Balancing ASR and diarization in end-to-end LLMs for multi-talker speech recognition
Pith reviewed 2026-06-27 06:02 UTC · model grok-4.3
The pith
Four strategies let an end-to-end LLM handle multi-talker speech recognition after training on limited real-recorded data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
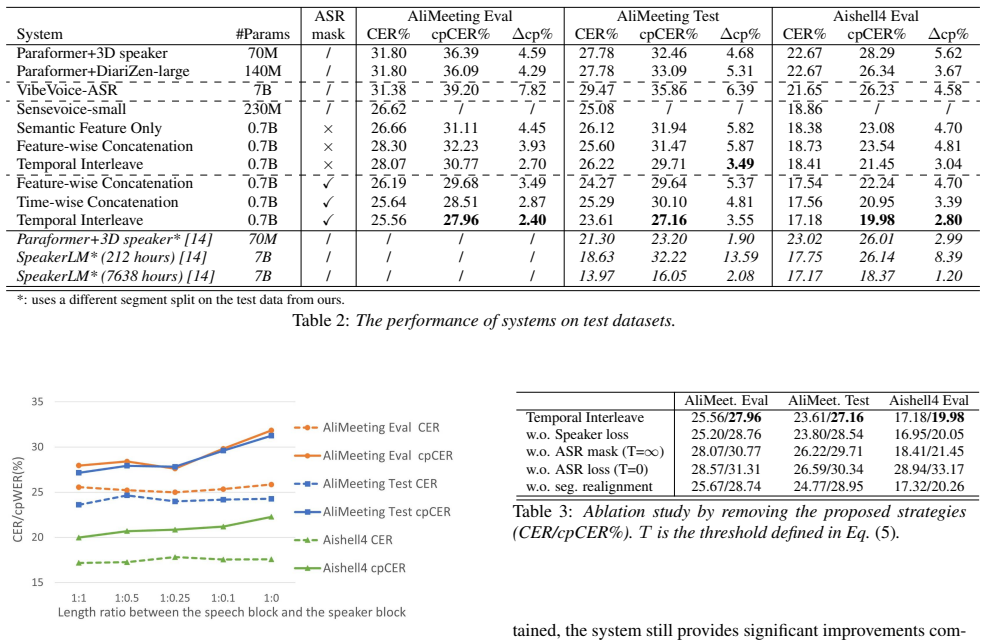
The central claim is that the four proposed strategies—a dual-encoder architecture, feature interleaving format, length-aware speaker ID loss, and adaptive threshold for ASR loss—balance ASR and diarization training in an LLM-based multi-talker system. This balance allows high speaker-attribution accuracy when only limited real-recorded data are available, producing relative improvements of 18 percent on the AliMeeting corpus and 24 percent on the Aishell4 corpus over open-source baselines.
What carries the argument
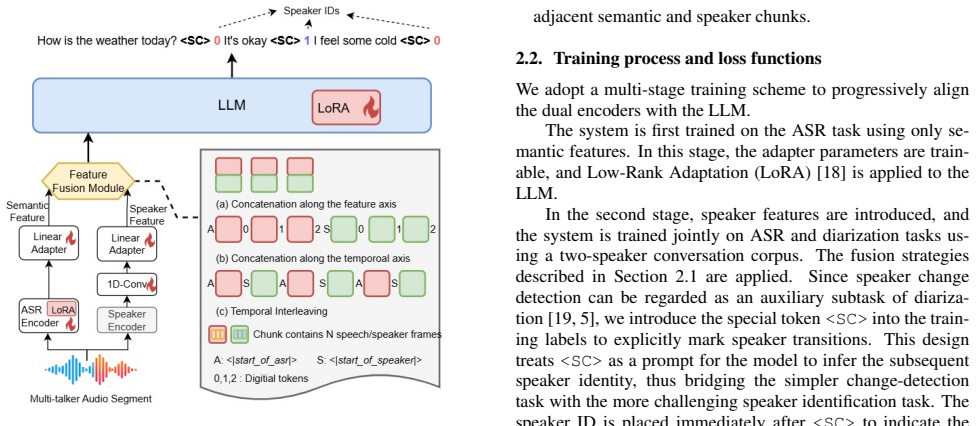
The dual-encoder architecture that extracts semantic and speaker features separately, combined with their interleaving as LLM input and the two task-specific loss adjustments.
If this is right
- The dual-encoder separates semantic content from speaker identity before the LLM sees the input.
- Feature interleaving lets the single LLM attend to both kinds of information in one forward pass.
