynamical systems,
R. Goebel, R. G. Sanfelice, and A. R. Teel, “Hybrid dynamical systems,”IEEE Control Systems Magazine, vol. 29, no. 2, pp. 28–93, 2009
2009
-
[24]
Understanding world or predicting future? A comprehensive survey of world models,
J. Ding, Y. Zhang, Y. Shang, Y. Zhang, Z. Zong, J. Feng, Y. Yuan, H. Su, N. Li, N. Sukiennik, F. Xu, and Y. Li, “Understanding world or predicting future? A comprehensive survey of world models,”ACM Computing Surveys, vol. 58, no. 3, p. 65, 2025
2025
-
[25]
A review of learning-based dynamics models for robotic manipulation,
B. Ai, S. Tian, H. Shi, Y. Wang, T. Pfaff, C. Tan, H. I. Christensen, H. Su, J. Wu, and Y. Li, “A review of learning-based dynamics models for robotic manipulation,”Science Robotics, vol. 10, no. 106, p. eadt1497, 2025
2025
-
[26]
Neural ordinary differen- tial equations,
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differen- tial equations,” inProceedings of the 2018 Advances in Neural Information Processing Systems (NeurIPS), vol. 31, pp. 6571–6583, 2018
2018
-
[27]
M. M. Deza and E. Deza,Encyclopedia of Distances. Springer Berlin Heidelberg, 4th ed., 2016
2016
-
[28]
A Lyapunov formulation of the nonlinear small- gain theorem for interconnected ISS systems,
Z.-P . Jiang, I. M. Y. Mareels, and Y. Wang, “A Lyapunov formulation of the nonlinear small- gain theorem for interconnected ISS systems,”Automatica, vol. 32, no. 8, pp. 1211–1215, 1996. Stabilization Learning76
1996
-
[29]
Small gain theorems for large scale systems and construction of ISS Lyapunov functions,
S. Dashkovskiy, B. S. Rüffer, and F. R. Wirth, “Small gain theorems for large scale systems and construction of ISS Lyapunov functions,”SIAM Journal on Control and Optimization, vol. 48, no. 6, pp. 4089–4118, 2010
2010
-
[30]
Neural networks and physical systems with emergent collective computa- tional abilities,
J. J. Hopfield, “Neural networks and physical systems with emergent collective computa- tional abilities,”Proceedings of the National Academy of Sciences, vol. 79, no. 8, pp. 2554–2558, 1982
1982
-
[31]
Handwritten character recognition using Hopfield neural network,
C. Olson and R. Y. Li, “Handwritten character recognition using Hopfield neural network,” inProceedings of the 1993 Applications of Artificial Neural Networks IV (SPIE), vol. 1965, pp. 412–418, 1993
1993
-
[32]
Dynamics of pattern formation in lateral-inhibition type neural fields,
S.-i. Amari, “Dynamics of pattern formation in lateral-inhibition type neural fields,”Biologi- cal Cybernetics, vol. 27, no. 2, pp. 77–87, 1977
1977
-
[33]
Self-organizing continuous attractor networks and path integration: One-dimensional models of head direction cells,
S. Stringer, T. Trappenberg, E. Rolls, and I. Araujo, “Self-organizing continuous attractor networks and path integration: One-dimensional models of head direction cells,”Network: Computation in Neural Systems, vol. 13, no. 2, pp. 217–242, 2002
2002
-
[34]
Path integration and cognitive mapping in a continuous attractor neural network model,
A. Samsonovich and B. L. McNaughton, “Path integration and cognitive mapping in a continuous attractor neural network model,”Journal of Neuroscience, vol. 17, no. 15, pp. 5900– 5920, 1997
1997
-
[35]
Continuous attractor dynamics in spatial navigation: From population geometry to flexible computation,
Y. Chen, M. Hua, X. Sun, and J. Peng, “Continuous attractor dynamics in spatial navigation: From population geometry to flexible computation,”Frontiers in Neuroscience, vol. 20, p. 1788255, 2026
2026
-
[36]
Optimal adaptive control and differential games by reinforcement learning principles,
D. Vrabie, K. G. Vamvoudakis, and F. L. Lewis, “Optimal adaptive control and differential games by reinforcement learning principles,”IEEE Control Systems Magazine, vol. 33, no. 3, pp. 50–91, 2013
2013
-
[37]
Neural Lyapunov control,
Y.-C. Chang, N. Roohi, and S. Gao, “Neural Lyapunov control,” inProceedings of the 2019 Advances in Neural Information Processing Systems (NeurIPS), vol. 32, pp. 3245–3254, 2019
2019
-
[38]
Stabilizing neural control using self-learned almost Lyapunov critics,
Y.-C. Chang and S. Gao, “Stabilizing neural control using self-learned almost Lyapunov critics,” inProceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 1803–1809, 2021
2021
-
[39]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction. Cambridge, MA: The MIT Press, 2nd ed., 2018
2018
-
[40]
D. P . Bertsekas,Reinforcement Learning and Optimal Control. Belmont, MA: Athena Scientific, 2019
2019
-
[41]
Q-learning,
