Spandana: Reconciling Strict SLOs with Low Cost under Fine-Grained Load Fluctuations
Pith reviewed 2026-06-30 03:19 UTC · model grok-4.3
The pith
Spandana decouples SLO enforcement from cost optimization by placing a lightweight controller on each VM to steer individual requests between the VM and FaaS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
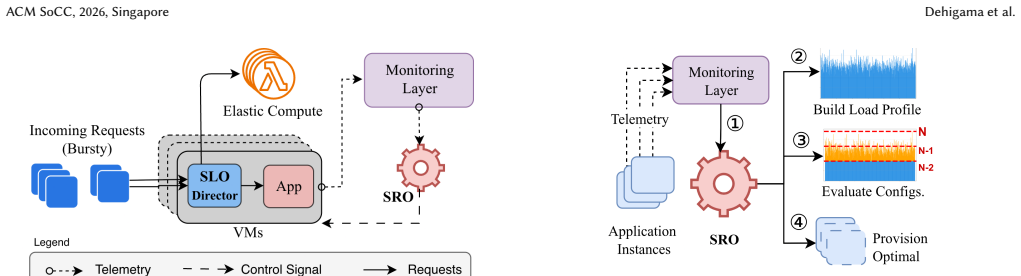
Spandana addresses the tradeoff by decoupling SLO enforcement from cost optimization. A lightweight controller colocated with each application VM enforces SLOs by steering each arriving request between the VM and FaaS. Requests that can meet the SLO stay on the VM; the remaining requests are forwarded to a stock FaaS layer such as AWS Lambda. For cost optimization, Spandana's resource allocator determines the most-efficient VM provisioning by accounting for VM cost, FaaS cost, and traffic volatility, allowing the VM pool to run at high utilization.
What carries the argument
The lightweight controller colocated with each VM that classifies arriving requests and steers them to the VM if the SLO can be met or to FaaS otherwise.
If this is right
- VM pools can be sized for high utilization without risking SLO breaches during load spikes.
- Existing FaaS platforms can be used unchanged as the overflow tier.
- Cost savings of 5-44 percent are achieved while preserving strict SLO compliance.
- Resource allocation can explicitly factor in both VM and FaaS pricing plus traffic volatility.
Where Pith is reading between the lines
- The same steering idea could be applied to other hybrid execution environments beyond VM-FaaS pairs.
- Operators might reduce reliance on complex reactive autoscalers if per-application controllers handle local decisions.
- Workloads with bursty but short peaks become cheaper to run without custom capacity planning.
Load-bearing premise
The colocated controller can classify each request accurately and with negligible added latency so that steering decisions neither violate the SLO themselves nor systematically misroute traffic under real sub-second fluctuations.
What would settle it
Run the system on a production trace with measured sub-second spikes and record whether any request routed to the VM misses its SLO or whether total cost exceeds that of the best baseline.
Figures

read the original abstract
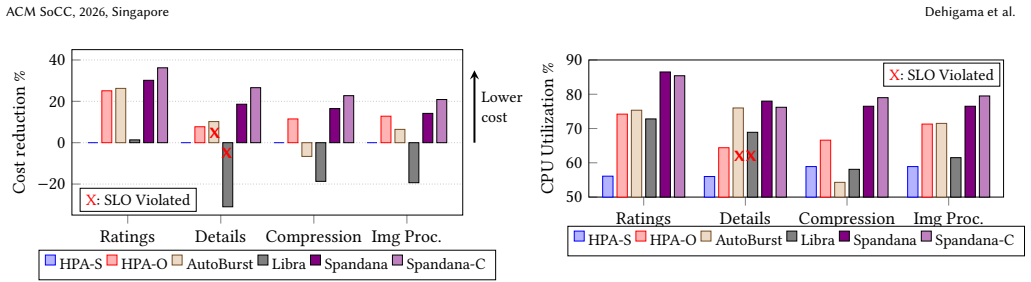
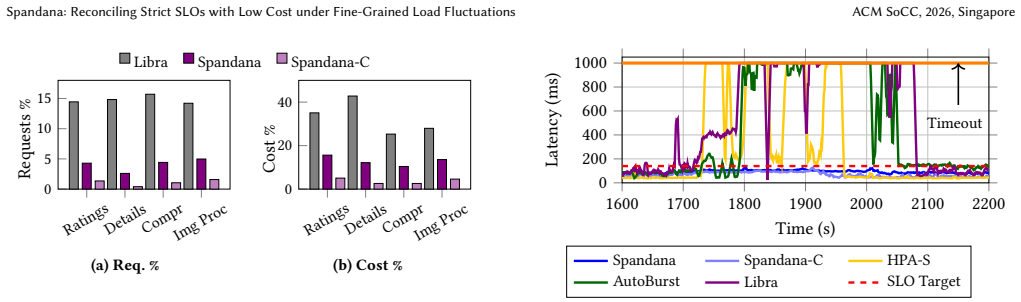
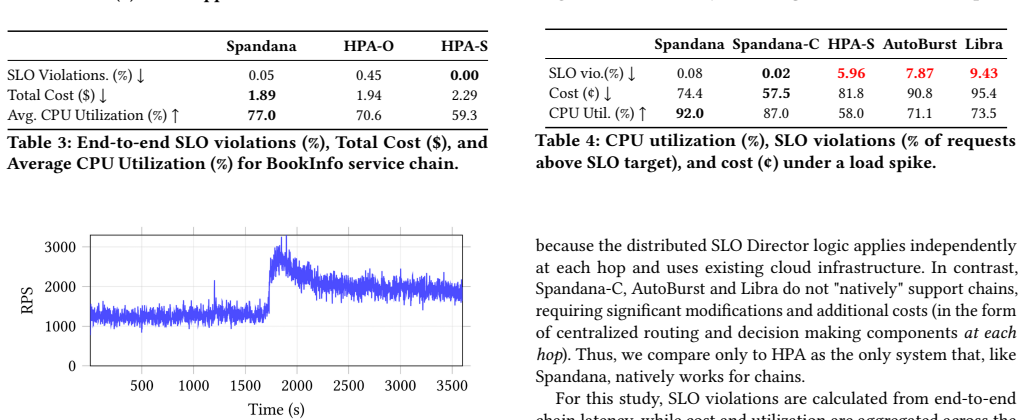
