Pattern-Calibrated Multimodal Prediction under Blockwise Missingness
Pith reviewed 2026-07-03 08:16 UTC · model grok-4.3
The pith
MOSAIC borrows information across missingness patterns in multimodal data by fitting on overlaps then calibrating the gap with target-pattern samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By separating overlap-based representation learning and first-stage prediction from a subsequent calibration step estimated solely on target-pattern observations, the procedure yields predictors whose error is controlled by the product of overlap sample size and calibration gap plus representation error, rather than by the full pooled sample or by imputation artifacts.
What carries the argument
The MOSAIC procedure: overlap-aware shared-specific alignment followed by inter-pattern calibration that estimates the additive gap from target data alone.
If this is right
- When the calibration gap is small relative to overlap sample size, borrowing improves finite-sample risk over fitting only on the target pattern.
- Representation-learning error appears as an additive term that cannot be reduced by more target data alone.
- Rule mismatch between patterns acts as a hard limit on the benefit of borrowing, independent of sample sizes.
- The same decomposition quantifies the cost of using a single pooled model versus pattern-specific calibration.
Where Pith is reading between the lines
- The framework suggests collecting a modest calibration set for each clinically important pattern rather than maximizing total sample size across all patterns.
- It may generalize to other structured missingness where the observed set defines a distinct conditional distribution.
