ViP-VL: Vietnamese Self-supervised Speech Pretraining Model with Vector-Quantization Learning
Pith reviewed 2026-06-27 12:07 UTC · model grok-4.3
The pith
ViP-VL pretrained on 17,000 hours of unlabeled Vietnamese speech sets new state-of-the-art results on automatic speech recognition, speech emotion recognition, dialect classification, and speaker verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViP-VL is a self-supervised speech pretraining model that leverages vector-quantization learning within the BEST-RQ framework on a ChunkFormer backbone. By applying Acoustic Stacking and Receptive Field Alignment, it achieves synchronized 8x subsampling, and a specialized Mask Selection Strategy enhances representation robustness. Pretrained on 17,000 hours of unlabeled Vietnamese speech, this model sets new state-of-the-art results on Automatic Speech Recognition, Speech Emotion Recognition, Dialect Classification, and Speaker Verification tasks.
What carries the argument
Acoustic Stacking combined with Receptive Field Alignment to enable synchronized 8x subsampling inside ChunkFormer, together with the Mask Selection Strategy inside BEST-RQ vector-quantization pretraining.
If this is right
- Vietnamese automatic speech recognition systems can reach higher accuracy by starting from the released ViP-VL weights.
- Speech emotion recognition for Vietnamese audio improves when fine-tuned from the same pretrained representations.
- Dialect classification accuracy for Vietnamese rises with the new model as initialization.
- Speaker verification performance on Vietnamese voices benefits from the same pretraining checkpoint.
- The public release of weights and code enables additional Vietnamese speech applications and experiments.
Where Pith is reading between the lines
- The 8x subsampling may reduce memory and compute needs when processing long audio recordings in practice.
- The same stacking and alignment steps could be tested on other languages that have large unlabeled speech collections.
- Community fine-tuning of the released model on narrow domains such as medical or broadcast Vietnamese could produce further task-specific gains.
Load-bearing premise
The performance gains are produced by Acoustic Stacking, Receptive Field Alignment, and the Mask Selection Strategy rather than by the scale of the data or model size alone.
What would settle it
A controlled experiment that trains a standard BEST-RQ ChunkFormer model on the identical 17,000 hours of Vietnamese speech without Acoustic Stacking, Receptive Field Alignment, or the Mask Selection Strategy and checks whether downstream task scores still match or exceed the reported results.
Figures
read the original abstract
We present ViP-VL, an efficient Vietnamese Self-supervised speech Pretraining model leveraging Vector-quantization Learning. To bridge the gap between high-resolution audio and efficient processing, ViP-VL incorporates Acoustic Stacking and Receptive Field Alignment to enable a synchronized 8x subsampling rate within the ChunkFormer architecture, while further enhancing representation robustness through a specialized Mask Selection Strategy during pretraining on the BEST-RQ framework. Pretrained on 17,000 hours of unlabeled Vietnamese speech, our model establishes new state-of-the-art results across four major downstream tasks: Automatic Speech Recognition, Speech Emotion Recognition, Dialect Classification, and Speaker Verification. To facilitate future research and the development of high-performance Vietnamese speech technologies, we publicly release our pretrained weights and implementation at github.com/khanld/chunkformer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViP-VL, a self-supervised Vietnamese speech pretraining model that extends ChunkFormer with BEST-RQ via vector quantization. It proposes Acoustic Stacking and Receptive Field Alignment to achieve synchronized 8x subsampling, plus a Mask Selection Strategy during pretraining. The model is trained on 17,000 hours of unlabeled Vietnamese speech and claims new state-of-the-art results on Automatic Speech Recognition, Speech Emotion Recognition, Dialect Classification, and Speaker Verification. Pretrained weights and code are released publicly.
Significance. If the empirical results are robust and the proposed architectural and training modifications are shown to drive gains beyond data scale alone, the work would provide a valuable open resource for Vietnamese speech technology and demonstrate practical adaptations of self-supervised methods to a lower-resource language setting.
major comments (1)
- [Experiments] The manuscript attributes the reported SOTA gains specifically to Acoustic Stacking, Receptive Field Alignment, and Mask Selection Strategy, yet provides no ablation studies that disable or remove these components while holding data volume, model size, and training framework fixed. Without such controlled comparisons (e.g., in the Experiments section), the causal link between the three modifications and the headline downstream numbers cannot be established versus simple scaling effects.
minor comments (1)
- [Abstract] The abstract asserts new state-of-the-art results across four tasks but supplies no numerical metrics, baseline comparisons, or statistical tests; this should be augmented with at least headline numbers and references to the corresponding tables.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive suggestion regarding ablation studies. We address the comment point-by-point below.
read point-by-point responses
-
Referee: [Experiments] The manuscript attributes the reported SOTA gains specifically to Acoustic Stacking, Receptive Field Alignment, and Mask Selection Strategy, yet provides no ablation studies that disable or remove these components while holding data volume, model size, and training framework fixed. Without such controlled comparisons (e.g., in the Experiments section), the causal link between the three modifications and the headline downstream numbers cannot be established versus simple scaling effects.