Cloud-based online services face significant sub-second load fluctuations while needing to meet strict Service Level Objectives (SLOs). Cluster operators often over-provision resources to protect SLOs, sacrificing utilization and cost efficiency. Existing reactive and proactive autoscalers, serverless (FaaS) deployments, and VM/FaaS hybrid systems fail to reconcile strict SLO compliance with low cost and high utilization under fine-grained load fluctuation. We introduce Spandana, an architecture that addresses this trade off by decoupling SLO enforcement from cost optimization. A lightweight controller colocated with each application VM enforces SLOs by steering each arriving request between the VM and FaaS. Requests that can meet the SLO stay on the VM; the remaining requests are forwarded to a stock FaaS layer such as AWS Lambda. For cost optimization, Spandana's resource allocator determines the most-efficient VM provisioning by accounting for VM cost, FaaS cost, and traffic volatility, allowing the VM pool to run at high utilization. Our evaluation shows that Spandana maintains strict SLO adherence, achieves 76-86% CPU utilization, and reduces cost by 5-44% over three SOTA baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Spandana, a hybrid VM/FaaS architecture that decouples SLO enforcement from cost optimization. A lightweight controller colocated with each application VM steers individual requests to the VM (if the SLO can be met) or forwards them to FaaS; a separate resource allocator then provisions the VM pool to maximize utilization while accounting for VM/FaaS costs and traffic volatility. Evaluation claims strict SLO adherence, 76-86% CPU utilization, and 5-44% cost reduction versus three SOTA baselines under fine-grained load fluctuations.
Significance. If the controller's per-request decisions can be shown to be both fast and accurate, the architecture would allow cloud operators to run VMs at high utilization without sacrificing strict SLOs, offering a practical middle ground between over-provisioned VMs and pure serverless deployments.
major comments (3)
- [§3.2] §3.2 (Controller): the per-request classification rule is presented only at a high level with no pseudocode, threshold equations, or latency analysis; without an explicit decision procedure it is impossible to verify that classification itself does not add latency or systematically misroute requests under sub-second arrival and service-time jitter—the central assumption supporting the SLO guarantee.
- [§4] §4 (Evaluation setup): workload generation, fluctuation timescales, and request-size distributions are described only qualitatively; the reported 76-86% utilization and cost numbers therefore cannot be reproduced or stress-tested against the exact volatility regime the paper targets.