- The length-aware speaker ID loss strengthens diarization without harming word recognition.
- The adaptive threshold on ASR loss reduces hallucinations that arise from overlapping speech.
- The resulting system exceeds open-source pipeline and LLM baselines on two standard multi-talker corpora.
Where Pith is reading between the lines
- The same loss-balancing tactics might reduce dependence on synthetic multi-talker data in other joint audio tasks.
- If the interleaving format works for two feature streams, it could be tested on additional modalities such as visual or textual context.
- Real-world deployments with only small collections of meeting recordings could become feasible sooner than data-hungry alternatives.
Load-bearing premise
The four strategies together are sufficient to keep ASR and diarization training in balance on limited real-recorded data while preserving speaker attribution accuracy.
What would settle it
Reproducing the system on the AliMeeting or Aishell4 test sets and finding no relative improvement, or a drop, in combined ASR and diarization metrics would show the strategies do not achieve the claimed balance.
Figures

read the original abstract
Multi-talker speech recognition is often addressed by combining automatic speech recognition (ASR) and speaker diarization in a pipeline system. Recently, LLM-based approaches have shown promise by jointly modeling semantic and speaker information, but they typically require large-scale multi-talker corpora that are costly to annotate. In this paper, we investigate how to efficiently train an LLM-based system with limited real-recorded data while maintaining high accuracy in speaker attribution. We propose several strategies: (1) a dual-encoder architecture to extract semantic and speaker features, (2) a feature interleaving format to merge these features as the inputs to the LLM, (3) a length-aware speaker ID loss to enhance diarization capability, and (4) an adaptive threshold strategy for ASR loss computation to mitigate hallucinations caused by speech overlaps. These strategies balance training between ASR and diarization tasks. Our system outperforms open-source baseline approaches, achieving relative improvements of 18% on the AliMeeting corpus and 24% on the Aishell4 corpus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes four strategies—a dual-encoder architecture, feature interleaving format, length-aware speaker ID loss, and adaptive threshold for ASR loss—to train an end-to-end LLM-based multi-talker ASR system on limited real-recorded data. It claims these balance ASR and diarization objectives while mitigating overlap-induced hallucinations, yielding relative WER improvements of 18% on AliMeeting and 24% on Aishell4 over open-source baselines.
Significance. If the empirical gains are shown to be robust and attributable to the proposed components, the work would be significant for practical multi-talker ASR, as it addresses the data-efficiency bottleneck that currently limits LLM-based joint modeling approaches. The explicit focus on balancing the two tasks via a heuristic threshold is a concrete contribution, though its generality remains to be verified.
major comments (3)
- [Experiments] Experiments section (results tables): No ablation is reported that removes only the adaptive threshold while keeping the dual-encoder, interleaving, and length-aware loss fixed. Without overlap-specific metrics (e.g., WER on overlap vs. non-overlap subsets) or this controlled ablation, it is impossible to confirm that the threshold drives the claimed mitigation of hallucinations or the 18%/24% gains, as opposed to the structural changes alone. This directly undermines the central claim that the four strategies together suffice.
- [Results] Results section: Relative improvements are stated without error bars, standard deviations across runs, or statistical significance tests against the baselines. Given that the abstract presents these numbers as the primary evidence, the absence of variability measures makes it impossible to judge whether the reported gains are reliable or could arise from training stochasticity.
- [§3.4] §3.4 (adaptive threshold description): The threshold is described as mitigating hallucinations from overlaps, yet the manuscript provides no quantitative analysis of how the threshold value is chosen or its sensitivity. If the threshold is a key load-bearing heuristic, its derivation or validation procedure should be shown explicitly rather than left as an empirical choice.
minor comments (2)
- [Abstract] The abstract and introduction refer to 'open-source baseline approaches' without naming the specific systems or their configurations in the main text; this should be clarified for reproducibility.
- [§3] Notation for the feature interleaving format and the length-aware speaker ID loss could be made more explicit (e.g., by defining the input tensor shapes) to aid readers implementing the dual-encoder.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help clarify the contributions of our proposed strategies. We address each major point below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results tables): No ablation is reported that removes only the adaptive threshold while keeping the dual-encoder, interleaving, and length-aware loss fixed. Without overlap-specific metrics (e.g., WER on overlap vs. non-overlap subsets) or this controlled ablation, it is impossible to confirm that the threshold drives the claimed mitigation of hallucinations or the 18%/24% gains, as opposed to the structural changes alone. This directly undermines the central claim that the four strategies together suffice.
