TabClean: Reusable LLM-Synthesized Programs for Tabular Data Cleaning
Pith reviewed 2026-06-25 19:32 UTC · model grok-4.3
The pith
TabClean compiles LLM reasoning into reusable guarded Python programs that clean new tables without repeated calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
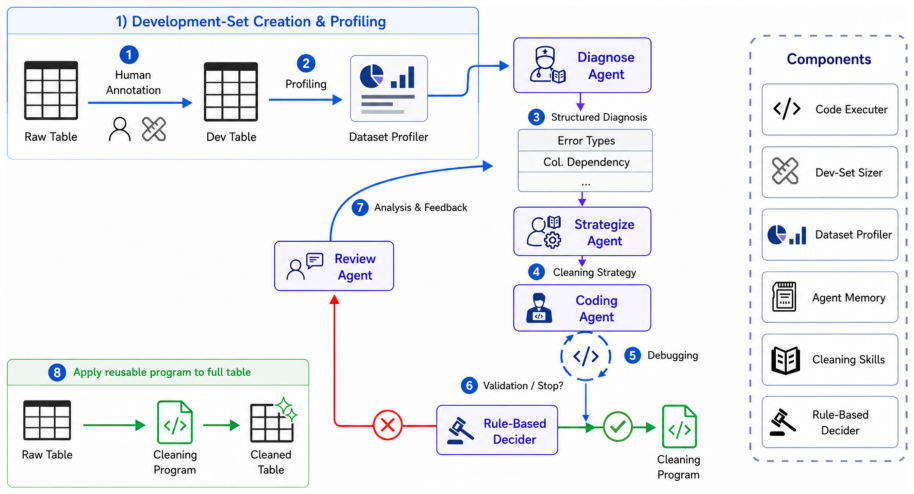
TabClean compiles LLM reasoning into reusable guarded cleaning programs. Given a dirty table and a small annotated development set, TabClean profiles table evidence, diagnoses repair mechanisms, synthesizes executable Python transformations, validates candidates with cell-level feedback, and commits the best program for reuse on schema-compatible batches. The key abstraction is an evidence-backed guarded repair clause that lets a deterministic transformation fire only when its dirty pattern, target-negative condition, evidence support, and scope constraints are satisfied.
What carries the argument
The evidence-backed guarded repair clause, a structure that ties a deterministic Python transformation to explicit conditions on dirty patterns, negative targets, supporting evidence, and scope so the transformation applies safely and only when warranted.
If this is right
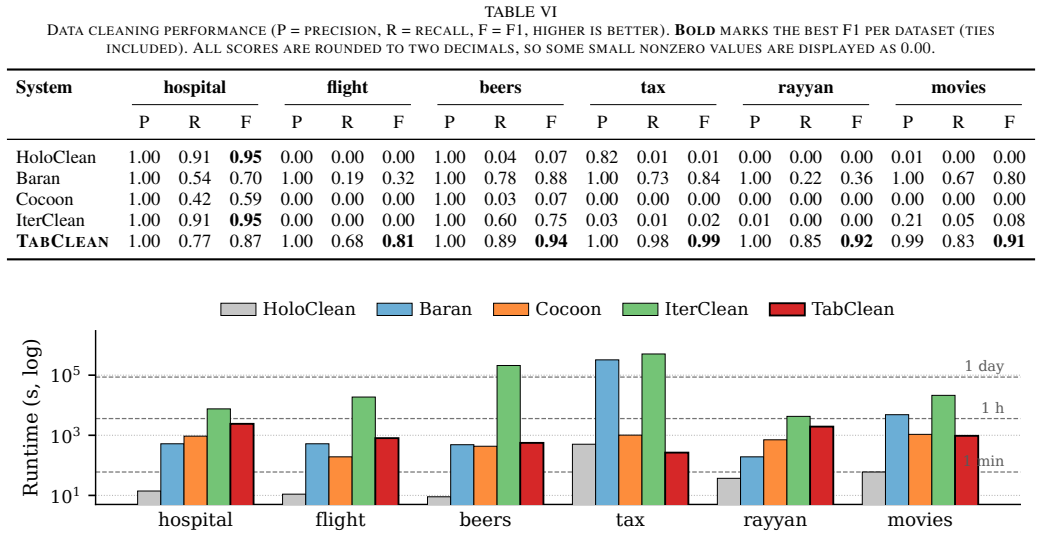
- TabClean achieves high precision across six benchmarks and improves F1 over rule-based, learning-based, and LLM-based baselines on five datasets.
