Investigating LLM-Powered Dissenting Minority Support in Power-Imbalanced Group Decision-Making: Counterargument and Mediation as Intervention Strategies
Pith reviewed 2026-07-01 03:49 UTC · model grok-4.3
The pith
LLM counterarguments improve group satisfaction while AI mediation increases minority participation but lowers their safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
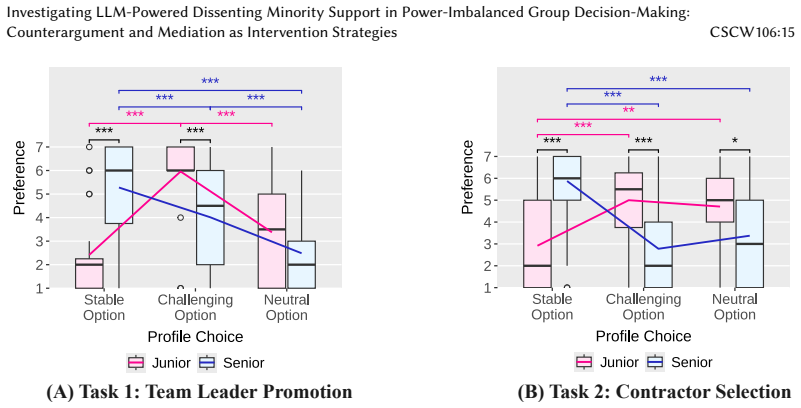
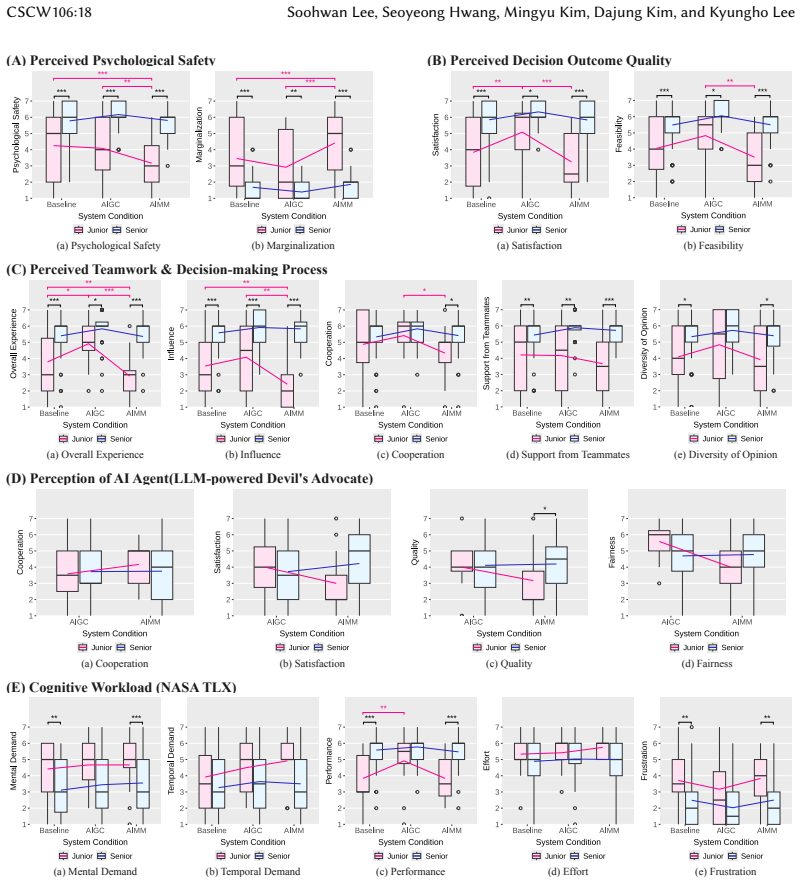
In the experiment, AI-generated counterarguments created a more flexible atmosphere and raised satisfaction for minority members, whereas AI-mediated messages raised their participation rate but reduced their reported psychological safety.
What carries the argument
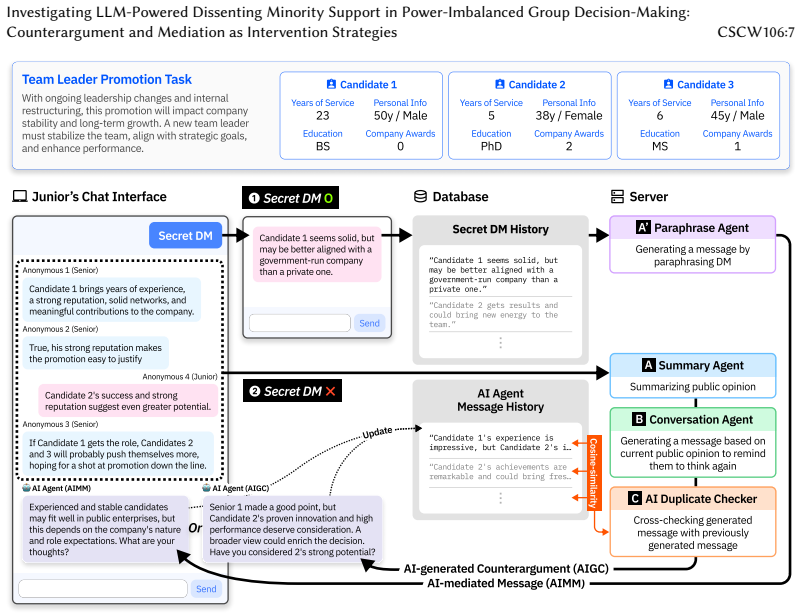
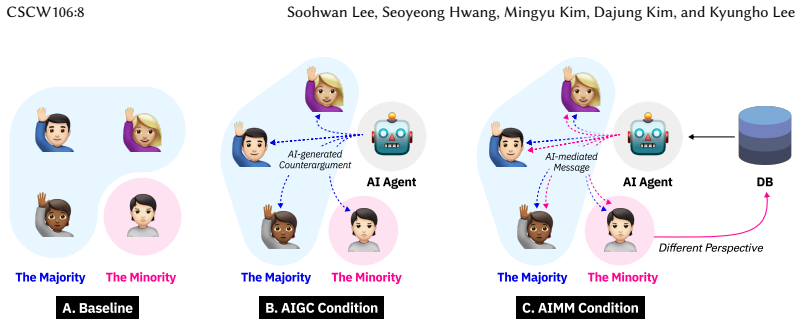
LLM-powered system that supplies either generated counterarguments to majority positions or mediated delivery of minority messages.
