SurveilNav: Collaborative Object Goal Navigation with Robot and Surveillance System
Pith reviewed 2026-06-25 23:59 UTC · model grok-4.3
The pith
SurveilNav lets robots navigate better by collaborating with fixed surveillance cameras.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
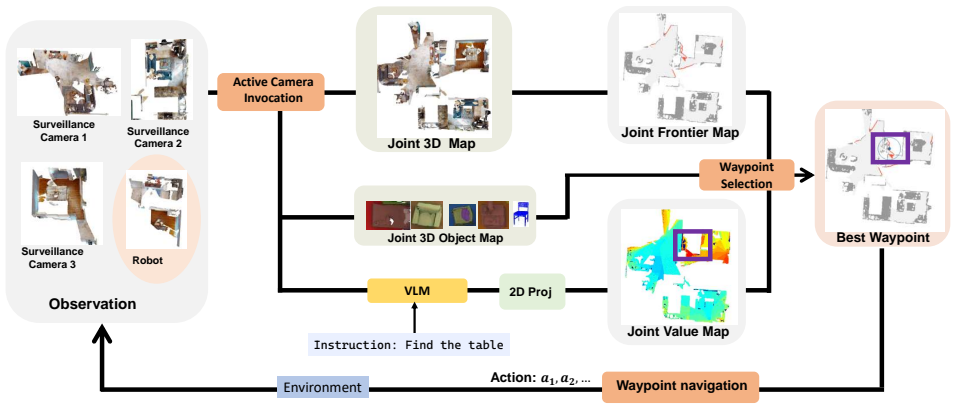
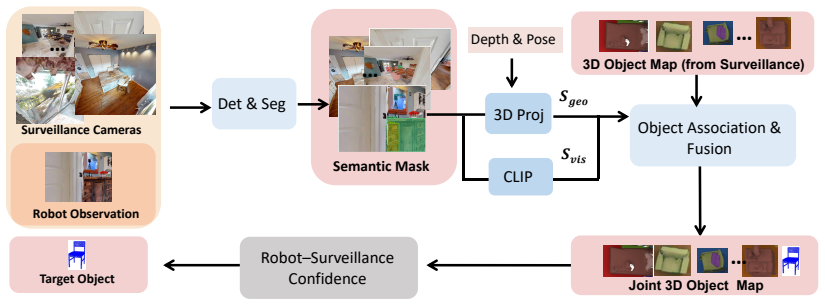
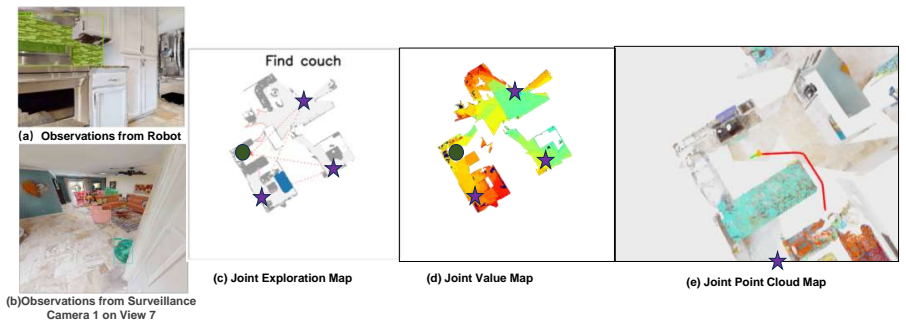
SurveilNav is a collaborative navigation framework that integrates active camera scheduling, joint 2D/3D mapping, VLM-based value estimation, and collaborative target verification. By synergizing the robot's dynamic local perception with the static global view of surveillance, this architecture effectively overcomes both the limited perception range of single agents and the inherent blind spots of fixed cameras, resolving inefficient exploration. Experimental results demonstrate that SurveilNav substantially outperforms existing methods, achieving state-of-the-art performance in both exploration efficiency and navigation success rate.
What carries the argument
The SurveilNav framework, which merges active camera scheduling, joint 2D/3D mapping, VLM-based value estimation, and collaborative target verification to combine robot mobility with surveillance views.
If this is right
- Exploration becomes more efficient in large indoor spaces by using multi-view information.
- Navigation success rates rise for object goal tasks compared with prior single-agent approaches.
- The method supports applications in large-scale search, home environments, and rescue missions.
