Joint Learning of Covariance Estimation and White Noise Gain for Robust MVDR Beamforming
Pith reviewed 2026-06-25 23:11 UTC · model grok-4.3
The pith
A neural network jointly learns a noise mask and frequency-dependent WNG threshold to make MVDR beamforming adapt to unknown conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that jointly training a network to output a time-frequency noise mask and a frequency-dependent WNG threshold, then passing these outputs through a differentiable robust MVDR layer, produces an adaptive beamformer whose performance exceeds that of manually tuned fixed-WNG baselines under unknown acoustic conditions.
What carries the argument
The joint neural network that outputs a time-frequency noise mask and a frequency-dependent WNG threshold, integrated with a differentiable robust MVDR beamformer layer that permits gradient-based end-to-end optimization.
If this is right
- The beamformer can adjust its robustness-directivity trade-off dynamically across frequencies and time.
- End-to-end training removes the need for separate manual tuning of the WNG threshold.
- Performance remains stable when acoustic conditions deviate from those seen during conventional design.
- Covariance estimates derived from the predicted noise mask become part of the same optimization loop as the WNG constraint.
Where Pith is reading between the lines
- The same joint-prediction structure could be applied to other linearly constrained beamformers that use similar robustness parameters.
- One could measure whether the network's learned WNG values track physical array mismatch levels in controlled calibration experiments.
- Real-time implementations would need to verify that the added network computation does not offset the latency savings from avoiding repeated manual recalibration.
Load-bearing premise
That a differentiable implementation of the robust MVDR beamformer permits stable end-to-end optimization yielding consistent gains over fixed-WNG baselines under unknown acoustic conditions.
What would settle it
Training the model and testing it on real recordings that contain measured microphone self-noise and array mismatches; the claim fails if the learned adaptive version shows no improvement over fixed-WNG baselines on standard speech quality and intelligibility metrics.
Figures
read the original abstract
The minimum variance distortionless response (MVDR) beamformer is widely used for multichannel speech enhancement due to strong noise suppression while preserving target signals. In practice, its performance is sensitive to microphone self-noise and array mismatches. Existing approaches typically rely on fixed, manually tuned WNG thresholds or diagonal loading, leading to suboptimal performance under unknown or time-varying acoustic conditions. This paper proposes a data-driven MVDR framework that adaptively estimates the WNG constraint using a deep neural network. The network jointly predicts a time-frequency noise mask for covariance estimation and a frequency-dependent WNG threshold, enabling dynamic robustness-directivity control. A differentiable robust MVDR layer is integrated into the framework, allowing end-to-end optimization. Experiments demonstrate consistent improvements in speech quality and intelligibility over conventional fixed-WNG MVDR methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a data-driven MVDR beamforming framework in which a neural network jointly predicts a time-frequency noise mask (for covariance estimation) and a frequency-dependent WNG threshold. A differentiable robust MVDR layer is integrated to enable end-to-end optimization, with the goal of providing dynamic robustness-directivity control under unknown acoustic conditions. The abstract claims that experiments show consistent improvements in speech quality and intelligibility over conventional fixed-WNG MVDR methods.
Significance. If the results hold under proper validation, the approach would offer a principled way to learn the WNG constraint rather than relying on manual tuning or diagonal loading, potentially improving MVDR performance in time-varying environments. The use of a differentiable layer is a methodological strength that supports reproducible optimization.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvements' is stated without any reported metrics, baselines, datasets, statistical tests, or experimental details, so the soundness of the joint-learning contribution cannot be evaluated from the provided text.
- [Method (assumed from abstract)] The manuscript provides no description of the differentiable robust MVDR layer implementation, loss function, or training procedure, leaving the claim that end-to-end optimization is stable and yields gains unverified.
minor comments (1)
- [Abstract] WNG is used without an initial expansion of 'white noise gain'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements' is stated without any reported metrics, baselines, datasets, statistical tests, or experimental details, so the soundness of the joint-learning contribution cannot be evaluated from the provided text.
Authors: We agree that the abstract is too concise and does not provide sufficient experimental context to support the claims. In the revised manuscript we will expand the abstract to report key quantitative results (e.g., average PESQ and STOI gains), the evaluation datasets, the primary baselines (fixed-WNG MVDR and diagonal loading), and note that improvements were statistically significant (paired t-tests, p<0.01). The detailed experimental protocol remains in Section 4. revision: yes
-
Referee: [Method (assumed from abstract)] The manuscript provides no description of the differentiable robust MVDR layer implementation, loss function, or training procedure, leaving the claim that end-to-end optimization is stable and yields gains unverified.
