As It Was: Aligning LLM Search Evaluation with Historical User Preferences
Pith reviewed 2026-07-02 06:33 UTC · model grok-4.3
The pith
Augmenting LLM search judges with historical user interaction summaries improves alignment with actual preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
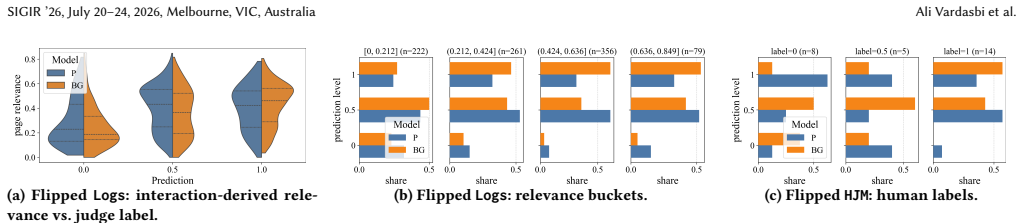
The behavior-grounded LLM judge augments each SERP item with a Query-Relevance-Impressions card that condenses historical user interactions with similar queries and results; when the judge cites this card it produces relevance scores whose Spearman correlation with user-derived preferences rises by about 5 percent overall, by 91 percent relative on disagreement cases, by 15 percent on a multilingual human-labeled set, and shows stronger agreement with the winning model in a live A/B test.
What carries the argument
The Query-Relevance-Impressions (QRI) card, a lightweight summary of historical user interactions with similar queries and results that supplies an auditable behavioral prior the LLM judge can cite during relevance assessment.
If this is right
- Evaluation of long-tail and ambiguous queries can rely less on purely semantic reasoning.
- Multilingual search systems gain a consistent way to incorporate local user behavior.
- Live experiment outcomes become more predictable from offline LLM judgments.
- Relevance labels can be produced at scale while remaining traceable to past user actions.
Where Pith is reading between the lines
- The same card format could be reused to ground LLM judges in other ranking domains such as recommendations or ads.
- If QRI cards remain stable over time they might reduce the frequency of fresh human labeling campaigns.
- Extending the cards to include explicit negative signals could further sharpen disagreement resolution.
Load-bearing premise
Historical user interactions summarized in QRI cards supply an unbiased and temporally stable prior that correctly resolves relevance ambiguity for the current queries without introducing selection or drift biases.
What would settle it
A fresh A/B test in which the model preferred by the grounded judge loses to the alternative according to observed user metrics would show the claimed alignment gain does not hold.
Figures

read the original abstract
Large-scale search systems evolve faster than human quality assurance can scale, especially for long-tail intents and multilingual queries. LLM-as-a-judge approaches provide a scalable alternative for evaluating the relevance of search engine result pages (SERPs), but judgments based solely on semantic similarity or world knowledge can drift from actual user preferences, particularly for ambiguous queries. We introduce a behavior-grounded LLM judge that augments each SERP item with a lightweight and auditable behavioral prior in the form of a Query-Relevance-Impressions (QRI) card. Each card summarizes how users have historically interacted with similar queries and results, providing compact empirical evidence that the judge can cite to resolve ambiguity and make more consistent relevance judgments while still relying on semantic reasoning. In a large-scale music search evaluation at Spotify, using relevance estimates derived from historical user interactions across 6,000 recomposed SERPs, the behavior-grounded judge achieves stronger alignment with user preferences, improving Spearman rank correlation by approximately 5% overall and yielding a 91% relative improvement on disagreement cases. On a multilingual human-judged dataset spanning five languages, grounding further increases correlation with human relevance judgments by 15%. Importantly, when evaluated against outcomes from a live A/B test, the grounded judge shows consistently higher alignment with the observed winning model. While absolute alignment remains moderate, these findings demonstrate that lightweight behavioral grounding can improve the reliability and practical usefulness of LLM-based evaluation in real-world search systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that augmenting LLM judges for SERP relevance with lightweight Query-Relevance-Impressions (QRI) cards, which summarize historical user interactions with similar queries and results, leads to better alignment with actual user preferences. This is demonstrated through improved Spearman rank correlations of approximately 5% overall and 91% relative improvement on disagreement cases on 6,000 recomposed SERPs from a music search evaluation, a 15% increase on a multilingual human-judged dataset across five languages, and higher alignment with outcomes from a live A/B test.