Authors: We agree that a controlled ablation isolating the adaptive threshold is essential to attribute gains specifically to it rather than the architectural changes. In the revised version, we will add this ablation (training without the threshold while fixing the other three components) and report WER on overlap versus non-overlap subsets to directly demonstrate the threshold's role in reducing hallucinations. revision: yes
-
Referee: [Results] Results section: Relative improvements are stated without error bars, standard deviations across runs, or statistical significance tests against the baselines. Given that the abstract presents these numbers as the primary evidence, the absence of variability measures makes it impossible to judge whether the reported gains are reliable or could arise from training stochasticity.
Authors: We acknowledge that variability measures are needed to assess reliability. Due to the high computational cost of LLM training, only single runs were performed. In revision we will add multiple runs with different seeds where feasible and report standard deviations; otherwise we will explicitly note this limitation while highlighting consistency across the two evaluation corpora. revision: partial
-
Referee: [§3.4] §3.4 (adaptive threshold description): The threshold is described as mitigating hallucinations from overlaps, yet the manuscript provides no quantitative analysis of how the threshold value is chosen or its sensitivity. If the threshold is a key load-bearing heuristic, its derivation or validation procedure should be shown explicitly rather than left as an empirical choice.
Authors: We will expand §3.4 with a quantitative description of the threshold selection process, including the validation procedure on a held-out set and a sensitivity analysis showing WER variation across different threshold values. This will make the empirical choice explicit and demonstrate its robustness. revision: yes
Circularity Check
No circularity: purely empirical method proposal with external baselines
full rationale
The paper proposes four training strategies (dual-encoder, feature interleaving, length-aware speaker ID loss, adaptive threshold) and reports relative WER improvements of 18% and 24% versus open-source baselines on AliMeeting and Aishell4. No derivation chain, first-principles result, fitted parameter renamed as prediction, or self-citation load-bearing step exists. Performance numbers are direct empirical comparisons to external systems; the strategies are architectural/heuristic choices whose efficacy is tested by ablation or comparison outside the paper's own fitted values. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
These sys- tems are relatively lightweight in parameters and deliver robust performance
Introduction Multi-talker speech recognition[1, 2, 3] has been widely applied in scenarios such as meeting recordings, subtitle transcription, and dialogue understanding, aiming to solve the problem of ”who spoke what.” Since the task can be split into both au- tomatic speech recognition (ASR) and speaker identification tasks, it can be solved with the pi...
-
[2]
Proposed Method 2.1. Dual-encoder structure and feature fusion strategies Figure 1 illustrates the overall architecture, which consists of two encoders: an ASR encoder and a speaker-feature encoder. Given an audio segment containing multiple speakers, the dual encoders extract semantic features and speaker features, which are then combined in various form...
Pith/arXiv arXiv 2026
-
[3]
Experiments In the first training stage, we use the WenetSpeech corpus [21]. For the second and third stages, we adopt an internal ASR corpus of approximately 4,000 hours, which consists of long- duration two-speaker conversations with transcriptions but does not contain overlap labels. Long recordings are truncated into shorter segments (8–20 seconds) ac...
-
[4]
Results Table 2 presents the performance of different systems across three evaluation sets. The pipeline systems, whether using 3D-Speaker or DiariZen-large for diarization, achieve compa- rable results. In contrast, the end-to-end model VibeV oice-ASR struggles on highly overlapped segments. Our systems, built upon the SenseV oice-small encoder, in- heri...
-
[5]
The relationship between ASR and diarization tasks is carefully balanced through both the model architecture and the training scheme
Conclusions In this paper, we proposed an end-to-end model for multi- speaker ASR with only 0.7B parameters, which achieves strong performance on far-field recordings with high overlap ratios. The relationship between ASR and diarization tasks is carefully balanced through both the model architecture and the training scheme. Our experiments demonstrate th...
-
[6]
These tools were not employed to gen- erate scientific ideas, experimental data, or technical contribu- tions
Generative AI Use Disclosure During the preparation of this manuscript, generative AI tools were used solely for language editing and manuscript polishing to enhance readability. These tools were not employed to gen- erate scientific ideas, experimental data, or technical contribu- tions. All authors have thoroughly reviewed and approved the final version...