- Inefficient exploration caused by perception limits is reduced through robot-surveillance synergy.
Where Pith is reading between the lines
- Buildings with existing camera networks could support robot tasks without adding many extra robots.
- The collaboration idea could apply to other wide-area robotic jobs like monitoring or delivery.
- Extensions might test performance when some cameras move or when new sensors are added.
Load-bearing premise
The components of active camera scheduling, joint mapping, value estimation, and target verification can reliably overcome single-robot perception limits and fixed-camera blind spots.
What would settle it
An experiment on indoor navigation benchmarks where SurveilNav shows no gain in success rate or exploration efficiency over single-robot baselines would disprove the main claim.
Figures


read the original abstract
With the growing deployment of surveillance systems in factories, offices, and homes, integrating them with robots offers a promising direction for collaborative and efficient task execution. However, existing approaches largely focus on single-robot scenarios and struggle with multi-view collaboration in large-scale environments. In this paper, we present a novel indoor collaborative object navigation dataset built on Habitat-Sim, featuring 206 cameras across 74 floors. The dataset enables systematic evaluation of an agent's ability to exploit multi-view surveillance information. To address the limitations of single-robot perception, we propose SurveilNav, a collaborative navigation framework that integrates active camera scheduling, joint 2D/3D mapping, VLM-based value estimation, and collaborative target verification. By synergizing the robot's dynamic local perception with the static global view of surveillance, this architecture effectively overcomes both the limited perception range of single agents and the inherent blind spots of fixed cameras, resolving inefficient exploration. Experimental results on the HM3D dataset demonstrate that SurveilNav substantially outperforms existing methods, achieving state-of-the-art performance in both exploration efficiency and navigation success rate. Moreover, the system shows strong potential for applications in large-scale search, home environments, and rescue missions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new collaborative object-goal navigation dataset on Habitat-Sim/HM3D augmented with 206 fixed surveillance cameras across 74 floors, and proposes the SurveilNav framework that combines active camera scheduling, joint 2D/3D mapping, VLM-based value estimation, and collaborative target verification. The central claim is that this architecture overcomes single-robot perception limits and fixed-camera blind spots, yielding state-of-the-art exploration efficiency and navigation success rates on the augmented HM3D scenes.
Significance. If the reported gains hold under the standard Habitat evaluation protocol, the work would be a useful contribution to multi-view robotic navigation by showing how static surveillance infrastructure can be actively scheduled and fused with a mobile agent. The released dataset itself is a concrete resource for the community studying collaborative perception.
minor comments (2)
- [§4] §4 (Experiments): the abstract asserts SOTA without naming the exact baselines or reporting the precise success-rate and SPL deltas; the experimental section should include a single consolidated table with all compared methods, metrics, and statistical significance to make the claim immediately verifiable.
- The description of the VLM-based value estimation module would benefit from an explicit statement of the prompt template and the precise output format used for value scoring, to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of the dataset as a community resource, and the recommendation for minor revision. We will incorporate any minor suggestions in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical system (SurveilNav) with components including active camera scheduling, joint mapping, VLM value estimation, and collaborative verification, evaluated on a new HM3D-based dataset with 206 cameras. The central claims are experimental outperformance and SOTA results in exploration efficiency and success rate. No derivation chain, equations, or first-principles predictions exist that reduce to fitted parameters or self-citations by construction. The evaluation protocol is described as standard for Habitat navigation tasks, with gains attributed directly to the collaborative architecture rather than any self-referential fitting or renaming. This is a standard empirical robotics paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Surveillance cameras provide complementary global views that can be actively scheduled and integrated with robot perception to resolve blind spots and limited range.