- [§5] §5 (Baselines and results): the three SOTA baselines are compared without reporting their internal parameter settings or the precise cost model used for the 5-44% savings; this leaves open whether the gains depend on favorable baseline configurations rather than on Spandana's decoupling.
minor comments (2)
- Notation for the allocator's cost function is introduced without a consolidated table of symbols.
- Figure captions should explicitly state the fluctuation frequency (e.g., requests per second) used in each experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Controller): the per-request classification rule is presented only at a high level with no pseudocode, threshold equations, or latency analysis; without an explicit decision procedure it is impossible to verify that classification itself does not add latency or systematically misroute requests under sub-second arrival and service-time jitter—the central assumption supporting the SLO guarantee.
Authors: We agree that the controller description in §3.2 is high-level. The classification uses a threshold rule based on the SLO target, estimated service time, and current VM load, but we will add explicit pseudocode, the threshold equations, and a latency breakdown in the revision. Measurements will show classification overhead is under 100μs and does not introduce systematic misrouting under the evaluated jitter levels. revision: yes
-
Referee: [§4] §4 (Evaluation setup): workload generation, fluctuation timescales, and request-size distributions are described only qualitatively; the reported 76-86% utilization and cost numbers therefore cannot be reproduced or stress-tested against the exact volatility regime the paper targets.
Authors: We will revise §4 to include quantitative details on the workload generator, exact fluctuation timescales (e.g., burst intervals and amplitudes), and request-size distributions used. This will allow full reproduction of the 76-86% utilization and cost results under the targeted volatility. revision: yes
-
Referee: [§5] §5 (Baselines and results): the three SOTA baselines are compared without reporting their internal parameter settings or the precise cost model used for the 5-44% savings; this leaves open whether the gains depend on favorable baseline configurations rather than on Spandana's decoupling.
Authors: We will report the exact parameter settings for each baseline (e.g., scaling thresholds and prediction horizons) as configured per their original papers, and provide the full cost model (VM hourly rates and FaaS per-invocation/duration pricing). This will clarify that the reported savings arise from Spandana's decoupling rather than baseline tuning. revision: yes
Circularity Check
No circularity: architecture and evaluation lack derivation chain or fitted predictions
full rationale
The paper presents Spandana as an architecture using a colocated lightweight controller to steer requests between VM and FaaS for SLO enforcement, with a separate resource allocator for cost optimization. Evaluation claims (76-86% utilization, 5-44% cost reduction) are presented as empirical outcomes. No equations, fitted parameters, predictions derived from inputs, self-citations as load-bearing premises, or ansatzes appear in the abstract or description. The derivation chain is absent; claims rest on system design and reported measurements rather than any reduction of results to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Envoy Proxy. https://www.envoyproxy.io/
-
[2]
[n. d.]. Fluent Bit. https://fluentbit.io/
-
[3]
AWS Lambda – Container Image Support
2021. AWS Lambda – Container Image Support. https://aws.amazon.com/blogs/ aws/new-for-aws-lambda-container-image-support/. Accessed 10. Sep. 2025
2021
-
[4]
AWS Lambda Web Adapter
2022. AWS Lambda Web Adapter. https://github.com/awslabs/aws-lambda-web- adapter. Accessed 10. Sep. 2025
2022
-
[5]
Serverless Adapter
2022. Serverless Adapter. https://github.com/H4ad/serverless-adapter. Accessed
2022
-
[6]
Archive Team: The Twitter Stream Grab
2024. Archive Team: The Twitter Stream Grab. https://archive.org/details/ twitterstream. Accessed 9. Jan. 2024
2024
-
[7]
BookInfo Application
