UniVocal: Unified Speech-Singing Code-Switching Synthesis
Pith reviewed 2026-06-28 13:15 UTC · model grok-4.3
The pith
UniVocal lets text semantics alone trigger speech-to-singing switches in a single model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
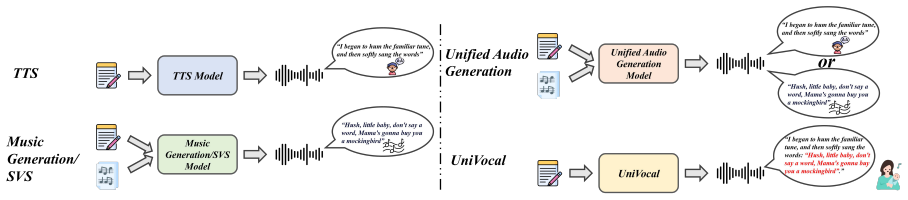
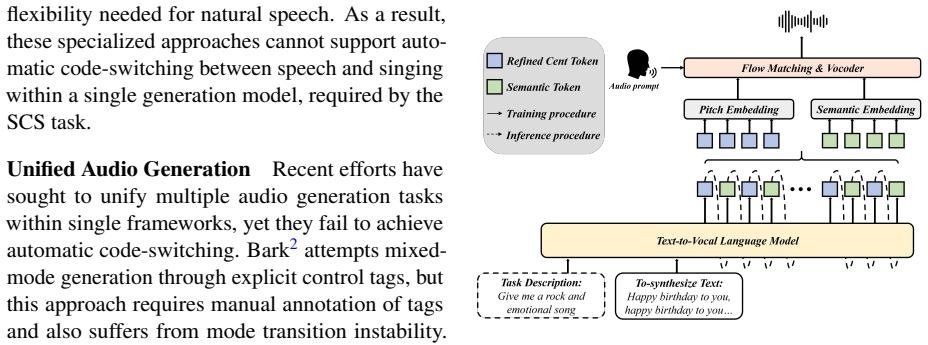
UniVocal implicitly infers vocal modes solely from text context to pioneer Speech-Singing Code-Switching (SCS) Synthesis, a task where transitions are autonomously driven by textual semantics. It employs a data-efficient two-stage curriculum learning strategy that progressively trains a competitive TTS system to acquire the desired SCS capability, supported by a scalable pipeline that synthesizes diverse yet natural code-switching data and by refined cent tokens plus Chain-of-Thought generation for prosody planning.
What carries the argument
Two-stage curriculum learning on synthesized speech-singing code-switching data that trains implicit mode inference without explicit tags.
If this is right
- SCS outputs can be produced without mode-control tags at inference time.
- The same model maintains competitive performance on pure speech and pure singing tasks.
- Refined cent tokens and CoT planning improve both empathetic speech and singing melody.
- SCSBench provides a standardized way to measure mixed vocal-mode quality.
Where Pith is reading between the lines
- The data-synthesis pipeline could be reused to create training sets for other low-resource vocal-mode mixtures such as emotion or accent switches.
- Removing the need for explicit tags may simplify deployment in dialogue systems that mix narration and song.
- If the implicit inference generalizes, similar curriculum methods might apply to other continuous control signals like volume or timbre.
Load-bearing premise
The synthesized code-switching data must be semantically and acoustically natural enough for the curriculum to teach the model to switch modes from text alone.
What would settle it
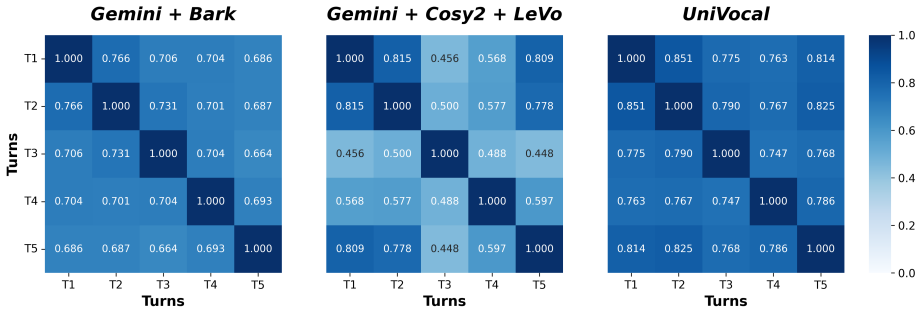
A blind listening test on SCSBench where human raters find no statistical difference in transition naturalness between UniVocal outputs and human references, or where regular speech and singing quality falls below current baselines.