Authors: The full manuscript contains these elements in Sections 3.2 (differentiable robust MVDR layer with closed-form solution and gradient derivation), 3.3 (composite loss combining mask MSE and WNG regularization), and 4.1 (training schedule, optimizer, and stability measures). However, we acknowledge that the current presentation may be insufficiently explicit. We will add a concise implementation overview, pseudocode for the robust MVDR layer, and explicit loss/training details to Section 3 in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present a standard data-driven neural network extension of MVDR beamforming: a DNN jointly predicts a TF noise mask (for covariance) and frequency-dependent WNG threshold, with a differentiable robust MVDR layer enabling end-to-end training. No derivation, equation, or claim reduces a 'prediction' to its own fitted inputs by construction, nor relies on self-citation load-bearing uniqueness theorems or ansatz smuggling. The central claim rests on empirical gains from training, which is externally falsifiable via standard benchmarks and does not match any enumerated circularity pattern. Full text would be needed for deeper inspection, but nothing supplied indicates the result is forced by definition or self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MVDR performance is sensitive to microphone self-noise and array mismatches
- domain assumption A differentiable robust MVDR layer enables end-to-end optimization
Reference graph
Works this paper leans on
-
[1]
Among existing approaches, the minimum variance distortionless response (MVDR) beamformer is par- ticularly attractive [6, 7, 8, 9]
Introduction Microphone array beamforming is a core technique in multi- channel speech processing, with applications including voice capture, spatial audio recording, and environmental percep- tion [1, 2, 3, 4, 5]. Among existing approaches, the minimum variance distortionless response (MVDR) beamformer is par- ticularly attractive [6, 7, 8, 9]. The MVDR ...
-
[2]
Signal Model and Problem Formulation Consider a microphone array consisting ofMsensors in a acoustic environment , capturing a desired source propagating arXiv:2606.24137v1 [eess.AS] 23 Jun 2026 from directionθ s, the observation signal vector of lengthMin the short-time Fourier transform (STFT) domain can be written as y(k) = Y1(n, k)Y 2(n, k)· · ·Y M(n,...
Pith/arXiv arXiv 2026
-
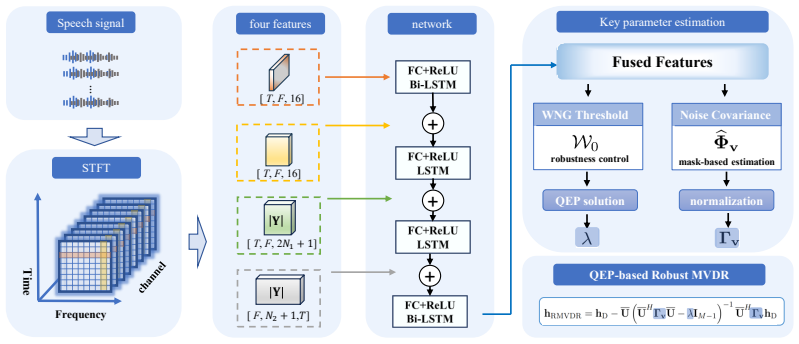
[3]
Data-Driven Robustness Control for MVDR Beamforming 3.1. Robust MVDR with Learnable WNG Constraints To overcome the limitations of fixed robustness control and heuristic parameter tuning, a data-driven MVDR beamform- ing framework is proposed based on a dual-branch neural net- work architecture. The two branches are designed to ad- dress complementary mec...