2024. "BookInfo Application". https://istio.io/latest/docs/examples/bookinfo/. Accessed 20. May. 2024
2024
-
[8]
Horizontal Pod Autoscaler - Kubernetes
2024. Horizontal Pod Autoscaler - Kubernetes. [Online; accessed 14. Jan. 2024]. https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
2024
-
[9]
2025 Kubernetes Cost Benchmark Report
2025. 2025 Kubernetes Cost Benchmark Report. https://cast.ai/kubernetes-cost- benchmark/. Accessed 19. Aug. 2025
2025
-
[10]
Discovering Services
2025. Discovering Services. https://kubernetes.io/docs/concepts/services- networking/service/#discovering-services. Accessed: 18.Sept.2025
2025
-
[11]
Horizontal Pod Autoscaling
2025. Horizontal Pod Autoscaling. https://kubernetes.io/docs/tasks/run- application/horizontal-pod-autoscale/. Accessed: 18.Sept.2025
2025
-
[12]
Services, Load Balancing, and Networking
2025. Services, Load Balancing, and Networking. https://kubernetes.io/docs/ concepts/services-networking/
2025
-
[13]
Amazon Web Services. 2025. Burstable Performance Instances and CPU Cred- its. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-credits- baseline-concepts.html. Accessed: 18.Sept.2025
2025
-
[14]
Ataollah Fatahi Baarzi, Timothy Zhu, and Bhuvan Urgaonkar. 2019. BurScale: Using Burstable Instances for Cost-Effective Autoscaling in the Public Cloud. In Proceedings of the ACM Symposium on Cloud Computing(Santa Cruz, CA, USA) (SoCC ’19). Association for Computing Machinery, New York, NY, USA, 126–138. doi:10.1145/3357223.3362706
-
[15]
Haoqiong Bian, Tiannan Sha, and Anastasia Ailamaki. 2023. Using Cloud Func- tions as Accelerator for Elastic Data Analytics.Proc. ACM Manag. Data1, 2, Article 161 (jun 2023), 27 pages. doi:10.1145/3589306
-
[16]
Peter Bodik, Armando Fox, Michael J. Franklin, Michael I. Jordan, and David A. Patterson. 2010. Characterizing, modeling, and generating workload spikes for stateful services. InProceedings of the 1st ACM Symposium on Cloud Computing (Indianapolis, Indiana, USA)(SoCC ’10). Association for Computing Machinery, New York, NY, USA, 241–252. doi:10.1145/180712...
-
[17]
Eric Boutin, Jaliya Ekanayake, Wei Lin, Bing Shi, Jingren Zhou, Zhengping Qian, Ming Wu, and Lidong Zhou. 2014. Apollo: scalable and coordinated scheduling for cloud-scale computing. InProceedings of the 11th USENIX Conference on Oper- ating Systems Design and Implementation(Broomfield, CO)(OSDI’14). USENIX Association, USA, 285–300
2014
- [18]
-
[19]
Jiagan Cheng, Yilong Zhao, Zijun Li, Quan Chen, Weihao Cui, and Minyi Guo
-
[20]
In2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS)
Microless: Cost-efficient Hybrid Deployment of Microservices on IaaS VMs and Serverless. In2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS). IEEE, 2303–2310
-
[21]
2022.Service Meshes Are on the Rise — But Greater Understanding and Experience Are Required
Cloud Native Computing Foundation. 2022.Service Meshes Are on the Rise — But Greater Understanding and Experience Are Required. Technical Report. Cloud Native Computing Foundation. Accessed: 2025-09-18. https://www.cncf.io/wp- content/uploads/2022/05/CNCF_Service_Mesh_MicroSurvey_Final.pdf
2022
-
[22]
Marcin Copik, Grzegorz Kwasniewski, Maciej Besta, Michal Podstawski, and Torsten Hoefler. 2021. SeBS: a serverless benchmark suite for function-as-a- service computing. InProceedings of the 22nd International Middleware Conference (Québec city, Canada)(Middleware ’21). Association for Computing Machinery, New York, NY, USA, 64–78. doi:10.1145/3464298.3476133
-
[23]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Marcus Fontoura, and Ricardo Bianchini. 2017. Resource Central: Understanding and Predicting Workloads for Improved Resource Management in Large Cloud Platforms. In Proceedings of the 26th Symposium on Operating Systems Principles(Shanghai, China)(SOSP ’17). Association for Computing Machinery, N...
-
[24]
Jaime Dantas, Hamzeh Khazaei, and Marin Litoiu. 2021. BIAS Autoscaler: Lever- aging Burstable Instances for Cost-Effective Autoscaling on Cloud Systems. In Proceedings of the Seventh International Workshop on Serverless Computing (WoSC7) 2021(Virtual Event, Canada)(WoSC ’21). Association for Computing Machinery, New York, NY, USA, 9–16. doi:10.1145/349365...
