From Objectives to Applications: Aligning Architectural Biases in Audio Self-Supervised Learning
Pith reviewed 2026-07-02 05:51 UTC · model grok-4.3
The pith
Audio SSL pretraining objectives align with the inductive biases of different architectures to determine success on downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
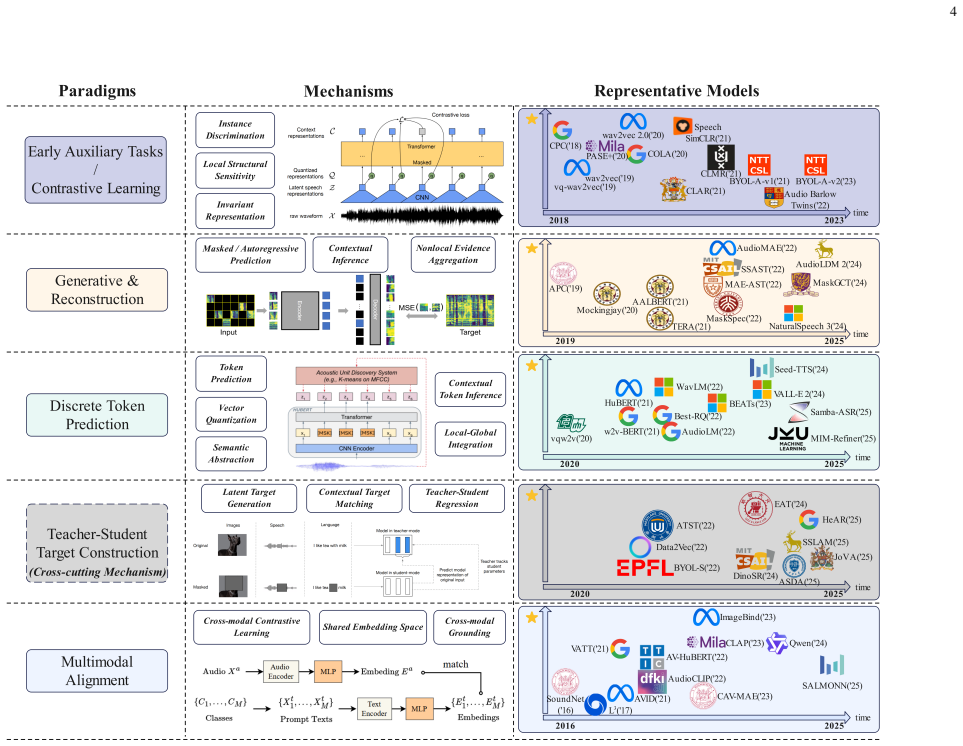
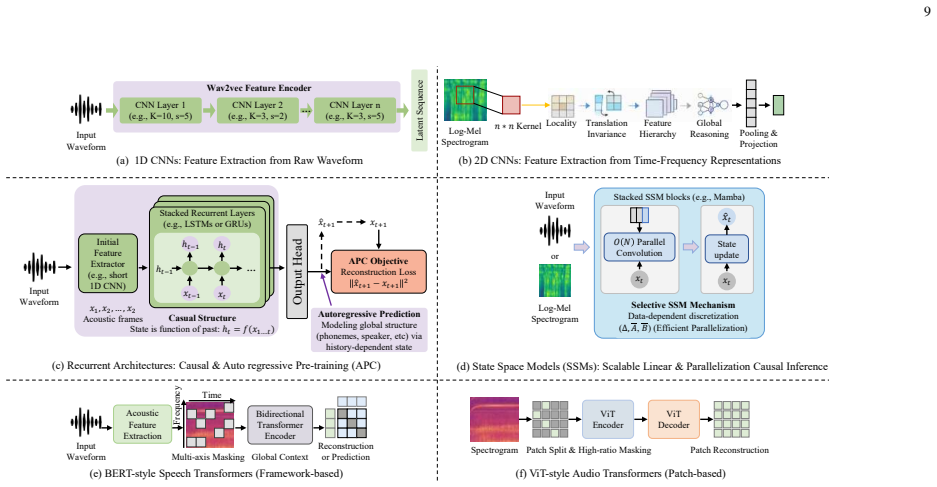
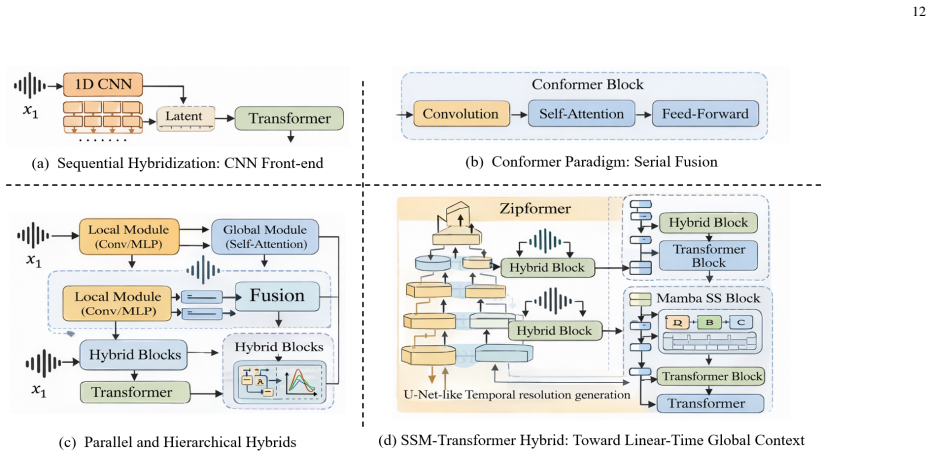
The paper establishes that the five SSL paradigms impose demands on models including local structural sensitivity, contrastive invariance, contextual inference, discrete semantic abstraction, and multimodal grounding, which correspond to the inductive biases of CNNs, recurrent and state space models, Transformers, and hybrid architectures, thereby explaining performance differences across downstream applications in speech processing, environmental sound analysis, music information retrieval, medical and bioacoustic analysis, and multimodal audio understanding.
What carries the argument
The alignment between the five SSL paradigms (auxiliary tasks, contrastive learning, generative reconstruction, discrete token prediction, multimodal alignment) and architectural inductive biases of CNNs, recurrent/SSMs, Transformers, and hybrids.
If this is right
- CNNs support local acoustic compression needed for auxiliary tasks.
- Recurrent and state space models enable sequential state propagation for contextual tasks.
- Transformers provide content-dependent global routing for inference and abstraction.
- Hybrid architectures integrate local and global processing for multimodal alignment.
- Downstream applications serve as tests of whether these alignments hold across domains.
Where Pith is reading between the lines
- Designers could use this mapping to select or create architectures for new audio domains without extensive trial and error.
- Extending the framework to emerging objectives like those in audio-language models could reveal new alignment patterns.
- Addressing open challenges such as tokenization bottlenecks may require architectures tuned to discrete prediction paradigms.
- Long-context efficiency issues might be resolved by state space models if their alignment with generative objectives is confirmed.
Load-bearing premise
The five paradigms comprehensively capture all audio SSL objectives and their demands can be mapped to architectural biases using only existing literature without new experiments.
What would settle it
A controlled experiment training multiple architectures on one objective from each paradigm and testing on a downstream task where the alignment predicts poor performance but the model succeeds anyway.
