CSI-CLIP++: A Scalable Channel Foundation Model for Wireless Communication via CIR-CSI Consistency
Pith reviewed 2026-06-25 19:57 UTC · model grok-4.3
The pith
Treating CSI and CIR as paired views of the same propagation process and aligning them contrastively yields transferable wireless channel representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CSI-CLIP++ treats frequency-domain channel state information and delay-domain channel impulse response as paired views of the identical propagation process and learns transferable representations through CSI-CIR contrastive alignment; the pretrained encoder adapts to PHY, RAN, and ISAC tasks with improved performance over supervised baselines.
What carries the argument
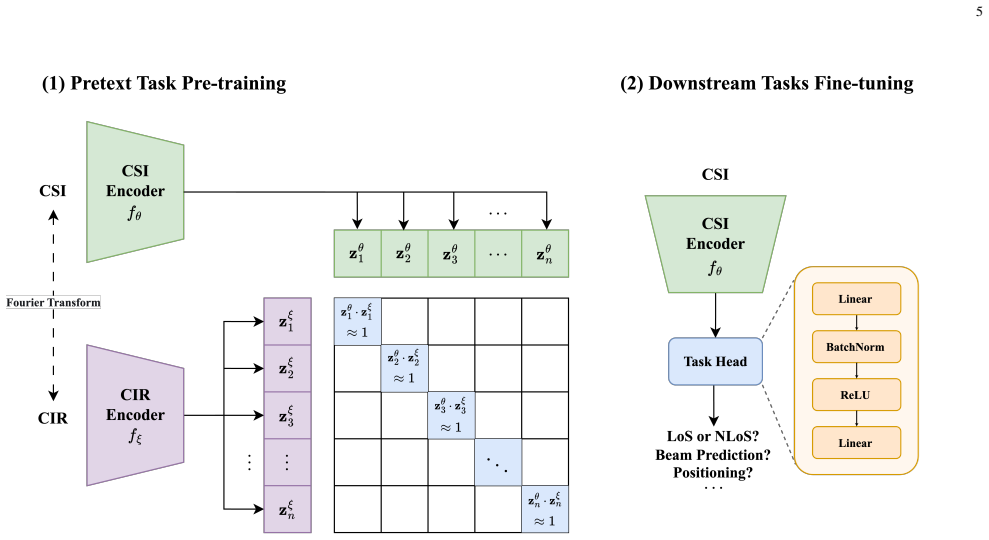
CSI-CIR contrastive alignment, which pulls matching CSI-CIR pairs together and pushes non-matching pairs apart in representation space.
If this is right
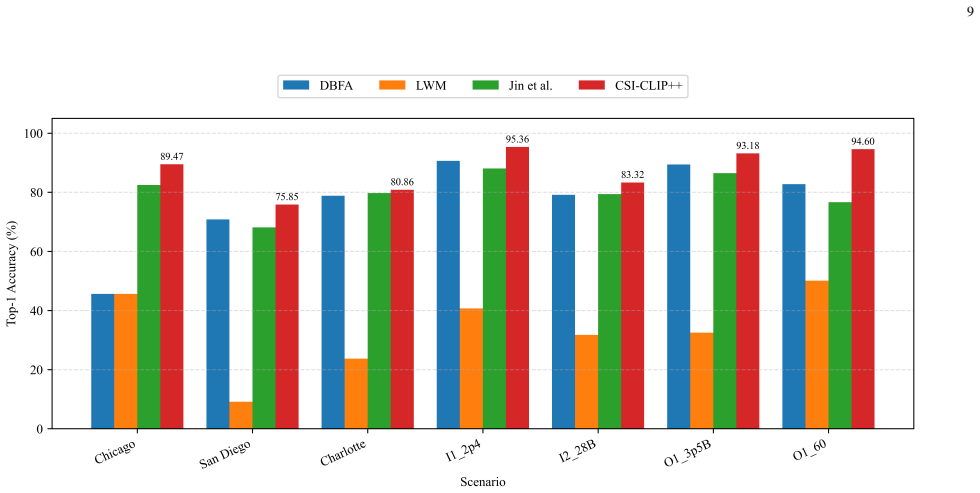
- Beam prediction Top-1 accuracy improves by up to 19.31 percentage points over supervised baselines.