- In deployment, one could monitor the estimated calibration gap on incoming target data to decide whether to switch from the borrowed predictor to a purely local one.
Load-bearing premise
Target-pattern observations are numerous enough to estimate the calibration gap reliably and the first-stage predictor on overlaps introduces no bias that calibration cannot remove.
What would settle it
An experiment in which the measured calibration gap fails to shrink with additional target samples or in which the total error exceeds the local-only error even when the estimated gap is near zero.
Figures
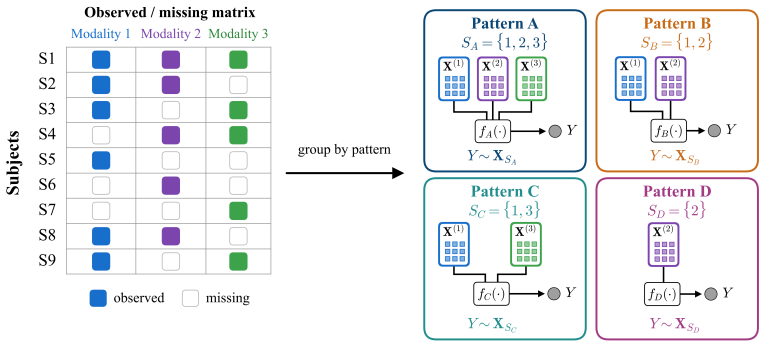
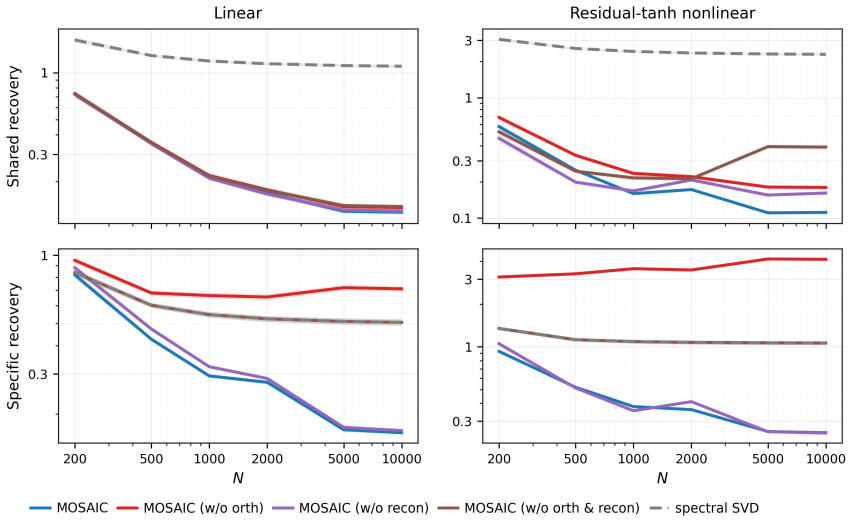
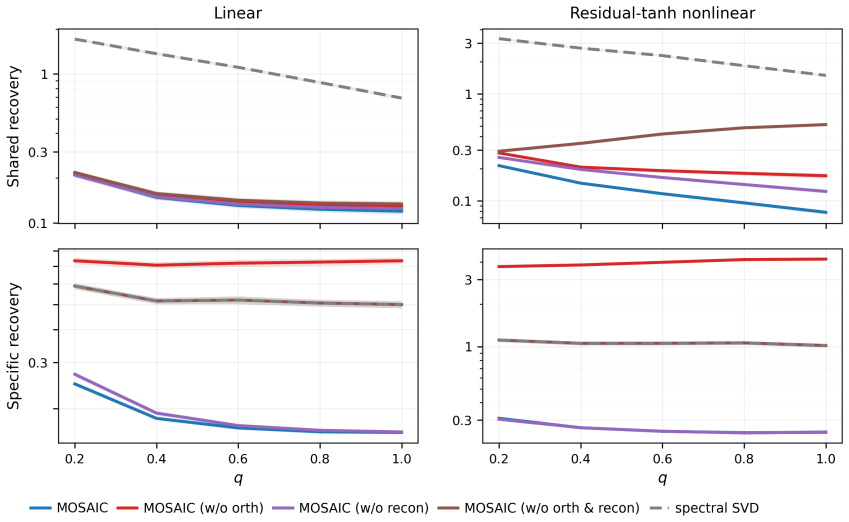
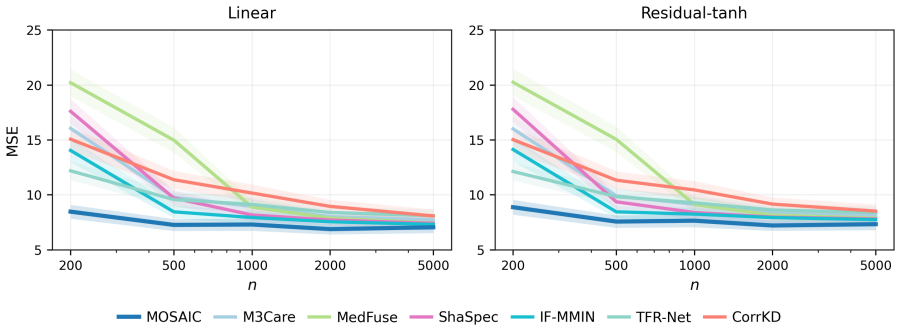
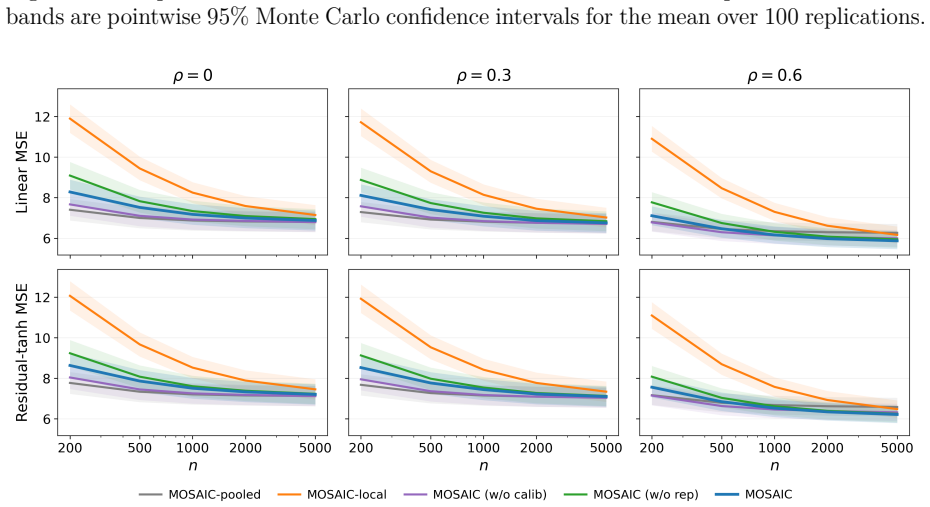
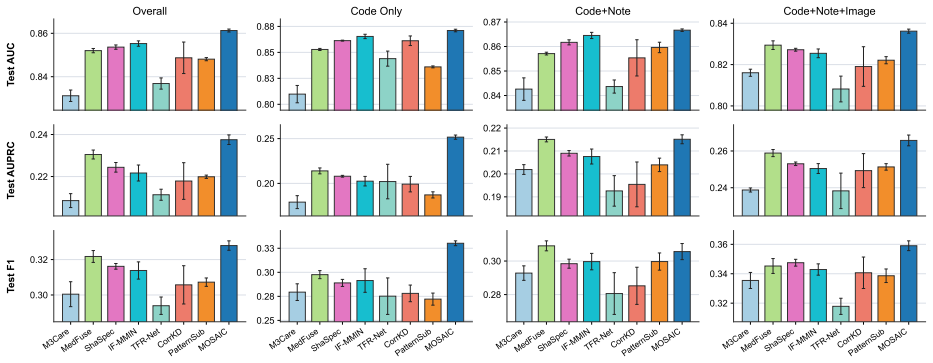
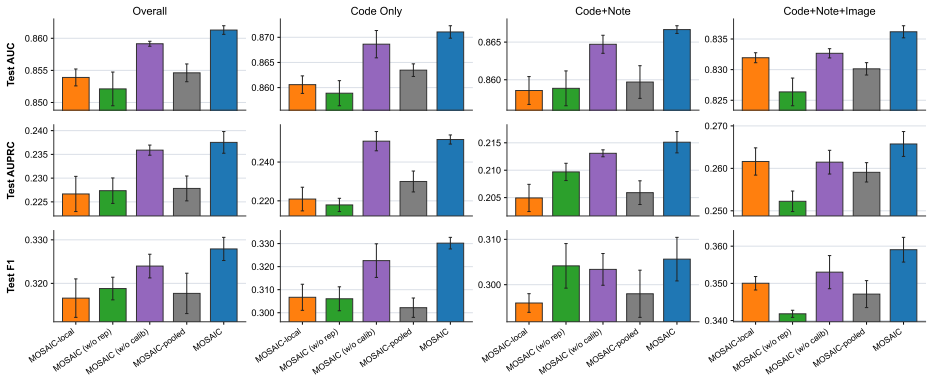
read the original abstract
Blockwise missingness in multimodal data is usually treated as an incomplete-input problem. We instead focus on prediction for a prespecified observed-modality pattern, where the observed modality set determines the information on which the prediction rule can condition. A procedure that imputes missing modalities, zero-fills unobserved modalities, or trains a single pooled predictor may borrow information across patterns, but it can also mix pattern-specific prediction rules. We propose Multimodal Overlap-aware Shared-specific Alignment and Inter-pattern Calibration (MOSAIC), a pattern-calibrated framework for borrowing across missingness patterns without collapsing their prediction rules. MOSAIC learns shared and modality-specific representations, uses the available representations that overlap with the target pattern to fit a first-stage predictor, and then estimates the calibration gap from target-pattern data. We establish non-asymptotic bounds that decompose the error into overlap effective sample size, calibration gap, and representation-learning error, clarifying when cross-pattern borrowing improves over local fitting and when the improvement is controlled by rule mismatch or representation-learning error. Simulations examine representation recovery and target-pattern correction, and applications to ICU mortality prediction, emotion recognition, and glaucoma classification show gains when target-pattern samples are limited or pattern-specific rules differ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MOSAIC (Multimodal Overlap-aware Shared-specific Alignment and Inter-pattern Calibration), a pattern-calibrated framework for multimodal prediction under blockwise missingness that targets a prespecified observed-modality pattern. It learns shared and modality-specific representations, fits a first-stage predictor on representations overlapping the target pattern, and estimates a calibration gap from target-pattern data. Non-asymptotic bounds are derived that decompose prediction error into overlap effective sample size, calibration gap, and representation-learning error, with the goal of clarifying when cross-pattern borrowing improves over local fitting. Simulations study representation recovery and target correction; applications to ICU mortality, emotion recognition, and glaucoma classification report gains when target samples are limited or pattern-specific rules differ.