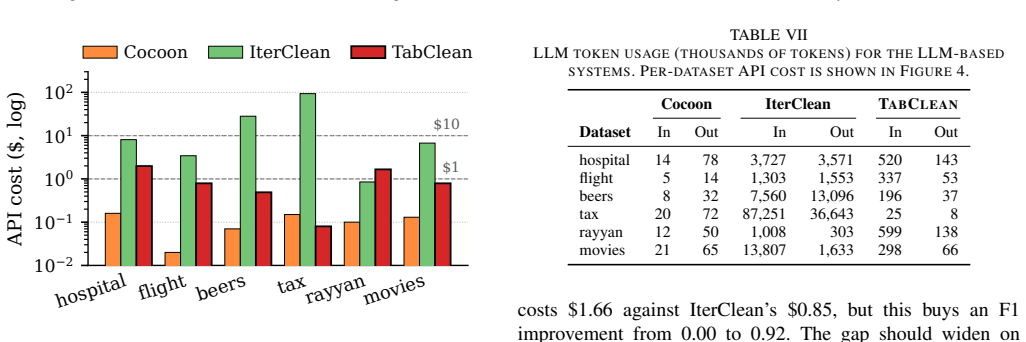
- Recurring runtime and API cost drop because repeated LLM inference is replaced by deterministic program execution on new batches.
- The synthesized programs can be committed and applied to any future table that matches the original schema without further LLM involvement.
- Cell-level feedback during validation guides selection of the final program before reuse.
Where Pith is reading between the lines
- Production analytics pipelines that ingest periodic batches could adopt the same compile-once, run-many pattern to control LLM spend.
- The guarded-clause design might transfer to other data tasks such as schema mapping or value normalization where deterministic rules need safe triggers.
- If the small development set must be re-annotated for every schema change, the net savings would shrink for highly variable data sources.
Load-bearing premise
A small annotated development set plus table profiling is sufficient to synthesize programs that generalize correctly to schema-compatible batches via the guarded repair clauses.
What would settle it
Run the synthesized program on a held-out schema-compatible batch and measure whether precision or F1 drops below the level achieved by direct LLM calls on the same batch; a clear drop would falsify the reuse claim.
Figures

read the original abstract
Reliable analytics and machine-learning pipelines depend on clean tabular data, yet production tables often contain missing values, typographical errors, inconsistent formats, violated dependencies, unit mismatches, and ambiguous categorical values. Existing cleaning systems make different trade-offs. Constraint-based systems need experts to specify rules. Learning-based systems need labels or retraining. Recent LLM-based cleaners reduce setup effort, but many call an LLM on rows, cells, or repeated workflow steps, so their cost grows with table size and with every recurring batch. We present TabClean, a model-training-free system that compiles LLM reasoning into reusable guarded cleaning programs. Given a dirty table and a small annotated development set, TabClean profiles table evidence, diagnoses repair mechanisms, synthesizes executable Python transformations, validates candidates with cell-level feedback, and commits the best program for reuse on schema-compatible batches. The key abstraction is an evidence-backed guarded repair clause. A deterministic transformation may fire only when its dirty pattern, target-negative condition, evidence support, and scope constraints are satisfied. Across six benchmarks, TabClean achieves high precision, improves F1 over representative rule-based, learning-based, and LLM-based baselines on five datasets, and substantially reduces recurring runtime and API cost by replacing repeated LLM inference with deterministic program execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TabClean, a model-training-free system that uses an LLM to synthesize reusable Python programs containing evidence-backed guarded repair clauses (dirty pattern, target-negative condition, evidence support, scope constraints) from a small annotated development set plus table profiling. These programs are validated with cell-level feedback and then applied deterministically to schema-compatible batches, avoiding repeated LLM calls. The abstract reports high precision, F1 improvements over rule-based, learning-based, and LLM-based baselines on five of six benchmarks, and substantial reductions in recurring runtime and API cost.