Figures


read the original abstract
This paper examines audio self-supervised learning (SSL) through the alignment between pretraining objectives, architectural inductive biases, and downstream applications. Rather than treating SSL methods as a chronological sequence of pretext tasks or model families, we ask how different supervisory signals shape the representations that models are expected to learn. The discussion is organized around five paradigms: auxiliary tasks, contrastive learning, generative reconstruction, discrete token prediction, and multimodal alignment. These objectives place different demands on the model, from local structural sensitivity and contrastive invariance to contextual inference, discrete semantic abstraction, and multimodal grounding. We relate these demands to the biases of CNNs, recurrent and State Space Models, Transformers, and hybrid architectures, showing how local acoustic compression, sequential state propagation, content-dependent global routing, and local--global integration support different forms of audio SSL. The same view is then used to interpret downstream applications in speech processing, environmental sound analysis, music information retrieval, medical and bioacoustic analysis, and multimodal audio understanding as practical tests of whether learned representations and architectural choices generalize across domains. We also review benchmark protocols and open challenges, including tokenization bottlenecks, long-context efficiency, robustness, and secure multimodal deployment, and discuss how codec-based tokenization and audio-language modeling extend this objective--architecture--application pipeline. The accompanying repository is released at https://github.com/colaudiolab/Awesome-Self-Supervised-Audio-Learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an organizational framework for audio self-supervised learning (SSL) by aligning five pretraining paradigms—auxiliary tasks, contrastive learning, generative reconstruction, discrete token prediction, and multimodal alignment—with the inductive biases of architectures such as CNNs, recurrent and state space models, Transformers, and hybrids. It uses this alignment to interpret how these objectives shape representations for downstream applications in speech, environmental sound, music, medical, and multimodal domains, while reviewing benchmarks and open challenges.
Significance. If the proposed mappings between objectives, architectures, and applications hold, the paper offers a valuable interpretive lens for the audio SSL community. It synthesizes existing literature into a coherent structure that could guide architecture selection and highlight generalization issues. The accompanying repository enhances reproducibility and accessibility of the reviewed resources.
minor comments (2)
- The abstract refers to 'the accompanying repository' but does not specify its contents or how it supports the framework; this could be clarified to better inform readers.
- Some terminology, such as 'content-dependent global routing', would benefit from a brief definition or example upon first use to aid readers unfamiliar with the specific architectural biases discussed.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and positive assessment of the manuscript. The recommendation for minor revision is noted, and we will address any editorial or minor points in the revised version. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
This is a survey paper that proposes an organizational framework for existing audio SSL literature around five paradigms (auxiliary tasks, contrastive, generative, discrete token, multimodal) and relates their demands to architectural biases of CNNs, SSMs, Transformers, and hybrids. No new derivations, equations, quantitative predictions, or proofs are introduced. The mapping is presented as an interpretive lens rather than a deductive chain, with all content supported by external references and no load-bearing steps that reduce to self-citations or fitted inputs by construction. The work is self-contained as a review without circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[2]
Deep learning for audio signal processing,