-
[7]
Deep neu- ral networks for single-channel multi-talker speech recognition,
C. Weng, D. Yu, M. L. Seltzer, and J. Droppo, “Deep neu- ral networks for single-channel multi-talker speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 23, no. 10, pp. 1670–1679, 2015
2015
-
[8]
Improv- ing end-to-end single-channel multi-talker speech recognition,
W. Zhang, X. Chang, Y . Qian, and S. Watanabe, “Improv- ing end-to-end single-channel multi-talker speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 28, pp. 1385–1394, 2020
2020
-
[9]
Integration of speech separation, diariza- tion, and recognition for multi-speaker meetings: System descrip- tion, comparison, and analysis,
D. Raj, P. Denisov, Z. Chen, H. Erdogan, Z. Huang, M. He, S. Watanabe, J. Du, T. Yoshioka, Y . Luo, N. Kanda, J. Li, S. Wis- dom, and J. R. Hershey, “Integration of speech separation, diariza- tion, and recognition for multi-speaker meetings: System descrip- tion, comparison, and analysis,” in2021 IEEE Spoken Language Technology Workshop (SLT), 2021, pp. 897–904
2021
-
[10]
Transcribe-to-diarize: Neural speaker diarization for unlimited number of speakers using end- to-end speaker-attributed asr,
N. Kanda, X. Xiao, Y . Gaur, X. Wang, Z. Meng, Z. Chen, and T. Yoshioka, “Transcribe-to-diarize: Neural speaker diarization for unlimited number of speakers using end- to-end speaker-attributed asr,”ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8082–8086, 2021. [Online]. Available: https://api.se...
2022
-
[11]
SCDiar: a streaming diarization system based on speaker change detection and speech recognition,
N. Zheng, X. Wan, K. Liu, and Z. Huan, “SCDiar: a streaming diarization system based on speaker change detection and speech recognition,” inICASSP 2025 - 2025 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[12]
META-CAT: Speaker-informed speech embeddings via meta information con- catenation for multi-talker asr,
J. Wang, W. Wang, K. Dhawan, T. Park, M. Kim, I. Medennikov, H. Huang, N. Koluguri, J. Balam, and B. Ginsburg, “META-CAT: Speaker-informed speech embeddings via meta information con- catenation for multi-talker asr,” inICASSP 2025 - 2025 IEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing (ICASSP), 2025, pp. 1–5
2025
-
[13]
Separate-to- recognize: Joint multi-target speech separation and speech recog- nition for speaker-attributed asr,
Y . Lin, Z. Du, S. Zhang, F. Yu, Z. Zhao, and F. Wu, “Separate-to- recognize: Joint multi-target speech separation and speech recog- nition for speaker-attributed asr,” in2022 13th International Sym- posium on Chinese Spoken Language Processing (ISCSLP), 2022, pp. 150–154
2022
-
[14]
DiarizationLM: Speaker Diarization Post-Processing with Large Language Models,
Q. Wang, Y . Huang, G. Zhao, E. Clark, W. Xia, and H. Liao, “DiarizationLM: Speaker Diarization Post-Processing with Large Language Models,” inInterspeech 2024, 2024, pp. 3754–3758
2024
-
[15]
Sortformer: A novel approach for permutation-resolved speaker supervision in speech-to-text systems,
T. Park, I. Medennikov, K. Dhawan, W. Wang, H. Huang, N. R. Koluguri, K. C. Puvvada, J. Balam, and B. Ginsburg, “Sortformer: A novel approach for permutation-resolved speaker supervision in speech-to-text systems,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. ...
