Efficient Regex Matching with Sparse Counting-Sets
Pith reviewed 2026-06-26 02:08 UTC · model grok-4.3
The pith
A sparse counting-set tracks only essential counters to cut replication costs during c-regex matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a counting-set can be represented sparsely by retaining only essential counter values, so that branching transitions require copying far fewer entries yet the resulting automaton still recognizes exactly the same language as the full counting-set version for every input string and every c-regex.
What carries the argument
The sparse counting-set, a data structure that stores only the minimal subset of counter values required to preserve matching semantics across nondeterministic transitions.
If this is right
- The matching procedure runs faster on automata with high out-degree because each transition copies a smaller set.
- Memory usage per active state drops proportionally to the number of non-essential counters that can be discarded.
- The same language is recognized, so existing c-regex compilers or validators can adopt the method without changing their output specifications.
- The approach remains correct even when counters appear inside nested or alternative subexpressions.
Where Pith is reading between the lines
- The technique could be combined with existing lazy or on-the-fly determinization strategies to further limit state explosion.
- If essential values can be computed statically from the regex syntax, the method might be implemented as a preprocessing pass rather than a runtime analysis.
- Similar sparsity ideas might apply to other counter-based automata models used in XML schema validation or network protocol analysis.
Load-bearing premise
It is always possible to identify in advance which counter values are essential for any given state and input, without missing any value that would later affect acceptance.
What would settle it
An input string and c-regex for which the sparse algorithm reports a different match result or different set of active counters than the original non-sparse counting-set algorithm on the same automaton.
Figures
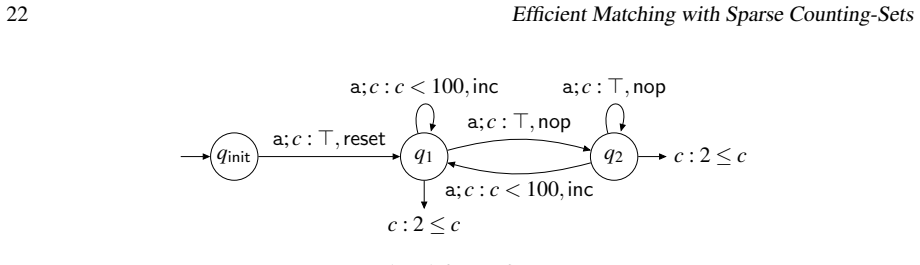
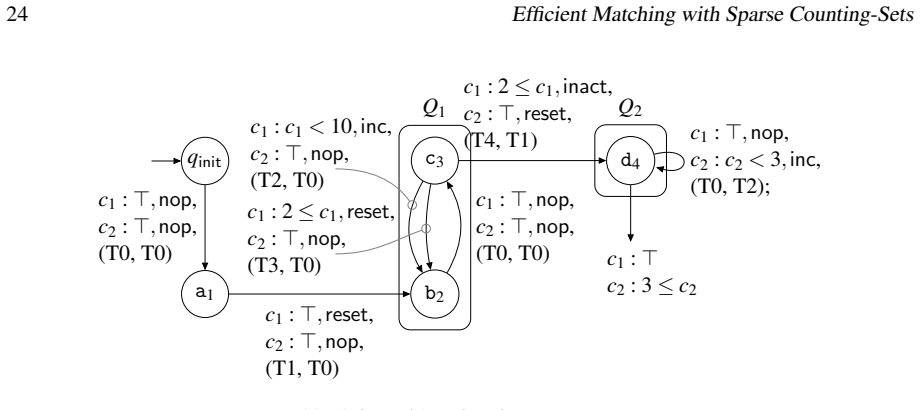
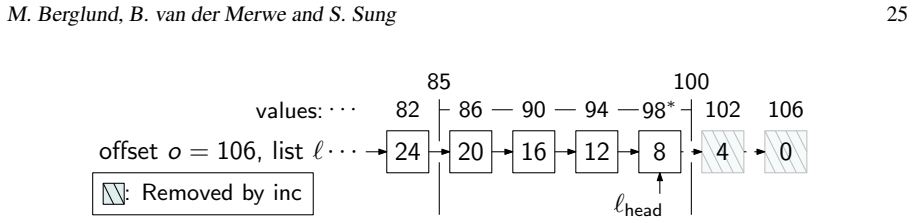

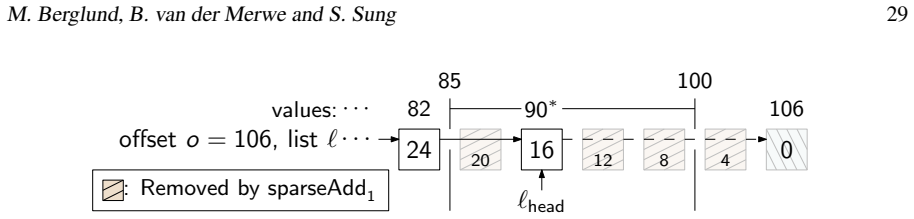
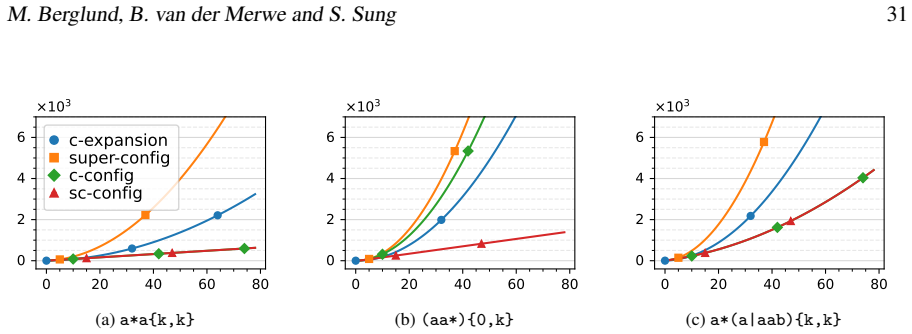
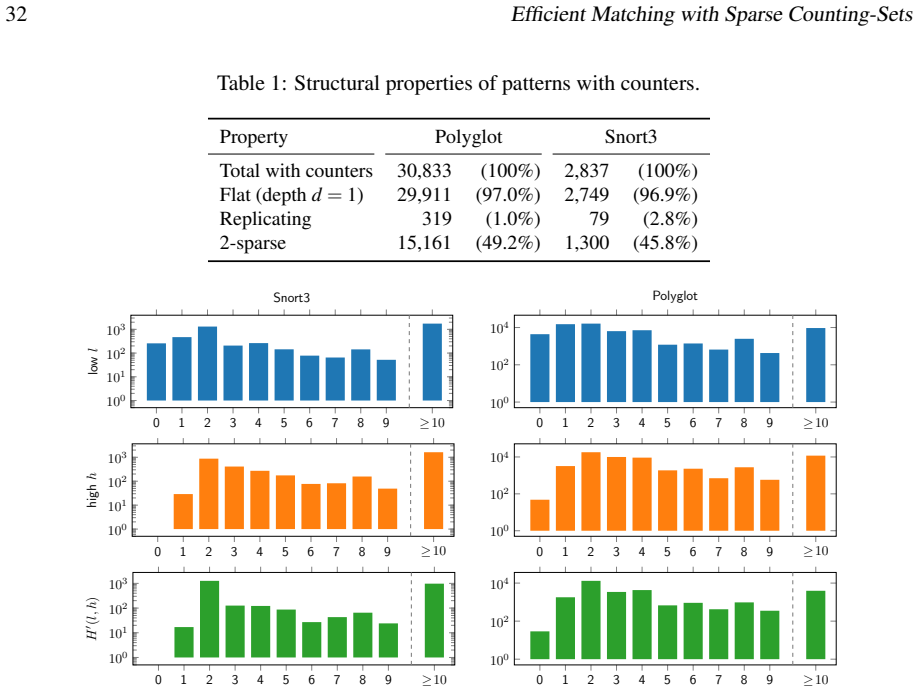
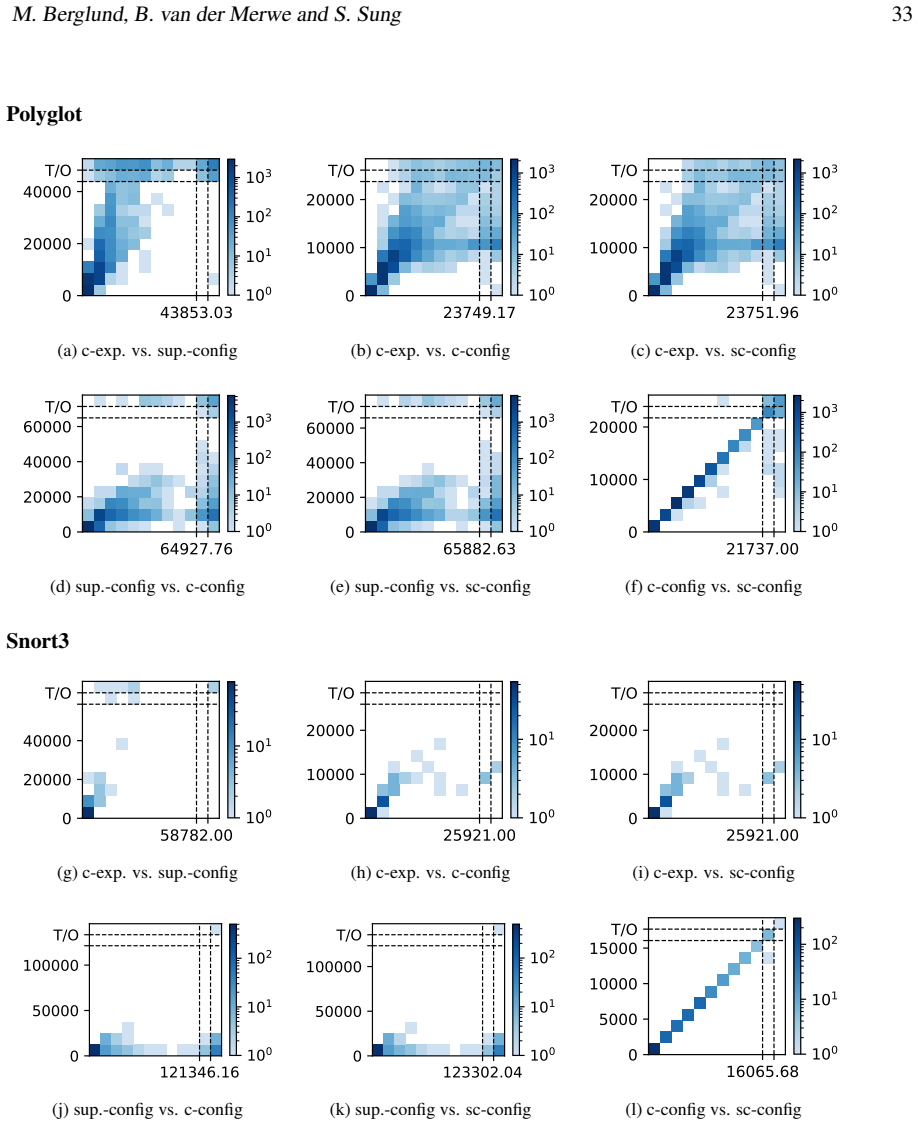
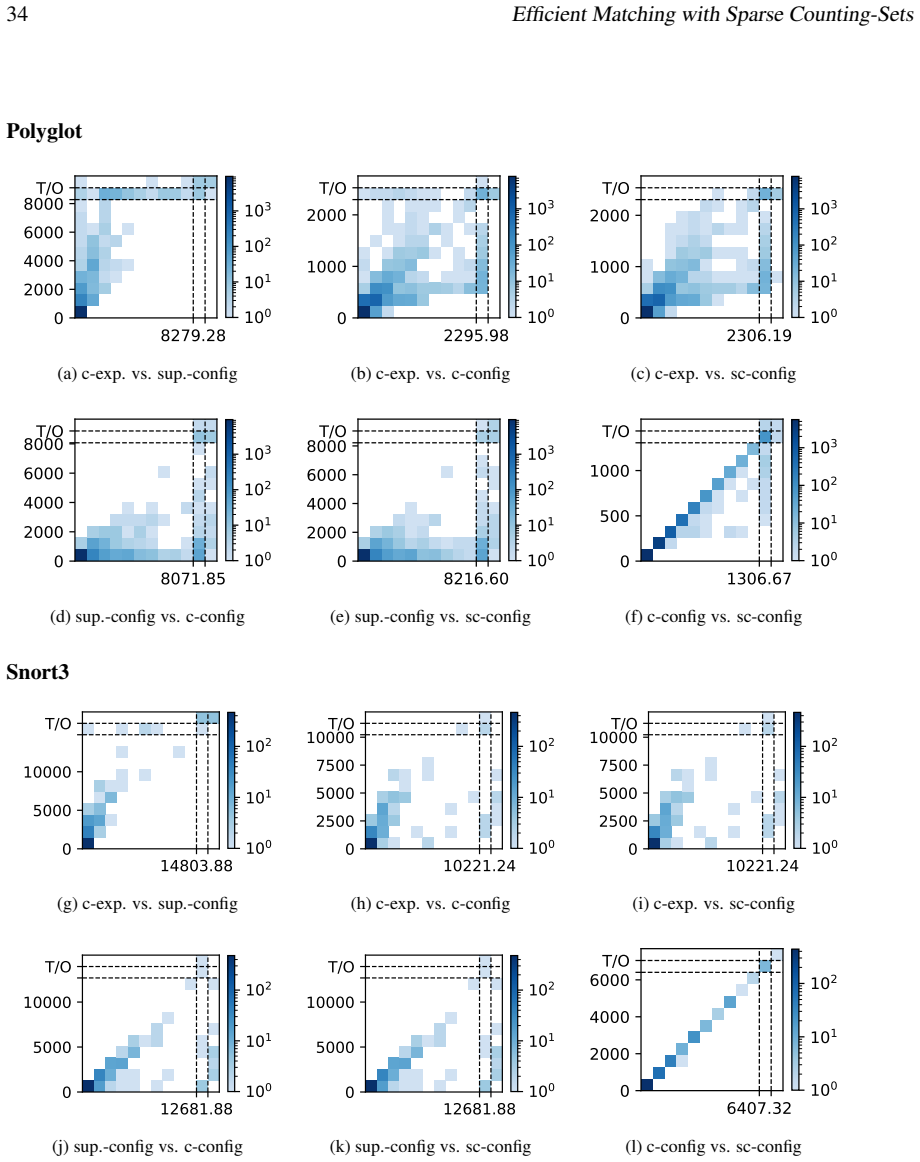
read the original abstract
Regular expressions with counting operations (c-regexes) offer a compact representation of repeating patterns by allowing numerical bounds to be added to subexpressions. Recent work introduced the counting-set data structure, which allows simultaneous updates of multiple counter values for efficient matching. However, this approach suffers from a performance bottleneck when counting-sets must be replicated due to the presence of branching transitions. We propose a sparse counting-set approach, which reduces the replication overhead by maintaining only essential counter values, thereby yielding a more efficient matching algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sparse counting-set data structure for efficient matching of counting regular expressions (c-regexes). It builds on prior counting-set automata that incur replication costs on branching transitions and claims that maintaining only essential counter values reduces this overhead while preserving exact acceptance semantics for every input string.