Authors: We agree that controlled ablation studies are necessary to isolate the contributions of Acoustic Stacking, Receptive Field Alignment, and Mask Selection Strategy from potential scaling effects. The current manuscript does not include such ablations. In the revised version, we will add experiments in the Experiments section that disable each component individually (while fixing data volume at 17k hours, model size, and the BEST-RQ training framework) and report the resulting performance drops on the downstream tasks. This will provide direct evidence for the causal impact of the proposed modifications. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivation chain
full rationale
The manuscript describes an empirical self-supervised pretraining pipeline (ChunkFormer + BEST-RQ with three architectural tweaks) trained on 17k hours of Vietnamese speech and evaluated on four downstream tasks. No equations, uniqueness theorems, or parameter-fitting steps are presented that could reduce a claimed prediction or result to its own inputs by construction. All performance claims rest on reported experimental outcomes rather than any self-referential logic, self-citation load-bearing argument, or ansatz smuggled through prior work. This is the standard non-circular case for an applied ML paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- subsampling factor
axioms (1)
- domain assumption BEST-RQ framework produces robust speech representations when combined with the listed modifications
Reference graph
Works this paper leans on
-
[1]
Introduction Self-supervised learning (SSL) has recently driven signifi- cant advancements in speech processing. By leveraging vast amounts of unlabeled data, these approaches enable the mod- els to learn robust acoustic representations that, when com- bined with supervised fine-tuning, substantially improve per- formance. This capability is particularly ...
-
[2]
demonstrates the benefits of massive multilingual pretrain- ing. In contrast, predictive approaches, pioneered by HuBERT [4], treat pretraining as a masked token prediction task by gen- erating discrete targets viak-means clustering on intermediate features. W2v-BERT [5] subsequently unified these paradigms by utilizing contrastive and predictive losses s...
Pith/arXiv arXiv 2026
-
[3]
Architecture ViP-VL leverages BEST-RQ, a paradigm that streamlines self- supervised learning via a frozen, randomly initialized quantizer
ViP-VL 2.1. Architecture ViP-VL leverages BEST-RQ, a paradigm that streamlines self- supervised learning via a frozen, randomly initialized quantizer. This approach eliminates the need for the computationally ex- pensive codebook training required by wav2vec 2.0 [1] or the iterative clustering used in HuBERT [4]. By utilizing fixed random projections to m...
-
[4]
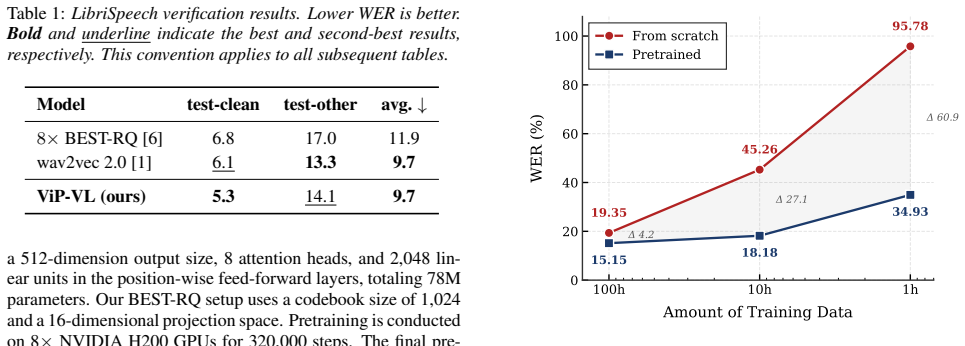
Experiments 3.1. ViP-VL Pretraining and Evaluations Proposal Verification.We first validate our architecture by pretraining on the 960-hour LibriSpeech dataset [23] and fine- tuning on the 100-hour subset. As shown in Table 1, our method bridges the performance gap typical of high compres- sion, achieving performance comparable to the2×baseline while redu...
2020
-
[5]
Conclusion In this paper, we introduce ViP-VL, an efficient Vietnamese self-supervised speech pretraining model leveraging Vector- quantization Learning. By combining the BEST-RQ framework with a ChunkFormer encoder, a receptive field-aligned stacking strategy, and a specialized mask selection strategy, we achieve state-of-the-art performance across multi...