If this is right
- AI counterargument support can make groups feel more open without raising participation.
- AI message mediation can raise how much minorities contribute but at a cost to their sense of safety.
- Systems that help minorities must weigh participation gains against possible drops in psychological safety.
- Design choices in AI group tools carry ethical questions about communication in unequal settings.
Where Pith is reading between the lines
- The trade-off may mean future tools need separate modes or user controls so groups can choose the effect they want.
- The findings could apply to other settings such as online teams or classrooms where one side holds more authority.
- Testing whether combining both counterargument and mediation features reduces the safety cost would be a direct next step.
Load-bearing premise
Lab-based group tasks and self-reported feelings accurately reflect how power imbalances work in real settings and that the LLM outputs did not create unnoticed biases or pressure on participants.
What would settle it
Running the same conditions inside actual workplace teams over multiple meetings and checking whether minority members change their future behavior or stay in the group would show if the participation-safety trade-off appears outside the lab.
Figures


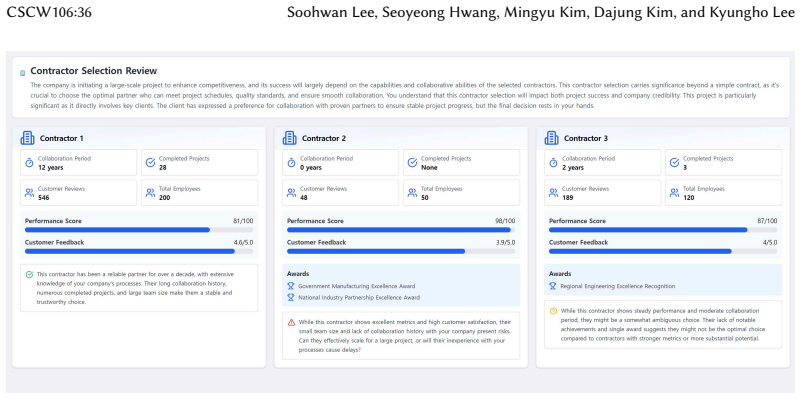
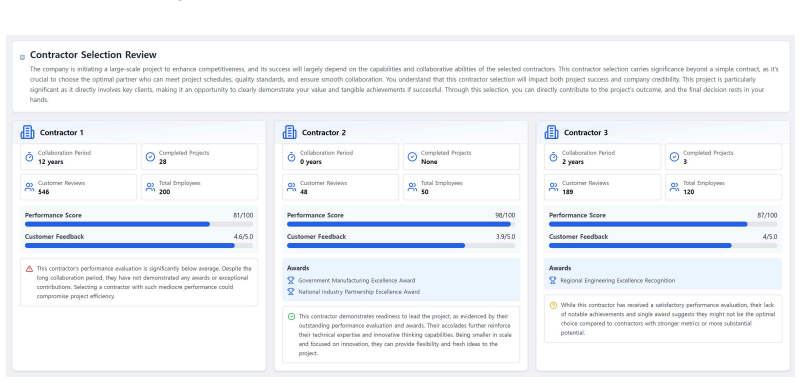
read the original abstract
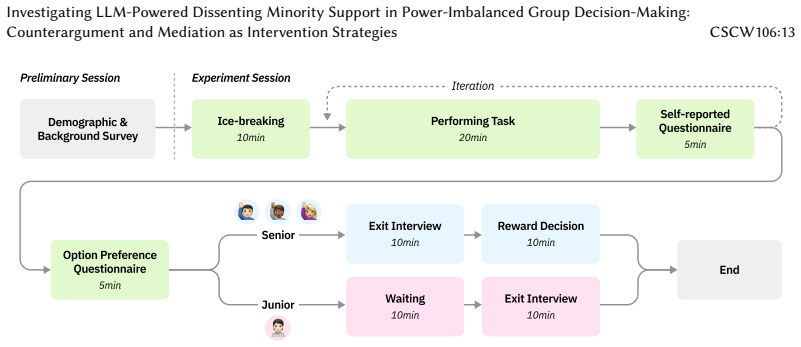
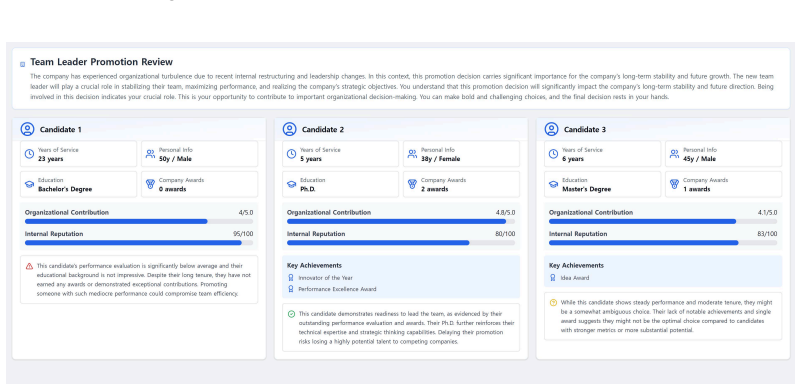
Minority viewpoints are often suppressed in power-imbalanced group decision-making due to social pressure to comply with the majority. To address this problem, we developed an LLM-powered dissenting minority support system that aimed to foster attention to minority views through either AI-generated counterarguments or AI-mediated messages. We conducted a mixed-method experiment with 96 participants in 24 groups, comparing minority members' experiences across baseline, AI-counterargument, and AI-mediated message conditions. Our findings revealed a nuanced trade-off: AI-generated counterarguments fostered a more flexible atmosphere and enhanced satisfaction, while AI-mediated messaging increased minority participation but unexpectedly reduced their psychological safety. This research contributes empirical evidence on how different AI implementations affect group dynamics, identifies a critical support paradox between participation and psychological safety, provides design implications for future systems, and highlights ethical challenges in implementing AI-mediated communication in hierarchical settings. These insights advance understanding of designing more equitable AI support for power-imbalanced group decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an LLM-powered system to support dissenting minorities in power-imbalanced group decision-making via two interventions: AI-generated counterarguments and AI-mediated messages. It reports results from a mixed-methods experiment with 96 participants across 24 groups comparing baseline, counterargument, and mediation conditions, claiming a nuanced trade-off in which counterarguments improve perceived flexibility and satisfaction while mediation increases minority participation but reduces psychological safety. The work positions these findings as evidence for a participation-safety paradox and offers design implications for equitable AI support in hierarchical settings.