-
[4]
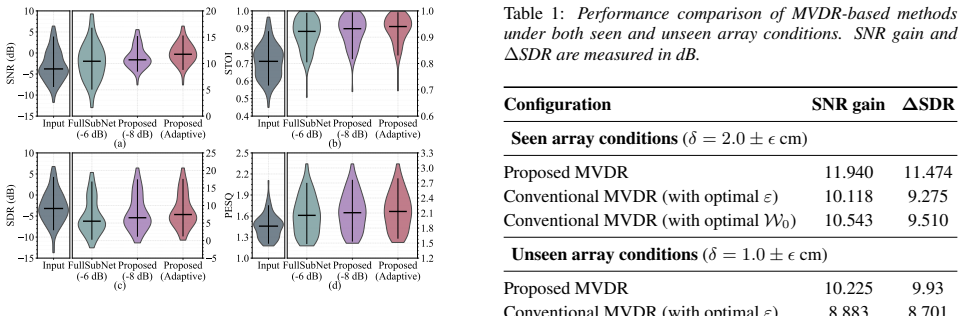
Dataset and Acoustic Experimental Setup The VCTK dataset is used as the speech source, which is sam- pled at16kHz and from multiple speakers
Experimental Results 4.1. Dataset and Acoustic Experimental Setup The VCTK dataset is used as the speech source, which is sam- pled at16kHz and from multiple speakers. Each target speech segment is truncated to a fixed duration of3s. To generate mul- tichannel noisy signals, an8-microphone ULA with an inter- microphone spacing of2cm is employed. The targe...
-
[5]
Conclusion This work proposed a data-driven method for estimating the WNG constraint in MVDR beamforming. Unlike conven- tional approaches that use a fixed WNG threshold, the proposed framework employs a deep neural network to jointly predict the optimal WNG value and the noise presence mask. By doing so, the beamformer can dynamically adjust its robustne...
-
[6]
The numerical calculations in this paper have been done on the supercomput- ing system in the Supercomputing Center of Wuhan University
Acknowledgments This work was supported by the National Natural Science Foun- dation (NSFC) of China under Grant 62471340. The numerical calculations in this paper have been done on the supercomput- ing system in the Supercomputing Center of Wuhan University
-
[7]
Generative AI Use Disclosure ChatGPT was used only for language polishing and grammar checking
-
[8]
Brandstein and D
M. Brandstein and D. Ward,Microphone Arrays: Signal Process- ing Techniques and Applications. Springer, 2001
2001
-
[9]
Benesty, I
J. Benesty, I. Cohen, and J. Chen,Fundamentals of Signal En- hancement and Array Signal Processing. Singapore: Wiley- IEEE Press., 2018
2018
-
[10]
Design of fully steerable differential beamformers with linear superarrays,
X. Luo, J. Jin, G. Huang, J. Chen, and J. Benesty, “Design of fully steerable differential beamformers with linear superarrays,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 32, pp. 3076–3089, 2024
2024
-
[11]
Kronecker prod- uct multichannel linear filtering for adaptive weighted prediction error-based speech dereverberation,
G. Huang, J. Benesty, I. Cohen, and J. Chen, “Kronecker prod- uct multichannel linear filtering for adaptive weighted prediction error-based speech dereverberation,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 1277–1289, 2022
2022
-
[12]
Explainable dnn- based beamformer with postfilter,
A. Cohen, D. Wong, J.-S. Lee, and S. Gannot, “Explainable dnn- based beamformer with postfilter,”IEEE Trans. Audio, Speech, Lang. Process., vol. 33, pp. 3070–3084, 2025
2025
-
[13]
Time-frequency-bin-wise linear combination of beamformers for distortionless signal en- hancement,
K. Yamaoka, N. Ono, and S. Makino, “Time-frequency-bin-wise linear combination of beamformers for distortionless signal en- hancement,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 29, pp. 3461–3475, Nov. 2021
2021
-
[14]
Unsupervised im- proved mvdr beamforming for sound enhancement,
J. Kealey, J. R. Hershey, and F. Grondin, “Unsupervised im- proved mvdr beamforming for sound enhancement,” inInter- speech, 2024, pp. 2175–2179
2024
-
[15]
Learning-based multi-channel speech presence probability esti- mation using a low-parameter model and integration with mvdr beamforming for multi-channel speech enhancement,
S. Tao, P. Mowlaee, J. R. Jensen, and M. G. Christensen, “Learning-based multi-channel speech presence probability esti- mation using a low-parameter model and integration with mvdr beamforming for multi-channel speech enhancement,” in2024 18th International Workshop on Acoustic Signal Enhancement (IWAENC). IEEE, 2024, pp. 100–104
2024
-
[16]
Diffusion-based dis- tributed multi-frame kalman filtering with speech distortionless constraint for speech enhancement,
Q. Zhao, R. Chang, Z. Chen, and F. Yin, “Diffusion-based dis- tributed multi-frame kalman filtering with speech distortionless constraint for speech enhancement,”IEEE Trans. Audio, Speech, Lang. Process., vol. 33, pp. 1063–1077, 2025