-
[6]
All scientific content, experimental design, and re- sults were produced by the authors
Generative AI Use Disclosure Generative AI tools were used for editing and polishing the manuscript. All scientific content, experimental design, and re- sults were produced by the authors
-
[7]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[8]
wav2vec-C: A Self- Supervised Model for Speech Representation Learning,
S. Sadhu, D. He, C.-W. Huang, S. H. Mallidi, M. Wu, A. Ras- trow, A. Stolcke, J. Droppo, and R. Maas, “wav2vec-C: A Self- Supervised Model for Speech Representation Learning,” inInter- speech 2021, 2021, pp. 711–715
2021
-
[9]
XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Conneau, and M. Auli, “XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,” inInterspeech 2022, 2022, pp. 2278–2282
2022
-
[10]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
2021
-
[11]
W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,
Y .-A. Chung, Y . Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang, and Y . Wu, “W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 244–250
2021
-
[12]
Self-supervised learning with random-projection quantizer for speech recogni- tion,
C.-C. Chiu, J. Qin, Y . Zhang, J. Yu, and Y . Wu, “Self-supervised learning with random-projection quantizer for speech recogni- tion,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 3915–3924
2022
-
[13]
Open im- plementation and study of best-rq for speech processing,
R. Whetten, T. Parcollet, M. Dinarelli, and Y . Est `eve, “Open im- plementation and study of best-rq for speech processing,”2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), pp. 460–464, 2024
2024
-
[14]
Open-source conversational ai with speechbrain 1.0,
M. Ravanelli, T. Parcollet, A. Moumen, S. De Langen, C. Sub- akan, P. Plantinga, Y . Wang, P. Mousavi, L. Della Libera, A. Plou- jnikovet al., “Open-source conversational ai with speechbrain 1.0,”Journal of Machine Learning Research, vol. 25, no. 333, pp. 1–11, 2024
2024
-
[15]
WeNet 2.0: More Productive End- to-End Speech Recognition Toolkit,
B. Zhang, D. Wu, Z. Peng, X. Song, Z. Yao, H. Lv, L. Xie, C. Yang, F. Pan, and J. Niu, “WeNet 2.0: More Productive End- to-End Speech Recognition Toolkit,” inInterspeech 2022, 2022, pp. 1661–1665
2022
-
[16]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[17]
Nest: Self- supervised fast conformer as all-purpose seasoning to speech pro- cessing tasks,
H. Huang, T. Park, K. Dhawan, I. Medennikov, K. C. Puvvada, N. R. Koluguri, W. Wang, J. Balam, and B. Ginsburg, “Nest: Self- supervised fast conformer as all-purpose seasoning to speech pro- cessing tasks,” inICASSP 2025-2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[18]
Fast conformer with linearly scalable attention for efficient speech recognition,
D. Rekesh, N. R. Koluguri, S. Kriman, S. Majumdar, V . Noroozi, H. Huang, O. Hrinchuk, K. Puvvada, A. Kumar, J. Balamet al., “Fast conformer with linearly scalable attention for efficient speech recognition,” in2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[19]
MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification,
Y . Zhang, Z. Lv, H. Wu, S. Zhang, P. Hu, Z. Wu, H. yi Lee, and H. Meng, “MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification,” inInterspeech 2022, 2022, pp. 306–310
2022
-
[20]
Squeezeformer: an efficient transformer for automatic speech recognition,
S. Kim, A. Gholami, A. Shaw, N. Lee, K. Mangalam, J. Malik, M. W. Mahoney, and K. Keutzer, “Squeezeformer: an efficient transformer for automatic speech recognition,” inProceedings of the 36th International Conference on Neural Information Pro- cessing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[21]
Conformer-based speech recognition on extreme edge-computing devices,
M. Xu, A. Jin, S. Wang, M. Su, T. Ng, H. Mason, S. Han, Z. Lei, Y . Deng, Z. Huang, and M. Krishnamoorthy, “Conformer-based speech recognition on extreme edge-computing devices,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), Y . ...