Significance. If the empirical trade-off is robustly supported, the study would contribute timely evidence on LLM interventions in group dynamics, particularly the identification of a support paradox between participation and safety, with practical value for HCI researchers designing AI-mediated communication tools.
major comments (2)
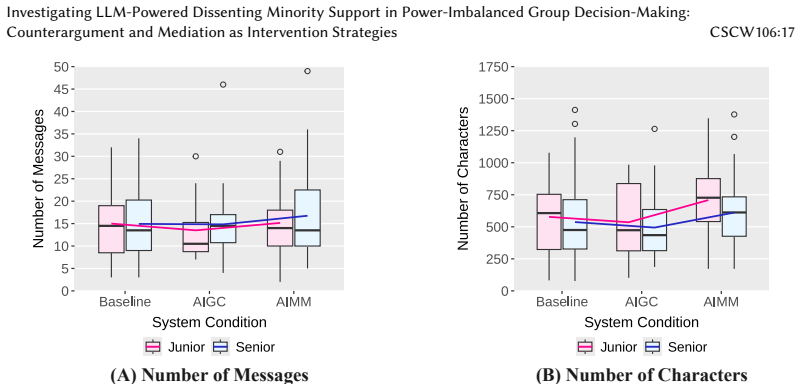
- [Results / Experiment] The central claim of a participation-safety trade-off rests entirely on self-report Likert measures of participation and psychological safety (results section). No behavioral validation (e.g., coded turn-taking counts, message volume logs, or objective participation metrics) is reported, leaving the findings vulnerable to demand effects and social-desirability bias in an AI-aware participant pool; this directly undermines attribution of the observed differences to the interventions rather than expectancy.
- [Abstract / Methods] The abstract and methods description provide no statistical details (means, SDs, p-values, effect sizes, or exclusion criteria) for the 96-participant, 24-group design, making it impossible to assess whether the reported trade-off meets conventional significance thresholds or survives multiple-comparison correction.
minor comments (2)
- [Methods] Clarify the exact wording of the self-report items for psychological safety and participation to allow replication.
- [Analysis] The mixed-methods analysis should explicitly state how qualitative themes were triangulated with the quantitative self-reports.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results / Experiment] The central claim of a participation-safety trade-off rests entirely on self-report Likert measures of participation and psychological safety (results section). No behavioral validation (e.g., coded turn-taking counts, message volume logs, or objective participation metrics) is reported, leaving the findings vulnerable to demand effects and social-desirability bias in an AI-aware participant pool; this directly undermines attribution of the observed differences to the interventions rather than expectancy.
Authors: We appreciate the referee's concern regarding reliance on self-report measures. Likert scales for psychological safety and perceived participation are established in group dynamics and HCI research (e.g., Edmondson’s scale). Our mixed-methods design incorporates qualitative data from post-experiment interviews and open-ended responses that provide convergent support for the quantitative patterns. However, we acknowledge that the absence of objective behavioral logs (such as turn counts or message volumes) limits triangulation and leaves room for demand effects. The experiment focused on subjective experiences rather than logging all utterances, as the platform did not capture full transcripts beyond intervention messages. We will add an explicit limitations subsection discussing this issue, the rationale for self-report focus, and suggestions for future work with behavioral metrics. This constitutes a partial revision. revision: partial
-
Referee: [Abstract / Methods] The abstract and methods description provide no statistical details (means, SDs, p-values, effect sizes, or exclusion criteria) for the 96-participant, 24-group design, making it impossible to assess whether the reported trade-off meets conventional significance thresholds or survives multiple-comparison correction.