Significance. If the claimed error decomposition is valid and the procedure avoids irreducible bias from the first-stage predictor, the work supplies a theoretically grounded approach to borrowing across missingness patterns without collapsing distinct prediction rules. This could be valuable in domains with structured multimodal missingness, such as clinical prediction, where target-pattern data are scarce.
major comments (1)
- [Abstract] Abstract: the non-asymptotic bounds are asserted as decomposing error into overlap effective sample size, calibration gap, and representation-learning error, but no derivation steps, explicit assumptions on the representation-learning procedure, or conditions ensuring the calibration gap is estimable without irreducible bias are visible; this is load-bearing for the central claim that the bounds clarify when borrowing helps versus when it is controlled by rule mismatch or representation error.
minor comments (1)
- [Abstract] The abstract introduces the MOSAIC acronym and procedure but does not define the precise form of the first-stage predictor or how the calibration gap is estimated from target data; adding one sentence on these operational details would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying this point about the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the non-asymptotic bounds are asserted as decomposing error into overlap effective sample size, calibration gap, and representation-learning error, but no derivation steps, explicit assumptions on the representation-learning procedure, or conditions ensuring the calibration gap is estimable without irreducible bias are visible; this is load-bearing for the central claim that the bounds clarify when borrowing helps versus when it is controlled by rule mismatch or representation error.
Authors: The abstract is a concise high-level summary and does not contain full derivations or assumption statements, which is standard due to length constraints. The non-asymptotic bounds and their decomposition into overlap effective sample size, calibration gap, and representation-learning error are derived in Section 4, with complete proof steps in Appendix A. Explicit assumptions on the representation-learning procedure (including bounded representation error and consistency of overlap-aware alignment) appear as Assumptions 1-3 in Section 3.1. Conditions ensuring the calibration gap is estimable without irreducible bias from the first-stage predictor are stated in Theorem 2, which requires positive target-pattern sample size and controlled representation error so that the gap term vanishes with the representation error. These results support the central claim by separating the error sources, enabling analysis of when cross-pattern borrowing reduces error relative to local fitting. We do not view changes to the abstract as necessary. revision: no
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines the MOSAIC procedure (shared/specific representations, first-stage predictor on overlaps, target-pattern calibration gap estimation) and derives non-asymptotic error bounds that decompose into overlap effective sample size, calibration gap, and representation-learning error. These quantities are constructed directly from the observed data and procedure components; the bounds clarify when borrowing improves over local fitting without any step reducing the claimed improvement to a fitted parameter already present in the target pattern or to a self-citation chain. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A General Representation-Based Approach to Multi-Source Domain Adaptation
A General Representation-Based Approach to Multi-Source Domain Adaptation , author=. arXiv preprint arXiv:2604.23790 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 29th ACM International Conference on Multimedia , pages =
Transformer-Based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis , author =. Proceedings of the 29th ACM International Conference on Multimedia , pages =. 2021 , doi =
2021
-
[3]
Molecular Systems Biology , volume =
Multi-Omics Factor Analysis---a framework for unsupervised integration of multi-omics data sets , author =. Molecular Systems Biology , volume =. 2018 , doi =
2018
-
[4]
Biometrika , volume =
Inference and Missing Data , author =. Biometrika , volume =. 1976 , doi =
1976
-
[5]
2019 , doi =
Statistical Analysis with Missing Data , author =. 2019 , doi =
2019
-
[6]
Multimodal fusion on low-quality data: A comprehensive survey , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.inffus.2026.104437 , author =
-