-
[25]
Datadog. 2025. Container Report. https://www.datadoghq.com/container-report/. Accessed: 18.Sept.2025
2025
-
[26]
Dilina Dehigama, Shyam Jesalpura, Antonios Katsarakis, Marios Kogias, Rakesh Kumar, and Boris Grot. 2024. Composing microservices and serverless for load resilience. 1–8. The 2nd Workshop on SErverless Systems, Applications and MEthodologies, SESAME 2024 ; Conference date: 22-04-2024 Through 22-04-2024. https://sesame2024.github.io/
2024
-
[27]
Ferguson, Peter Bodik, Srikanth Kandula, Eric Boutin, and Rodrigo Fonseca
Andrew D. Ferguson, Peter Bodik, Srikanth Kandula, Eric Boutin, and Rodrigo Fonseca. 2012. Jockey: guaranteed job latency in data parallel clusters. InProceed- ings of the 7th ACM European Conference on Computer Systems(Bern, Switzerland) (EuroSys ’12). Association for Computing Machinery, New York, NY, USA, 99–112. doi:10.1145/2168836.2168847
-
[28]
Gallager
Robert G. Gallager. 2013.Stochastic Processes: Theory for Applications. Cambridge University Press. https://books.google.co.uk/books?id=ERLrAQAAQBAJ
2013
-
[29]
Anshul Gandhi, Mor Harchol-Balter, Ram Raghunathan, and Michael A. Kozuch
- [30]
-
[31]
Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, and Ion Stoica. 2011. Dominant resource fairness: fair allocation of multiple resource types. InProceedings of the 8th USENIX Conference on Networked Systems Design and Implementation(Boston, MA)(NSDI’11). USENIX Association, USA, 323–336
2011
-
[32]
Ionel Gog, Malte Schwarzkopf, Adam Gleave, Robert N. M. Watson, and Steven Hand. 2016. Firmament: fast, centralized cluster scheduling at scale. InProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (Savannah, GA, USA)(OSDI’16). USENIX Association, USA, 99–115
2016
-
[33]
Google Cloud. 2025. Scalable Apps and Autoscaling in Google Kubernetes Engine. https://cloud.google.com/kubernetes-engine/docs/learn/scalable-apps- autoscale. Accessed: 18.Sept.2025
2025
-
[34]
2025.Grafana Loki: Like Prometheus, but for logs
Grafana Labs. 2025.Grafana Loki: Like Prometheus, but for logs. Grafana Labs
2025
-
[35]
Grafana Labs. 2025. k6 Documentation. https://grafana.com/docs/k6/latest/
2025
-
[36]
Jashwant Raj Gunasekaran, Prashanth Thinakaran, Mahmut Taylan Kandemir, Bhuvan Urgaonkar, George Kesidis, and Chita Das. 2019. Spock: Exploiting Serverless Functions for SLO and Cost Aware Resource Procurement in Public Cloud. In2019 IEEE 12th International Conference on Cloud Computing (CLOUD). 199–208. doi:10.1109/CLOUD.2019.00043
-
[37]
Rubaba Hasan, Timothy Zhu, and Bhuvan Urgaonkar. 2024. AutoBurst: Au- toscaling Burstable Instances for Cost-effective Latency SLOs. InProceedings of the 2024 ACM Symposium on Cloud Computing(Redmond, WA, USA)(SoCC ’24). Association for Computing Machinery, New York, NY, USA, 243–258. doi:10.1145/3698038.3698530
-
[38]
Md Rajib Hossen, Mohammad A. Islam, and Kishwar Ahmed. 2022. Practical Efficient Microservice Autoscaling with QoS Assurance. InProceedings of the 31st International Symposium on High-Performance Parallel and Distributed Computing (Minneapolis, MN, USA)(HPDC ’22). Association for Computing Machinery, New York, NY, USA, 240–252. doi:10.1145/3502181.3531460
-
[39]
Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar, and Andrew Goldberg. 2009. Quincy: fair scheduling for distributed computing clusters. InProceedings of the ACM SIGOPS 22nd Symposium on Operating Sys- tems Principles(Big Sky, Montana, USA)(SOSP ’09). Association for Computing Machinery, New York, NY, USA, 261–276. doi:10.1145/1629...
-
[40]
Baarzi, George Kesidis, Bhuvan Urgaonkar, Nader Alfares, and Mahmut Kandemir
Aman Jain, Ata F. Baarzi, George Kesidis, Bhuvan Urgaonkar, Nader Alfares, and Mahmut Kandemir. 2020. SplitServe: Efficiently Splitting Apache Spark Jobs Across FaaS and IaaS. InProceedings of the 21st International Middleware Conference(Delft, Netherlands)(Middleware ’20). Association for Computing Machinery, New York, NY, USA, 236–250. doi:10.1145/34232...