2025
-
[17]
Beamforming: A versatile approach to spatial filtering,
B. D. Van Veen and K. M. Buckley, “Beamforming: A versatile approach to spatial filtering,”IEEE ASSP Magazine, vol. 5, no. 2, pp. 4–24, 1988
1988
-
[18]
Pseudo-coherence-based MVDR beamformer for speech enhancement with ad hoc microphone arrays,
V . M. Tavakoli, J. R. Jensen, M. G. Christenseny, and J. Ben- esty, “Pseudo-coherence-based MVDR beamformer for speech enhancement with ad hoc microphone arrays,” inProc. IEEE ICASSP. IEEE, 2015, pp. 2659–2663
2015
-
[19]
New insights into the mvdr beamformer in room acous- tics,
E. A. P. Habets, J. Benesty, I. Cohen, S. Gannot, and J. Dmo- chowski, “New insights into the mvdr beamformer in room acous- tics,”IEEE Transactions on Audio, Speech and Language Pro- cessing, vol. 18, no. 1, pp. 158–170, 2010
2010
-
[20]
New designs on mvdr robust adaptive beamforming based on optimal steering vector es- timation,
Y . Huang, M. Zhou, and S. A. V orobyov, “New designs on mvdr robust adaptive beamforming based on optimal steering vector es- timation,”IEEE Trans. Signal Process., vol. 67, no. 14, pp. 3624– 3638, 2019
2019
-
[21]
A compact noise covariance matrix model for mvdr beamform- ing,
A. H. Moore, S. Hafezi, R. R. V os, P. A. Naylor, and M. Brookes, “A compact noise covariance matrix model for mvdr beamform- ing,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 2049–2061, Jun. 2022
2049
-
[22]
Regularized min- imum variance distortionless response-based cepstral features for robust continuous speech recognition,
M. J. Alam, P. Kenny, and D. O’Shaughnessy, “Regularized min- imum variance distortionless response-based cepstral features for robust continuous speech recognition,”Speech Communication, vol. 73, pp. 28–46, 2015
2015
-
[23]
Microphone array signal processing and deep learn- ing for speech enhancement: Combining model-based and data- driven approaches to parameter estimation and filtering,
R. H ¨eb-Umbach, T. Nakatani, M. Delcroix, C. Boeddeker, and T. Ochiai, “Microphone array signal processing and deep learn- ing for speech enhancement: Combining model-based and data- driven approaches to parameter estimation and filtering,”IEEE Signal Processing Magazine, vol. 41, no. 6, pp. 12–23, 2024
2024
-
[24]
Improved mvdr beamforming using single-channel mask prediction networks
H. Erdogan, J. R. Hershey, S. Watanabe, M. I. Mandel, and J. Le Roux, “Improved mvdr beamforming using single-channel mask prediction networks.” inInterspeech, 2016, pp. 1981–1985
2016
-
[25]
Neural network based spectral mask estimation for acoustic beamforming,
J. Heymann, L. Drude, and R. Haeb-Umbach, “Neural network based spectral mask estimation for acoustic beamforming,” in Proc. IEEE ICASSP, 2016, pp. 196–200
2016
-
[26]
Online mvdr beamformer based on complex gaus- sian mixture model with spatial prior for noise robust asr,
T. Higuchi, N. Ito, S. Araki, T. Yoshioka, M. Delcroix, and T. Nakatani, “Online mvdr beamformer based on complex gaus- sian mixture model with spatial prior for noise robust asr,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 4, pp. 780–793, 2017
2017
-
[27]
Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise,
T. Higuchi, N. Ito, T. Yoshioka, and T. Nakatani, “Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise,” inProc. IEEE ICASSP. IEEE, 2016, pp. 5210–5214
2016
-
[28]
Data-driven white noise gain constrained robust superdirective beamformer for speech enhancement,
H. Pei, G. Huang, J. Jin, J. Ma, Z. Wu, J. Chen, and J. Benesty, “Data-driven white noise gain constrained robust superdirective beamformer for speech enhancement,” inProc. IEEE ICASSP, 2025, pp. 1–5
2025
-
[29]
Robust adaptive beamform- ing,
H. Cox, R. Zeskind, and M. Owen, “Robust adaptive beamform- ing,”IEEE Trans. Acoust., Speech, Signal Process., vol. 35, pp. 1365–1376, Oct. 1987