- Positioning performance remains competitive and transfers across simulators such as Sionna RT.
- The contrastive objective stays effective when the encoder architecture is scaled and benefits from larger model capacity.
Where Pith is reading between the lines
- The same paired-view contrastive approach could apply to other physically linked signal representations, such as time-frequency or spatial-angular pairs.
- Explicit domain consistency during pretraining may lower the amount of labeled data needed for new carrier frequencies or antenna configurations.
- Foundation models built this way might support rapid adaptation to integrated sensing and communication tasks without task-specific architectural changes.
Load-bearing premise
Frequency-domain CSI and delay-domain CIR can be treated as paired views of the identical propagation process whose contrastive alignment alone will produce representations that transfer to downstream tasks.
What would settle it
On a new held-out DeepMIMO or Sionna RT scenario, the contrastively pretrained encoder shows no improvement or worse Top-1 beam prediction accuracy than a model trained from scratch with the same supervised objective.
Figures

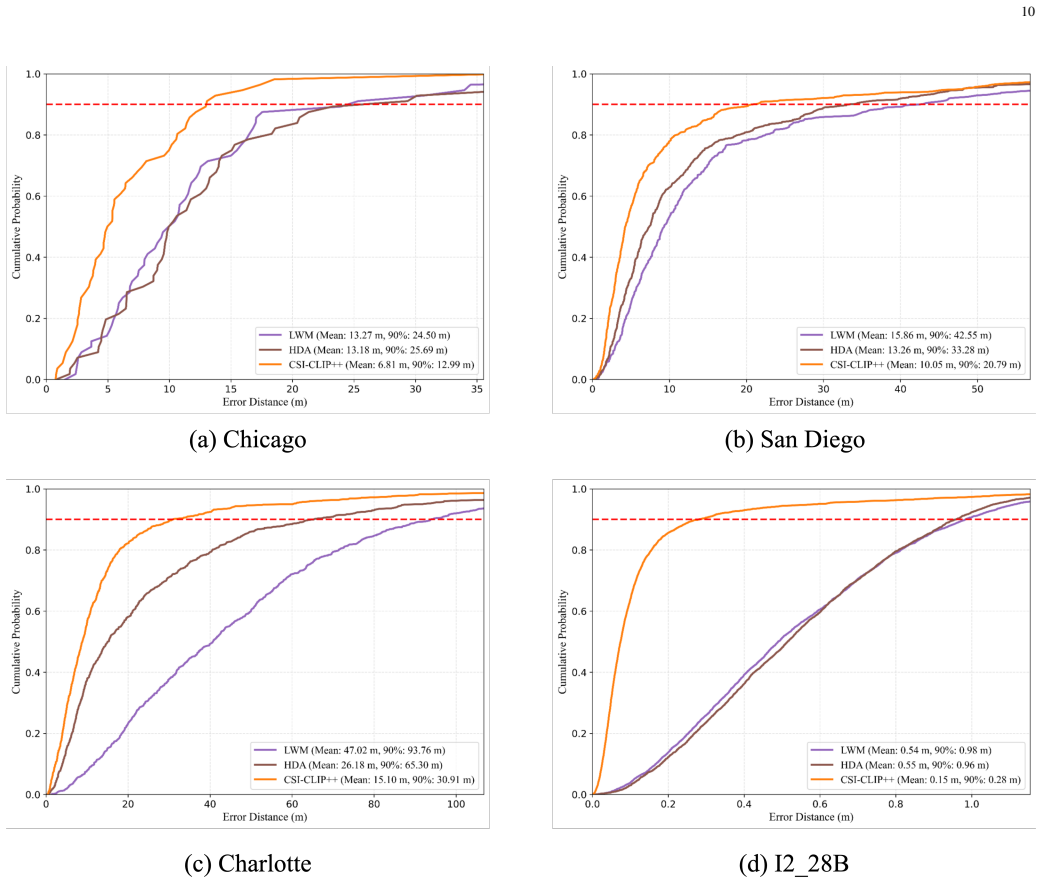
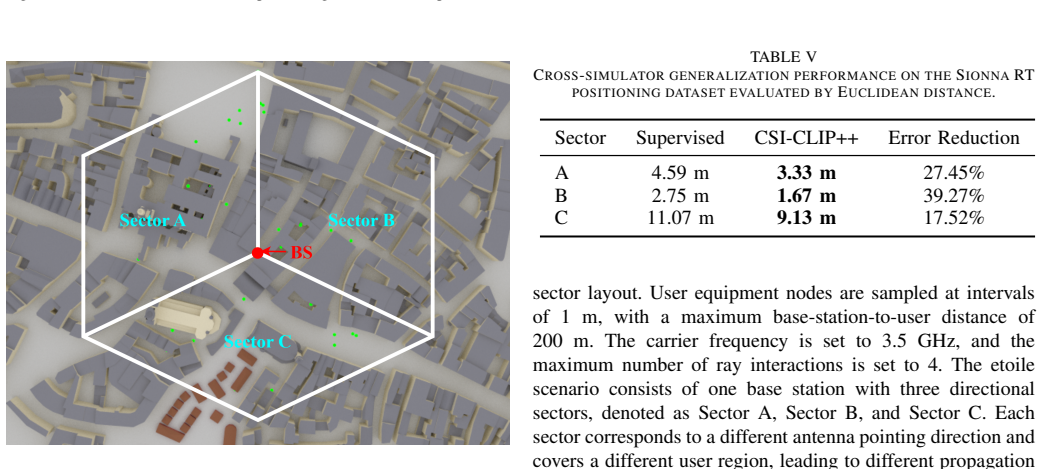
read the original abstract
Self-supervised learning can exploit large-scale unlabeled channel data to improve the transferability of wireless AI models. Existing channel foundation models are often built on single-domain representations or reconstruction-oriented objectives, which may not explicitly capture the physical correspondence between frequency- and delay-domain channel views. This paper proposes CSI-CLIP++, a scalable channel foundation model for MIMO wireless channels. CSI-CLIP++ treats frequency-domain channel state information (CSI) and delay-domain channel impulse response (CIR) as paired views of the same propagation process and learns transferable representations through CSI-CIR contrastive alignment. The pretrained CSI encoder is adapted to channel identification, beam prediction, and positioning, representing PHY, RAN, and ISAC applications. Experiments on large-scale DeepMIMO