[7]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Missing Modalities Imputation via Cascaded Residual Autoencoder , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[8]
IEEE Transactions on Medical Imaging , volume =
Multimodal MR Synthesis via Modality-Invariant Latent Representation , author =. IEEE Transactions on Medical Imaging , volume =. 2018 , doi =
2018
-
[9]
Advances in Neural Information Processing Systems , volume =
Multimodal Generative Models for Scalable Weakly-Supervised Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
Advances in Neural Information Processing Systems , volume =
Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep Generative Models , author =. Advances in Neural Information Processing Systems , volume =
-
[11]
and Hoadley, Katherine A
Lock, Eric F. and Hoadley, Katherine A. and Marron, J. S. and Nobel, Andrew B. , journal =. Joint and Individual Variation Explained (. 2013 , doi =
2013
-
[12]
Journal of Multivariate Analysis , volume =
Angle-Based Joint and Individual Variation Explained , author =. Journal of Multivariate Analysis , volume =. 2018 , doi =
2018
-
[13]
Biometrics , volume =
Structural Learning and Integrative Decomposition of Multi-View Data , author =. Biometrics , volume =. 2019 , doi =
2019
-
[14]
Biometrika , volume =
A Spectral Framework for Multi-View Subspace Learning Using the Product of Projections , author =. Biometrika , volume =. 2026 , doi =
2026
-
[15]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Transfer Learning for High-Dimensional Linear Regression , author =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2022 , doi =
2022
-
[16]
Journal of the American Statistical Association , volume =
Transfer Learning Under High-Dimensional Generalized Linear Models , author =. Journal of the American Statistical Association , volume =. 2023 , doi =
2023
-
[17]
Information Fusion , volume =
Review of multimodal machine learning approaches in healthcare , author =. Information Fusion , volume =. 2025 , doi =
2025
-
[18]
Transactions on Machine Learning Research , issn=
Deep Multimodal Learning with Missing Modality: A Survey , author=. Transactions on Machine Learning Research , issn=. 2026 , note=
2026
-
[19]
, journal=
Zhang, Yue and Peng, Chengtao and Wang, Qiuli and Song, Dan and Li, Kaiyan and Kevin Zhou, S. , journal=. Unified Multi-Modal Image Synthesis for Missing Modality Imputation , year=
-
[20]
Missing Modality Imagination Network for Emotion Recognition with Uncertain Missing Modalities , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =. 2021 , address =
2021
-
[21]
ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =
Exploiting Modality-Invariant Feature for Robust Multimodal Emotion Recognition with Missing Modalities , author =. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2023 , doi =
2023
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Multi-Modal Learning With Missing Modality via Shared-Specific Feature Modelling , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
MMANet: Margin-Aware Distillation and Modality-Aware Regularization for Incomplete Multimodal Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[24]
Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis , DOI =
Yuan, Ziqi and Li, Wei and Xu, Hua and Yu, Wenmeng , year =. Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis , DOI =. Proceedings of the 29th ACM International Conference on Multimedia , publisher =
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2024 , doi =
2024
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Multimodal Machine Learning: A Survey and Taxonomy , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2019 , doi =
2019
-
[27]
Proceedings of the 28th ACM International Conference on Multimedia , pages =
MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis , author =. Proceedings of the 28th ACM International Conference on Multimedia , pages =. 2020 , doi =
2020
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages =
Private-Shared Disentangled Multimodal VAE for Learning of Latent Representations , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages =. 2021 , doi =
2021
-
[29]
IEEE Transactions on Knowledge and Data Engineering , volume =
A Survey on Transfer Learning , author =. IEEE Transactions on Knowledge and Data Engineering , volume =. 2010 , doi =
2010
-
[30]
Advances in Neural Information Processing Systems 21 , pages =
Domain Adaptation with Multiple Sources , author =. Advances in Neural Information Processing Systems 21 , pages =
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-source domain adaptation: A causal view , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Journal of Machine Learning Research , volume =