Figures
read the original abstract
We propose UniVocal, a unified framework that implicitly infers vocal modes from text context to pioneer Speech-Singing Code-Switching (SCS) Synthesis - a task where transitions are autonomously driven by textual semantics, akin to seamless human language blending. Unlike single-mode generation or systems relying on switching-control tags, our proposed UniVocal implicitly infers vocal modes solely from text context. To achieve this, we employ a data-efficient two-stage curriculum learning strategy that progressively trains a competitive TTS system to acquire the desired SCS capability. Addressing data scarcity, we introduce a scalable pipeline to synthesize diverse code-switching data that is both semantically and acoustically natural, alongside a new multi-scenario benchmark, SCSBench. To address limitations of semantic tokenizers in capturing acoustic details, we also introduce refined cent token and Chain-of-Thought (CoT) generation for planning prosody before content generation, effectively enhancing empathetic speech generation and singing melody. Experimental results demonstrate that UniVocal achieves state-of-the-art performance on SCSBench while maintaining competitive performance on regular speech and singing tasks. Audio samples are available at https://project-univocal-demo.github.io/demo/. The code and dataset are released at https://github.com/FunAudioLLM/FunResearch/tree/main/UniVocal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniVocal, a unified TTS framework for Speech-Singing Code-Switching (SCS) synthesis. It claims to implicitly infer vocal modes (speech vs. singing) solely from text context without explicit tags, using a two-stage curriculum on data from a new scalable synthesis pipeline, refined cent tokens, and Chain-of-Thought prosody planning. A new benchmark SCSBench is introduced, with claims of SOTA performance on it and competitive results on standard speech/singing tasks; code and dataset are released.
Significance. If the core claims hold, the work would advance unified audio generation by demonstrating tag-free, semantically driven mode switching between speech and singing. The data-efficient curriculum strategy and open release of the pipeline, benchmark, and models would provide reusable resources for the speech synthesis community.
major comments (2)
- [Abstract / Data Synthesis Pipeline] The load-bearing assumption that the scalable synthesis pipeline produces semantically and acoustically natural SCS examples (sufficient for the curriculum to train true text-only mode inference rather than artifact exploitation) is stated in the abstract but lacks any quantitative validation such as human naturalness ratings, acoustic continuity metrics, or ablation on transition artifacts in the data generation description.
- [Experiments] The SOTA claim on SCSBench and competitive performance on regular tasks are asserted without any reported metrics, baselines, error bars, or statistical tests in the provided abstract; the experimental section must supply these to substantiate that performance does not reduce to the author-defined benchmark construction.
minor comments (2)
- [Method] The abstract mentions 'refined cent token and Chain-of-Thought (CoT) generation' but does not define the token vocabulary or CoT prompt structure; add a short notation table or equation in §3.
- [Abstract] Audio demo link and GitHub release are provided, which is good for reproducibility; ensure the released dataset includes the exact synthesis prompts and filtering criteria used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / Data Synthesis Pipeline] The load-bearing assumption that the scalable synthesis pipeline produces semantically and acoustically natural SCS examples (sufficient for the curriculum to train true text-only mode inference rather than artifact exploitation) is stated in the abstract but lacks any quantitative validation such as human naturalness ratings, acoustic continuity metrics, or ablation on transition artifacts in the data generation description.
Authors: We agree that the manuscript would benefit from explicit quantitative validation of the synthesis pipeline. The current version describes the pipeline as producing semantically and acoustically natural data but does not report human ratings or continuity metrics. In the revision, we will add a dedicated subsection with human naturalness evaluations (MOS scores) on synthesized SCS examples, acoustic continuity metrics across transitions, and an ablation study on transition artifacts to confirm the data supports text-only mode inference rather than artifact exploitation. revision: yes
-
Referee: [Experiments] The SOTA claim on SCSBench and competitive performance on regular tasks are asserted without any reported metrics, baselines, error bars, or statistical tests in the provided abstract; the experimental section must supply these to substantiate that performance does not reduce to the author-defined benchmark construction.