Significance. If the sparsity rule is both sound and complete, the result would offer a practical improvement to automata-based matching for bounded repetitions, a common feature in real-world regexes. The work directly targets a documented performance bottleneck and could influence implementations in string-processing libraries and formal-verification tools.
major comments (3)
- [§3] §3 (Sparsity Rule): The criterion for identifying 'essential' counters is defined locally in terms of currently active counters and immediate transitions. No argument is given that this rule remains complete when a counter incremented on one branch later constrains acceptance on an alternative path, which is exactly the non-local dependency case highlighted by the central claim.
- [§4] §4 (Correctness Argument): The manuscript asserts that the sparse representation yields an equivalent automaton, yet provides neither an inductive invariant relating sparse and full counting-sets nor an exhaustive case analysis for c-regexes whose counting constraints interact across epsilon-transitions. This equivalence is load-bearing for the efficiency claim.
- [§5] §5 (Experimental Evaluation): Reported speed-ups are measured only on synthetic patterns; no data are given on whether any of the tested c-regexes exercise the non-local counter interactions that would falsify the sparsity rule. Without such cases the experiments cannot confirm that exact semantics are preserved in practice.
minor comments (2)
- Notation for the sparse counting-set is introduced without a compact formal definition; a small example showing the difference between full and sparse sets on a single transition would clarify the data structure.
- The abstract states the approach 'preserves exact matching semantics' but the introduction does not cite the prior counting-set paper whose semantics are being preserved; adding that reference would help readers locate the baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the presentation of the sparsity rule, its correctness, and the experimental validation.
read point-by-point responses
-
Referee: [§3] §3 (Sparsity Rule): The criterion for identifying 'essential' counters is defined locally in terms of currently active counters and immediate transitions. No argument is given that this rule remains complete when a counter incremented on one branch later constrains acceptance on an alternative path, which is exactly the non-local dependency case highlighted by the central claim.
Authors: The local definition of essential counters is sufficient because the underlying counting-set automaton propagates all relevant counter constraints through its state space; any counter that could later affect an alternative path is already marked essential at the point of branching due to the way the original dense construction tracks possible values. We will add a short lemma in the revised §3 proving that the local rule is complete with respect to non-local dependencies. revision: yes
-
Referee: [§4] §4 (Correctness Argument): The manuscript asserts that the sparse representation yields an equivalent automaton, yet provides neither an inductive invariant relating sparse and full counting-sets nor an exhaustive case analysis for c-regexes whose counting constraints interact across epsilon-transitions. This equivalence is load-bearing for the efficiency claim.
Authors: We agree that an explicit inductive argument would improve clarity. The revised manuscript will include a new subsection in §4 that states the inductive invariant (the sparse set contains exactly the counter values that can still affect acceptance) and sketches the induction over both ordinary and epsilon transitions, covering interacting counters. revision: yes
-
Referee: [§5] §5 (Experimental Evaluation): Reported speed-ups are measured only on synthetic patterns; no data are given on whether any of the tested c-regexes exercise the non-local counter interactions that would falsify the sparsity rule. Without such cases the experiments cannot confirm that exact semantics are preserved in practice.
Authors: The synthetic suite was constructed to include branching patterns with multiple interacting counters; however, we acknowledge that explicit confirmation on real-world examples would be stronger. We will add a short subsection reporting results on a small set of regexes drawn from common libraries that contain non-local counting constraints. revision: partial
Circularity Check
No circularity: proposal for sparse counting-set data structure does not reduce to self-definition or fitted inputs.