H. Purwins, B. Li, T. Virtanen, J. Schl ¨uter, S.-Y . Chang, and T. Sainath, “Deep learning for audio signal processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 206–219, 2019. 21
2019
-
[3]
Audio signal processing in the 21st century: The important outcomes of the past 25 years,
G. Richard, P. Smaragdis, S. Gannot, P. A. Naylor, S. Makino, W. Kellermann, and A. Sugiyama, “Audio signal processing in the 21st century: The important outcomes of the past 25 years,”IEEE Signal Processing Magazine, vol. 40, no. 5, pp. 12–26, 2023
2023
-
[4]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[5]
P. Cai, Y . Song, K. Li, H. Song, and I. McLoughlin, “Mat-sed: A masked audio transformer with masked-reconstruction based pre- training for sound event detection,”arXiv preprint arXiv:2408.08673, 2024
-
[6]
Taming data and transformers for audio generation,
M. Haji-Ali, W. Menapace, A. Siarohin, G. Balakrishnan, and V . Or- donez, “Taming data and transformers for audio generation,”Interna- tional Journal of Computer Vision, vol. 134, no. 3, p. 87, 2026
2026
-
[7]
Deep convolutional neural networks and data augmentation for environmental sound classification,
J. Salamon and J. P. Bello, “Deep convolutional neural networks and data augmentation for environmental sound classification,”IEEE Signal processing letters, vol. 24, no. 3, pp. 279–283, 2017
2017
-
[8]
Synthio: Augmenting small-scale audio classification datasets with synthetic data,
S. Ghosh, S. Kumar, Z. Kong, R. Valle, B. Catanzaro, and D. Manocha, “Synthio: Augmenting small-scale audio classification datasets with synthetic data,”arXiv preprint arXiv:2410.02056, 2024
-
[9]
Explaining and Harnessing Adversarial Examples
I. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, and et al., “Intriguing properties of neural networks,”arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Understanding deep learning requires rethinking generalization
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understand- ing deep learning requires rethinking generalization,”arXiv preprint arXiv:1611.03530, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,”arXiv preprint arXiv:1904.05862, 2019
-
[13]
Specaugment: A simple data augmentation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “Specaugment: A simple data augmentation method for automatic speech recognition,”arXiv preprint arXiv:1904.08779, 2019
-
[14]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,”Ad- vances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
2020
-
[15]
Musical genre classification of audio signals,
G. Tzanetakis and P. Cook, “Musical genre classification of audio signals,”IEEE Transactions on speech and audio processing, vol. 10, no. 5, pp. 293–302, 2002
2002
-
[16]
Dynamic attention-asymmetric perceptron network for overlapping sound event detection,
Y . Miao, J. Zhu, and Y . Li, “Dynamic attention-asymmetric perceptron network for overlapping sound event detection,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 636–649, 2026
2026
-
[17]
SPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
X. Yang, Y . Yang, Z. Jin, Z. Cui, W. Wu, B. Li, C. Zhang, and P. Woodland, “Spear: A unified ssl framework for learning speech and audio representations,”arXiv preprint arXiv:2510.25955, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Scaling up masked audio encoder learning for general audio classification,
H. Dinkel, Z. Yan, Y . Wang, J. Zhang, Y . Wang, and B. Wang, “Scaling up masked audio encoder learning for general audio classification,” arXiv preprint arXiv:2406.06992, 2024
-
[19]
A survey on contrastive self-supervised learning,
A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,”Technologies, vol. 9, no. 1, p. 2, 2020
2020
-
[20]
Audio self-supervised learning: A survey,
S. Liu, A. Mallol-Ragolta, E. Parada-Cabaleiro, K. Qian, X. Jing, A. Kathan, B. Hu, and B. W. Schuller, “Audio self-supervised learning: A survey,”Patterns, vol. 3, no. 12, 2022
2022
-
[21]
Scaling bioacoustic signal pre-training with million samples via mask- modeling,
X. Deng, T. Wan, K. Xu, T. Gao, P. Qiao, D. Feng, and Y . Dou, “Scaling bioacoustic signal pre-training with million samples via mask- modeling,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[22]
Hearsay benchmark: Do audio llms leak what they hear?