Invariant Models for Causal Transfer Learning , author =. Journal of Machine Learning Research , volume =
-
[33]
Attention Bottlenecks for Multimodal Fusion , url =
Nagrani, Arsha and Yang, Shan and Arnab, Anurag and Jansen, Aren and Schmid, Cordelia and Sun, Chen , booktitle =. Attention Bottlenecks for Multimodal Fusion , url =
-
[34]
Machine Learning for Healthcare Conference , pages=
Learning missing modal electronic health records with unified multi-modal data embedding and modality-aware attention , author=. Machine Learning for Healthcare Conference , pages=. 2023 , organization=
2023
-
[35]
The Twelfth International Conference on Learning Representations , year=
Multimodal patient representation learning with missing modalities and labels , author=. The Twelfth International Conference on Learning Representations , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-modal learning with missing modality via shared-specific feature modelling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
M3care: Learning with missing modalities in multimodal healthcare data , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[38]
Proceedings of the AAAI conference on artificial intelligence , volume=
Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[39]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
2024 , month = mar, note =
Johnson, Alistair and Lungren, Matthew and Peng, Yifan and Lu, Zhiyong and Mark, Roger and Berkowitz, Seth and Horng, Steven , title =. 2024 , month = mar, note =
2024
-
[41]
Nature communications , volume=
The medical segmentation decathlon , author=. Nature communications , volume=. 2022 , publisher=
2022
-
[42]
2023 , publisher=
Johnson, Alistair EW and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom J and Hao, Sicheng and Moody, Benjamin and Gow, Brian and others , journal=. 2023 , publisher=
2023
-
[43]
Scientific data , volume=
The eICU Collaborative Research Database, a freely available multi-center database for critical care research , author=. Scientific data , volume=. 2018 , publisher=
2018
-
[44]
Computer Vision--ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2--6, 2018, Revised Selected Papers, Part V 14 , pages=
VIPL-HR: A multi-modal database for pulse estimation from less-constrained face video , author=. Computer Vision--ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2--6, 2018, Revised Selected Papers, Part V 14 , pages=. 2019 , organization=
2018
-
[45]
npj Digital Medicine , volume=
Multimodal machine learning in precision health: A scoping review , author=. npj Digital Medicine , volume=. 2022 , publisher=
2022
-
[46]
AMIA Annual Symposium Proceedings , volume=
A multimodal transformer: Fusing clinical notes with structured ehr data for interpretable in-hospital mortality prediction , author=. AMIA Annual Symposium Proceedings , volume=
-
[47]
International conference on machine learning , pages=
The effect of natural distribution shift on question answering models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[48]
International conference on machine learning , pages=
Do imagenet classifiers generalize to imagenet? , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[49]
Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection , url =
Park, Chunjong and Awadalla, Anas and Kohno, Tadayoshi and Patel, Shwetak , booktitle =. Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection , url =
-
[50]
Split learning for health: Distributed deep learning without sharing raw patient data
Split learning for health: Distributed deep learning without sharing raw patient data , author=. arXiv preprint arXiv:1812.00564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Scientific reports , volume=
Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data , author=. Scientific reports , volume=. 2020 , publisher=
2020
-
[52]
Le and Thu Nguyen and Michael A
Lien P. Le and Thu Nguyen and Michael A. Riegler and Pål Halvorsen and Binh T. Nguyen , keywords =. Multimodal missing data in healthcare: A comprehensive review and future directions , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.cosrev.2024.100720 , url =
-
[53]
, author=
Multimodal deep learning. , author=. ICML , volume=
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Smil: Multimodal learning with severely missing modality , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Are multimodal transformers robust to missing modality? , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
and Ma, Jieming and Cui, Zhiming , TITLE =
Xu, Jiabao and Xi, Xuefeng and Chen, Jie and Sheng, Victor S. and Ma, Jieming and Cui, Zhiming , TITLE =. Applied Sciences , VOLUME =. 2022 , NUMBER =