-
[41]
Sangeetha Abdu Jyothi, Carlo Curino, Ishai Menache, Shravan Matthur Narayana- murthy, Alexey Tumanov, Jonathan Yaniv, Ruslan Mavlyutov, Íñigo Goiri, Subru Krishnan, Janardhan Kulkarni, and Sriram Rao. 2016. Morpheus: towards auto- mated SLOs for enterprise clusters. InProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation...
2016
-
[42]
Ram Srivatsa Kannan, Lavanya Subramanian, Ashwin Raju, Jeongseob Ahn, Jason Mars, and Lingjia Tang. 2019. GrandSLAm: Guaranteeing SLAs for Jobs in Microservices Execution Frameworks. InProceedings of the Fourteenth EuroSys Conference 2019(Dresden, Germany)(EuroSys ’19). Association for Computing Machinery, New York, NY, USA, Article 34, 16 pages. doi:10.1...
-
[43]
Shutian Luo, Huanle Xu, Kejiang Ye, Guoyao Xu, Liping Zhang, Guodong Yang, and Chengzhong Xu. 2022. The Power of Prediction: Microservice Auto Scaling via Workload Learning. InProceedings of the 13th Symposium on Cloud Computing (San Francisco, California)(SoCC ’22). Association for Computing Machinery, New York, NY, USA, 355–369. doi:10.1145/3542929.3563477
-
[44]
Ming Mao and Marty Humphrey. 2012. A Performance Study on the VM Startup Time in the Cloud. In2012 IEEE Fifth International Conference on Cloud Computing. 423–430. doi:10.1109/CLOUD.2012.103
-
[45]
Ziming Mao, Tian Xia, Zhanghao Wu, Wei-Lin Chiang, Tyler Griggs, Romil Bhardwaj, Zongheng Yang, Scott Shenker, and Ion Stoica. 2025. SkyServe: Serving AI Models across Regions and Clouds with Spot Instances. InProceedings of the Twentieth European Conference on Computer Systems(Rotterdam, Netherlands) (EuroSys ’25). Association for Computing Machinery, Ne...
-
[46]
Maxday. 2025. Lambda Performance Benchmark. https://maxday.github.io/ lambda-perf/. Accessed: 18.Sept.2025
2025
- [47]
-
[48]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Language Models on Preemptible Instances. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(La Jolla, CA, USA)(ASPLOS ’24). Association for ...
-
[49]
Ingo Müller, Renato Marroquín, and Gustavo Alonso. 2020. Lambada: Interactive Data Analytics on Cold Data Using Serverless Cloud Infrastructure. InProceed- ings of the 2020 ACM SIGMOD International Conference on Management of Data (Portland, OR, USA)(SIGMOD ’20). Association for Computing Machinery, New York, NY, USA, 115–130. doi:10.1145/3318464.3389758
-
[50]
Novak, Sneha Kumar Kasera, and Ryan Stutsman
Joe H. Novak, Sneha Kumar Kasera, and Ryan Stutsman. 2019. Cloud Functions for Fast and Robust Resource Auto-Scaling. In2019 11th International Conference on Communication Systems & Networks (COMSNETS). 133–140. doi:10.1109/ COMSNETS.2019.8711058
-
[51]
Shin, Xiaoyun Zhu, Mustafa Uysal, Zhikui Wang, Sharad Singhal, and Arif Merchant
Pradeep Padala, Kai-Yuan Hou, Kang G. Shin, Xiaoyun Zhu, Mustafa Uysal, Zhikui Wang, Sharad Singhal, and Arif Merchant. 2009. Automated control of multiple virtualized resources. InProceedings of the 4th ACM European Conference on Com- puter Systems(Nuremberg, Germany)(EuroSys ’09). Association for Computing Machinery, New York, NY, USA, 13–26. doi:10.114...