Authors: We agree that the abstract omits statistical details due to length constraints and that the methods section should be more explicit. The full results section contains the relevant statistics, but we will expand the methods to report means, SDs, p-values, effect sizes, exclusion criteria, and any multiple-comparison corrections. We will also revise the abstract to include key statistical highlights (e.g., significant differences and effect sizes) within word limits. This is a full revision. revision: yes
Circularity Check
No significant circularity: purely empirical study with no derivations
full rationale
This paper reports results from a mixed-method experiment with 96 participants across 24 groups, comparing baseline, AI-counterargument, and AI-mediated conditions via self-report measures. No equations, parameters, derivations, or first-principles claims appear in the provided text or abstract. Central findings (trade-off between flexibility/satisfaction and participation/safety) are presented as direct observations from the data rather than reductions to fitted inputs or self-citations. No self-definitional, fitted-prediction, or uniqueness-theorem patterns exist. The study is self-contained against external benchmarks as standard empirical work; the reader's noted validity concerns (self-reports, demand effects) pertain to correctness risk, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported psychological safety and satisfaction scores validly reflect participants' internal states in the experimental setting.
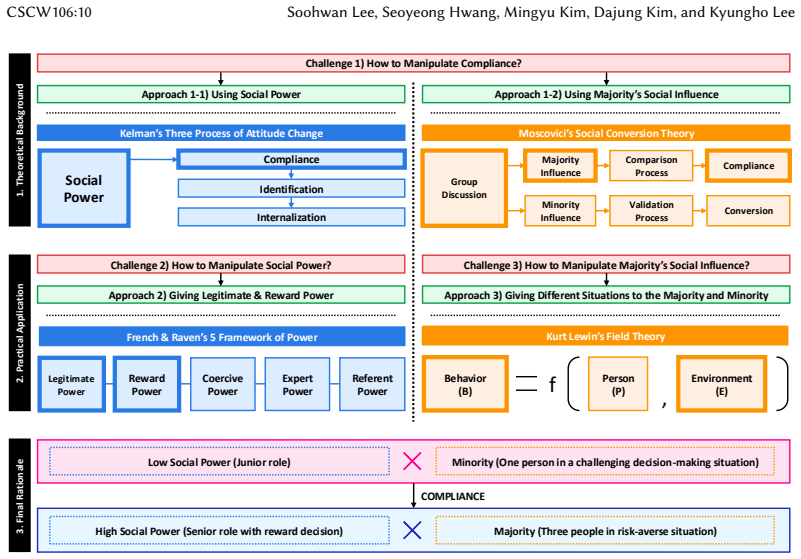
Reference graph
Works this paper leans on
-
[1]
Dhruv Agarwal, Farhana Shahid, and Aditya Vashistha. 2024. Conversational Agents to Facilitate Deliberation on Harmful Content in WhatsApp Groups.Proceedings of the ACM on Human-Computer Interaction8, CSCW2 (Nov. 2024), 1–32. arXiv:2405.20254 [cs] doi:10.1145/3687030
-
[2]
Solomon E. Asch. 1955. Opinions and Social Pressure. https://www.scientificamerican.com/article/opinions-and-social- pressure/
1955
-
[3]
Vera Liao, Casey Dugan, James Johnson, Qian Pan, Wei Zhang, Sadhana Kumaravel, and Murray Campbell
Zahra Ashktorab, Q. Vera Liao, Casey Dugan, James Johnson, Qian Pan, Wei Zhang, Sadhana Kumaravel, and Murray Campbell. 2020. Human-AI Collaboration in a Cooperative Game Setting: Measuring Social Perception and Outcomes. Proc. ACM Hum.-Comput. Interact.4, CSCW2 (Oct. 2020), 96:1–96:20. doi:10.1145/3415167
-
[4]
Reuben Binns, Max Van Kleek, Michael Veale, Ulrik Lyngs, Jun Zhao, and Nigel Shadbolt. 2018. ’It’s Reducing a Human Being to a Percentage’: Perceptions of Justice in Algorithmic Decisions. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–14. doi:10.1145/3173...
-
[5]
Rod Bond and Peter B. Smith. 1996. Culture and Conformity: A Meta-Analysis of Studies Using Asch’s (1952b, 1956) Line Judgment Task.Psychological Bulletin119, 1 (Jan. 1996), 111–137. doi:10.1037/0033-2909.119.1.111
-
[6]
Brannick, Eduardo Salas, and Carolyn W
Michael T. Brannick, Eduardo Salas, and Carolyn W. Prince. 1997.Team Performance Assessment and Measurement: Theory, Methods, and Applications. Psychology Press
1997
-
[7]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z. Gajos. 2021. To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making.Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (April 2021), 188:1–188:21. doi:10.1145/3449287
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[8]
Judee K. Burgoon and Jerold L. Hale. 1988. Nonverbal Expectancy Violations: Model Elaboration and Application to Immediacy Behaviors.Communication Monographs55, 1 (March 1988), 58–79. doi:10.1080/03637758809376158 Proc. ACM Hum.-Comput. Interact., Vol. 10, No. 6, Article CSCW106. Publication date: October 2026. Investigating LLM-Powered Dissenting Minorit...
