Promise-Future Synchronization for Cluster Asynchronous Many-Task Runtimes via MPI One-Sided Communication
Pith reviewed 2026-07-02 01:03 UTC · model grok-4.3
The pith
Promise-future model via MPI one-sided communication extends AMT runtime to support dynamic algorithms like HLU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
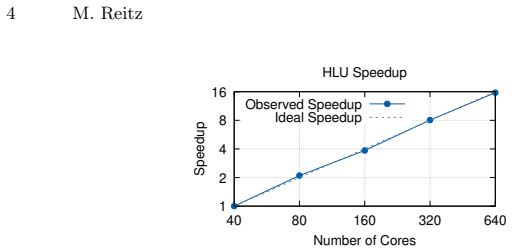
The ItoyoriFBC variant with promise-future synchronization supports dynamic algorithms such as Hierarchical LU factorization by using MPI one-sided communication, achieving near-ideal scaling with a 15.6x speedup on up to 16 nodes.
What carries the argument
Promise-future model implemented with MPI one-sided communication to handle dynamic task dependencies.
Load-bearing premise
The promise-future model can be realized with MPI one-sided communication in a way that preserves correctness and delivers the reported scaling without hidden costs from the synchronization mechanism itself.
What would settle it
A test showing that the HLU implementation fails to scale near-ideally or produces incorrect results due to synchronization issues would falsify the claim.
Figures

read the original abstract
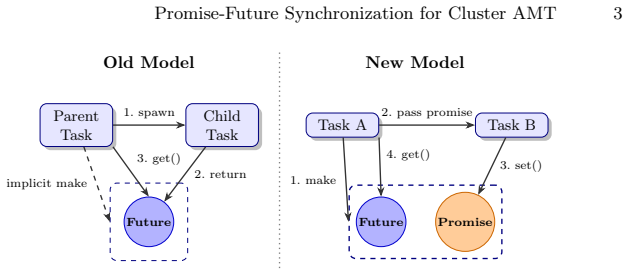
Asynchronous Many-Task (AMT) runtimes use futures as placeholders for values produced by other tasks. In the ItoyoriFBC AMT runtime, the existing future-only model binds each future to its producer at creation time and requires the number of tasks that read each future to be fixed at compile time. This prevents directly expressing algorithms that create dependencies dynamically. We extend ItoyoriFBC with an implementation of a promise-future model that lifts these limitations. Thereby, our ItoyoriFBC variant supports dynamic algorithms such as Hierarchical LU factorization (HLU). We experimentally evaluated our implementation using HLU on up to 16 nodes and observed near-ideal scaling with a 15.6x speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the ItoyoriFBC AMT runtime, which previously bound futures to producers at creation time and required compile-time fixed reader counts, by implementing a promise-future model via MPI one-sided communication. This change enables dynamic task graphs, including Hierarchical LU factorization (HLU). The authors report an experimental evaluation on up to 16 nodes showing near-ideal scaling and a 15.6x speedup.
Significance. If the implementation correctly realizes promise-future synchronization without introducing hidden costs and the scaling result holds under standard HPC evaluation practices, the work would be a useful engineering contribution to cluster-scale AMT systems. It demonstrates a concrete path to support dynamic dependencies while retaining the performance characteristics of MPI RMA, which could benefit other task-based runtimes that currently restrict dependency creation.
major comments (1)
- [Abstract] Abstract: the central performance claim ('near-ideal scaling with a 15.6x speedup' for HLU) is presented with no description of the experimental setup, baseline (original ItoyoriFBC or other runtimes), node configuration, measurement protocol, number of trials, or error bars. This detail is load-bearing for assessing whether the MPI one-sided promise-future implementation preserves correctness and delivers the reported scaling without synchronization overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim ('near-ideal scaling with a 15.6x speedup' for HLU) is presented with no description of the experimental setup, baseline (original ItoyoriFBC or other runtimes), node configuration, measurement protocol, number of trials, or error bars. This detail is load-bearing for assessing whether the MPI one-sided promise-future implementation preserves correctness and delivers the reported scaling without synchronization overhead.