-
[52]
Jun Woo Park, Alexey Tumanov, Angela Jiang, Michael A. Kozuch, and Gre- gory R. Ganger. 2018. 3Sigma: distribution-based cluster scheduling for runtime uncertainty. InProceedings of the Thirteenth EuroSys Conference(Porto, Portugal) (EuroSys ’18). Association for Computing Machinery, New York, NY, USA, Article 2, 17 pages. doi:10.1145/3190508.3190515
-
[53]
Matthew Perron, Raul Castro Fernandez, David DeWitt, Michael Cafarella, and Samuel Madden. 2023. Cackle: Analytical Workload Cost and Performance Stability With Elastic Pools.Proc. ACM Manag. Data1, 4, Article 233 (dec 2023), 25 pages. doi:10.1145/3626720
-
[54]
Satya Nagamani Pothu and Swathi Kailasam. 2025. Hybrid workload prediction for improved autoscaling in IaaS clouds: An ARIMA-OLSTM approach.Ing. Syst. D Inf.30, 04 (April 2025), 961–970
2025
-
[55]
Banerjee, Saurabh Jha, Zbigniew T
Haoran Qiu, Subho S. Banerjee, Saurabh Jha, Zbigniew T. Kalbarczyk, and Ravis- hankar K. Iyer. 2020. FIRM: An Intelligent Fine-grained Resource Management Framework for SLO-Oriented Microservices. In14th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 20). USENIX Association, 805–825. https://www.usenix.org/conference/osdi20/presen...
2020
-
[56]
Kalbarczyk, Tamer Başar, and Ravishankar K
Haoran Qiu, Weichao Mao, Chen Wang, Hubertus Franke, Alaa Youssef, Zbig- niew T. Kalbarczyk, Tamer Başar, and Ravishankar K. Iyer. 2023. AWARE: Auto- mate Workload Autoscaling with Reinforcement Learning in Production Cloud Systems. In2023 USENIX Annual Technical Conference (USENIX ATC 23). USENIX Association, Boston, MA, 387–402. https://www.usenix.org/c...
2023
-
[57]
Ali Raza, Zongshun Zhang, Nabeel Akhtar, Vatche Isahagian, and Ibrahim Matta
-
[58]
In2021 IEEE International Conference on Cloud Engineering (IC2E)
LIBRA: An Economical Hybrid Approach for Cloud Applications with Strict SLAs. In2021 IEEE International Conference on Cloud Engineering (IC2E). 136–146. doi:10.1109/IC2E52221.2021.00028
-
[59]
Benjamin Reidys, Pantea Zardoshti, Íñigo Goiri, Celine Irvene, Daniel S. Berger, Haoran Ma, Kapil Arya, Eli Cortez, Taylor Stark, Eugene Bak, Mehmet Iyigun, Stanko Novakovic, Lisa Hsu, Karel Trueba, Abhisek Pan, Chetan Bansal, Saravan Rajmohan, Jian Huang, and Ricardo Bianchini. 2025. Coach: Exploiting Temporal Patterns for All-Resource Oversubscription i...
-
[60]
Nilabja Roy, Abhishek Dubey, and Aniruddha Gokhale. 2011. Efficient Autoscaling in the Cloud Using Predictive Models for Workload Forecasting. InProceedings of the IEEE International Conference on Cloud Computing. IEEE, 159–166
2011
-
[61]
Krzysztof Rzadca, Pawel Findeisen, Jacek Swiderski, Przemyslaw Zych, Przemys- law Broniek, Jarek Kusmierek, Pawel Nowak, Beata Strack, Piotr Witusowski, Steven Hand, and John Wilkes. 2020. Autopilot: workload autoscaling at Google. InProceedings of the Fifteenth European Conference on Computer Systems(Her- aklion, Greece)(EuroSys ’20). Association for Com...
-
[62]
Ghazal Sadeghian, Mohamed Elsakhawy, Mohanna Shahrad, Joe Hattori, and Mohammad Shahrad. 2023. UnFaaSener: Latency and Cost Aware Offloading of Functions from Serverless Platforms. InProceedings of the 2023 USENIX Annual Technical Conference. USENIX Association, Boston, MA, USA. https://www. usenix.org/conference/atc23/presentation/sadeghian
2023
-
[63]
Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, and Ricardo Bianchini. 2020. Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. In2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, 205...
