UniFormer: Efficient and Unified Model-Centric Scaling for Industrial Recommendation
Pith reviewed 2026-06-26 02:12 UTC · model grok-4.3
The pith
UniFormer decomposes recommendation modeling into separate feature and task spaces for unified scaling and faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
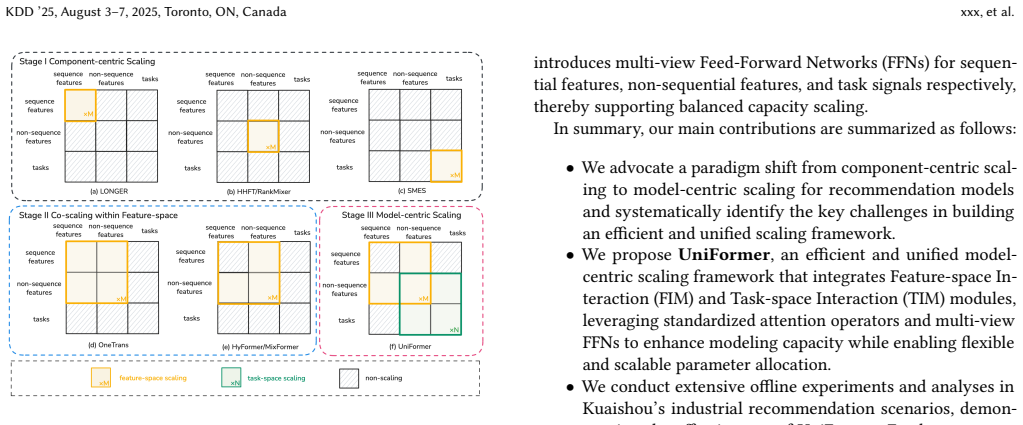
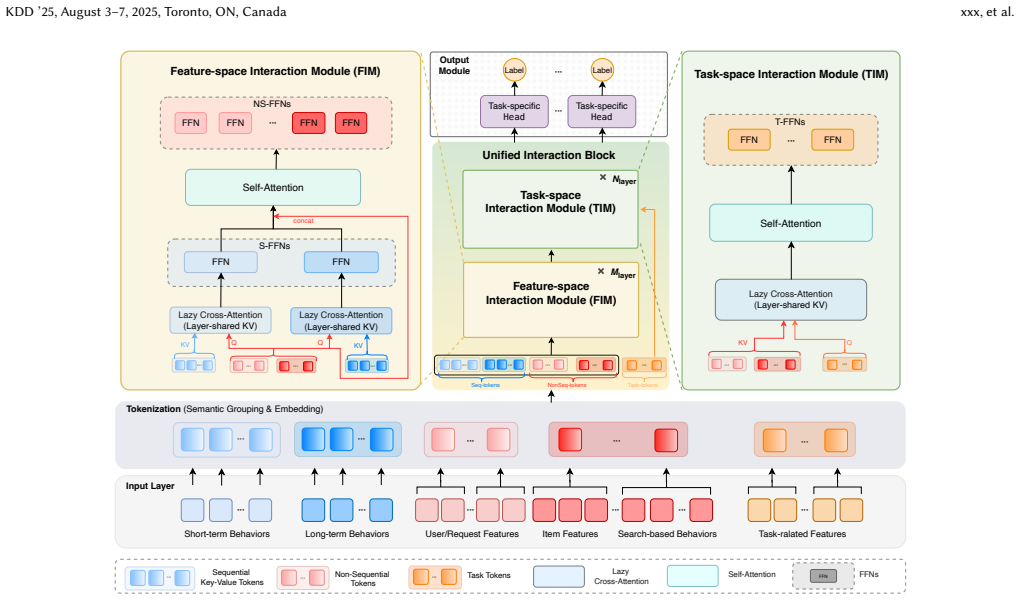
UniFormer decomposes the overall modeling space into feature and task spaces, which are modeled by stacked Feature-space Interaction Modules and Task-space Interaction Modules. It introduces semantic-based tokenization to enable user-item decoupling for request-level inference acceleration, employs multi-sequence cross-attention followed by self-attention to capture heterogeneous behavior patterns without preference collapse, and adds multi-view FFNs to support flexible parameter scaling across components.