Significance. If the improvements are not due to data leakage, this work provides a scalable method to ground LLM-based search evaluation in empirical user behavior, addressing limitations of purely semantic judgments for ambiguous and long-tail queries. The large scale of the evaluation (6,000 SERPs) and the use of live A/B tests as a benchmark are notable strengths that enhance the practical relevance of the findings for real-world search systems.
major comments (1)
- [Abstract and evaluation methodology] Abstract and evaluation methodology: The relevance estimates used as ground truth and the QRI cards are both derived from historical user interactions on the same 6,000 recomposed SERPs. The manuscript does not specify any temporal, query-level, or other partitioning to ensure the QRI cards provide independent information. This raises the possibility that the reported correlation gains (5% overall, 91% on disagreements) result from the judge citing signals that define the labels rather than from improved reasoning, directly undermining the central claim that the behavioral prior resolves ambiguity independently.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying a critical methodological detail that requires clarification. The concern about potential data leakage is substantive and directly relevant to the validity of our central claims. We address it below and commit to revisions that strengthen the paper without altering its core findings.
read point-by-point responses
-
Referee: [Abstract and evaluation methodology] Abstract and evaluation methodology: The relevance estimates used as ground truth and the QRI cards are both derived from historical user interactions on the same 6,000 recomposed SERPs. The manuscript does not specify any temporal, query-level, or other partitioning to ensure the QRI cards provide independent information. This raises the possibility that the reported correlation gains (5% overall, 91% on disagreements) result from the judge citing signals that define the labels rather than from improved reasoning, directly undermining the central claim that the behavioral prior resolves ambiguity independently.
Authors: The referee is correct that the current manuscript text does not explicitly describe temporal, query-level, or other partitioning between QRI card construction and ground-truth label derivation. This omission leaves open the possibility of leakage and must be addressed. In the full experimental pipeline, QRI cards are built from a much larger historical interaction corpus using query similarity (embedding-based and reformulation-based) with explicit exclusion of direct interactions from the 6,000 evaluation SERPs; ground-truth relevance estimates are computed only from user behavior on the recomposed pages themselves. However, because this separation is not documented in the submitted version, we will add a dedicated subsection (and accompanying diagram) in the Methods section that details: (1) the temporal window used for QRI data (pre-dating SERP recomposition), (2) the query-similarity threshold and exclusion rules, and (3) verification that no evaluation-SERP impressions appear in any QRI card. We will also report an ablation that removes any borderline-similar queries to quantify sensitivity to leakage. These changes will be made in the revision. revision: yes
Circularity Check
No significant circularity; evaluations rely on external benchmarks
full rationale
The paper's central claims rest on empirical correlations between LLM judgments (with and without QRI cards) and three reported benchmarks: relevance estimates from historical interactions on 6,000 SERPs, a separate multilingual human-judged dataset, and live A/B test outcomes. These are presented as independent external signals rather than quantities defined by the paper's own fitted parameters or self-referential definitions. No equations, self-citations, or derivation steps are shown that reduce the reported Spearman improvements (+5% overall, +91% on disagreements, +15% multilingual) to the inputs by construction. The evaluation chain therefore remains self-contained against the cited external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical user interactions summarized in QRI cards provide a reliable and unbiased prior for resolving relevance ambiguity in current queries
invented entities (1)
-
Query-Relevance-Impressions (QRI) card
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Gomez-Cabello, Syed Ali Haider, Bernardo Collaco, Nadia G
Ariana Genovese, Lars Hegstrom, Srinivasagam Prabha, Cesar A. Gomez-Cabello, Syed Ali Haider, Bernardo Collaco, Nadia G. Wood, and Antonio Jorge Forte
-
[3]
Artificial Authority: The Promise and Perils of LLM Judges in Healthcare. Bioengineering13, 1 (2026). doi:10.3390/bioengineering13010108
- [4]
-
[5]
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, and Min Zhang. 2025. A Survey on Human Preference Learning for Aligning Large Language Models.ACM Comput. Surv.58, 6, Article 152 (Dec. 2025), 39 pages. doi:10.1145/3773279
-
[6]
Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased Learning-to-Rank with Biased Feedback. InProceedings of the Tenth ACM Interna- tional Conference on Web Search and Data Mining(Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 781–789. doi:10.1145/3018661.3018699
-
[7]
Krishnaram Kenthapadi, Mehrnoosh Sameki, and Ankur Taly. 2024. Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned (Survey). InProceedings of the 30th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 6523–6533. doi:10....
