When to Personalize Household Object Search: A Rigidity-Gated Hybrid Policy
Pith reviewed 2026-07-03 23:22 UTC · model grok-4.3
The pith
A rigidity-gated hybrid policy personalizes robot searches for household objects only when placement varies by resident traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
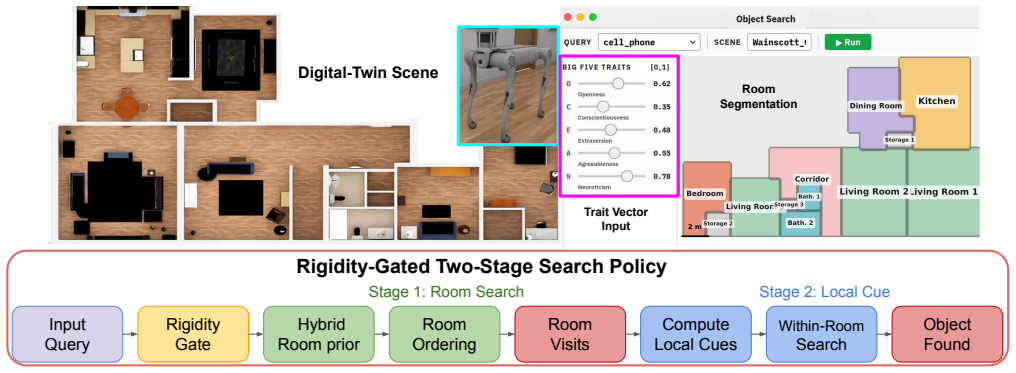
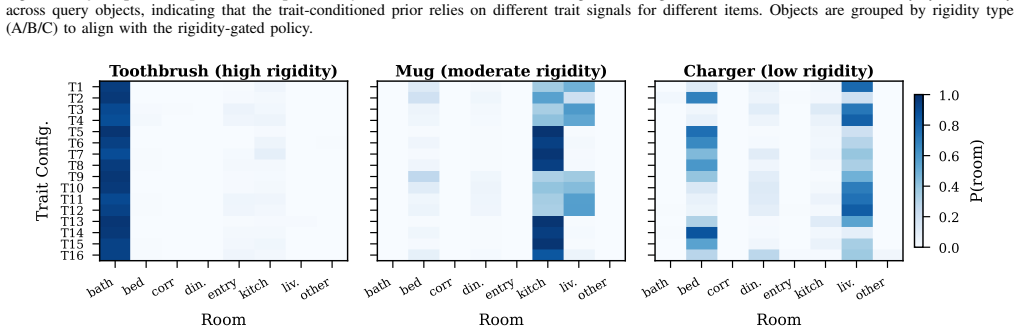
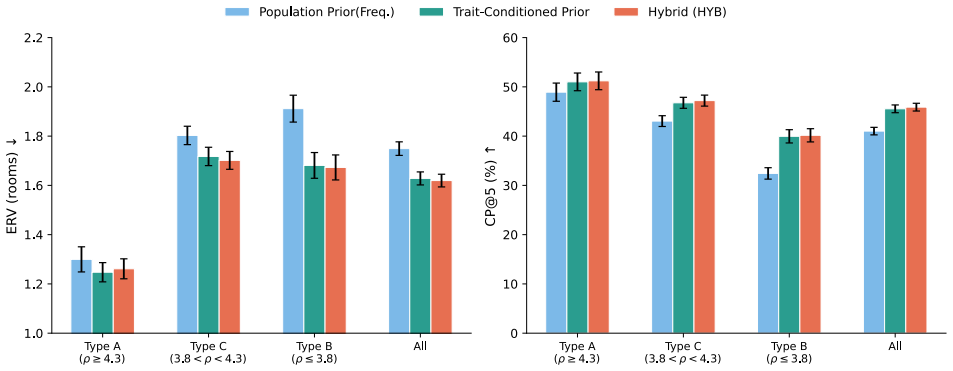
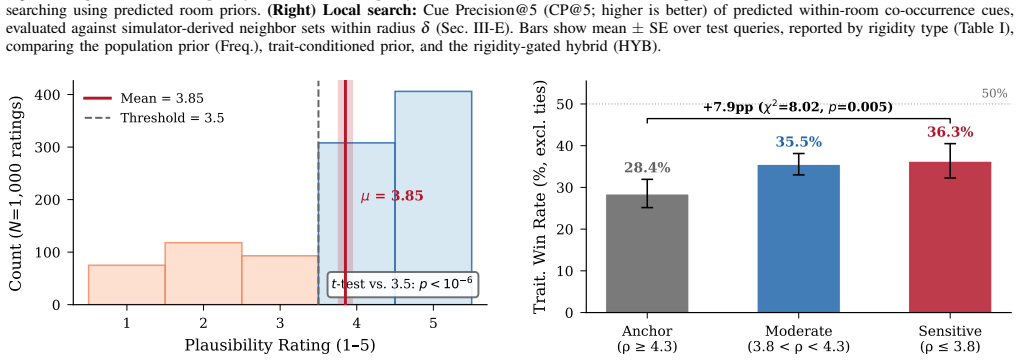
In a unified human study (N=200), personalization is favored primarily for low-rigidity objects (p=0.005), while the population-frequency baseline remains strong for universally placed items, yielding a decision rule for when to personalize. PerSim combines a trait-conditioned prior with the baseline via rigidity gating, produces room-level and co-occurrence cues from continuous personality vectors, and lowers overall search cost by integrating visitation and checking effort.
What carries the argument
The rigidity-gated hybrid policy PerSim, which activates the trait-conditioned room-level prior and within-room cues only for objects whose placement behavior varies across residents.
If this is right
- Personalization improves expected search performance mainly on objects with high placement variability.
- A population-frequency baseline suffices without loss for objects placed consistently across residents.
- Continuous interpolation across five-dimensional trait space yields small but measurable gains over discrete matching.
- End-to-end cost savings arise from combining room visitation planning with within-room cue verification rather than from prediction accuracy alone.
Where Pith is reading between the lines
- Robots using this rule could avoid collecting long-term personal data in households with mostly stable object placements.
- The same gating logic might extend to other variable household behaviors such as appliance use or furniture arrangement.
- Real-robot deployments could test whether the simulated cost reductions hold when perception noise and movement constraints are added.
- Adding context like time of day or recent activity might sharpen the rigidity threshold without new trait data.
Load-bearing premise
The simulation pipeline, calibrated solely through subjective human plausibility ratings, correctly captures real-world object-placement dynamics across diverse homes and trait vectors.
What would settle it