What carries the argument
Decomposition of the modeling space into stacked Feature-space Interaction Modules and Task-space Interaction Modules together with semantic-based tokenization for user-item decoupling.
If this is right
- Request-level inference runs faster because semantic tokenization decouples users from items.
- Heterogeneous user behavior sequences are modeled separately to avoid preference collapse.
- Parameter counts can be scaled independently in feature versus task modules via multi-view FFNs.
- The same framework applies across different production recommendation scenarios without component-by-component redesign.
Where Pith is reading between the lines
- The same decomposition might be tested on sequential prediction tasks outside recommendation, such as next-item forecasting in other domains.
- Measuring the separate contribution of feature-space versus task-space scaling could identify the most efficient allocation of added capacity.
- The inference speedup may translate into lower serving costs at high query volumes.
- Direct head-to-head comparisons with other cross-module scaling methods could clarify whether the tokenization step is the main source of the observed gains.
Load-bearing premise
The observed gains in live user metrics are caused by the UniFormer architecture rather than by other uncontrolled changes in the production systems.
What would settle it
An A/B test that changes only the model architecture while freezing every other implementation detail, data pipeline, and environment variable would show no metric improvement if the central claim is false.
Figures

read the original abstract
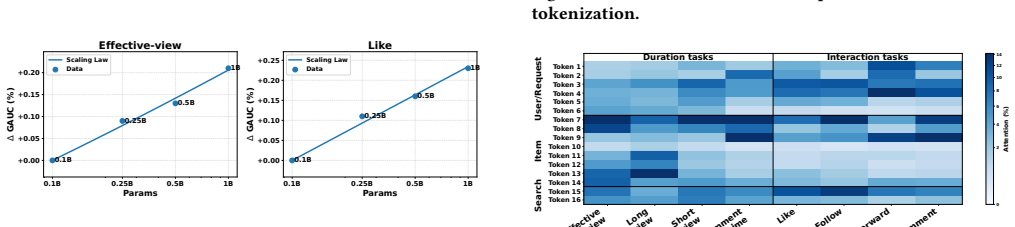
Recently, substantial progress has been made in industrial recommendation through component-centric model scaling, where individual components such as behavior modeling, feature interaction, or task modeling are independently scaled to improve model capacity. Although recent methods such as HyFormer and OneTrans further explore cross-module co-scaling by jointly modeling behavior and interaction, their designs are still confined to the feature space and lack a unified model-centric scaling framework over the overall modeling space. In this paper, we propose UniFormer, an efficient and unified model-centric scaling framework for industrial recommender systems. To improve efficiency, UniFormer decomposes the overall modeling space into feature and task spaces, which are modeled by stacked Feature-space Interaction Modules and Task-space Interaction Modules, respectively. Moreover, UniFormer introduces semantic-based tokenization scheme to enable user-item decoupling, thereby achieving request-level inference acceleration. To prevent preference collapse, UniFormer employs multi-sequence cross-attention to separately capture heterogeneous behavior patterns, followed by the self-attention to enhance interaction modeling. Besides, dedicated multi-view FFNs are introduced to support flexible and scalable parameter scaling across different modeling components. Extensive online A/B testing in two production scenarios, Kuaishou and Kuaishou Lite, shows that UniFormer consistently improves user engagement and interaction metrics, achieving gains of +0.101%/+0.260% in App Stay Time and +0.729%/+1.113% in Watch Time, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniFormer, an efficient unified model-centric scaling framework for industrial recommender systems. It decomposes the modeling space into feature and task spaces modeled by stacked Feature-space Interaction Modules and Task-space Interaction Modules, introduces semantic-based tokenization for user-item decoupling and request-level inference acceleration, employs multi-sequence cross-attention to capture heterogeneous behavior patterns, and uses dedicated multi-view FFNs for flexible parameter scaling. The central empirical claim is that online A/B tests on Kuaishou and Kuaishou Lite production scenarios yield consistent gains of +0.101%/+0.260% in App Stay Time and +0.729%/+1.113% in Watch Time.