Significance. If the generalization of the guarded programs holds, the work could meaningfully reduce the operational cost of LLM-based data cleaning in production pipelines that process recurring batches, by amortizing LLM inference into one-time synthesis while preserving accuracy through deterministic execution and validation.
major comments (2)
- [Abstract] Abstract (benchmark results paragraph): the central claims of F1 improvement and recurring-cost reduction rest on the assumption that programs synthesized from a small annotated dev set will generalize via their guarded repair clauses to future schema-compatible batches. No quantitative details are supplied on dev-set size, how evidence support is quantified, whether the six benchmarks use internal splits or truly held-out batches with distribution shift, or error bars, so the data-to-claim link cannot be verified.
- [Abstract] Abstract (system description): the key abstraction of an 'evidence-backed guarded repair clause' is introduced without any formal definition, pseudocode, or example of how the four components (dirty pattern, target-negative condition, evidence support, scope constraints) are extracted or combined, making it impossible to assess whether the mechanism actually prevents overfitting to the dev set.
minor comments (1)
- [Abstract] The abstract refers to 'six benchmarks' and 'representative baselines' without naming the datasets or citing the baseline papers, which would aid reproducibility even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the abstract to improve clarity on experimental details and the core abstraction while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract (benchmark results paragraph): the central claims of F1 improvement and recurring-cost reduction rest on the assumption that programs synthesized from a small annotated dev set will generalize via their guarded repair clauses to future schema-compatible batches. No quantitative details are supplied on dev-set size, how evidence support is quantified, whether the six benchmarks use internal splits or truly held-out batches with distribution shift, or error bars, so the data-to-claim link cannot be verified.
Authors: We agree the abstract would benefit from explicit indicators. The full manuscript details dev-set sizes (20-150 rows, Section 4.1), evidence support as cell-match fraction with threshold 3 (Section 3.3), held-out schema-compatible batches with distribution shift (Section 4.2), and mean/std over 5 runs (Section 5.1). We will revise the abstract to include brief quantitative phrasing such as 'from dev sets of ~100 rows on held-out batches' to make the generalization basis verifiable. revision: yes
-
Referee: [Abstract] Abstract (system description): the key abstraction of an 'evidence-backed guarded repair clause' is introduced without any formal definition, pseudocode, or example of how the four components (dirty pattern, target-negative condition, evidence support, scope constraints) are extracted or combined, making it impossible to assess whether the mechanism actually prevents overfitting to the dev set.
Authors: The abstract's brevity precludes full detail, but Section 3.2 formally defines the clause with the four components, Algorithm 1 gives synthesis pseudocode, and Figure 1 shows an extraction example from LLM reasoning plus profiling. Guards require multi-cell evidence support and schema scope to limit overfitting. We will add a parenthetical reference '(formal definition in Section 3)' to the abstract. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper presents TabClean as an empirical system that synthesizes guarded repair programs from a small annotated development set and evaluates them on six benchmarks, reporting F1 improvements and cost reductions versus baselines. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to an input by construction. The generalization claim is framed as an experimental outcome rather than a definitional or self-referential necessity, making the derivation self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A small annotated development set is representative enough for the LLM to synthesize programs that generalize to schema-compatible batches.
invented entities (1)
-
evidence-backed guarded repair clause
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tabular data: Deep learning is not all you need,
R. Shwartz-Ziv and A. Armon, “Tabular data: Deep learning is not all you need,”Information fusion, vol. 81, pp. 84–90, 2022
2022
-
[2]
Why do tree-based models still outperform deep learning on typical tabular data?
L. Grinsztajn, E. Oyallon, and G. Varoquaux, “Why do tree-based models still outperform deep learning on typical tabular data?” in Proceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[3]
Data cleaning: Overview and emerging challenges,
X. Chu, I. F. Ilyas, S. Krishnan, and J. Wang, “Data cleaning: Overview and emerging challenges,” inProceedings of the 2016 international conference on management of data, 2016, pp. 2201–2206
2016
-
[4]
I. F. Ilyas and X. Chu,Data Cleaning, ser. ACM Books. Morgan & Claypool Publishers, 2019
2019
-
[5]
Detecting data errors: Where are we and what needs to be done?