2022
-
[57]
Machine Learning for Healthcare Conference , pages=
MedFuse: Multi-modal fusion with clinical time-series data and chest X-ray images , author=. Machine Learning for Healthcare Conference , pages=. 2022 , organization=
2022
-
[58]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Hgmf: heterogeneous graph-based fusion for multimodal data with incompleteness , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[59]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Multimodal learning with incomplete modalities by knowledge distillation , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[60]
Machine Learning for Health (ML4H) , pages=
Multimodal pretraining of medical time series and notes , author=. Machine Learning for Health (ML4H) , pages=. 2023 , organization=
2023
-
[61]
Computers in Biology and Medicine , volume=
Multimodal image encoding pre-training for diabetic retinopathy grading , author=. Computers in Biology and Medicine , volume=. 2022 , publisher=
2022
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Best of both worlds: Multimodal contrastive learning with tabular and imaging data , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
IEEE journal of biomedical and health informatics , volume=
Hi-BEHRT: hierarchical transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records , author=. IEEE journal of biomedical and health informatics , volume=. 2022 , publisher=
2022
-
[64]
Proceedings of the Conference on Empirical Methods in Natural Language Processing
Hierarchical pretraining on multimodal electronic health records , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing , volume=
-
[65]
IEEE Journal of Biomedical and Health Informatics , volume=
Multimodal data matters: Language model pre-training over structured and unstructured electronic health records , author=. IEEE Journal of Biomedical and Health Informatics , volume=. 2022 , publisher=
2022
-
[66]
IEEE journal of biomedical and health informatics , volume=
Bidirectional representation learning from transformers using multimodal electronic health record data to predict depression , author=. IEEE journal of biomedical and health informatics , volume=. 2021 , publisher=
2021
-
[67]
International conference on machine learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[68]
and Lee, Sungbok and Narayanan, Shrikanth S
Busso, Carlos and Bulut, Murtaza and Lee, Chi-Chun and Kazemzadeh, Abe and Mower, Emily and Kim, Samuel and Chang, Jeannette N. and Lee, Sungbok and Narayanan, Shrikanth S. , year =. IEMOCAP: interactive emotional dyadic motion capture database , volume =. Language Resources and Evaluation , publisher =. doi:10.1007/s10579-008-9076-6 , number =
-
[69]
Tian, Yu and Wen, Congcong and Shi, Min and Afzal, Muhammad Muneeb and Huang, Hao and Khan, Muhammad Osama and Luo, Yan and Fang, Yi and Wang, Mengyu , editor =. FairDomain: Achieving Fairness in Cross-Domain Medical Image Segmentation and Classification , booktitle =. 2025 , publisher =. doi:10.1007/978-3-031-73116-7_15 , isbn =
-
[70]
IEEE Journal of Selected Topics in Signal Processing , volume=
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[71]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages=
2019
-
[72]
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , volume =
Wang, Wenhui and Wei, Furu and Dong, Li and Bao, Hangbo and Yang, Nan and Zhou, Ming , booktitle =. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , volume =
-
[73]
Fletcher Mercaldo, Sarah and Blume, Jeffrey D , title =. Biostatistics , volume =. 2020 , month =. doi:10.1093/biostatistics/kxy040 , eprint =
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sharing Pattern Submodels for Prediction with Missing Values , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2023 , doi=
2023
-
[75]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[76]
Deep Multimodal Representation Learning: A Survey , year=
Guo, Wenzhong and Wang, Jianwen and Wang, Shiping , journal=. Deep Multimodal Representation Learning: A Survey , year=
-
[77]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Deepseek-vl: towards real-world vision-language understanding , author=. arXiv preprint arXiv:2403.05525 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[79]
ACM Computing Surveys , volume=
Multimodal sentiment analysis: a survey of methods, trends, and challenges , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[80]
Information Fusion , volume=
Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions , author=. Information Fusion , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.