-
[16]
48 153–48 169
PMLR, 13–19 Jul 2025, pp. 48 153–48 169
2025
-
[17]
Diarization-aware multi-speaker automatic speech recognition via large language models,
Y . Lin, M. Cheng, Z. Li, B. Tang, and M. Li, “Diarization-aware multi-speaker automatic speech recognition via large language models,” 2025
2025
-
[18]
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and diarization on long audio,” 2025. [Online]. Available: https://arxiv.org/abs/2511.16046
arXiv 2025
-
[19]
TagSpeech: End-to-end multi- speaker asr and diarization with fine-grained temporal grounding,
M. Huo, Y . Shao, and Y . Zhang, “TagSpeech: End-to-end multi- speaker asr and diarization with fine-grained temporal grounding,”
-
[20]
Available: https://arxiv.org/abs/2601.06896
[Online]. Available: https://arxiv.org/abs/2601.06896
-
[21]
MOSS transcribe diarize technical report,
M. AI, D. Yu, Z. Lin, C. Yang, Y . Zhang, H. Chen, J. Chen, K. Chen, L. Fan, Y . Jiang, J. Zhu, M. Li, W. Wang, Y . Wang, Z. Xu, Y . Gong, Y . Zhang, W. Zhang, S. Wang, Z. Wu, Z. Fei, Q. Cheng, S. Li, and X. Qiu, “MOSS transcribe diarize technical report,” 2026. [Online]. Available: https://arxiv.org/abs/2601.01554
arXiv 2026
-
[22]
H. Yin, Y . Chen, C. Deng, L. Cheng, H. Wang, C.- H. Tan, Q. Chen, W. Wang, and X. Li, “SpeakerLM: End-to-end versatile speaker diarization and recognition with multimodal large language models,” 2026. [Online]. Available: https://arxiv.org/abs/2508.06372
arXiv 2026
-
[23]
VibeV oice-ASR technical report,
Z. Peng, J. Yu, Y . Chang, Z. Wang, L. Dong, Y . Hao, Y . Tu, C. Yang, W. Wang, S. Xu, Y . Sun, H. Bao, W. Xu, Y . Zhu, Z. Wang, T. Song, Y . Xia, Z. Chi, S. Huang, L. Wang, C. Ding, S. Wang, X. Chen, and F. Wei, “VibeV oice-ASR technical report,”
-
[24]
Available: https://arxiv.org/abs/2601.18184
[Online]. Available: https://arxiv.org/abs/2601.18184
-
[25]
K. An, Q. Chen, C. Deng, Z. Du, C. Gao, Z. Gao, Y . Gu, T. He, H. Hu, K. Hu, S. Ji, Y . Li, Z. Li, H. Lu, H. Luo, X. Lv, B. Ma, Z. Ma, C. Ni, C. Song, J. Shi, X. Shi, H. Wang, W. Wang, Y . Wang, Z. Xiao, Z. Yan, Y . Yang, B. Zhang, Q. Zhang, S. Zhang, N. Zhao, and S. Zheng, “FunAudioLLM: V oice understanding and genera- tion foundation models for natural ...
arXiv 2024
-
[26]
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking,” inInterspeech 2023, 2023, pp. 5301– 5305
2023
-
[27]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inInternational Conference on Learning Repre- sentations, 2022
2022
-
[28]
Convolutional neural network for speaker change detection in telephone speaker diarization system,
M. Hruz and Z. Zajic, “Convolutional neural network for speaker change detection in telephone speaker diarization system,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 4945–4949
2017
-
[29]
CHiME-6 challenge: Tackling multispeaker speech recognition for unseg- mented recordings,
S. Watanabe, M. Mandel, J. Barker, and E. Vincent, “CHiME-6 challenge: Tackling multispeaker speech recognition for unseg- mented recordings,”ArXiv, vol. abs/2004.09249, 2020
arXiv 2004
-
[30]
WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,
B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zeng, D. Wu, and Z. Peng, “WenetSpeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,” in International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2022
2022
-
[31]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inProc. ICASSP. IEEE, 2022
2022
-
[32]
AISHELL-4: An open source dataset for speech enhance- ment, separation, recognition and speaker diarization in confer- ence scenario,
F. Yihui, C. Luyao, L. Shubo, J. Yukai, K. Yuxiang, C. Zhuo, H. Yanxin, X. Lei, W. Jian, B. Hui, X. Xin, D. Jun, and C. Jing- dong, “AISHELL-4: An open source dataset for speech enhance- ment, separation, recognition and speaker diarization in confer- ence scenario,” inInterspeech, 2021
2021
-
[33]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September
-
[34]
Available: https://qwenlm.github.io/blog/qwen2.5
[Online]. Available: https://qwenlm.github.io/blog/qwen2.5
-
[35]
3D-Speaker- Toolkit: An open source toolkit for multi-modal speaker verifi- cation and diarization,
Y . Chen, S. Zheng, H. Wang, L. Chenget al., “3D-Speaker- Toolkit: An open source toolkit for multi-modal speaker verifi- cation and diarization,” 2025
2025
-
[36]
Efficient and generalizable speaker diarization via structured pruning of self-supervised models,
J. Han, P. P ´alka, M. Delcroix, F. Landini, J. Rohdin, J. Cernock`y, and L. Burget, “Efficient and generalizable speaker diarization via structured pruning of self-supervised models,”arXiv preprint arXiv:2506.18623, 2025
arXiv 2025
-
[37]
Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to- end speech recognition,
Z. Gao, S. Zhang, I. McLoughlin, and Z. Yan, “Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to- end speech recognition,” inProc. Interspeech 2022, 2022, pp. 2063–2067
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.