Z. Abedjan, X. Chu, D. Deng, R. C. Fernandez, I. F. Ilyas, M. Ouz- zani, P. Papotti, M. Stonebraker, and N. Tang, “Detecting data errors: Where are we and what needs to be done?”Proceedings of the VLDB Endowment, vol. 9, no. 12, pp. 993–1004, 2016
2016
-
[6]
How to clean noisy and erroneous big data using machine learn- ing,
Tamr, “How to clean noisy and erroneous big data using machine learn- ing,” Tamr Blog, 2017. [Online]. Available: https://www.tamr.com/blog/ how-to-clean-noisy-and-erroneous-big-data-using-machine-learning/
2017
-
[7]
Data cleaning is a machine learning problem that needs data systems help!
I. F. Ilyas and X. Chu, “Data cleaning is a machine learning problem that needs data systems help!” ACM SIGMOD Blog, 2019. [Online]. Available: http://wp.sigmod.org/?p=2288
2019
-
[8]
Variable extraction for model recovery in scientific literature,
C. Liu, E. Noriega-Atala, A. Pyarelal, C. T. Morrison, and M. Cafarella, “Variable extraction for model recovery in scientific literature,” inPro- ceedings of the 1st Workshop on AI and Scientific Discovery: Directions and Opportunities, 2025, pp. 1–12
2025
-
[9]
Data civilizer 2.0: a holistic framework for data preparation and analytics,
E. K. Rezig, M. Ouzzani, A. K. Elmagarmid, W. G. Aref, and M. Stone- braker, “Data civilizer 2.0: a holistic framework for data preparation and analytics,”Proceedings of the VLDB Endowment, vol. 12, no. 12, pp. 1954–1957, 2019
1954
-
[10]
Data ambiguity strikes back: How documentation improves gpt’s text-to-sql,
Z. Huang, P. K. Damalapati, and E. Wu, “Data ambiguity strikes back: How documentation improves gpt’s text-to-sql,”arXiv preprint arXiv:2310.18742, 2023
arXiv 2023
-
[11]
Activeclean: Interactive data cleaning for statistical modeling
S. Krishnan, J. Wang, E. Wu, M. J. Franklin, and K. Goldberg, “Activeclean: Interactive data cleaning for statistical modeling.”Proc. VLDB Endow., vol. 9, no. 12, pp. 948–959, 2016
2016
-
[12]
Conditional functional dependencies for capturing data inconsistencies,
W. Fan, F. Geerts, X. Jia, and A. Kementsietsidis, “Conditional functional dependencies for capturing data inconsistencies,”ACM Trans. Database Syst., vol. 33, no. 2, Jun. 2008. [Online]. Available: https://doi.org/10.1145/1366102.1366103
-
[13]
Holistic data cleaning: Putting violations into context,
X. Chu, I. F. Ilyas, and P. Papotti, “Holistic data cleaning: Putting violations into context,” in2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, 2013, pp. 458–469
2013
-
[14]
Don’t be scared: use scalable automatic repairing with maximal likelihood and bounded changes,
M. Yakout, L. Berti-’Equille, and A. K. Elmagarmid, “Don’t be scared: use scalable automatic repairing with maximal likelihood and bounded changes,” inProceedings of the 2013 ACM SIGMOD International Conference on Management of Data, 2013, pp. 553–564
2013
-
[15]
Holoclean: Holistic data repairs with probabilistic inference,
T. Rekatsinas, X. Chu, I. F. Ilyas, and C. R’e, “Holoclean: Holistic data repairs with probabilistic inference,”arXiv preprint arXiv:1702.00820, 2017
Pith/arXiv arXiv 2017
-
[16]
Raha: A configuration-free error detec- tion system,
M. Mahdavi, Z. Abedjan, R. Castro Fernandez, S. Madden, M. Ouzzani, M. Stonebraker, and N. Tang, “Raha: A configuration-free error detec- tion system,” inProceedings of the 2019 International Conference on Management of Data, 2019, pp. 865–882
2019
-
[17]
Holodetect: Few-shot learning for error detection,
A. Heidari, J. McGrath, I. F. Ilyas, and T. Rekatsinas, “Holodetect: Few-shot learning for error detection,” inProceedings of the 2019 international conference on management of data, 2019, pp. 829–846
2019
-
[18]
Baran: Effective error correction via a unified context representation and transfer learning,
M. Mahdavi and Z. Abedjan, “Baran: Effective error correction via a unified context representation and transfer learning,”Proceedings of the VLDB Endowment, vol. 13, no. 12, pp. 1948–1961, 2020
1948
-
[19]
Can foundation models wrangle your data?