J. Wang, L. Lin, K. Luo, W. Wang, Y . Chen, M. Aloqaily, X. Tang, Z. Zhou, K. Wang, L. Sunet al., “Hearsay benchmark: Do audio llms leak what they hear?”arXiv preprint arXiv:2601.03783, 2026
-
[23]
A survey on self-supervised learning: Algorithms, applications, and future trends,
J. Gui, T. Chen, J. Zhang, Q. Cao, Z. Sun, H. Luo, and D. Tao, “A survey on self-supervised learning: Algorithms, applications, and future trends,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 9052–9071, 2024
2024
-
[24]
Self-supervised speech representation learning: A review,
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløeet al., “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, 2022
2022
-
[25]
Ssast: Self- supervised audio spectrogram transformer,
Y . Gong, C.-I. J. Lai, Y .-A. Chung, and J. Glass, “Ssast: Self- supervised audio spectrogram transformer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 10 699– 10 709
2022
-
[26]
Unsupervised feature learning via non-parametric instance discrimination,
Z. Wu, Y . Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3733–3742
2018
-
[27]
Unsupervised representation learning by predicting image rotations,
S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image rotations,” inInternational Conference on Learning Representations, 2018
2018
-
[28]
Unsupervised learning of visual representa- tions by solving jigsaw puzzles,
M. Noroozi and P. Favaro, “Unsupervised learning of visual representa- tions by solving jigsaw puzzles,” inEuropean conference on computer vision. Springer, 2016, pp. 69–84
2016
-
[29]
A simple frame- work for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple frame- work for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
-
[30]
Contrastive learning of general-purpose audio representations,
A. Saeed, D. Grangier, and N. Zeghidour, “Contrastive learning of general-purpose audio representations,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3875–3879
2021
-
[31]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[32]
Masked autoencoders that listen,
P.-Y . Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer, “Masked autoencoders that listen,”Advances in neural information processing systems, vol. 35, pp. 28 708–28 720, 2022
2022
-
[33]
Masked spectrogram prediction for self-supervised audio pre-training,
D. Chong, H. Wang, P. Zhou, and Q. Zeng, “Masked spectrogram prediction for self-supervised audio pre-training,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[34]
Recent advances in discrete speech tokens: A review,
Y . Guo, Z. Li, H. Wang, B. Li, C. Shao, H. Zhang, C. Du, X. Chen, S. Liu, and K. Yu, “Recent advances in discrete speech tokens: A review,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
2025
-
[35]
Beats: Audio pre-training with acoustic tokenizers,
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, and F. Wei, “Beats: Audio pre-training with acoustic tokenizers,”arXiv preprint arXiv:2212.09058, 2022
-
[36]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-C. Tsai, K. Lakhotia, R. Salakhutdinov, M. Ma, and J. Glass, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[37]
Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,
H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y . Cui, and B. Gong, “Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,”Advances in neural information processing systems, vol. 34, pp. 24 206–24 221, 2021
2021
-
[38]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[39]
Clap learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “Clap learning audio concepts from natural language supervision,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[40]
Pre-training audio representations with self-supervision,
M. Tagliasacchi, B. Gfeller, F. de Chaumont Quitry, and D. Roblek, “Pre-training audio representations with self-supervision,”IEEE Signal Processing Letters, vol. 27, pp. 600–604, 2020
2020
-
[41]
Shuffle and learn: unsupervised learning using temporal order verification,
I. Misra, C. L. Zitnick, and M. Hebert, “Shuffle and learn: unsupervised learning using temporal order verification,” inEuropean conference on computer vision. Springer, 2016, pp. 527–544
2016
-
[42]
Self-supervised learning of audio representations from permutations with differentiable ranking,
A. N. Carr, Q. Berthet, M. Blondel, O. Teboul, and N. Zeghidour, “Self-supervised learning of audio representations from permutations with differentiable ranking,”IEEE Signal Processing Letters, vol. 28, pp. 708–712, 2021
2021
-
[43]
Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