1987
-
[30]
Benesty, J
J. Benesty, J. Chen, and Y . Huang,Microphone Array Signal Pro- cessing. Berlin, Germany: Springer-Verlag, 2008
2008
-
[31]
Worst-case-optimization robust- mvdr beamformer for stereo noise reduction in hearing aids,
W. Lobato and M. H. Costa, “Worst-case-optimization robust- mvdr beamformer for stereo noise reduction in hearing aids,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 28, pp. 2224–2237, 2020
2020
-
[32]
Sensitiv- ity analysis of mvdr and mpdr beamformers,
L. Ehrenberg, S. Gannot, A. Leshem, and E. Zehavi, “Sensitiv- ity analysis of mvdr and mpdr beamformers,” in2010 IEEE 26- th Convention of Electrical and Electronics Engineers in israel. IEEE, 2010, pp. 416–420
2010
-
[33]
On the robust- ness of the superdirective beamformer,
X. Chen, J. Benesty, G. Huang, and J. Chen, “On the robust- ness of the superdirective beamformer,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 29, pp. 838–849, 2021
2021
-
[34]
Benesty, G
J. Benesty, G. Huang, J. Chen, and N. Pan,Microphone Arrays. Berlin, Germany: Springer-Verlag, 2023, vol. 22
2023
-
[35]
Relationships be- tween adaptive minimum variance beamforming and optimal source localization,
K. Harmanci, J. Tabrikian, and J. L. Krolik, “Relationships be- tween adaptive minimum variance beamforming and optimal source localization,”IEEE Trans. Signal Process., vol. 48, no. 1, pp. 1–12, 2000
2000
-
[36]
Fundamental approaches to robust differential beamforming with high directivity factors,
G. Huang, J. Benesty, and J. Chen, “Fundamental approaches to robust differential beamforming with high directivity factors,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 3074–3088, 2022
2022
-
[37]
Performance study of the MVDR beamformer as a function of the source incidence angle,
C. Pan, J. Chen, and J. Benesty, “Performance study of the MVDR beamformer as a function of the source incidence angle,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 22, no. 1, pp. 67–79, 2014
2014
-
[38]
Microphone arrays,
G. W. Elko and J. Meyer, “Microphone arrays,” inSpringer Handbook of Speech Processing, J. Benesty, M. M. Sondhi, and Y . Huang, Eds. Berlin, Germany: Springer-Verlag, 2008, ch. 48, pp. 1021–1041
2008
-
[39]
McNet: Fuse multiple cues for multichannel speech enhancement,
Y . Yang, C. Quan, and X. Li, “McNet: Fuse multiple cues for multichannel speech enhancement,” inProc. IEEE ICASSP, 2023, pp. 1–5
2023
-
[40]
On the role of spatial, spectral, and temporal processing for DNN-based non- linear multi-channel speech enhancement,
K. Tesch, N.-H. Mohrmann, and T. Gerkmann, “On the role of spatial, spectral, and temporal processing for DNN-based non- linear multi-channel speech enhancement,” inInterspeech 2022, 2022, pp. 2908–2912
2022
-
[41]
Adam: a method for stochastic optimiza- tion,
D. P. Kingma and J. Ba, “Adam: a method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[42]
Performance measure- ment in blind audio source separation,
E. Vincent, R. Gribonval, and C. F ´evotte, “Performance measure- ment in blind audio source separation,”IEEE Transactions on Au- dio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462– 1469, 2006
2006
-
[43]
A short- time objective intelligibility measure for time-frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short- time objective intelligibility measure for time-frequency weighted noisy speech,” inProc. IEEE ICASSP, 2010, pp. 4214–4217
2010
-
[44]
Per- ceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per- ceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. IEEE ICASSP, vol. 2, 2001, pp. 749–752
2001
-
[45]
Fullsubnet: a full-band and sub-band fusion model for real-time single-channel speech enhancement,
X. Hao, X. Su, R. Horaud, and X. Li, “Fullsubnet: a full-band and sub-band fusion model for real-time single-channel speech enhancement,” inProc. IEEE ICASSP, 2021, pp. 6633–6637
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.