A field trial in actual homes where the hybrid policy shows no reduction in search cost or no participant preference over the pure population baseline for low-rigidity objects would falsify the decision rule.
Figures



read the original abstract
Service robots searching for household objects rely on spatial priors to reduce search cost, yet object locations can vary with resident traits. Collecting longitudinal, trait-specific in-home trajectories is invasive and hard to scale. We study when personalization helps and propose PerSim, a rigidity-gated hybrid policy that combines a trait-conditioned prior with a population-frequency baseline, personalizing only when placement behavior is variable. To scale resident-conditioned dynamics, we employ a human-calibrated simulation pipeline to generate and validate object-placement transitions in diverse home layouts, and train a predictor that injects continuous Big Five vectors to output room-level priors and within-room co-occurrence cues. In a unified human study (N=200), dual-layer validation shows that (i) synthetic transitions are judged behaviorally plausible (mean 3.85/5, p < 1e-6), and (ii) in a blinded A/B comparison, personalization is favored primarily for low-rigidity objects (p=0.005), while the population-frequency baseline remains strong for universally placed items, yielding a decision rule for when to personalize. In an offline objective test, we observe a small but significant improvement on unseen continuous trait vectors over nearest discrete configuration matching (p=0.035), supporting interpolation in five-dimensional trait space. Finally, in a home digital twin we show that PerSim reduces expected search cost by combining room visitation effort with within-room cue checking, demonstrating end-to-end gains beyond isolated prediction metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PerSim, a rigidity-gated hybrid policy for household object search by service robots. It combines a trait-conditioned prior (using continuous Big Five personality vectors) with a population-frequency baseline, personalizing only for objects with variable placement behavior. A human-calibrated simulation pipeline generates placement transitions to train the predictor, validated in a N=200 human study showing that personalization is favored for low-rigidity objects (p=0.005), with supporting offline tests (p=0.035) and digital twin demonstrations of reduced search cost.