Authors: We agree that the abstract would benefit from additional context on the experimental setup to support the central claim. In the revised version we will expand the abstract to explicitly state the baseline (original ItoyoriFBC), the scale (up to 16 nodes), and that full details of the measurement protocol, number of trials, and error bars appear in the experimental evaluation section. Abstract length limits preclude including every protocol detail directly in the abstract, but the added sentence will make the claim more self-contained while preserving conciseness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an engineering description of an implementation extension to ItoyoriFBC that adds promise-future support via MPI one-sided communication, followed by an empirical evaluation on HLU showing measured scaling. No equations, derivations, parameter fits, or predictions appear in the supplied text. The central claim reduces to an experimental observation rather than any self-referential construction or self-citation chain. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hamouda , title =
Sara S. Hamouda , title =
-
[2]
Sadayappan and Chau-Wen Tseng , booktitle =
James Dinan and Stephen Olivier and Gerald Sabin and Jan Prins and P. Sadayappan and Chau-Wen Tseng , booktitle =. Dynamic Load Balancing of Unbalanced Computations Using Message Passing , year =
-
[3]
Martin Schulz and Dieter Kranzlm\". On the Inevitability of Integrated HPC Systems and How They Will Change HPC System Operations , year =. doi:10.1145/3468044.3468046 , booktitle =
-
[4]
Mia Reitz , title =. Proc. Int. Conf. on Cluster Computing (CLUSTER), Extended Abstract and Poster , publisher =. 2021 , pages =. doi:10.1109/Cluster48925.2021.00075 , keywords =
-
[5]
Mia Reitz , title =. Proc. Int. Parallel and Distributed Processing Symp. (IPDPS), Ph.D. Forum, Extended Abstract , year =. doi:10.1109/IPDPSW52791.2021.00160 , keywords =
-
[6]
Containment Domains: A Scalable, Efficient, and Flexible Resilience Scheme for Exascale Systems , year =
Jinsuk Chung and Ikhwan Lee and Michael Sullivan and Jee Ho Ryoo and Dong Wan Kim and Doe Hyun Yoon and Larry Kaplan and Mattan Erez , booktitle =. Containment Domains: A Scalable, Efficient, and Flexible Resilience Scheme for Exascale Systems , year =
-
[7]
, title =
Kapil Arya and Gene Cooperman and Rohan Garg and Jiajun Cao and and Artem Polyakov. , title =
-
[8]
Embracing Explicit Communication in Work-Stealing Runtime Systems , author =
-
[9]
2008 , isbn =
Monte Carlo methods , author =. 2008 , isbn =
2008
-
[10]
PCJ: HPC Challenge Award at Supecomputing'14 , urldate =
Piotr Ba. PCJ: HPC Challenge Award at Supecomputing'14 , urldate =
-
[11]
Reinit++: Evaluating the Performance of Global-Restart Recovery Methods For MPI Fault Tolerance , author =. Proc. Int. Conf. on High Performance Computing (ISC) , year =
-
[12]
CRAFT: A Library for Easier Application-Level Checkpoint/Restart and Automatic Fault Tolerance , year =
Faisal Shahzad and Jonas Thies and Moritz Kreutzer and Thomas Zeiser and Georg Hager and Gerhard Wellein , journal =. CRAFT: A Library for Easier Application-Level Checkpoint/Restart and Automatic Fault Tolerance , year =
-
[13]
Katz and Hemanth Kolla and Jacqueline Chen and Scott Klasky and Manish Parashar , booktitle =
Marc Gamell and Daniel S. Katz and Hemanth Kolla and Jacqueline Chen and Scott Klasky and Manish Parashar , booktitle =. Exploring Automatic, Online Failure Recovery for Scientific Applications at Extreme Scales , year =
-
[14]
Kuang-Hua Huang and Jacob A. Abraham , title =. 1984 , publisher =. doi:10.1109/TC.1984.1676475 , journal =
-
[15]
Distributed Task-Based Runtime Systems - Current State and Micro-Benchmark Performance , year =
Reazul Hoque and Pavel Shamis , booktitle =. Distributed Task-Based Runtime Systems - Current State and Micro-Benchmark Performance , year =
-
[16]
PufferFish: NUMA-Aware Work-stealing Library using Elastic Tasks , year =
Vivek Kumar , booktitle =. PufferFish: NUMA-Aware Work-stealing Library using Elastic Tasks , year =
-
[17]