scenarios show consistent gains over supervised baselines across environments, carrier frequencies, and data scales. CSI-CLIP++ improves beam prediction Top-1 accuracy by up to 19.31 percentage points and achieves competitive positioning performance, including cross-simulator transfer on a Sionna RT dataset. Backbone scaling results further show that the proposed objective remains effective across encoder architectures and benefits from larger model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CSI-CLIP++, a scalable channel foundation model that treats frequency-domain CSI and delay-domain CIR as paired views of the same propagation process and pretrains an encoder via CSI-CIR contrastive alignment. The pretrained encoder is then adapted to downstream tasks including channel identification, beam prediction, and positioning (representing PHY, RAN, and ISAC applications). Experiments on large-scale DeepMIMO scenarios report consistent gains over supervised baselines across environments, carrier frequencies, and data scales, with beam-prediction Top-1 accuracy improving by up to 19.31 percentage points and competitive positioning performance including cross-simulator transfer to a Sionna RT dataset; backbone scaling results indicate benefits from larger model capacity.
Significance. If the reported gains are shown to arise specifically from the contrastive alignment rather than from generic multi-view pretraining or the deterministic Fourier relationship, the work would advance self-supervised foundation models for wireless channels by demonstrating transferable representations across domains without task-specific regularization. The cross-simulator transfer result and scaling behavior across encoder architectures are concrete strengths that would support broader adoption if validated.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported 19.31 pp Top-1 beam-prediction gain is presented without any description of the supervised baseline architectures, training data splits, hyperparameter matching, or statistical significance testing, preventing attribution of the improvement to the CSI-CIR contrastive objective rather than other experimental factors.