C. J. Watkins and P . Dayan, “Q-learning,”Machine Learning, vol. 8, no. 3, pp. 279–292, 1992
1992
-
[42]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[43]
Continuous control with deep reinforcement learning,
T. P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wier- stra, “Continuous control with deep reinforcement learning,” inProceedings of the 2016 International Conference on Learning Representations (ICLR), 2016
2016
-
[44]
Control with patterns: A D-learning method,
Q. Quan, K.-Y. Cai, and C. Wang, “Control with patterns: A D-learning method,” in Proceedings of the 8th Annual Conference on Robot Learning (CoRL), vol. 270, pp. 1384–1401, 2025. Stabilization Learning77
2025
-
[45]
DOPT: D-learning with off-policy target toward sample efficiency and fast convergence control,
Z. Shen and Q. Quan, “DOPT: D-learning with off-policy target toward sample efficiency and fast convergence control,” inProceedings of the 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 9637–9643, 2025
2025
-
[46]
DL-Clip: Online D-learning with clipping operation for fast model-free stabilizing control,
J. Liu, C. Wang, Z. Shen, and Q. Quan, “DL-Clip: Online D-learning with clipping operation for fast model-free stabilizing control,” inProceedings of the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 15838–15844, 2025
2025
-
[47]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P . Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimiza- tion algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Learning to Adapt: Reptile-D-Learning for Robust and Efficient Control Under Parametric Uncertainty
H. Cao, Z. Shen, and Q. Quan, “Learning to adapt: Reptile-D-Learning for robust and efficient control under parametric uncertainty,”arXiv preprint arXiv:2606.25659, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Meta-Learning in neural networks: A survey,
T. Hospedales, A. Antoniou, P . Micaelli, and A. Storkey, “Meta-Learning in neural networks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 5149–5169, 2022
2022
-
[50]
Model-Agnostic Meta-Learning for fast adaptation of deep networks,
C. Finn, P . Abbeel, and S. Levine, “Model-Agnostic Meta-Learning for fast adaptation of deep networks,” inProceedings of the 2017 International Conference on Machine Learning (ICML), pp. 1126–1135, 2017
2017
-
[51]
On First-Order Meta-Learning Algorithms
A. Nichol, J. Achiam, and J. Schulman, “On First-Order Meta-Learning algorithms,”arXiv preprint arXiv:1803.02999, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[52]
Safe policy optimization with cost practical stability: A DQ-learning method,
C. Wang, L. Liu, and Q. Quan, “Safe policy optimization with cost practical stability: A DQ-learning method,”IEEE Robotics and Automation Letters, vol. 11, no. 6, pp. 6823–6830, 2026
2026
-
[53]
Visual servo control. I. Basic approaches,
F. Chaumette and S. Hutchinson, “Visual servo control. I. Basic approaches,”IEEE Robotics & Automation Magazine, vol. 13, no. 4, pp. 82–90, 2006
2006
-
[54]
Quan,Introduction to Multicopter Design and Control
Q. Quan,Introduction to Multicopter Design and Control. Singapore: Springer Singapore, 2017
2017
-
[55]
Line-of-sight-constrained multicopter interceptability,
K. Yang, C. Bai, and Q. Quan, “Line-of-sight-constrained multicopter interceptability,” Journal of Guidance, Control, and Dynamics, vol. 48, no. 4, pp. 951–960, 2025
2025
-
[56]
High-speed interception multicopter control by image-based visual servoing,
K. Yang, C. Bai, Z. She, and Q. Quan, “High-speed interception multicopter control by image-based visual servoing,”IEEE Transactions on Control Systems Technology, vol. 33, no. 1, pp. 119–135, 2024
2024
-
[57]
A general reinforce- ment learning algorithm that masters chess, shogi, and Go through self-play,
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, “A general reinforce- ment learning algorithm that masters chess, shogi, and Go through self-play,”Science, vol. 362, no. 6419, pp. 1140–1144, 2018
2018
-
[58]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[59]
Hairer, S
E. Hairer, S. P . Nørsett, and G. Wanner,Solving Ordinary Differential Equations I: Nonstiff Problems. Berlin, Heidelberg: Springer, 2nd ed., 1993
1993
-
[60]
Estimating 6D aircraft pose from keypoints and structures,
R. Fan, T.-B. Xu, and Z. Wei, “Estimating 6D aircraft pose from keypoints and structures,” Remote Sensing, vol. 13, no. 4, p. 663, 2021. Stabilization Learning78
2021
-
[61]
Vision-based autonomous quadrotor landing on a moving platform,