From tasks graphs to asynchronous distributed checkpointing with local restart , author =. Proc. Int. Conf. on High Performance Computing, Networking, Storage and Analysis (SC) Workshops (FTXS) , publisher =. 2020 , doi =
2020
-
[18]
Gengbin Zheng and Lixia Shi and L.V. Kale , booktitle =. FTC-Charm++: An In-Memory Checkpoint-Based Fault Tolerant Runtime for Charm++ and MPI , year =. doi:10.1109/CLUSTR.2004.1392606 , publisher =
-
[19]
Proceeding Euro-Par: Parallel Processing , year =
Sri Raj Paul and Akihiro Hayashi and Nicole Slattengren and Hemanth Kolla and Matthew Whitlock and Seonmyeong Bak and Keita Teranishi and Jackson Mayo and Vivek Sarkar , title =. Proceeding Euro-Par: Parallel Processing , year =
-
[20]
Concurrency and Computation: Practice and Experience (CCPE) , publisher =
Aurelien Bouteiller and George Bosilca and Jack Dongarra , title =. Concurrency and Computation: Practice and Experience (CCPE) , publisher =. doi:10.1002/cpe.1589 , year =
-
[21]
Amina Guermouche and Thomas Ropars and Elisabeth Brunet and Marc Snir and Franck Cappello , title =. Int. Parallel and Distributed Processing Symp. (IPDPS) , publisher =. 2011 , pages =
2011
-
[22]
Checkpoint/Restart for Lagrangian particle mesh with AMR in community code FLASH-X , author =. Int. Symp. on Checkpointing for Supercomputing (SuperCheck) , year =
-
[23]
Sihuan Li and Hongbo Li and Xin Liang and Jieyang Chen and Elisabeth Giem and Kaiming Ouyang and Kai Zhao and Sheng Di and Franck Cappello and Zizhong Chen , title =. 2019 , publisher =. doi:10.1145/3295500.3356195 , booktitle =
-
[24]
Reazul Hoque and Thomas Herault and George Bosilca and Jack Dongarra , title =. Proc. Int. Conf. on High Performance Computing, Networking, Storage and Analysis (SC) Workshops (ScalA) , publisher =. 2017 , doi =
2017
-
[25]
StarPU: A Unified Platform for Task Scheduling on Heterogeneous Multicore Architectures , journal =
C. StarPU: A Unified Platform for Task Scheduling on Heterogeneous Multicore Architectures , journal =. 2011 , publisher =
2011
-
[26]
2018 , doi =
Marco Bungart , title =. 2018 , doi =
2018
-
[27]
Brian Larkins , booktitle =
Hannah Cartier and James Dinan and D. Brian Larkins , booktitle =. Optimizing Work Stealing Communication with Structured Atomic Operations , year =
-
[28]
2019 , type =
Mia Reitz , title =. 2019 , type =
2019
-
[29]
2018 , type =
Mia Reitz , title =. 2018 , type =
2018
-
[30]
2010 , isbn =
Georg Hager and Gerhard Wellein , title =. 2010 , isbn =
2010
-
[31]
2018 , isbn =
Thomas Sterling and Matthew Anderson and Maciej Brodowicz , title =. 2018 , isbn =
2018
-
[32]
ServiceSs: An Interoperable Programming Framework for the Cloud , year =
Francesc Lordan and Enric Tejedor and Jorge Ejarque and Roger Rafanell and Javier \'. ServiceSs: An Interoperable Programming Framework for the Cloud , year =. doi:10.1007/s10723-013-9272-5 , journal =
-
[33]
Numrich and John Reid , title =
Robert W. Numrich and John Reid , title =. 2005 , publisher =. doi:10.1145/1080399.1080400 , journal =
-
[34]
Yelick and Luigi Semenzato and Geoff Pike and Carleton Miyamoto and Ben Liblit and Arvind Krishnamurthy and Paul N
Katherine A. Yelick and Luigi Semenzato and Geoff Pike and Carleton Miyamoto and Ben Liblit and Arvind Krishnamurthy and Paul N. Hilfinger and Susan L. Graham and David Gay and Phillip Colella and Alexander Aiken , title =. Concurrency: Practice and Experience , pages =. 1998 , volume =
1998
-
[35]
TOP500.org , title =
-
[36]
Competence Center for High Performance Computing in Hessen (HKHLR) , title =
-
[37]
Leibniz Supercomputing Centre (LRZ) , title =
-
[38]
Linux Cluster Kassel , urldate =
Competence Center for High Performance Computing in Hessen (HKHLR) , url =. Linux Cluster Kassel , urldate =
-
[39]
Morris and Qinglei Cao and George Bosilca and Seema Mirchandaney and Wonchan Lee and Sean Treichler and Patrick McCormick and Alex Aiken , title =
Elliott Slaughter and Wei Wu and Yuankun Fu and Legend Brandenburg and Nicolai Garcia and Wilhem Kautz and Emily Marx and Kaleb S. Morris and Qinglei Cao and George Bosilca and Seema Mirchandaney and Wonchan Lee and Sean Treichler and Patrick McCormick and Alex Aiken , title =. Proc. Int. Conf. for High Performance Computing, Networking, Storage and Analy...