-
[9]
João Carneiro, Pedro Saraiva, Luís Conceição, Ricardo Santos, Goreti Marreiros, and Paulo Novais. 2019. Predict- ing Satisfaction: Perceived Decision Quality by Decision-Makers in Web-based Group Decision Support Systems. Neurocomputing338 (April 2019), 399–417. doi:10.1016/j.neucom.2018.05.126
-
[10]
Linda G. Castillo, Collie W. Conoley, Daniel F. Brossart, and Alexander E. Quiros. 2007. Construction and Validation of the Intragroup Marginalization Inventory.Cultural Diversity & Ethnic Minority Psychology13, 3 (2007), 232–240. doi:10.1037/1099-9809.13.3.232
-
[11]
Jengchung Chen and Kyaw-Phyo Linn. 2012. User Satisfaction with Group Decision Making Process and Outcome. Journal of Computer Information Systems52 (June 2012), 30–39
2012
-
[12]
Chun-Wei Chiang, Zhuoran Lu, Zhuoyan Li, and Ming Yin. 2023. Are Two Heads Better Than One in AI-Assisted Decision Making? Comparing the Behavior and Performance of Groups and Individuals in Human-AI Collaborative Recidivism Risk Assessment. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing...
-
[13]
Chun-Wei Chiang, Zhuoran Lu, Zhuoyan Li, and Ming Yin. 2024. Enhancing AI-Assisted Group Decision Making through LLM-Powered Devil’s Advocate. InProceedings of the 29th International Conference on Intelligent User Interfaces (IUI ’24). Association for Computing Machinery, New York, NY, USA, 103–119. doi:10.1145/3640543.3645199
-
[14]
Amit K. Chopra and Munindar P. SIngh. 2018. Sociotechnical Systems and Ethics in the Large. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’18). Association for Computing Machinery, New York, NY, USA, 48–53. doi:10.1145/3278721.3278740
-
[15]
Elijah L. Claggett, Robert E. Kraut, and Hirokazu Shirado. 2025. Relational AI: Facilitating Intergroup Cooperation with Socially Aware Conversational Support. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–22. doi:10.1145/3706598.3713757
-
[16]
Nancy J. Cooke, Eduardo Salas, Janis A. Cannon-Bowers, and Renée J. Stout. 2000. Measuring Team Knowledge. Human Factors42, 1 (March 2000), 151–173. doi:10.1518/001872000779656561
-
[17]
Valdemar Danry, Pat Pataranutaporn, Yaoli Mao, and Pattie Maes. 2023. Don’t Just Tell Me, Ask Me: AI Systems That Intelligently Frame Explanations as Questions Improve Human Logical Discernment Accuracy over Causal AI Explanations. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery...
-
[18]
Advait Deshpande and Helen Sharp. 2022. Responsible AI Systems: Who Are the Stakeholders?. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’22). Association for Computing Machinery, New York, NY, USA, 227–236. doi:10.1145/3514094.3534187
-
[19]
Hyo Jin Do, Ha-Kyung Kong, Jaewook Lee, and Brian P. Bailey. 2022. How Should the Agent Communicate to the Group? Communication Strategies of a Conversational Agent in Group Chat Discussions.Proceedings of the ACM on Human-Computer Interaction6, CSCW2 (Nov. 2022), 387:1–387:23. doi:10.1145/3555112
-
[20]
Hyo Jin Do, Ha-Kyung Kong, Pooja Tetali, Karrie Karahalios, and Brian P. Bailey. 2023. Inform, Explain, or Control: Tech- niques to Adjust End-User Performance Expectations for a Conversational Agent Facilitating Group Chat Discussions. Proceedings of the ACM on Human-Computer Interaction7, CSCW2 (Oct. 2023), 343:1–343:26. doi:10.1145/3610192
-
[21]
Bich Ngoc (Rubi) Doan and Joseph Seering. 2025. The Design Space for Online Restorative Justice Tools: A Case Study with ApoloBot. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–19. doi:10.1145/3706598.3713598
-
[22]
Wen Duan, Naomi Yamashita, and Susan R. Fussell. 2019. Increasing Native Speakers’ Awareness of the Need to Slow Down in Multilingual Conversations Using a Real-Time Speech Speedometer.Proc. ACM Hum.-Comput. Interact.3, CSCW (Nov. 2019), 171:1–171:25. doi:10.1145/3359273
-
[23]
Robert F. Easley, Sarv Devaraj, and J. Michael Crant. 2003. Relating Collaborative Technology Use to Teamwork Quality and Performance: An Empirical Analysis.Journal of Management Information Systems19, 4 (April 2003), 247–265. doi:10.1080/07421222.2003.11045747
-
[24]
Amy Edmondson. 1999. Psychological Safety and Learning Behavior in Work Teams.Administrative Science Quarterly 44, 2 (June 1999), 350–383. doi:10.2307/2666999
-
[25]
Vera Liao, Michael Muller, Mark O
Upol Ehsan, Q. Vera Liao, Michael Muller, Mark O. Riedl, and Justin D. Weisz. 2021. Expanding Explainability: Towards Social Transparency in AI Systems. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–19. doi:10.1145/3411764.3445188
-
[26]
Donelson R. Forsyth. 2018.Group Dynamics. Cengage Learning
2018
-
[27]
John R. P. French Jr. and Bertram Raven. 1959. The Bases of Social Power. InStudies in Social Power. Univer. Michigan, Oxford, England, 150–167
1959
-
[28]
Yue Fu, Sami Foell, Xuhai Xu, and Alexis Hiniker. 2024. From Text to Self: Users’ Perception of AIMC Tools on Interpersonal Communication and Self. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–17. doi:10.1145/3613904.3641955 Proc. ACM Hum.-Comput. Interact., ...