Authors: The full experimental section already reports quantitative metrics, baselines, and comparisons on SCSBench as well as standard speech and singing tasks. However, we acknowledge that the abstract lacks specific numbers, error bars, or statistical details. We will revise the abstract to include key performance metrics (e.g., objective scores and subjective ratings), mention of baselines, and note on statistical significance where applicable, ensuring the claims are substantiated without relying solely on the benchmark construction. revision: yes
Circularity Check
No significant circularity; empirical system with independent evaluation
full rationale
The paper describes an empirical TTS framework using a data synthesis pipeline and two-stage curriculum learning, evaluated on a newly introduced benchmark (SCSBench) and existing tasks. No equations, derivations, or mathematical claims are present in the provided text. Performance results are experimental outcomes rather than quantities that reduce to fitted parameters or self-definitions by construction. Self-citations, if any, are not load-bearing for a central derivation. The work is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[4]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D \'e fossez. 2023. Simple and controllable music generation. Advances in Neural Information Processing Systems, 36:47704--47720
2023
-
[6]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, and 1 others. 2024 a . Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, and 1 others. 2024 b . Cosyvoice 2: Scalable streaming speech synthesis with large language models. arXiv preprint arXiv:2412.10117
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Chitralekha Gupta, Haizhou Li, and Ye Wang. 2017. Perceptual evaluation of singing quality. In Proc. APSIPA, pages 577--586. IEEE
2017
-
[9]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29:3451--3460
2021
-
[10]
Lin Huang, Chitralekha Gupta, and Haizhou Li. 2020. Spectral features and pitch histogram for automatic singing quality evaluation with CRNN . In Proc. APSIPA, pages 492--499
2020
-
[13]
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural information processing systems, 33:17022--17033
2020
-
[15]
Yi Lei, Shan Yang, Xinsheng Wang, Qicong Xie, Jixun Yao, Lei Xie, and Dan Su. 2023. Unisyn: an end-to-end unified model for text-to-speech and singing voice synthesis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13025--13033
2023
-
[18]
Ziqian Ning, Shuai Wang, Yuepeng Jiang, Jixun Yao, Lei He, Shifeng Pan, Jie Ding, and Lei Xie. 2025. Drop the beat! freestyler for accompaniment conditioned rapping voice generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24966--24974
2025
-
[19]
Changhao Pan, Dongyu Yao, Yu Zhang, Wenxiang Guo, Jingyu Lu, Zhiyuan Zhu, and Zhou Zhao. 2025. Synthetic singers: A review of deep-learning-based singing voice synthesis approaches. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computationa...
2025
-
[20]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[23]
George Tzanetakis, Andrey Ermolinskyi, and Perry Cook. 2003. Pitch histograms in audio and symbolic music information retrieval. Journal of New Music Research, pages 143--152
2003
-
[34]
Yu Zhang, Changhao Pan, Wenxiang Guo, Ruiqi Li, Zhiyuan Zhu, Jialei Wang, Wenhao Xu, Jingyu Lu, Zhiqing Hong, Chuxin Wang, and 1 others. 2024 b . Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks. Advances in Neural Information Processing Systems, 37:1117--1140
2024
- [36]
-
[37]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Neural codec language models are zero-shot text to speech synthesizers , author=. arXiv preprint arXiv:2301.02111 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Song, Yakun and Chen, Zhuo and Wang, Xiaofei and Ma, Ziyang and Chen, Xie , booktitle=
-
[40]
arXiv preprint arXiv:2404.03204 , year=
Rall-e: Robust codec language modeling with chain-of-thought prompting for text-to-speech synthesis , author=. arXiv preprint arXiv:2404.03204 , year=
-
[41]
Vall-e 2: Neural codec language models are human parity zero- shot text to speech synthesizers,
Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers , author=. arXiv preprint arXiv:2406.05370 , year=
-
[42]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Seed-tts: A family of high-quality versatile speech generation models , author=. arXiv preprint arXiv:2406.02430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Cosyvoice:
Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others , journal=. Cosyvoice:
-
[44]
Cosyvoice 2:
Du, Zhihao and Wang, Yuxuan and Chen, Qian and Shi, Xian and Lv, Xiang and Zhao, Tianyu and Gao, Zhifu and Yang, Yexin and Gao, Changfeng and Wang, Hui and others , journal=. Cosyvoice 2:
-
[45]
FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications , author=. arXiv preprint arXiv:2409.03283 , year=
-
[46]
Zhou, Siyi and Zhou, Yiquan and He, Yi and Zhou, Xun and Wang, Jinchao and Deng, Wei and Shu, Jingchen , journal=
-
[47]
arXiv preprint arXiv:2407.02049 , year=
Accompanied singing voice synthesis with fully text-controlled melody , author=. arXiv preprint arXiv:2407.02049 , year=
-
[48]
arXiv preprint arXiv:2502.13128 , year=
Songgen: A single stage auto-regressive transformer for text-to-song generation , author=. arXiv preprint arXiv:2502.13128 , year=
-
[49]
Advances in Neural Information Processing Systems , volume=
Songcreator: Lyrics-based universal song generation , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Seed-music: A unified framework for high quality and controlled music generation , author=. arXiv preprint arXiv:2409.09214 , year=
-
[51]
Yue: Scaling open foundation models for long-form music generation.arXiv preprint arXiv:2503.08638,
Yue: Scaling open foundation models for long-form music generation , author=. arXiv preprint arXiv:2503.08638 , year=
-
[52]
Analyzable chain-of-musical-thought prompting for high-fidelity music generation , author=. arXiv preprint arXiv:2503.19611 , year=
-
[53]
arXiv preprint arXiv:2506.07520 , year=
LeVo: High-Quality Song Generation with Multi-Preference Alignment , author=. arXiv preprint arXiv:2506.07520 , year=
-
[54]
arXiv preprint arXiv:2211.02903 , year=
Visinger 2: High-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer , author=. arXiv preprint arXiv:2211.02903 , year=
-
[55]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Sifisinger: A high-fidelity end-to-end singing voice synthesizer based on source-filter model , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[56]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Muse-svs: Multi-singer emotional singing voice synthesizer that controls emotional intensity , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2023 , publisher=
2023
-
[57]
arXiv preprint arXiv:2409.15977 , year=
Tcsinger: Zero-shot singing voice synthesis with style transfer and multi-level style control , author=. arXiv preprint arXiv:2409.15977 , year=
-
[58]
arXiv preprint arXiv:2505.14910 , year=
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis , author=. arXiv preprint arXiv:2505.14910 , year=
-
[59]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[60]
Speechgpt: Empow- ering large language models with intrinsic cross-modal conversational abilities
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities , author=. arXiv preprint arXiv:2305.11000 , year=
-
[61]
arXiv preprint arXiv:2310.00704 , year=
Uniaudio: An audio foundation model toward universal audio generation , author=. arXiv preprint arXiv:2310.00704 , year=
-
[62]
IEEE/ACM transactions on audio, speech, and language processing , volume=
Audiolm: a language modeling approach to audio generation , author=. IEEE/ACM transactions on audio, speech, and language processing , volume=. 2023 , publisher=
2023
-
[63]
Transactions of the Association for Computational Linguistics , volume=
Speak, read and prompt: High-fidelity text-to-speech with minimal supervision , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[64]
VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
Vall-e r: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment , author=. arXiv preprint arXiv:2406.07855 , year=
-
[65]
arXiv preprint arXiv:2502.05512 , year=
Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system , author=. arXiv preprint arXiv:2502.05512 , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Simple and controllable music generation , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
High Fidelity Neural Audio Compression
High fidelity neural audio compression , author=. arXiv preprint arXiv:2210.13438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
arXiv preprint arXiv:2403.11780 , year=
Prompt-singer: Controllable singing-voice-synthesis with natural language prompt , author=. arXiv preprint arXiv:2403.11780 , year=
-
[69]
arXiv preprint arXiv:2305.19269 , year=
Make-a-voice: Unified voice synthesis with discrete representation , author=. arXiv preprint arXiv:2305.19269 , year=
-
[70]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Clap learning audio concepts from natural language supervision , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[71]