2020
-
[40]
2020 , howpublished =
Claudia Fohry , title =. 2020 , howpublished =
2020
-
[41]
Encyclopedia of Parallel Computing , year =
George Almasi , title =. Encyclopedia of Parallel Computing , year =
-
[42]
Baden and Steven Hofmeyr and Mathias Jacquelin and Amir Kamil and Dan Bonachea and Paul H
John Bachan and Scott B. Baden and Steven Hofmeyr and Mathias Jacquelin and Amir Kamil and Dan Bonachea and Paul H. Hargrove and Hadia Ahmed , booktitle =. UPC++: A High-Performance Communication Framework for Asynchronous Computation , year =
-
[43]
HiPEAC: European Network on High-performance Embedded Architecture and Compilation , title =
-
[44]
The European Technology Platform For High-Performance Computing ETP4HPC Association , title =
-
[45]
Series , title =
SC Conf. Series , title =
-
[46]
Brad McCredie , title =
-
[47]
2018 , doi =
On the road to exascale: Advances in High Performance Computing and Simulations - An overview and editorial , journal =. 2018 , doi =
2018
-
[48]
Oak Ridge National Laboratory , title =
-
[49]
Resilient Application Co-scheduling with Processor Redistribution , year =
Anne Benoit and Lo. Resilient Application Co-scheduling with Processor Redistribution , year =. Proc. Int. Conf. on Parallel Processing (ICPP) , pages =
-
[50]
E.N. Elnozahy and Ricardo Bianchini and Tarek El-Ghazawi and Armando Fox and Forest Godf and Adolfy Hoisie and Kathryn McKinley and Rami Melhem and James Plank and Partha Ranganathan and Josh Simons , title =
-
[51]
Terracotta Open Source Community , urldate =
Terracotta , url =. Terracotta Open Source Community , urldate =
-
[52]
Infinispan, In-Memory Distributed Data Store , urldate =
Infinispan , url =. Infinispan, In-Memory Distributed Data Store , urldate =
-
[53]
Infinispan , howpublished =
-
[54]
Lakshman and Ramana Kompella , booktitle =
Advait Abhay Dixit and Fang Hao and Sarit Mukherjee and T.V. Lakshman and Ramana Kompella , booktitle =. ElastiCon: An Elastic Distributed Sdn Controller , year =
-
[55]
U U Multi-Tenanted Framework: Distributed Near Duplicate Detection for Big Data , year =
Pradeeban Kathiravelu and Helena Galhardas and Lu\'. U U Multi-Tenanted Framework: Distributed Near Duplicate Detection for Big Data , year =. On the Move to Meaningful Internet Systems , pages =
-
[56]
Concurrent and Distributed CloudSim Simulations , year =
Pradeeban Kathiravelu and Luis Veiga , booktitle =. Concurrent and Distributed CloudSim Simulations , year =
-
[57]
An Adaptive Distributed Simulator for Cloud and MapReduce Algorithms and Architectures , year =
Pradeeban Kathiravelu and Luis Veiga , booktitle =. An Adaptive Distributed Simulator for Cloud and MapReduce Algorithms and Architectures , year =
-
[58]
A Work-Stealing Scheduling Framework Supporting Fault Tolerance , year =
Yizhuo Wang and Weixing Ji and Feng Shi and Qi Zuo , booktitle =. A Work-Stealing Scheduling Framework Supporting Fault Tolerance , year =
-
[59]
A Programming Language Approach to Fault Tolerance for Fork-Join Parallelism , year =
Mustafa Zengin and Viktor Vafeiadis , booktitle =. A Programming Language Approach to Fault Tolerance for Fork-Join Parallelism , year =
-
[60]
Journal of Parallel and Distributed Computing (JPDC) , volume =
Rajesh Sudarsana and Calvin J.Ribbens , title =. Journal of Parallel and Distributed Computing (JPDC) , volume =. 2016 , doi =
2016
-
[61]
Equilibrium: An Elasticity Controller for Parallel Tree Search in the Cloud , year =
Stefan Kehrer and Wolfgang Blochinger , journal =. Equilibrium: An Elasticity Controller for Parallel Tree Search in the Cloud , year =
-
[62]
, booktitle =
Zheng, Gengbin and Xiang Ni and Kalé, Laxmikant V. , booktitle =. A Scalable Double In-Memory Checkpoint and Restart Scheme Towards Exascale , year =
-
[63]
and Szymanski, Boleslaw K