Significance. If the simulation faithfully captures real placement dynamics, the work provides a practical, evidence-based rule for when to personalize in robotics applications, balancing the costs of personalization against benefits. The dual validation (plausibility ratings and A/B preference) and interpolation in trait space are notable strengths if the grounding holds.
major comments (2)
- [Abstract (simulation pipeline and dual-layer validation)] Abstract (simulation pipeline and dual-layer validation): The simulation is grounded solely by a mean behavioral-plausibility rating of 3.85/5 (p<1e-6); this subjective measure does not directly confirm that the generated conditional distributions reproduce empirical trait-conditioned placement variability or rigidity statistics across homes, which is load-bearing for the gated policy's decision rule.
- [Abstract (human study and p-values)] Abstract (human study and p-values): The reported p=0.005 for low-rigidity preference and p=0.035 for offline improvement lack accompanying details on methods, data exclusion, multiple comparisons, or how rigidity is quantified from the simulation, making it difficult to assess whether post-hoc choices affect the central claims about when to personalize.
minor comments (1)
- [Abstract] The term 'rigidity' is used without a precise definition in the provided abstract; a formal definition would aid clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our validation approach. We address each major comment below and will revise the manuscript to incorporate clarifications and additional details where appropriate.
read point-by-point responses
-
Referee: The simulation is grounded solely by a mean behavioral-plausibility rating of 3.85/5 (p<1e-6); this subjective measure does not directly confirm that the generated conditional distributions reproduce empirical trait-conditioned placement variability or rigidity statistics across homes, which is load-bearing for the gated policy's decision rule.
Authors: We agree that the behavioral-plausibility rating is an indirect proxy rather than a direct empirical match to real-world conditional distributions. Collecting longitudinal trait-conditioned placement data at scale remains logistically and ethically challenging, which motivated the simulation design. In the revised manuscript we will add an expanded limitations discussion explicitly noting this gap, provide further details on how the simulation was calibrated to aggregate human placement statistics, and include supplementary analyses showing how rigidity statistics emerge from the generated transitions. revision: yes
-
Referee: The reported p=0.005 for low-rigidity preference and p=0.035 for offline improvement lack accompanying details on methods, data exclusion, multiple comparisons, or how rigidity is quantified from the simulation, making it difficult to assess whether post-hoc choices affect the central claims about when to personalize.