Reference graph
Works this paper leans on
-
[1]
Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,” inCVPR, 2023, pp. 23 171–23 181
2023
-
[2]
Esc: Exploration with soft commonsense constraints for zero- shot object navigation,
K. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “Esc: Exploration with soft commonsense constraints for zero- shot object navigation,” inICML, 2023, pp. 42 829–42 842
2023
-
[3]
L3mvn: Leveraging large language models for visual target navigation,
B. Yu, H. Kasaei, and M. Cao, “L3mvn: Leveraging large language models for visual target navigation,” inIROS, 2023, pp. 3554–3560
2023
-
[4]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “Vlfm: Vision- language frontier maps for zero-shot semantic navigation,” inICRA, 2024, pp. 42–48
2024
-
[5]
V oronav: V oronoi-based zero-shot object navigation with large language model,
P. Wu, Y . Mu, B. Wu, Y . Hou, J. Ma, S. Zhang, and C. Liu, “V oronav: V oronoi-based zero-shot object navigation with large language model,” arXiv preprint arXiv:2401.02695, 2024
arXiv 2024
-
[6]
V2x- sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,
Y . Li, D. Ma, Z. An, Z. Wang, Y . Zhong, S. Chen, and C. Feng, “V2x- sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,”IEEE robotics and automation letters, vol. 7, no. 4, pp. 10 914–10 921, 2022
2022
-
[7]
Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to- vehicle communication,
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to- vehicle communication,” inICRA, 2022, pp. 2583–2589
2022
-
[8]
Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection,
H. Yu, Y . Luo, M. Shu, Y . Huo, Z. Yang, Y . Shi, Z. Guo, H. Li, X. Hu, J. Yuanet al., “Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection,” inCVPR, 2022, pp. 21 361–21 370
2022
-
[9]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essaet al., “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,” arXiv preprint arXiv:1911.00357, 2019
arXiv 1911
-
[10]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inICCV, 2019, pp. 9339–9347
2019
-
[11]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,” NeurIPS, vol. 33, pp. 4247–4258, 2020
2020
-
[12]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” inICRA, 2017, pp. 3357–3364
2017
-
[13]
Objectnav revisited: On evaluation of embodied agents navigating to objects,
D. Batra, A. Gokaslan, A. Kembhavi, O. Maksymets, R. Mottaghi, M. Savva, A. Toshev, and E. Wijmans, “Objectnav revisited: On evaluation of embodied agents navigating to objects,”arXiv preprint arXiv:2006.13171, 2020
arXiv 2006
-
[14]
Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,” inECCV, 2020, pp. 104–120
2020
-
[15]
Navid: Video-based vlm plans the next step for vision-and-language navigation,
J. Zhang, K. Wang, R. Xu, G. Zhouet al., “Navid: Video-based vlm plans the next step for vision-and-language navigation,”arXiv preprint arXiv:2402.15852, 2024
Pith/arXiv arXiv 2024
-
[16]
Towards learning a generalist model for embodied navigation,
D. Zheng, S. Huang, L. Zhao, Y . Zhong, and L. Wang, “Towards learning a generalist model for embodied navigation,” inCVPR, 2024, pp. 13 624–13 634
2024
-
[17]
Urbannav: Learning language-guided urban navigation from web-scale human trajectories,
Y . Mei, Y . Yang, L. Guo, Q. Wanget al., “Urbannav: Learning language-guided urban navigation from web-scale human trajectories,” arXiv preprint arXiv:2512.09607, 2025
arXiv 2025
-
[18]
Habitat-web: Learning embodied object-search strategies from human demonstra- tions at scale,
R. Ramrakhya, E. Undersander, D. Batra, and A. Das, “Habitat-web: Learning embodied object-search strategies from human demonstra- tions at scale,” inCVPR, 2022, pp. 5173–5183
2022
-
[19]
Uni-navid: A video-based vision-language- action model for unifying embodied navigation tasks,
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-navid: A video-based vision-language- action model for unifying embodied navigation tasks,”arXiv preprint arXiv:2412.06224, 2024
Pith/arXiv arXiv 2024
-
[20]
Poliformer: Scaling on- policy rl with transformers results in masterful navigators,
K.-H. Zeng, Z. Zhang, K. Ehsani, R. Hendrix, J. Salvador, A. Herrasti, R. Girshick, A. Kembhavi, and L. Weihs, “Poliformer: Scaling on- policy rl with transformers results in masterful navigators,”arXiv preprint arXiv:2406.20083, 2024
arXiv 2024
-
[21]
C- nav: Towards self-evolving continual object navigation in open world,
M.-M. Yu, F. Zhu, W. Liu, Y . Yang, Q. Wang, W. Wu, and J. Liu, “C- nav: Towards self-evolving continual object navigation in open world,” arXiv preprint arXiv:2510.20685, 2025
Pith/arXiv arXiv 2025
-
[22]
Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models,