- [Methods / Experiments] Methods and Experiments sections: given that CIR is exactly the IDFT of CSI, the central claim that contrastive alignment produces representations capturing propagation invariants beyond the deterministic transform requires explicit ablation against reconstruction losses, direct Fourier pretraining, or other multi-view objectives on the same paired data; no such comparisons are supplied, leaving open the possibility that any paired-view pretraining would yield similar downstream gains.
minor comments (1)
- [Methods] Notation for the contrastive loss and the precise definition of positive/negative pairs should be stated with an equation to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional experimental details and ablations would strengthen the attribution of our results to the CSI-CIR contrastive objective. We address each major comment below and will incorporate the requested clarifications and comparisons in the revised version.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported 19.31 pp Top-1 beam-prediction gain is presented without any description of the supervised baseline architectures, training data splits, hyperparameter matching, or statistical significance testing, preventing attribution of the improvement to the CSI-CIR contrastive objective rather than other experimental factors.
Authors: We agree that the current presentation lacks sufficient detail on the baselines to fully attribute the gains. In the revised manuscript, we will expand the Experiments section to describe the supervised baseline architectures (including layer counts, dimensions, and optimization settings), explicitly state the pretraining/fine-tuning data splits and ratios, document the hyperparameter search and matching procedure, and report statistical significance via multiple random seeds with mean/std and p-values. These additions will be placed in both the main text and supplementary material. revision: yes
-
Referee: [Methods / Experiments] Methods and Experiments sections: given that CIR is exactly the IDFT of CSI, the central claim that contrastive alignment produces representations capturing propagation invariants beyond the deterministic transform requires explicit ablation against reconstruction losses, direct Fourier pretraining, or other multi-view objectives on the same paired data; no such comparisons are supplied, leaving open the possibility that any paired-view pretraining would yield similar downstream gains.
Authors: We acknowledge that the manuscript does not currently include the requested ablations and that the deterministic Fourier relationship between CSI and CIR necessitates such controls to isolate the benefit of contrastive alignment. In the revision, we will add a dedicated ablation study comparing the CSI-CIR contrastive objective against (i) reconstruction losses (e.g., CSI or CIR autoencoders), (ii) direct Fourier-based pretraining, and (iii) alternative multi-view objectives (e.g., correlation or simple alignment losses) using identical paired data, encoder backbones, and downstream tasks on the same DeepMIMO scenarios. Results will be reported with the same metrics to enable direct comparison. revision: yes
Circularity Check
No significant circularity; standard contrastive objective on physically paired views yields empirical gains
full rationale
The paper applies a standard contrastive alignment (CSI-CIR) objective to paired frequency- and delay-domain channel representations, then reports downstream empirical gains on beam prediction and positioning tasks. No equations, fitted parameters, or self-citations are shown that would make the reported accuracy improvements equivalent to the pretraining inputs by construction. The contrastive formulation is not defined in terms of the target metrics, nor does any derivation reduce predictions to a renaming or self-referential fit. The central claim rests on experimental transfer results rather than a closed mathematical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frequency-domain CSI and delay-domain CIR are paired views of the same propagation process.
Reference graph
Works this paper leans on
-
[1]
A MIMO wireless channel foundation model via CIR-CSI consistency,
J. Jiang, W. Yu, Y . Li, Y . Gao, and S. Xu, “A MIMO wireless channel foundation model via CIR-CSI consistency,” in2025 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN). IEEE, May 2025, pp. 1–6
2025
-
[2]
AI-driven channel state information (CSI) extrapolation for 6G: Current situations, challenges, and future research,
Y . Gao, Z. Lu, X. Wu, W. Yu, S. Liu, J. Du, Y . Jin, S. Zhang, X. Chu, and S. Xu, “AI-driven channel state information (CSI) extrapolation for 6G: Current situations, challenges, and future research,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 4485–4518, 2026
2026
-
[3]
A survey of artificial intelligence enabled channel estimation methods: Recent advance, performance, and outlook,
B. Li, Q. Zheng, X. Tian, M. Yang, G. Gui, W. Jiang, H. Lei, J. Jiang, F. Shu, A. Elhanashiet al., “A survey of artificial intelligence enabled channel estimation methods: Recent advance, performance, and outlook,”Artificial Intelligence Review, vol. 58, no. 6, p. 187, Jun. 2025
2025
-
[4]
AI-driven wireless positioning: Fundamentals, standards, state-of-the- art, and challenges,
G. Pan, Y . Gao, Y . Gao, W. Yu, Z. Zhong, X. Yang, X. Guo, and S. Xu, “AI-driven wireless positioning: Fundamentals, standards, state-of-the- art, and challenges,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 4394–4428, 2026
2026
-
[5]
Study on Artificial Intelligence (AI)/Machine Learning (ML) for NR Air Interface,
3GPP, “Study on Artificial Intelligence (AI)/Machine Learning (ML) for NR Air Interface,” 3rd Generation Partnership Project (3GPP), Technical Report TR 38.843, Dec. 2023
2023
-
[6]
Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,
J. Jiang, Y . Gao, X. Wu, and S. Xu, “Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,”arXiv preprint arXiv:2507.13637, Jul. 2025
Pith/arXiv arXiv 2025
-
[7]
6G native AI and channel foundation models,
S. Xu and J. Jiang, “6G native AI and channel foundation models,”ZTE Technology Journal, vol. 32, no. 1, pp. 46–52, Jan. 2026
2026
-
[8]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 139, Jul. 2021, pp...