Authors: We concur that the current manuscript provides insufficient methodological transparency for the reported p-values. The revision will include a new subsection (or appendix) that fully specifies the statistical tests, data exclusion rules, multiple-comparison corrections, and the precise algorithm used to compute object rigidity from the simulated placement transitions. This will allow readers to evaluate the robustness of the decision rule for when to personalize. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation chain relies on a simulation pipeline whose outputs are calibrated and validated against independent human plausibility ratings (mean 3.85/5) and a separate N=200 blinded human study that directly measures preference for personalization on low-rigidity objects (p=0.005). The predictor is trained on simulation-generated transitions, but the final decision rule, policy performance claims, and offline interpolation test (p=0.035) are grounded in these external human benchmarks rather than reducing to the simulation by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the approach remains self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient dynamic object search in home environment by mobile robot: A priori knowledge-based approach,
Y . Zhang, G. Tian, J. Lu, M. Zhang, and S. Zhang, “Efficient dynamic object search in home environment by mobile robot: A priori knowledge-based approach,”IEEE Transactions on Vehicular Technology, vol. 68, no. 10, pp. 9466–9477, 2019
2019
-
[2]
Semantic object maps for robotic housework–representation, acquisition and use,
D. Pangercic, B. Pitzer, M. Tenorth, and M. Beetz, “Semantic object maps for robotic housework–representation, acquisition and use,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 4644–4651
2012
-
[3]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 4247– 4258
2020
-
[4]
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation,
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sunet al., “Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation,” inConference on Robot Learning. PMLR, 2023, pp. 80– 93
2023
-
[5]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–22
2023
-
[6]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
The big-five trait taxonomy: History, measurement, and theoretical perspectives,
O. P. John and S. Srivastava, “The big-five trait taxonomy: History, measurement, and theoretical perspectives,”Handbook of Personality: Theory and Research, vol. 2, pp. 102–138, 1999
1999
-
[8]
Seek: Semantic reasoning for object goal navigation in real world inspection tasks,
M. F. Ginting, S.-K. Kim, D. D. Fan, M. Palieri, M. J. Kochen- derfer, and A.-a. Agha-Mohammadi, “Seek: Semantic reasoning for object goal navigation in real world inspection tasks,”arXiv preprint arXiv:2405.09822, 2024
-
[9]
Tidee: Tidying up novel rooms using visuo-semantic commonsense priors,
G. Sarch, Z. Fang, A. W. Harley, P. Schydlo, M. J. Tarr, S. Gupta, and K. Fragkiadaki, “Tidee: Tidying up novel rooms using visuo-semantic commonsense priors,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 480–496
2022
-
[10]
Housekeep: Tidying virtual households using commonsense reasoning,
Y . Kant, A. Ramachandran, S. Yenamandra, I. Gilitschenski, D. Batra, A. Szot, and H. Agrawal, “Housekeep: Tidying virtual households using commonsense reasoning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 355–373
2022
-
[11]
A room with a cue: Personality judgments based on offices and bedrooms,
S. D. Gosling, S. J. Ko, T. Mannarelli, and M. E. Morris, “A room with a cue: Personality judgments based on offices and bedrooms,”Journal of Personality and Social Psychology, vol. 82, no. 3, pp. 379–398, 2002
2002
-
[12]
Organizing objects by predicting user preferences through collaborative filtering,
N. Abdo, C. Stachniss, L. Spinello, and W. Burgard, “Organizing objects by predicting user preferences through collaborative filtering,” The International Journal of Robotics Research, vol. 35, no. 13, pp. 1587–1608, 2016
2016
-
[13]
Tidybot: Personalized robot assistance with large language models,
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, and T. Funkhouser, “Tidybot: Personalized robot assistance with large language models,”Autonomous Robots, vol. 47, no. 8, pp. 1087–1102, 2023
2023
-
[14]
V oyager: An open-ended embodied agent with large language models,
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[15]
Inner monologue: Embodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotaret al., “Inner monologue: Embodied reasoning through planning with language models,” in Conference on Robot Learning. PMLR, 2023, pp. 1769–1782
2023
-
[16]
Measuring personality in one minute or less: A 10-item short version of the big five inventory in english and german,
B. Rammstedt and O. P. John, “Measuring personality in one minute or less: A 10-item short version of the big five inventory in english and german,”Journal of Research in Personality, vol. 41, no. 1, pp. 203–212, 2007
2007
-
[17]
Taguchi approach to design optimization for quality and cost: An overview,
R. Unal and E. B. Dean, “Taguchi approach to design optimization for quality and cost: An overview,” inProceedings of the Annual Conference of the International Society of Parametric Analysts, 1991, pp. 28–32
1991
-
[18]
Off-line quality control, parameter design, and the taguchi method,
R. N. Kackar, “Off-line quality control, parameter design, and the taguchi method,”Journal of Quality Technology, vol. 17, no. 4, pp. 176–188, 1985
1985
-
[19]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.