S. Pascual, M. Ravanelli, J. Serra, A. Bonafonte, and Y . Bengio, “Learning problem-agnostic speech representations from multiple self- supervised tasks,”arXiv preprint arXiv:1904.03416, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[44]
Multi-task self-supervised learning for robust speech recognition,
M. Ravanelli, J. Zhong, S. Pascual, P. Swietojanski, J. Monteiro, J. Trmal, and Y . Bengio, “Multi-task self-supervised learning for robust speech recognition,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6989–6993
2020
-
[45]
Clar: Contrastive learning of auditory representations,
H. Al-Tahan and Y . Mohsenzadeh, “Clar: Contrastive learning of auditory representations,” inInternational conference on artificial intelligence and statistics. PMLR, 2021, pp. 2530–2538
2021
-
[46]
Byol for audio: Exploring pre-trained general-purpose audio repre- 22 sentations,
D. Niizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Byol for audio: Exploring pre-trained general-purpose audio repre- 22 sentations,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 137–151, 2022
2022
-
[47]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Byol for audio: Self-supervised learning for general-purpose audio representation,
D. Niizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Byol for audio: Self-supervised learning for general-purpose audio representation,” in2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8
2021
-
[49]
An Unsupervised Autoregressive Model for Speech Representation Learning
Y .-A. Chung, W.-N. Hsu, H. Tang, and J. Glass, “An unsupervised au- toregressive model for speech representation learning,”arXiv preprint arXiv:1904.03240, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[50]
Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders,
A. T. Liu, S.-w. Yang, P.-H. Chi, P.-c. Hsu, and H.-y. Lee, “Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders,” inICASSP 2020-2020 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6419–6423
2020
-
[51]
Audio albert: A lite bert for self-supervised learning of audio representation,
P.-H. Chi, P.-H. Chung, T.-H. Wu, C.-C. Hsieh, Y .-H. Chen, S.-W. Li, and H.-y. Lee, “Audio albert: A lite bert for self-supervised learning of audio representation,” in2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 344–350
2021
-
[52]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2871–2883, 2024
2024
-
[53]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text-to-speech with masked generative codec transformer,”arXiv preprint arXiv:2409.00750, 2024
-
[54]
w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,
Y .-A. Chung, Y . Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang, and Y . Wu, “w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” inIEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 244–250
2021
-
[55]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[56]
Discrete audio tokens: More than a survey!
P. Mousavi, G. Maimon, A. Moumen, D. Petermann, J. Shi, H. Wu, H. Yang, A. Kuznetsova, A. Ploujnikov, R. Marxeret al., “Discrete audio tokens: More than a survey!”arXiv preprint arXiv:2506.10274, 2025
-
[57]
Data2vec: A general framework for self-supervised learning in speech, vision and language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “Data2vec: A general framework for self-supervised learning in speech, vision and language,” inInternational conference on machine learning. PMLR, 2022, pp. 1298–1312
2022
-
[58]
Eat: Self- supervised pre-training with efficient audio transformer,
W. Chen, Y . Liang, Z. Ma, Z. Zheng, and X. Chen, “Eat: Self- supervised pre-training with efficient audio transformer,”arXiv preprint arXiv:2401.03497, 2024
-
[59]
Look, listen and learn,
R. Arandjelovic and A. Zisserman, “Look, listen and learn,” inProceed- ings of the IEEE international conference on computer vision, 2017, pp. 609–617
2017
-
[60]
Soundnet: Learning sound representations from unlabeled video,
Y . Aytar, C. V ondrick, and A. Torralba, “Soundnet: Learning sound representations from unlabeled video,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[61]
Robust audio-visual in- stance discrimination,
P. Morgado, I. Misra, and N. Vasconcelos, “Robust audio-visual in- stance discrimination,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 934–12 945
2021
-
[62]
Audioclip: Extending clip to image, text and audio,
A. Guzhov, F. Raue, J. Hees, and A. Dengel, “Audioclip: Extending clip to image, text and audio,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 976–980
2022
-
[63]
Self-supervised audio teacher-student transformer for both clip-level and frame-level tasks,