full rationale
The provided abstract and description contain no equations, fitted parameters, or load-bearing self-citations. The central claim is an algorithmic proposal for maintaining only essential counter values in counting-sets to reduce replication overhead. This does not reduce by construction to its inputs, as no derivation chain, uniqueness theorem, or ansatz is invoked that would make the result equivalent to a prior fit or self-referential definition. The derivation is self-contained as a new data structure optimization without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
George Argyros & Loris D’Antoni (2018): The Learnability of Symbolic Automata. In: Computer Aided Verification - 30th International Conference, CA V 2018, Proceedings, Part I, Lecture Notes in Computer Science 10981, Springer, pp. 427–445, doi:10.1007/978-3-319-96145-3_23
-
[2]
Henrik Björklund, Wim Martens & Thomas Timm (2015):Efficient Incremental Evaluation of Succinct Regular Expressions. In: Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, VIC, Australia, October 19 - 23, 2015 , ACM, pp. 1541–1550, doi:10.1145/2806416.2806434
-
[3]
Available at https://swtch.com/~rsc/regexp/regexp3.html
Russ Cox (2010): Regular Expression Matching in the Wild: A tour of RE2, an efficient, production regular expression implementation. Available at https://swtch.com/~rsc/regexp/regexp3.html. Accessed: 2025-04-26
2010
-
[4]
James C Davis, Christy A Coghlan, Francisco Servant & Dongyoon Lee (2018): The impact of regular expression denial of service (ReDoS) in practice: an empirical study at the ecosystem scale. In: Proceedings of the 2018 26th ACM joint meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 246–256, d...
-
[5]
James C. Davis, Louis G. Michael, IV , Christy A. Coghlan, Francisco Servant & Dongyoon Lee (2019): Why aren’t regular expressions a lingua franca? An empirical study on the re-use and portability of regular expressions. In: Proceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engine...
-
[6]
Wouter Gelade, Marc Gyssens & Wim Martens (2012): Regular Expressions with Counting: Weak versus Strong Determinism. SIAM J. Comput. 41(1), pp. 160–190, doi:10.1137/100814196
-
[7]
Alexis Le Glaunec, Lingkun Kong & Konstantinos Mamouras (2023): Regular Expression Matching using Bit Vector Automata. Proc. ACM Program. Lang. 7, pp. 492–521, doi:10.1145/3586044
-
[8]
Lukás Holík, Juraj Síc, Lenka Turonová & Tomás V ojnar (2023):Fast Matching of Regular Patterns with Synchronizing Counting (Technical Report). CoRR abs/2301.12851. arXiv:2301.12851
arXiv 2023
-
[9]
Lingkun Kong, Qixuan Yu, Agnishom Chattopadhyay, Alexis Le Glaunec, Yi Huang, Konstantinos Mamouras & Kaiyuan Yang (2022): Software-hardware codesign for efficient in-memory regular pattern matching. In Ranjit Jhala & Isil Dillig, editors: PLDI ’22: 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation, San Diego, CA,...
-
[10]
Randy Smith, Cristian Estan & Somesh Jha (2008): XFA: Faster Signature Matching with Extended Automata. In: 2008 IEEE Symposium on Security and Privacy (SP 2008), 18-21 May 2008, Oakland, California, USA, IEEE Computer Society, pp. 187–201, doi:10.1109/SP.2008.14
-
[11]
In: 33rd USENIX Security Symposium (USENIX Security 24), pp
Weihao Su, Hong Huang, Rongchen Li, Haiming Chen & Tingjian Ge (2024): Towards an Effective Method of ReDoS Detection for Non-backtracking Engines. In: 33rd USENIX Security Symposium (USENIX Security 24), pp. 271–288
2024
-
[12]
In: 31st USENIX Security Symposium, USENIX Security 2022, Boston, MA, USA, August 10-12, 2022 , USENIX Association, pp
Lenka Turonová, Lukás Holík, Ivan Homoliak, Ondrej Lengál, Margus Veanes & Tomás V ojnar (2022): Counting in Regexes Considered Harmful: Exposing ReDoS Vulnerability of Nonbacktracking Matchers . In: 31st USENIX Security Symposium, USENIX Security 2022, Boston, MA, USA, August 10-12, 2022 , USENIX Association, pp. 4165–4182
2022
-
[13]
Lenka Turonová, Lukás Holík, Ondrej Lengál, Olli Saarikivi, Margus Veanes & Tomás V ojnar (2020):Regex matching with counting-set automata. Proc. ACM Program. Lang. 4, pp. 218:1–218:30, doi:10.1145/3428286
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.