2021
-
[9]
Enhanced fingerprint-based positioning with practical imperfections: Deep learning-based approaches,
S. Xu, J. Jiang, W. Yu, Y . Gao, G. Pan, S. Mu, Z. Ai, Y . Gao, P. Jiang, and C.-X. Wang, “Enhanced fingerprint-based positioning with practical imperfections: Deep learning-based approaches,”IEEE Wireless Communications, vol. 33, no. 1, pp. 252–258, Feb. 2026
2026
-
[10]
ChannelMamba: A Mamba-driven selective state-space model for channel prediction of high-mobility MIMO in 6G IoT,
H. Shi, K. Jin, X. Ren, W. Li, and Y . Zhou, “ChannelMamba: A Mamba-driven selective state-space model for channel prediction of high-mobility MIMO in 6G IoT,”IEEE Transactions on Wireless Communications, vol. 25, pp. 5291–5305, 2026
2026
-
[11]
Deep learning for massive MIMO CSI feedback,
C.-K. Wen, W.-T. Shih, and S. Jin, “Deep learning for massive MIMO CSI feedback,”IEEE Wireless Communications Letters, vol. 7, no. 5, pp. 748–751, Oct. 2018
2018
-
[12]
MTCA: Multi-task channel analysis for wireless communication,
J. Jiang, W. Yu, Y . Gao, and S. Xu, “MTCA: Multi-task channel analysis for wireless communication,” in2025 IEEE 102nd Vehicular Technology Conference (VTC2025-Fall). IEEE, Sept. 2025, pp. 1–6
2025
-
[13]
Super-resolution of wireless channel characteristics: A multitask learn- ing model,
X. Wang, K. Guan, D. He, Z. Zhang, H. Zhang, J. Dou, and Z. Zhong, “Super-resolution of wireless channel characteristics: A multitask learn- ing model,”IEEE Transactions on Antennas and Propagation, vol. 71, no. 10, pp. 8197–8209, Oct. 2023
2023
-
[14]
Multi-task learning approach for au- tomatic modulation and wireless signal classification,
A. Jagannath and J. Jagannath, “Multi-task learning approach for au- tomatic modulation and wireless signal classification,” inICC 2021 - IEEE International Conference on Communications. IEEE, Jun. 2021, pp. 1–7
2021
-
[15]
AM-FM: A foundation model for ambient intelligence through WiFi,
G. Zhu, Y . Hu, S. Jayaweera, W. Gao, W.-H. Wang, J. Zhang, B. Wang, C. Wu, and K. J. Liu, “AM-FM: A foundation model for ambient intelligence through WiFi,”arXiv preprint arXiv:2602.11200, Feb. 2026
arXiv 2026
-
[16]
Large wireless localization model (LWLM): A foundation model for positioning in 6G networks,
G. Pan, K. Huang, H. Chen, S. Zhang, C. H ¨ager, and H. Wymeersch, “Large wireless localization model (LWLM): A foundation model for positioning in 6G networks,”arXiv preprint arXiv:2505.10134, May 2025
arXiv 2025
-
[17]
A multi-task foundation model for wireless channel representation using contrastive and masked autoen- coder learning,
B. Guler, G. Geraci, and H. Jafarkhani, “A multi-task foundation model for wireless channel representation using contrastive and masked autoen- coder learning,”IEEE Journal on Selected Areas in Communications, vol. 44, pp. 4489–4504, 2026
2026
-
[18]
Addressing the curse of scenario and task generalization in AI-6G: A multi-modal paradigm,
T. Jiao, Z. Xiao, Y . Xu, C. Ye, Y . Huang, Z. Chen, L. Cai, J. Chang, D. He, Y . Guanet al., “Addressing the curse of scenario and task generalization in AI-6G: A multi-modal paradigm,”IEEE Transactions on Wireless Communications, vol. 24, no. 9, pp. 7377–7391, Sept. 2025
2025
-
[19]
Foundation model empowered synesthesia of machines (SoM): AI-native intelligent multi- modal sensing-communication integration,