X. Li, N. Shao, and X. Li, “Self-supervised audio teacher-student transformer for both clip-level and frame-level tasks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1336–1351, 2024
2024
-
[64]
Audio mamba: Selective state spaces for self- supervised audio representations,
S. Yadav and Z.-H. Tan, “Audio mamba: Selective state spaces for self- supervised audio representations,”arXiv preprint arXiv:2406.02178, 2024
-
[65]
Ssamba: Self-supervised audio representation learning with mamba state space model,
S. Shams, S. S. Dindar, X. Jiang, and N. Mesgarani, “Ssamba: Self-supervised audio representation learning with mamba state space model,”arXiv preprint arXiv:2405.11831, 2024
-
[66]
Mamba in speech: Towards an alternative to self-attention,
X. Zhang, Q. Zhang, H. Liu, T. Xiao, X. Qian, B. Ahmed, E. Am- bikairajah, H. Li, and J. Epps, “Mamba in speech: Towards an alternative to self-attention,”IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[67]
xlstm: Extended long short-term memory,
M. Beck, K. P ¨oppel, M. Spanring, A. Auer, O. Prudnikova, M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter, “xlstm: Extended long short-term memory,”Advances in Neural Information Processing Systems, vol. 37, pp. 107 547–107 603, 2024
2024
-
[68]
Axlstms: learning self-supervised audio representations with xlstms,
S. Yadav, S. Theodoridis, and Z.-H. Tan, “Axlstms: learning self-supervised audio representations with xlstms,”arXiv preprint arXiv:2408.16568, 2024
-
[69]
Tera: Self-supervised learning of transformer encoder representation for speech,
A. T. Liu, S.-W. Li, and H.-y. Lee, “Tera: Self-supervised learning of transformer encoder representation for speech,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 29, pp. 2351– 2366, 2021
2021
-
[70]
Ast: Audio spectrogram trans- former,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram trans- former,”arXiv preprint arXiv:2104.01778, 2021
-
[71]
AaSP: Aliasing-aware Self-Supervised Pre-Training for Audio Spectrogram Transformers
K. Yamamoto and K. Okusa, “Aape: Aliasing-aware patch embed- ding for self-supervised audio representation learning,”arXiv preprint arXiv:2512.03637, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Bigssl: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition,
Y . Zhang, D. S. Park, W. Han, J. Qin, A. Gulati, J. Shor, A. Jansen, Y . Xu, Y . Huang, S. Wanget al., “Bigssl: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1519–1532, 2022
2022
-
[73]
Hypercon- former: Multi-head hypermixer for efficient speech recognition,
F. Mai, J. Zuluaga-Gomez, T. Parcollet, and P. Motlicek, “Hypercon- former: Multi-head hypermixer for efficient speech recognition,”arXiv preprint arXiv:2305.18281, 2023
-
[74]
Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding,
Y . Peng, S. Dalmia, I. Lane, and S. Watanabe, “Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 17 627–17 643
2022
-
[75]
E-branchformer: Branchformer with enhanced merging for speech recognition,
K. Kim, F. Wu, Y . Peng, J. Pan, P. Sridhar, K. J. Han, and S. Watanabe, “E-branchformer: Branchformer with enhanced merging for speech recognition,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 84–91
2023
-
[76]
Zipformer: A faster and better encoder for automatic speech recognition,
Z. Yao, L. Guo, X. Yang, W. Kang, F. Kuang, Y . Yang, Z. Jin, L. Lin, and D. Povey, “Zipformer: A faster and better encoder for automatic speech recognition,”arXiv preprint arXiv:2310.11230, 2023
-
[77]
Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650
2022
-
[78]
Joint semantic knowl- edge distillation and masked acoustic modeling for full-band speech restoration with improved intelligibility,
X. Liu, X. Li, J. Serr `a, and S. Pascual, “Joint semantic knowl- edge distillation and masked acoustic modeling for full-band speech restoration with improved intelligibility,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[79]
Distilhubert: Speech represen- tation learning by layer-wise distillation of hidden-unit bert,
H.-J. Chang, S.-w. Yang, and H.-y. Lee, “Distilhubert: Speech represen- tation learning by layer-wise distillation of hidden-unit bert,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7087–7091
2022
-
[80]
Skill: Similarity-aware knowledge distillation for speech self-supervised learning,
L. Zampierin, G. B. Hacene, B. Nguyen, and M. Ravanelli, “Skill: Similarity-aware knowledge distillation for speech self-supervised learning,” in2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). IEEE, 2024, pp. 675– 679
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.