2020
-
[64]
Danfeng Shan, Fengyuan Ren, Peng Cheng, and Ran Shu. 2016. Micro- burst in Data Centers: Observations, Implications, and Applications. arXiv:1604.07621 [cs.NI] https://arxiv.org/abs/1604.07621
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[65]
Prateek Sharma, David Irwin, and Prashant Shenoy. 2017. Portfolio-driven Resource Management for Transient Cloud Servers.Proc. ACM Meas. Anal. Comput. Syst.1, 1, Article 5 (June 2017), 23 pages. doi:10.1145/3084442
-
[66]
Won Wook Song, Taegeon Um, Sameh Elnikety, Myeongjae Jeon, and Byung- Gon Chun. 2023. Sponge: Fast Reactive Scaling for Stream Processing with Serverless Frameworks. In2023 USENIX Annual Technical Conference (USENIX ATC 23). USENIX Association, Boston, MA, 301–314. https://www.usenix.org/ conference/atc23/presentation/song
2023
-
[67]
Dmitrii Ustiugov, Theodor Amariucai, and Boris Grot. 2021. Analyzing Tail Latency in Serverless Clouds with STeLLAR. InProceedings of the 2021 IEEE International Symposium on Workload Characterization (IISWC). IEEE
2021
-
[68]
Zibo Wang, Pinghe Li, Chieh-Jan Mike Liang, Feng Wu, and Francis Y. Yan
-
[69]
InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation(Santa Clara, CA, USA)(NSDI’24)
Autothrottle: a practical bi-level approach to resource management for SLO-targeted microservices. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation(Santa Clara, CA, USA)(NSDI’24). USENIX Association, USA, Article 9, 17 pages
-
[70]
WikiBench Project. 2025. WikiBench: A Distributed Wikipedia Access Bench- mark. http://www.wikibench.eu/?page_id=60. Accessed: 18.Sept.2025
2025
-
[71]
Zhanghao Wu, Wei-Lin Chiang, Ziming Mao, Zongheng Yang, Eric Friedman, Scott Shenker, and Ion Stoica. 2024. Can’t be late: optimizing spot instance savings under deadlines. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation(Santa Clara, CA, USA)(NSDI’24). USENIX Association, USA, Article 11, 19 pages
2024
-
[72]
Rumble, and Aaron Archer
Bartek Wydrowski, Robert Kleinberg, Stephen M. Rumble, and Aaron Archer
-
[73]
In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24)
Load is not what you should balance: Introducing Prequal. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). USENIX Association, Santa Clara, CA, 1285–1299. https://www.usenix.org/conference/ nsdi24/presentation/wydrowski
-
[74]
Fangkai Yang, Lu Wang, Zhenyu Xu, Jue Zhang, Liqun Li, Bo Qiao, Camille Cou- turier, Chetan Bansal, Soumya Ram, Si Qin, Zhen Ma, Íñigo Goiri, Eli Cortez, Terry Yang, Victor Rühle, Saravan Rajmohan, Qingwei Lin, and Dongmei Zhang. 2023. Snape: Reliable and Low-Cost Computing with Mixture of Spot and On-Demand VMs. InProceedings of the 28th ACM Internationa...
-
[75]
Chengliang Zhang, Minchen Yu, Wei Wang, and Feng Yan. 2019. MArk: ex- ploiting cloud services for cost-effective, SLO-aware machine learning inference serving. InProceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference(Renton, WA, USA)(USENIX ATC ’19). USENIX Association, USA, 1049–1062
2019
-
[76]
Edward Suh, and Christina Delimitrou
Yanqi Zhang, Weizhe Hua, Zhuangzhuang Zhou, G. Edward Suh, and Christina Delimitrou. 2021. Sinan: ML-based and QoS-aware resource management for cloud microservices. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems(Virtual, USA)(ASPLOS ’21). Association for Computing Machinery,...
-
[77]
Yanqi Zhang, Zhuangzhuang Zhou, Sameh Elnikety, and Christina Delimitrou
-
[78]
arXiv:2401.02920 [cs.DC] https://arxiv.org/abs/2401.02920
Analytically-Driven Resource Management for Cloud-Native Microservices. arXiv:2401.02920 [cs.DC] https://arxiv.org/abs/2401.02920
-
[79]
Ziming Zhao, Mingyu Wu, Jiawei Tang, Binyu Zang, Zhaoguo Wang, and Haibo Chen. 2023. BeeHive: Sub-second Elasticity for Web Services with Semi-FaaS Ex- ecution. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2023). Association for Compu...
-
[80]
Xiangfeng Zhu, Guozhen She, Bowen Xue, Yu Zhang, Yongsu Zhang, Xuan Kelvin Zou, XiongChun Duan, Peng He, Arvind Krishnamurthy, Matthew Lentz, Danyang Zhuo, and Ratul Mahajan. 2023. Dissecting Overheads of Service Mesh Sidecars. InProceedings of the 2023 ACM Symposium on Cloud Computing (Santa Cruz, CA, USA)(SoCC ’23). Association for Computing Machinery, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.