-
[29]
Suyash Fulay and Deb Roy. 2025. The Empty Chair: Using LLMs to Raise Missing Perspectives in Policy Deliberations. arXiv:2503.13812 [cs] doi:10.48550/arXiv.2503.13812
-
[30]
Fraide A. Ganotice, Linda Chan, Xiaoai Shen, Angie Ho Yan Lam, Gloria Hoi Yan Wong, Rebecca Ka Wai Liu, and George L. Tipoe. 2022. Team Cohesiveness and Collective Efficacy Explain Outcomes in Interprofessional Education. BMC Medical Education22 (Nov. 2022), 820. doi:10.1186/s12909-022-03886-7
-
[31]
Ge Gao, Naomi Yamashita, Ari MJ Hautasaari, Andy Echenique, and Susan R. Fussell. 2014. Effects of Public vs. Private Automated Transcripts on Multiparty Communication between Native and Non-Native English Speakers. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’14). Association for Computing Machinery, New York, NY, U...
-
[32]
Ge Gao, Naomi Yamashita, Ari M.J. Hautasaari, and Susan R. Fussell. 2015. Improving Multilingual Collaboration by Displaying How Non-native Speakers Use Automated Transcripts and Bilingual Dictionaries. InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (CHI ’15). Association for Computing Machinery, New York, NY, USA, 3...
-
[33]
Xiao Ge, Chunchen Xu, Daigo Misaki, Hazel Rose Markus, and Jeanne L Tsai. 2024. How Culture Shapes What People Want From AI. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3613904.3642660
-
[34]
Harold B. Gerard, Roland A. Wilhelmy, and Edward S. Conolley. 1968. Conformity and Group Size.Journal of Personality and Social Psychology8, 1, Pt.1 (1968), 79–82. doi:10.1037/h0025325
-
[35]
Jill C. Glick and Kelley Staley. 2007. Inflicted Traumatic Brain Injury: Advances in Evaluation and Collaborative Diagnosis.Pediatric Neurosurgery43, 5 (Sept. 2007), 436–441. doi:10.1159/000106400
-
[36]
Jarod Govers, Eduardo Velloso, Vassilis Kostakos, and Jorge Goncalves. 2024. AI-Driven Mediation Strategies for Audience Depolarisation in Online Debates. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–18. doi:10.1145/3613904.3642322
-
[37]
G. Mark Grimes, Ryan M. Schuetzler, and Justin Scott Giboney. 2021. Mental Models and Expectation Violations in Conversational AI Interactions.Decision Support Systems144 (May 2021), 113515. doi:10.1016/j.dss.2021.113515
-
[38]
Jeffrey T Hancock, Mor Naaman, and Karen Levy. 2020. AI-Mediated Communication: Definition, Research Agenda, and Ethical Considerations.Journal of Computer-Mediated Communication25, 1 (March 2020), 89–100. doi:10.1093/ jcmc/zmz022
2020
-
[39]
Sandra G. Hart and Lowell E. Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. InAdvances in Psychology, Peter A. Hancock and Najmedin Meshkati (Eds.). Human Mental Workload, Vol. 52. North-Holland, 139–183. doi:10.1016/S0166-4115(08)62386-9
-
[40]
Gonzalez, Darío Andrés Silva Moran, Steven I
Jessica He, Stephanie Houde, Gabriel E. Gonzalez, Darío Andrés Silva Moran, Steven I. Ross, Michael Muller, and Justin D. Weisz. 2024. AI and the Future of Collaborative Work: Group Ideation with an LLM in a Virtual Canvas. In Proceedings of the 3rd Annual Meeting of the Symposium on Human-Computer Interaction for Work (CHIWORK ’24). Association for Compu...
-
[41]
Geert Hofstede. 2011. Dimensionalizing Cultures: The Hofstede Model in Context.Online Readings in Psychology and Culture2, 1 (Dec. 2011). doi:10.9707/2307-0919.1014
-
[42]
Jess Hohenstein, Rene F. Kizilcec, Dominic DiFranzo, Zhila Aghajari, Hannah Mieczkowski, Karen Levy, Mor Naaman, Jeffrey Hancock, and Malte F. Jung. 2023. Artificial Intelligence in Communication Impacts Language and Social Relationships.Scientific Reports13, 1 (April 2023), 5487. doi:10.1038/s41598-023-30938-9
-
[43]
Yoyo Tsung-Yu Hou, EunJeong Cheon, and Malte F. Jung. 2024. Power in Human-Robot Interaction. InProceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction (HRI ’24). Association for Computing Machinery, New York, NY, USA, 269–282. doi:10.1145/3610977.3634949
-
[44]
Should I Follow the Human, or Follow the Robot?