arXiv preprint arXiv:2508.16332 , year=
Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning , author=. arXiv preprint arXiv:2508.16332 , year=
-
[72]
Spectral features and pitch histogram for automatic singing quality evaluation with
Huang, Lin and Gupta, Chitralekha and Li, Haizhou , booktitle=. Spectral features and pitch histogram for automatic singing quality evaluation with
-
[73]
Journal of New Music Research , pages=
Pitch histograms in audio and symbolic music information retrieval , author=. Journal of New Music Research , pages=
-
[74]
Perceptual evaluation of singing quality , author=. Proc. APSIPA , pages=. 2017 , organization=
2017
-
[75]
Advances in neural information processing systems , volume=
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis , author=. Advances in neural information processing systems , volume=
-
[76]
arXiv preprint arXiv:2308.05725 , year=
Expresso: A benchmark and analysis of discrete expressive speech resynthesis , author=. arXiv preprint arXiv:2308.05725 , year=
-
[77]
arXiv preprint arXiv:2504.12867 , year=
Emovoice: Llm-based emotional text-to-speech model with freestyle text prompting , author=. arXiv preprint arXiv:2504.12867 , year=
-
[78]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[79]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Drop the beat! freestyler for accompaniment conditioned rapping voice generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[80]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
LibriTTS: A corpus derived from LibriSpeech for text-to-speech , author=. arXiv preprint arXiv:1904.02882 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[81]
Advances in Neural Information Processing Systems , volume=
Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[82]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Unisyn: an end-to-end unified model for text-to-speech and singing voice synthesis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[83]
IEEE/ACM transactions on audio, speech, and language processing , volume=
Hubert: Self-supervised speech representation learning by masked prediction of hidden units , author=. IEEE/ACM transactions on audio, speech, and language processing , volume=. 2021 , publisher=
2021
-
[84]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Soundstream: An end-to-end neural audio codec , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2021 , publisher=
2021
-
[85]
Advances in Neural Information Processing Systems , volume=
High-fidelity audio compression with improved rvqgan , author=. Advances in Neural Information Processing Systems , volume=
-
[86]
arXiv preprint arXiv:2109.03264 , year=
Text-free prosody-aware generative spoken language modeling , author=. arXiv preprint arXiv:2109.03264 , year=
-
[87]
arXiv preprint arXiv:2005.07884 , year=
Improved prosody from learned f0 codebook representations for vq-vae speech waveform reconstruction , author=. arXiv preprint arXiv:2005.07884 , year=
-
[88]
2015 , publisher=
Fundamentals of music processing: Audio, analysis, algorithms, applications , author=. 2015 , publisher=
2015
-
[89]
arXiv preprint arXiv:2305.12838 , year=
An enhanced res2net with local and global feature fusion for speaker verification , author=. arXiv preprint arXiv:2305.12838 , year=
-
[90]
arXiv preprint arXiv:2204.02152 , year=
Utmos: Utokyo-sarulab system for voicemos challenge 2022 , author=. arXiv preprint arXiv:2204.02152 , year=
-
[91]
arXiv preprint arXiv:2501.01108 , year=
Muq: Self-supervised music representation learning with mel residual vector quantization , author=. arXiv preprint arXiv:2501.01108 , year=
-
[92]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound , author=. arXiv preprint arXiv:2502.05139 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[93]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Fr 'echet audio distance: A metric for evaluating music enhancement algorithms , author=. arXiv preprint arXiv:1812.08466 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[94]
arXiv preprint arXiv:2506.00885 , year=
CoVoMix2: Advancing Zero-Shot Dialogue Generation with Fully Non-Autoregressive Flow Matching , author=. arXiv preprint arXiv:2506.00885 , year=
-
[95]
Synthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[96]
arXiv preprint arXiv:2411.13577 , year=
Wavchat: A survey of spoken dialogue models , author=. arXiv preprint arXiv:2411.13577 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.