Y . Kuang, H. Lin, and M. Jiang, “Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models,” inFindings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 338–351
2024
-
[23]
Prioritized semantic learning for zero-shot instance navigation,
X. Sun, L. Liu, H. Zhi, R. Qiu, and J. Liang, “Prioritized semantic learning for zero-shot instance navigation,” inECCV, 2024, pp. 161– 178
2024
-
[24]
Ranger: A monocular zero-shot semantic navigation framework through contextual adapta- tion,
M.-M. Yu, Y . Chen, B. F. Karlsson, and W. Wu, “Ranger: A monocular zero-shot semantic navigation framework through contextual adapta- tion,”arXiv preprint arXiv:2512.24212, 2025
arXiv 2025
-
[25]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[26]
Qwen-vl: A frontier large vision-language model with versatile abilities,
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[27]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[28]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML. PmLR, 2021, pp. 8748–8763
2021
-
[29]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inICCV, 2021, pp. 9650–9660
2021
-
[30]
Seek: Semantic reasoning for object goal navigation in real world inspection tasks,
M. F. Ginting, S.-K. Kim, D. D. Fan, M. Palieri, M. J. Kochen- derfer, and A.-a. Agha-Mohammadi, “Seek: Semantic reasoning for object goal navigation in real world inspection tasks,”arXiv preprint arXiv:2405.09822, 2024
arXiv 2024
-
[31]
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batraet al., “Goat: Go to any thing,” arXiv preprint arXiv:2311.06430, 2023
arXiv 2023
-
[32]
Stronger together: Air-ground robotic collaboration using semantics,
I. D. Miller, F. Cladera, T. Smith, C. J. Taylor, and V . Kumar, “Stronger together: Air-ground robotic collaboration using semantics,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9643–9650, 2022
2022
-
[33]
Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,
Q. Chen, S. Tang, Q. Yang, and S. Fu, “Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,” in ICDCS, 2019, pp. 514–524
2019
-
[34]
Cooperative per- ception for 3d object detection in driving scenarios using infrastructure sensors,
E. Arnold, M. Dianati, R. De Temple, and S. Fallah, “Cooperative per- ception for 3d object detection in driving scenarios using infrastructure sensors,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 3, pp. 1852–1864, 2020
2020
-
[35]
V2vnet: Vehicle-to-vehicle communication for joint perception and prediction,
T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Ur- tasun, “V2vnet: Vehicle-to-vehicle communication for joint perception and prediction,” inECCV, 2020, pp. 605–621
2020
-
[36]
A cooperative perception system robust to localization errors,
Z. Song, F. Wen, H. Zhang, and J. Li, “A cooperative perception system robust to localization errors,” in2023 IEEE Intelligent Vehicles Symposium (IV), 2023, pp. 1–6
2023
-
[37]
Habitat-matterport 3d semantics dataset,
K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervetet al., “Habitat-matterport 3d semantics dataset,” inCVPR, 2023, pp. 4927– 4936
2023
-
[38]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”NeurIPS, vol. 37, pp. 21 875–21 911, 2024
2024
-
[39]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inICCV, 2023, pp. 4015–4026
2023
-
[40]
A fast marching level set method for monotonically advancing fronts
J. A. Sethian, “A fast marching level set method for monotonically advancing fronts.”proceedings of the National Academy of Sciences, vol. 93, no. 4, pp. 1591–1595, 1996
1996
-
[41]
Enhancing multi- robot semantic navigation through multimodal chain-of-thought score collaboration,
Z. Shen, H. Luo, K. Chen, F. Lv, and T. Li, “Enhancing multi- robot semantic navigation through multimodal chain-of-thought score collaboration,” inAAAI, vol. 39, no. 14, 2025, pp. 14 664–14 672
2025
-
[42]
Co-navgpt: Multi-robot cooperative vi- sual semantic navigation using large language models,
B. Yu, H. Kasaei, and M. Cao, “Co-navgpt: Multi-robot cooperative vi- sual semantic navigation using large language models,”arXiv preprint arXiv:2310.07937, 2023
arXiv 2023
-
[43]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environment,
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong, “Instructnav: Zero-shot system for generic instruction navigation in unexplored environment,”arXiv preprint arXiv:2406.04882, 2024
arXiv 2024
-
[44]
Vln-game: Vision-language equilibrium search for zero-shot semantic navigation,
B. Yu, Y . Liu, L. Han, H. Kasaei, T. Li, and M. Cao, “Vln-game: Vision-language equilibrium search for zero-shot semantic navigation,” arXiv preprint arXiv:2411.11609, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.