Yoyo Tsung-Yu Hou, Wen-Ying Lee, and Malte Jung. 2023. “Should I Follow the Human, or Follow the Robot?” — Robots in Power Can Have More Influence Than Humans on Decision-Making. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3544548.3581066
-
[45]
Ross, Dario Andres Silva Moran, Gabriel Enrique Gonzalez, Siya Kunde, Morgan A
Stephanie Houde, Kristina Brimijoin, Michael Muller, Steven I. Ross, Dario Andres Silva Moran, Gabriel Enrique Gonzalez, Siya Kunde, Morgan A. Foreman, and Justin D. Weisz. 2025. Controlling AI Agent Participation in Group Conversations: A Human-Centered Approach. arXiv:2501.17258 [cs] doi:10.1145/3708359.3712089
-
[46]
Angel Hsing-Chi Hwang and Andrea Stevenson Won. 2024. The Sound of Support: Gendered Voice Agent as Support to Minority Teammates in Gender-Imbalanced Team. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–22. doi:10.1145/3613904.3642202
-
[47]
Jamieson, Piercarlo Valdesolo, and Brett J
Jeremy P. Jamieson, Piercarlo Valdesolo, and Brett J. Peters. 2014. Sympathy for the Devil? The Physiological and Psychological Effects of Being an Agent (and Target) of Dissent during Intragroup Conflict.Journal of Experimental Social Psychology55 (Nov. 2014), 221–227. doi:10.1016/j.jesp.2014.07.011 Proc. ACM Hum.-Comput. Interact., Vol. 10, No. 6, Artic...
-
[48]
Irving L. Janis. 1972.Victims of Groupthink: A Psychological Study of Foreign-Policy Decisions and Fiascoes. Houghton Mifflin, Oxford, England. viii, 277 pages
1972
-
[49]
Irving L. Janis. 1982.Groupthink : Psychological Studies of Policy Decisions and Fiascoes. Boston : Houghton Mifflin
1982
-
[50]
Jessup, Terry Connolly, and Jolene Galegher
Leonard M. Jessup, Terry Connolly, and Jolene Galegher. 1990. The Effects of Anonymity on GDSS Group Process with an Idea-Generating Task.MIS Quarterly14, 3 (1990), 313–321. jstor:248893 doi:10.2307/248893
-
[51]
Tatsuya Kameda and Shinkichi Sugimori. 1993. Psychological Entrapment in Group Decision Making: An Assigned Decision Rule and a Groupthink Phenomenon.Journal of Personality and Social Psychology65, 2 (1993), 282–292. doi:10.1037/0022-3514.65.2.282
-
[52]
Herbert C. Kelman. 1958. Compliance, Identification, and Internalization Three Processes of Attitude Change.Journal of Conflict Resolution2, 1 (March 1958), 51–60. doi:10.1177/002200275800200106
-
[53]
Soomin Kim, Jinsu Eun, Changhoon Oh, Bongwon Suh, and Joonhwan Lee. 2020. Bot in the Bunch: Facilitating Group Chat Discussion by Improving Efficiency and Participation with a Chatbot. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3313831.3376785
-
[54]
Sang Gyu Kwak and Jong Hae Kim. 2017. Central limit theorem: the cornerstone of modern statistics.Korean journal of anesthesiology70, 2 (2017), 144
2017
-
[55]
Vera Liao, Alison Smith-Renner, and Chenhao Tan
Vivian Lai, Chacha Chen, Q. Vera Liao, Alison Smith-Renner, and Chenhao Tan. 2021. Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies. https://arxiv.org/abs/2112.11471v1
arXiv 2021
-
[56]
Vivian Lai, Chacha Chen, Alison Smith-Renner, Q. Vera Liao, and Chenhao Tan. 2023. Towards a Science of Human-AI Decision Making: An Overview of Design Space in Empirical Human-Subject Studies. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’23). Association for Computing Machinery, New York, NY, USA, 1369–13...
-
[57]
Tuan-He Lee and Susan R. Fussell. 2025. Countering Misinformation in Private Messaging Groups: Insights From a Fact-checking Chatbot.Proc. ACM Hum.-Comput. Interact.9, GROUP (Jan. 2025), GROUP10:1–GROUP10:30. doi:10. 1145/3701189
2025
-
[58]
Joanne Leong, John Tang, Edward Cutrell, Sasa Junuzovic, Gregory Paul Baribault, and Kori Inkpen. 2024. Dittos: Personalized, Embodied Agents That Participate in Meetings When You Are Unavailable.Proc. ACM Hum.-Comput. Interact.8, CSCW2 (Nov. 2024), 494:1–494:28. doi:10.1145/3687033
-
[59]
Kurt Lewin. 1939. Field Theory and Experiment in Social Psychology: Concepts and Methods.Amer. J. Sociology44, 6 (1939), 868–896. doi:10.1086/218177
-
[60]
Xiaoyan Li, Naomi Yamashita, Wen Duan, Yoshinari Shirai, and Susan R. Fussell. 2022. Improving Non-Native Speakers’ Participation with an Automatic Agent in Multilingual Groups.Proc. ACM Hum.-Comput. Interact.7, GROUP (Dec. 2022), 12:1–12:28. doi:10.1145/3567562
-
[61]
Q.Vera Liao and S. Shyam Sundar. 2022. Designing for Responsible Trust in AI Systems: A Communication Perspective. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 1257–1268. doi:10.1145/3531146.3533182
-
[62]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172 [cs] doi:10.48550/arXiv.2307.03172
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.03172 2023
-
[63]
Diniz Lopes, Jorge Vala, Dominique Oberlé, and Ewa Drozda-Senkowska. 2014. Validation of group decisions : Why and when perceived group heterogeneity is relevant.Revue internationale de psychologie sociale27, 2 (2014), 35–49
2014
-
[64]
Shuai Ma, Ying Lei, Xinru Wang, Chengbo Zheng, Chuhan Shi, Ming Yin, and Xiaojuan Ma. 2023. Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision- Making. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machin...