2024
-
[22]
An improvement to conformer-based model for high-accuracy speech feature extraction and learning,
M. Liu and Y . Wei, “An improvement to conformer-based model for high-accuracy speech feature extraction and learning,” Entropy, vol. 24, no. 7, 2022. [Online]. Available: https: //www.mdpi.com/1099-4300/24/7/866
2022
-
[23]
Vietnamese end-to-end speech recognition using wav2vec 2.0,
T. B. Nguyen, “Vietnamese end-to-end speech recognition using wav2vec 2.0,” 09 2021. [Online]. Available: https: //github.com/vietai/ASR
2021
-
[24]
Vi- etASR: Achieving Industry-level Vietnamese ASR with 50-hour labeled data and Large-Scale Speech Pretraining,
J. Zhuo, Y . Yang, Y . Shao, Y . Xu, D. Yu, K. Yu, and X. Chen, “Vi- etASR: Achieving Industry-level Vietnamese ASR with 50-hour labeled data and Large-Scale Speech Pretraining,” inInterspeech 2025, 2025, pp. 1163–1167
2025
-
[25]
Chunkformer: Masked chunking conformer for long-form speech transcription,
K. Le, T. V . Ho, D. Tran, and D. T. Chau, “Chunkformer: Masked chunking conformer for long-form speech transcription,” inICASSP 2025-2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[26]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Interspeech 2020, 2020, pp. 5036–5040
2020
-
[27]
BERT: Pre- training of deep bidirectional transformers for language under- standing,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language under- standing,” inNAACL-HLT, 2019, pp. 4171–4186
2019
-
[28]
Pushing the limits of semi-supervised learning for automatic speech recognition,
Y . Zhang, J. Qin, D. S. Park, W. Han, C.-C. Chiu, R. Pang, Q. V . Le, and Y . Wu, “Pushing the limits of semi-supervised learning for automatic speech recognition,”arXiv preprint arXiv:2010.10504, 2020
arXiv 2010
-
[29]
Lib- rispeech: an ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an ASR corpus based on public domain audio books,” inProc. Interspeech 2015, 2015, pp. 520–524
2015
-
[30]
GigaSpeech 2: An evolving, large-scale and multi-domain ASR corpus for low-resource languages with automated crawling, transcription and refinement,
Y . Yang, Z. Song, J. Zhuo, M. Cui, J. Li, B. Yang, Y . Du, Z. Ma, X. Liu, Z. Wang, K. Li, S. Fan, K. Yu, W.-Q. Zhang, G. Chen, and X. Chen, “GigaSpeech 2: An evolving, large-scale and multi-domain ASR corpus for low-resource languages with automated crawling, transcription and refinement,” inProceedings of the 63rd Annual Meeting of the Association for C...
2025
-
[31]
MSR- 86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research,
S. Li, Y . You, X. Wang, Z. Tian, K. Ding, and G. Wan, “MSR- 86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research,” inInter- speech 2024, 2024, pp. 1245–1249
2024
-
[32]
ECAPA- TDNN: emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,” inInterspeech 2020, H. Meng, B. Xu, and T. F. Zheng, Eds. ISCA, 2020, pp. 3830– 3834
2020
-
[33]
But system description to voxceleb speaker recognition chal- lenge 2019,
H. Zeinali, S. Wang, A. Silnova, P. Mat ˇejka, and O. Plchot, “But system description to voxceleb speaker recognition chal- lenge 2019,” inProceedings of The VoxCeleb Challange Work- shop 2019, Graz, 2019, pp. 1–4
2019
-
[34]
PhoWhisper: Auto- matic Speech Recognition for Vietnamese,
T.-T. Le, L. T. Nguyen, and D. Q. Nguyen, “PhoWhisper: Auto- matic Speech Recognition for Vietnamese,” inProceedings of the ICLR 2024 Tiny Papers track, 2024
2024
-
[35]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[36]
A robust pitch-fusion model for speech emotion recognition in tonal languages,
P. V . Thanh, N. T. T. Huyen, P. N. Quan, and N. T. T. Trang, “A robust pitch-fusion model for speech emotion recognition in tonal languages,” inICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 12 386–12 390
2024
-
[37]
Multi-dialect Vietnamese: Task, dataset, baseline models and challenges,
N. V . Dinh, T. C. Dang, L. Thanh Nguyen, and K. V . Nguyen, “Multi-dialect Vietnamese: Task, dataset, baseline models and challenges,” inProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Associ- ation for Computational Linguistics, Nov. 2024, pp....
2024
-
[38]
V oxvietnam: a large-scale multi-genre dataset for viet- namese speaker recognition,
H. L. Vu, P. T. Dat, P. T. Nhi, N. S. Hao, and N. T. T. Trang, “V oxvietnam: a large-scale multi-genre dataset for viet- namese speaker recognition,” inICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[39]
Musan: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
Pith/arXiv arXiv 2015
-
[40]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 5220–5224
2017
-
[41]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2019, pp. 4690–4699
2019
-
[42]
Attentive Statistics Pooling for Deep Speaker Embedding,
K. Okabe, T. Koshinaka, and K. Shinoda, “Attentive Statistics Pooling for Deep Speaker Embedding,” inInterspeech 2018, 2018, pp. 2252–2256
2018
-
[43]
Wespeaker: A research and production oriented speaker embedding learning toolkit,
H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y . Deng, and Y . Qian, “Wespeaker: A research and production oriented speaker embedding learning toolkit,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.