-
[8]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2025. From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christ...
-
[9]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv:2412.05579 [cs.CL] https://arxiv.org/abs/2412.05579
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Lihong Li, Shunbao Chen, Jim Kleban, and Ankur Gupta. 2015. Counterfactual Estimation and Optimization of Click Metrics in Search Engines: A Case Study. InProceedings of the 24th International Conference on World Wide Web(Florence, Italy)(WWW ’15 Companion). Association for Computing Machinery, New York, NY, USA, 929–934. doi:10.1145/2740908.2742562
-
[11]
Bo Ni, Zheyuan Liu, Leyao Wang, Yongjia Lei, Yuying Zhao, Xueqi Cheng, Qingkai Zeng, Luna Dong, Yinglong Xia, Krishnaram Kenthapadi, Ryan Rossi, Franck Dernoncourt, Md Mehrab Tanjim, Nesreen Ahmed, Xiaorui Liu, Wenqi Fan, Erik Blasch, Yu Wang, Meng Jiang, and Tyler Derr. 2025. Towards Trustwor- thy Retrieval Augmented Generation for Large Language Models:...
- [12]
-
[13]
Yuta Saito. 2020. Unbiased Pairwise Learning from Biased Implicit Feedback. InProceedings of the 2020 ACM SIGIR on International Conference on Theory of Information Retrieval(Virtual Event, Norway)(ICTIR ’20). Association for Computing Machinery, New York, NY, USA, 5–12. doi:10.1145/3409256.3409812
-
[14]
Ravneet Singh, Parminder Singh, Arun Malik, and Dede Sukmawan. 2025. Under- standing and Mitigating Hallucinations in Large Language Models: Insights from a Systematic Literature Review. In2025 International Conference on Metaverse and Current Trends in Computing (ICMCTC). 1–10. doi:10.1109/ICMCTC62214. 2025.11196493
- [15]
-
[16]
Ali Vardasbi, Maarten de Rijke, and Ilya Markov. 2020. Cascade Model-Based Propensity Estimation for Counterfactual Learning to Rank. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2089–2092. doi:10...
-
[17]
Ali Vardasbi, Harrie Oosterhuis, and Maarten de Rijke. 2020. When Inverse Propensity Scoring Does Not Work: Affine Corrections for Unbiased Learning to Rank. InProceedings of the 29th ACM International Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association for Computing Machinery, New York, NY, USA, 1475–1484. doi:...
-
[18]
Ali Vardasbi, Gustavo Penha, Claudia Hauff, and Hugues Bouchard. 2026. Adap- tive Repetition for Mitigating Position Bias in LLM-Based Ranking. InAdvances in Bias, Fairness, and Understudied Users in Information Retrieval. Springer Nature Switzerland, Cham, 3–15. doi:10.1007/978-3-032-12717-4_1
-
[19]
Xiangmeng Wang, Qian Li, Dianer Yu, Peng Cui, Zhichao Wang, and Guandong Xu. 2023. Causal Disentanglement for Semantic-Aware Intent Learning in Recom- mendation.IEEE Transactions on Knowledge and Data Engineering35, 10 (2023), 9836–9849. doi:10.1109/TKDE.2022.3159802
-
[20]
Yujia Zhou, Yan Liu, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Zheng Liu, Chaozhuo Li, Zhicheng Dou, Tsung-Yi Ho, and Philip S. Yu. 2024. Trustworthiness in SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Ali Vardasbi et al. Retrieval-Augmented Generation Systems: A Survey. arXiv:2409.10102 [cs.IR] https://arxiv.org/abs/2409.10102
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Ziwei Zhu, Yun He, Yin Zhang, and James Caverlee. 2020. Unbiased Implicit Recommendation and Propensity Estimation via Combinational Joint Learning. InProceedings of the 14th ACM Conference on Recommender Systems(Virtual Event, Brazil)(RecSys ’20). Association for Computing Machinery, New York, NY, USA, 551–556. doi:10.1145/3383313.3412210
-
[22]
Shengyao Zhuang, Hang Li, and Guido Zuccon. 2022. Implicit Feedback for Dense Passage Retrieval: A Counterfactual Approach. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 18–28. doi:10.1145/3477495.3531994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.