A. Narayan, I. Chami, L. Orr, S. Arora, and C. R’e, “Can foundation models wrangle your data?”arXiv preprint arXiv:2205.09911, 2022
arXiv 2022
-
[20]
Large language models as data preprocessors,
H. Zhang, Y . Dong, C. Xiao, and M. Oyamada, “Large language models as data preprocessors,”arXiv preprint arXiv:2308.16361, 2023
arXiv 2023
-
[21]
Retclean: Retrieval-based data cleaning using foundation models and data lakes,
Z. A. Naeem, M. S. Ahmad, M. Y . Eltabakh, M. Ouzzani, and N. Tang, “Retclean: Retrieval-based data cleaning using foundation models and data lakes,”Proceedings of the VLDB Endowment, vol. 17, pp. 4421– 4424, 2024
2024
-
[22]
Cleanagent: Automating data standard- ization with llm-based agents,
D. Qi, Z. Miao, and J. Wang, “Cleanagent: Automating data standard- ization with llm-based agents,”arXiv preprint arXiv:2403.08291, 2024
arXiv 2024
-
[23]
Autodcworkflow: Llm-based data cleaning workflow auto-generation and benchmark,
L. Li, L. Fang, and V . I. Torvik, “Autodcworkflow: Llm-based data cleaning workflow auto-generation and benchmark,”arXiv preprint arXiv:2412.06724, 2024
arXiv 2024
-
[24]
Data cleaning using large language models,
S. Zhang, Z. Huang, and E. Wu, “Data cleaning using large language models,” in2025 IEEE 41st International Conference on Data Engi- neering Workshops (ICDEW). IEEE, 2025, pp. 28–32
2025
-
[25]
Gidcl: A graph- enhanced interpretable data cleaning framework with large language models,
M. Yan, Y . Wang, Y . Wang, X. Miao, and J. Li, “Gidcl: A graph- enhanced interpretable data cleaning framework with large language models,”Proceedings of the ACM on Management of Data, vol. 2, no. 6, pp. 1–29, 2024
2024
-
[26]
Can llms clean up your mess? a survey of application- ready data preparation with llms,
W. Zhou, J. Zhou, H. Wang, Z. Li, Q. He, S. Han, G. Li, X. Zhou, Y . He, C. Liuet al., “Can llms clean up your mess? a survey of application- ready data preparation with llms,”arXiv preprint arXiv:2601.17058, 2026
arXiv 2026
-
[27]
Iterclean: An iterative data cleaning framework with large language models,
W. Ni, K. Zhang, X. Miao, X. Zhao, Y . Wu, and J. Yin, “Iterclean: An iterative data cleaning framework with large language models,” in Proceedings of the ACM Turing Award Celebration Conference-China 2024, 2024, pp. 100–105
2024
-
[28]
Leveraging structured and unstructured data for tabular data cleaning,
P. Mehraet al., “Leveraging structured and unstructured data for tabular data cleaning,” in2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 5765–5768
2024
-
[29]
Truth finding on the deep web: is the problem solved?