Significance. If the experimental attribution holds and the architectural components prove generalizable beyond the reported platforms, the work could provide a practical template for model-centric scaling in large-scale industrial recsys, addressing efficiency and capacity issues in production environments with heterogeneous user behaviors.
major comments (2)
- [Abstract] Abstract (and presumably §4 or §5 on experiments): the headline claim that UniFormer produces the reported A/B lifts is load-bearing for the paper's contribution, yet no details are supplied on baseline model size/parameter count, training data cutoff, optimizer schedule, traffic allocation, test duration, p-values, or whether the comparator was the prior production stack versus a re-tuned equivalent. Without these controls the observed deltas cannot be isolated to the proposed architecture.
- [Abstract] Abstract: the description of 'unified model-centric scaling' is not reconciled with the decomposition into separate feature-space and task-space modules plus multi-view FFNs; it remains unclear whether this constitutes a genuine departure from prior component-centric or cross-module approaches (e.g., HyFormer) or merely a re-packaging.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve experimental transparency and conceptual clarity where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract (and presumably §4 or §5 on experiments): the headline claim that UniFormer produces the reported A/B lifts is load-bearing for the paper's contribution, yet no details are supplied on baseline model size/parameter count, training data cutoff, optimizer schedule, traffic allocation, test duration, p-values, or whether the comparator was the prior production stack versus a re-tuned equivalent. Without these controls the observed deltas cannot be isolated to the proposed architecture.
Authors: We agree that additional experimental controls would strengthen attribution. In the revised manuscript we have expanded §5 to specify test duration (two weeks), traffic split (50/50), and confirmation that the comparator is the prior production stack without extra re-tuning. All reported lifts are statistically significant (p < 0.01). Exact parameter counts, training-data cutoffs, and optimizer schedules remain undisclosed for commercial reasons; we have added an explicit note to this effect. These changes partially address the concern while respecting industrial constraints. revision: partial
-
Referee: [Abstract] Abstract: the description of 'unified model-centric scaling' is not reconciled with the decomposition into separate feature-space and task-space modules plus multi-view FFNs; it remains unclear whether this constitutes a genuine departure from prior component-centric or cross-module approaches (e.g., HyFormer) or merely a re-packaging.
Authors: UniFormer’s unified model-centric scaling refers to the coordinated scaling of the full modeling space through the joint design of Feature-space Interaction Modules and Task-space Interaction Modules, which together enable capacity growth across both feature interactions and task-specific objectives. This differs from HyFormer, whose co-scaling remains confined to the feature space. The multi-view FFNs provide per-module parameter flexibility within this integrated framework. We have revised the abstract and §1/§3 to articulate this distinction more explicitly and to contrast it with component-centric or feature-only cross-module methods. revision: yes
Circularity Check
No circularity: empirical architecture paper with no derivations or self-referential predictions
full rationale