D. Falanga, A. Zanchettin, A. Simovic, J. Delmerico, and D. Scaramuzza, “Vision-based autonomous quadrotor landing on a moving platform,” inProceedings of the 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), pp. 200–207, 2017
2017
-
[62]
A unified and persistent interception control of multicopters with strapdown monocular camera,
K. Yang, L. Liu, C. Bai, and Q. Quan, “A unified and persistent interception control of multicopters with strapdown monocular camera,”IEEE Transactions on Aerospace and Electronic Systems, vol. 62, pp. 1244–1253, 2025
2025
-
[63]
Fast and omnidirectional relative position estimation with circular markers for UAV swarm,
Z. Lu, Y. Wu, S. Yang, K. Zhang, and Q. Quan, “Fast and omnidirectional relative position estimation with circular markers for UAV swarm,”IEEE Transactions on Instrumentation and Measurement, vol. 73, p. 5034911, 2024
2024
-
[64]
Consistency analysis and improvement of vision-aided inertial navigation,
J. A. Hesch, D. G. Kottas, S. L. Bowman, and S. I. Roumeliotis, “Consistency analysis and improvement of vision-aided inertial navigation,”IEEE Transactions on Robotics, vol. 30, no. 1, pp. 158–176, 2013
2013
-
[65]
ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,
R. Mur-Artal and J. D. Tardós, “ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,”IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[66]
Direct sparse odometry,
J. Engel, V . Koltun, and D. Cremers, “Direct sparse odometry,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 3, pp. 611–625, 2017
2017
-
[67]
SVO: Semidirect visual odometry for monocular and multicamera systems,
C. Forster, Z. Zhang, M. Gassner, M. Werlberger, and D. Scaramuzza, “SVO: Semidirect visual odometry for monocular and multicamera systems,”IEEE Transactions on Robotics, vol. 33, no. 2, pp. 249–265, 2016
2016
-
[68]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inProceedings of the 2015 International Conference on Machine Learning (ICML), vol. 37, pp. 2256–2265, 2015
2015
-
[69]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,”Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020
2020
-
[70]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P . Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inProceedings of the 2021 International Conference on Machine Learning (ICML), vol. 139, pp. 8748–8763, 2021
2021
-
[71]
Practical distributed control for VTOL UAVs to pass a virtual tube,
Q. Quan, R. Fu, M. Li, D. Wei, Y. Gao, and K.-Y. Cai, “Practical distributed control for VTOL UAVs to pass a virtual tube,”IEEE Transactions on Intelligent Vehicles, vol. 7, no. 2, pp. 342–353, 2021
2021
-
[72]
Making robotics swarm flow more smoothly: A regular virtual tube model,
P . Mao and Q. Quan, “Making robotics swarm flow more smoothly: A regular virtual tube model,” inProceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 4498–4504, 2022
2022
-
[73]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”ArXiv, vol. abs/2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[74]
Flow matching for scalable simulation-based inference,
J. Wildberger, M. Dax, S. Buchholz, S. Green, J. H. Macke, and B. Schölkopf, “Flow matching for scalable simulation-based inference,”Advances in Neural Information Processing Systems, vol. 36, pp. 16837–16864, 2023
2023
-
[75]
Improving and generalizing flow-based generative models with minibatch optimal transport,
A. Tong, C. Meng, N. Malkin, G. Huguet, A. Carmichael, J. Rector-Brooks, K. Schramm, Y. Bengio, and G. Wolf, “Improving and generalizing flow-based generative models with minibatch optimal transport,” inProceedings of the 2023 International Conference on Machine Learning (ICML), pp. 34337–34358, PMLR, 2023. Stabilization Learning79
2023
-
[76]
Rectified Flow: A Marginal Preserving Approach to Optimal Transport
Q. Liu, “Rectified flow: A marginal preserving approach to optimal transport,”arXiv preprint arXiv:2209.14577, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[77]
A survey on transfer learning,
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345–1359, 2009
2009
-
[78]
Deep Transfer Network: Unsupervised Domain Adaptation
X. Zhang, F. X. Yu, S.-F. Chang, and S. Wang, “Deep transfer network: Unsupervised domain adaptation,”arXiv preprint arXiv:1503.00591, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[79]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences (PNAS), vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[80]
A continual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 3366–3385, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.