X. Li, X. L. Dong, K. Lyons, W. Meng, and D. Srivastava, “Truth finding on the deep web: is the problem solved?”Proc. VLDB Endow., vol. 6, no. 2, p. 97–108, Dec. 2012. [Online]. Available: https://doi.org/10.14778/2535568.2448943
-
[30]
Llmclean: Context-aware tabular data cleaning via llm-generated ofds,
F. Biester, M. Abdelaal, and D. Del Gaudio, “Llmclean: Context-aware tabular data cleaning via llm-generated ofds,” inEuropean Conference on Advances in Databases and Information Systems. Springer, 2024, pp. 68–78
2024
-
[31]
Quite: A query rewrite system beyond rules with llm agents,
Y . Song, H. Yan, J. Lao, Y . Wang, Y . Li, Y . Zhou, J. Wang, and M. Tang, “Quite: A query rewrite system beyond rules with llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2506.07675
arXiv 2026
-
[32]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[33]
Teaching large language models to self-debug,
X. Chen, M. Lin, N. Sch ¨arli, and D. Zhou, “Teaching large language models to self-debug,” 2023
2023
-
[34]
Reflexion: Language agents with verbal reinforcement learn- ing,
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learn- ing,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[35]
Large language models can be easily distracted by irrelevant context,
F. Shi, X. Chen, K. Misra, N. Scales, D. Dohan, E. H. Chi, N. Sch”arli, and D. Zhou, “Large language models can be easily distracted by irrelevant context,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 31 210–31 227
2023
-
[36]
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack,
Y . Kuratov, A. Bulatov, P. Anokhin, I. Rodkin, D. Sorokin, A. Sorokin, and M. Burtsev, “Babilong: Testing the limits of llms with long context reasoning-in-a-haystack,”Advances in Neural Information Processing Systems, vol. 37, pp. 106 519–106 554, 2024
2024
-
[37]
Hospital compare,
Centers for Medicare & Medicaid Services, “Hospital compare,” Provider Data Catalog, 2012, accessed: 2026-06-09. [Online]. Available: https://data.cms.gov/provider-data/topics/hospitals
2012
-
[38]
Craft beers dataset,
J. N. Hould, “Craft beers dataset,” Kaggle dataset, n.d., accessed: 2026- 04-22. [Online]. Available: https://www.kaggle.com/datasets/nickhould/ craft-cans
2026
-
[39]
Messing up with bart: error generation for evaluating data- cleaning algorithms,
P. C. Arocena, B. Glavic, G. Mecca, R. J. Miller, P. Papotti, and D. Santoro, “Messing up with bart: error generation for evaluating data- cleaning algorithms,”Proceedings of the VLDB Endowment, vol. 9, no. 2, pp. 36–47, 2015
2015
-
[40]
Rayyan—a web and mobile app for systematic reviews,
M. Ouzzani, H. Hammady, Z. Fedorowicz, and A. Elmagarmid, “Rayyan—a web and mobile app for systematic reviews,”Systematic reviews, vol. 5, no. 1, p. 210, 2016
2016
-
[41]
The magellan data repository,
S. Das, A. Doan, P. S. G. C., C. Gokhale, P. Konda, Y . Govind, and D. Paulsen, “The magellan data repository,” https://sites.google.com/site/ anhaidgroup/useful-stuff/the-magellan-data-repository
-
[42]
Trends in cleaning relational data: Consistency and deduplication,
I. F. Ilyas and X. Chu, “Trends in cleaning relational data: Consistency and deduplication,”Foundations and Trends in Databases, vol. 5, no. 4, pp. 281–393, 2015
2015
-
[43]
Eracer: a database approach for statistical inference and data cleaning,
C. Mayfield, J. Neville, and S. Prabhakar, “Eracer: a database approach for statistical inference and data cleaning,” inProceedings of the 2010 ACM SIGMOD International Conference on Management of data, 2010, pp. 75–86
2010
-
[44]
Castle: Causal cascade updates in relational databases with large language models,
Y . Su, Y . Zhang, Z. Shi, B. Ribeiro, and E. Bertino, “Castle: Causal cascade updates in relational databases with large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, No...
2025
-
[45]
G. Li, X. Zhou, and X. Zhao, “Llm for data management,”Proc. VLDB Endow., vol. 17, no. 12, p. 4213–4216, Aug. 2024. [Online]. Available: https://doi.org/10.14778/3685800.3685838
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.