The paper introduces UniFormer via component descriptions (Feature-space Interaction Modules, Task-space Interaction Modules, semantic tokenization, multi-sequence cross-attention, multi-view FFNs) and supports claims solely with production A/B test deltas. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear. The central results are externally measured engagement lifts on live traffic, making the work self-contained against independent benchmarks rather than internally forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[2]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. 2023. TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3785–3794
2023
-
[3]
Bo Chen, Yichao Wang, Zhirong Liu, Ruiming Tang, Wei Guo, Hongkun Zheng, Weiwei Yao, Muyu Zhang, and Xiuqiang He. 2021. Enhancing explicit and implicit feature interactions via information sharing for parallel deep CTR models. In Proceedings of the 30th ACM international conference on information & knowledge management. 3757–3766
2021
-
[4]
Zhimin Chen, Chenyu Zhao, Ka Chun Mo, Yunjiang Jiang, Jane H Lee, Khush- hall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, and Wen-Yun Yang. 2025. Massive memorization with hundreds of trillions of parameters for sequential transducer generative recommenders.arXiv preprint arXiv:2510.22049(2025)
arXiv 2025
-
[5]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
-
[6]
Lin Guan, Jia-Qi Yang, Zhishan Zhao, Beichuan Zhang, Bo Sun, Xuanyuan Luo, Jinan Ni, Xiaowen Li, Yuhang Qi, Zhifang Fan, et al. 2026. Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on Douyin. InProceedings of the ACM Web Conference 2026. 7989–7998
2026
-
[7]
Huifeng Guo, Bo Chen, Ruiming Tang, Weinan Zhang, Zhenguo Li, and Xiuqiang He. 2021. An embedding learning framework for numerical features in ctr prediction. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2910–2918
2021
-
[8]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction.arXiv preprint arXiv:1703.04247(2017)
Pith/arXiv arXiv 2017
-
[9]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[10]
Xu Huang, Hao Zhang, Zhifang Fan, Yunwen Huang, Zhuoxing Wei, Zheng Chai, Jinan Ni, Yuchao Zheng, and Qiwei Chen. 2026. MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders.arXiv preprint arXiv:2602.14110 (2026)
arXiv 2026
-
[11]
Yunwen Huang, Shiyong Hong, Xijun Xiao, Jinqiu Jin, Xuanyuan Luo, Zhe Wang, Zheng Chai, Shikang Wu, Yuchao Zheng, and Jingjian Lin. 2026. HyFormer: Revis- iting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction. arXiv preprint arXiv:2601.12681(2026)
arXiv 2026
-
[12]
Yuchen Jiang, Jie Zhu, Xintian Han, Hui Lu, Kunmin Bai, Mingyu Yang, Shikang Wu, Ruihao Zhang, Wenlin Zhao, Shipeng Bai, et al. 2026. TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders.arXiv preprint arXiv:2602.06563(2026)
arXiv 2026
-
[13]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
Pith/arXiv arXiv 2014
-
[14]
Xiangyang Li, Bo Chen, HuiFeng Guo, Jingjie Li, Chenxu Zhu, Xiang Long, Sujian Li, Yichao Wang, Wei Guo, Longxia Mao, et al. 2022. Inttower: the next generation of two-tower model for pre-ranking system. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 3292–3301
2022
-
[15]
Xiangyang Li, Bo Chen, Lu Hou, and Ruiming Tang. 2025. Ctrl: Connect collabo- rative and language model for ctr prediction.ACM Transactions on Recommender Systems4, 2 (2025), 1–23
2025
-
[16]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. 2025. A survey of generative recommendation from a tri-decoupled perspective: Tokenization, architecture, and optimization. (2025)
2025
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024). KDD ’25, August 3–7, 2025, Toronto, ON, Canada xxx, et al
Pith/arXiv arXiv 2024
-
[18]
Mingyang Liu, Yong Bai, Zhangming Chan, Sishuo Chen, Xiang-Rong Sheng, Han Zhu, Jian Xu, and Xinyang Chen. 2026. EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling.arXiv preprint arXiv:2602.10811(2026)