El Maghraoui, Kaoutar and Desell, Travis J. and Szymanski, Boleslaw K. and Varela, Carlos A. , booktitle =. Dynamic Malleability in Iterative MPI Applications , year =
-
[64]
Transactions on Architecture and Code Optimization (TACO) , publisher =
Peter Pirkelbauer and Amalee Wilson and Christina Peterson and Damian Dechev , title =. Transactions on Architecture and Code Optimization (TACO) , publisher =. 2019 , volume =
2019
-
[65]
SchedMD LLC , title =
-
[66]
Patrick Finnerty , title =
-
[67]
Philippe Charles and Christian Grothoff and Vijay Saraswat and Christopher Donawa and Allan Kielstra and Kemal Ebcioglu and Christoph von Praun and Vivek Sarkar , title =. 2005 , publisher =. doi:10.1145/1103845.1094852 , journal =
-
[68]
Barcelona Supercomputing Center , title =
-
[69]
GLB: Lifeline-based Global Load Balancing Library in X10 , year =
Wei Zhang and Olivier Tardieu and David Grove and Benjamin Herta and Tomio Kamada and Vijay Saraswat and Mikio Takeuchi , booktitle =. GLB: Lifeline-based Global Load Balancing Library in X10 , year =
-
[70]
Self-Adjusting Task Granularity for Global Load Balancer Library on Clusters of Many-Core Processors , year =
Patrick Finnerty and Tomio Kamada and Chikara Ohta , booktitle =. Self-Adjusting Task Granularity for Global Load Balancer Library on Clusters of Many-Core Processors , year =
-
[71]
Sergio Iserte and Rafael Mayo and Enrique S. Quintana-Ort\'. DMRlib Easy-coding and Efficient Resource Management for Job Malleability , year =. doi:10.1109/TC.2020.3022933 , journal =
-
[72]
Extending Slurm for Dynamic Resource-Aware Adaptive Batch Scheduling , year =
Mohak Chadha and Jophin John and Michael Gerndt , booktitle =. Extending Slurm for Dynamic Resource-Aware Adaptive Batch Scheduling , year =
-
[73]
Feitelson , title =
Uri Lublin and Dror G. Feitelson , title =. Journal of Parallel and Distributed Computing , volume =. 2003 , doi =
2003
-
[74]
Harrison and Gregory Beylkin and Florian A
Robert J. Harrison and Gregory Beylkin and Florian A. Bischoff and Justus A. Calvin and George I. Fann and Jacob Fosso-Tande and Diego Galindo and Jeff R. Hammond and Rebecca Hartman-Baker and Judith C. Hill and Jun Jia and Jakob S. Kottmann and M-J. Yvonne Ou and Junchen Pei and Laura E. Ratcliff and Matthew G. Reuter and Adam C. Richie-Halford and Nicho...
2016
-
[75]
Parallel Programming with Migratable Objects: Charm++ in Practice , year =
Bilge Acun and Abhishek Gupta and Nikhil Jain and Akhil Langer and Harshitha Menon and Eric Mikida and Xiang Ni and Michael Robson and Yanhua Sun and Ehsan Totoni and Lukasz Wesolowski and Laxmikant Kale , booktitle =. Parallel Programming with Migratable Objects: Charm++ in Practice , year =
-
[76]
Enhancing the performance of malleable MPI applications by using performance-aware dynamic reconfiguration , journal =
Gonzalo Mart\'. Enhancing the performance of malleable MPI applications by using performance-aware dynamic reconfiguration , journal =. 2015 , doi =
2015
-
[77]
Dynamic Reconfiguration of Noniterative Scientific Applications: A Case Study with HPG Aligner , journal =
Sergio Iserte and H\'. Dynamic Reconfiguration of Noniterative Scientific Applications: A Case Study with HPG Aligner , journal =. 2019 , doi =
2019
-
[78]
Kale , booktitle =
Suraj Prabhakaran and Marcel Neumann and Sebastian Rinke and Felix Wolf and Abhishek Gupta and Laxmikant V. Kale , booktitle =. A Batch System with Efficient Adaptive Scheduling for Malleable and Evolving Applications , year =
-
[79]
Algorithms and Computation , year =
Marc Tchiboukdjian and Nicolas Gast and Denis Trystram and Jean-Louis Roch and Julien Bernard , title =. Algorithms and Computation , year =
-
[80]
The Implementation of the Cilk-5 Multithreaded Language , author =. Proc. Conf. on Programming Language Design and Implementation (PLDI) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.