-
[65]
Shuai Ma, Chenyi Zhang, Xinru Wang, Xiaojuan Ma, and Ming Yin. 2024. Beyond Recommender: An Exploratory Study of the Effects of Different AI Roles in AI-Assisted Decision Making. arXiv:2403.01791 [cs] doi:10.48550/arXiv.2403.01791
-
[66]
Colin MacDougall and Frances Baum. 1997. The Devil’s Advocate: A Strategy to Avoid Groupthink and Stimulate Discussion in Focus Groups.Qualitative Health Research7, 4 (Nov. 1997), 532–541. doi:10.1177/104973239700700407
-
[67]
Boris Maciejovsky, Matthias Sutter, David V. Budescu, and Patrick Bernau. 2013. Teams Make You Smarter: How Exposure to Teams Improves Individual Decisions in Probability and Reasoning Tasks.Management Science59, 6 (June 2013), 1255–1270. doi:10.1287/mnsc.1120.1668
-
[68]
Richard O. Mason. 1969. A Dialectical Approach to Strategic Planning.Management Science15, 8 (April 1969), B–403. doi:10.1287/mnsc.15.8.B403
-
[69]
Dave Mbiazi, Meghana Bhange, Maryam Babaei, Ivaxi Sheth, and Patrik Joslin Kenfack. 2023. Survey on AI Ethics: A Socio-technical Perspective. arXiv:2311.17228 [cs] doi:10.48550/arXiv.2311.17228
-
[70]
Hancock, Mor Naaman, Malte Jung, and Jess Hohenstein
Hannah Mieczkowski, Jeffrey T. Hancock, Mor Naaman, Malte Jung, and Jess Hohenstein. 2021. AI-Mediated Commu- nication: Language Use and Interpersonal Effects in a Referential Communication Task.Proc. ACM Hum.-Comput. Proc. ACM Hum.-Comput. Interact., Vol. 10, No. 6, Article CSCW106. Publication date: October 2026. CSCW106:32 Soohwan Lee, Seoyeong Hwang, ...
-
[71]
Federico Milana, Enrico Costanza, and Joel E Fischer. 2023. Chatbots as Advisers: The Effects of Response Variability and Reply Suggestion Buttons. InProceedings of the 5th International Conference on Conversational User Interfaces (CUI ’23). Association for Computing Machinery, New York, NY, USA, 1–10. doi:10.1145/3571884.3597132
-
[72]
Serge Moscovici and Elisabeth Lage. 1976. Studies in Social Influence III: Majority versus Minority Influence in a Group.European Journal of Social Psychology6, 2 (1976), 149–174. doi:10.1002/ejsp.2420060202
-
[73]
Imani Munyaka, Zahra Ashktorab, Casey Dugan, J. Johnson, and Qian Pan. 2023. Decision Making Strategies and Team Efficacy in Human-AI Teams.Proc. ACM Hum.-Comput. Interact.7, CSCW1 (April 2023), 43:1–43:24. doi:10.1145/3579476
-
[74]
Clifford Nass, Jonathan Steuer, and Ellen R. Tauber. 1994. Computers Are Social Actors. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’94). Association for Computing Machinery, New York, NY, USA, 72–78. doi:10.1145/191666.191703
-
[75]
Charlan Nemeth, Keith Brown, and John Rogers. 2001. Devil’s Advocate versus Authentic Dissent: Stimulating Quantity and Quality.European Journal of Social Psychology31, 6 (2001), 707–720. doi:10.1002/ejsp.58
-
[76]
Soya Park and Chinmay Kulkarni. 2024. Thinking Assistants: LLM-Based Conversational Assistants That Help Users Think By Asking Rather than Answering. arXiv:2312.06024 [cs] doi:10.48550/arXiv.2312.06024
-
[77]
Souren Paul, Priya Seetharaman, and Katikireddy Ramamurthy. 2004.User Satisfaction with System, Decision Process, and Outcome in GDSS Based Meeting: An Experimental Investigation. Vol. 37. 46 pages. doi:10.1109/HICSS.2004.1265108
-
[78]
Weisswange, and Marc Hassenzahl
Tuan Vu Pham, Thomas H. Weisswange, and Marc Hassenzahl. 2024. Embodied Mediation in Group Ideation – A Gestural Robot Can Facilitate Consensus-Building. InProceedings of the 2024 ACM Designing Interactive Systems Conference (DIS ’24). Association for Computing Machinery, New York, NY, USA, 2611–2632. doi:10.1145/3643834. 3660696
-
[79]
Ritika Poddar, Rashmi Sinha, Mor Naaman, and Maurice Jakesch. 2023. AI Writing Assistants Influence Topic Choice in Self-Presentation. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems (CHI EA ’23). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3544549.3585893
-
[80]
Fabian Reinkemeier, Ulrich Gnewuch, and Waldemar Toporowski. 2022. Can Humanizing Voice Assistants Unleash the Potential of Voice Commerce?. InProceedings of the 43rd International Conference on Information Systems (ICIS). Association for Information Systems, Copenhagen, Denmark. https://aisel.aisnet.org/icis2022/hci_robot/hci_robot/3
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.