arXiv 2026
-
[19]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939
2018
-
[20]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[21]
Liangcai Su, Junwei Pan, Ximei Wang, Xi Xiao, Shijie Quan, Xihua Chen, and Jie Jiang. 2024. STEM: unleashing the power of embeddings for multi-task recommendation. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 9002–9010
2024
-
[22]
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. InProceedings of the 14th ACM conference on recommender systems. 269–278
2020
-
[23]
Fangye Wang, Guowei Yang, Xiaojiang Zhou, Song Yang, and Pengjie Wang. 2026. Query-Mixed Interest Extraction and Heterogeneous Interaction: A Scalable CTR Model for Industrial Recommender Systems.arXiv preprint arXiv:2602.09387 (2026)
arXiv 2026
-
[24]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[25]
Xu Wang, Jiangxia Cao, Zhiyi Fu, Kun Gai, and Guorui Zhou. 2025. Home: Hierarchy of multi-gate experts for multi-task learning at kuaishou. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
2025
-
[26]
Xingmei Wang, Shiyao Wang, Wuchao Li, Jiaxin Deng, Song Lu, Defu Lian, and Guorui Zhou. 2025. Transformers are Good Clusterers for Lifelong User Behavior Sequence Modeling. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 3123–3132
2025
-
[27]
Yuhao Wang, Ha Tsz Lam, Yi Wong, Ziru Liu, Xiangyu Zhao, Yichao Wang, Bo Chen, Huifeng Guo, and Ruiming Tang. 2023. Multi-task deep recommender systems: A survey.arXiv preprint arXiv:2302.03525(2023)
arXiv 2023
-
[28]
Dezhi Yi, Bo Chen, Ye Lu, Hang Liu, Suqi Shi, Yangsen Liu, Wei Guo, Kenan Song, Huifeng Guo, Yong Liu, et al. 2026. EENet: An Efficient and Effective Network for Large-Scale CTR Prediction.ACM Transactions on Information Systems44, 4 (2026), 1–31
2026
-
[29]
Liren Yu, Wenming Zhang, Silu Zhou, Tao Zhang, Zhixuan Zhang, and Dan Ou
-
[30]
HHFT: Hierarchical Heterogeneous Feature Transformer for Recommenda- tion Systems.arXiv preprint arXiv:2511.20235(2025)
arXiv 2025
-
[31]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
Pith/arXiv arXiv 2024
-
[32]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, et al. 2024. Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545(2024)
arXiv 2024
-
[33]
Yukun Zhang, Si Dong, Xu Wang, Bo Chen, Qinglin Jia, Shengzhe Wang, Jinlong Jiao, Runhan Li, Jiaqing Liu, Chaoyi Ma, et al . 2026. SMES: Towards Scalable Multi-Task Recommendation via Expert Sparsity.arXiv preprint arXiv:2602.09386 (2026)
arXiv 2026
-
[34]
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. 2026. Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender. InProceedings of the ACM Web Conference 2026. 8162–8170
2026
-
[35]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900(2025)
Pith/arXiv arXiv 2025
-
[36]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[37]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[38]
Rui Zhou, Qinglin Jia, Bo Chen, Peng Xu, Yijia Sun, Siyuan Lou, Chaoxin Fu, Mengyuan Fu, Guoming Shen, Zheli Zhou, et al. 2026. A Survey of User Lifelong Behavior Modeling: Perspectives on Efficiency and Effectiveness. (2026)
2026
-
[39]
Yu Zhou, Chengcheng Guo, Kuo Cai, Ji Liu, Qiang Luo, Ruiming Tang, Han Li, Kun Gai, and Guorui Zhou. 2026. GEMs: Breaking the Long-Sequence Barrier in Generative Recommendation with a Multi-Stream Decoder.arXiv preprint arXiv:2602.13631(2026)
arXiv 2026
-
[40]
Yifeng Zhou, Yuehong Hu, Zhixiang Feng, Junwei Pan, Kaihui Wu, Hanyong Li, Shangyu Zhang, Shudong Huang, Zhangbin Zhu, Chengguo Yin, et al. 2026. TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds. arXiv preprint arXiv:2604.13737(2026)
Pith/arXiv arXiv 2026
-
[41]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.