X. Cheng, B. Liu, X. Liu, E. Liu, and Z. Huang, “Foundation model empowered synesthesia of machines (SoM): AI-native intelligent multi- modal sensing-communication integration,”IEEE Transactions on Net- work Science and Engineering, vol. 13, pp. 762–782, 2026
2026
-
[20]
A survey on self-supervised learning: Algorithms, applications, and future trends,
J. Gui, T. Chen, J. Zhang, Q. Cao, Z. Sun, H. Luo, and D. Tao, “A survey on self-supervised learning: Algorithms, applications, and future trends,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 9052–9071, Dec. 2024. 13
2024
-
[21]
SimMIM: A simple framework for masked image modeling,
Z. Xie, Z. Zhang, Y . Cao, Y . Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu, “SimMIM: A simple framework for masked image modeling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2022, pp. 9653–9663
2022
-
[22]
DropPos: Pre-training vision transformers by reconstructing dropped positions,
H. Wang, J. Fan, Y . Wang, K. Song, T. Wang, and Z.-X. Zhang, “DropPos: Pre-training vision transformers by reconstructing dropped positions,”Advances in Neural Information Processing Systems, vol. 36, pp. 46 134–46 151, Dec. 2023
2023
-
[23]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2020, pp. 9729–9738
2020
-
[24]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 119, Jul. 2020, pp. 1597–1607
2020
-
[25]
Self-supervised learning from images with a joint-embedding predictive architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rab- bat, Y . LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2023, pp. 15 619–15 629
2023
-
[26]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, vol. 1, Jun. 2019, pp. 4171–4186
2019
-
[27]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2022, pp. 16 000–16 009
2022
-
[28]
Masked image modeling: A survey,
V . Hondru, F. A. Croitoru, S. Minaee, R. T. Ionescu, and N. Sebe, “Masked image modeling: A survey,”International Journal of Computer Vision, vol. 133, no. 10, pp. 7154–7200, Oct. 2025
2025
-
[29]
WiMamba: Linear-scale wireless founda- tion model,
T. Raviv and N. Shlezinger, “WiMamba: Linear-scale wireless founda- tion model,”arXiv preprint arXiv:2603.26367, Mar. 2026
arXiv 2026
-
[30]
A wireless foundation model for multi-task prediction,
Y . Sheng, J. Wang, X. Zhou, L. Liang, H. Ye, S. Jin, and G. Y . Li, “A wireless foundation model for multi-task prediction,”arXiv preprint arXiv:2507.05938, Jul. 2025
arXiv 2025
-
[31]
F. O. Catak, M. Kuzlu, and U. Cali, “BERT4MIMO: A foundation model using BERT architecture for massive MIMO channel state information prediction,”arXiv preprint arXiv:2501.01802, Jan. 2025
arXiv 2025
-
[32]
Lwm: A pre-trained wire- less foundation model for universal feature extraction,
S. Alikhani, G. Charan, and A. Alkhateeb, “Lwm: A pre-trained wire- less foundation model for universal feature extraction,” in2025 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN), 2025, pp. 1–6
2025
-
[33]
CSI-MAE: A masked autoencoder-based channel foundation model,
J. Jiang, X. Ruan, and S. Xu, “CSI-MAE: A masked autoencoder-based channel foundation model,”arXiv preprint arXiv:2601.03789, Jan. 2026
arXiv 2026
-
[34]
A comprehensive survey on contrastive learning,
H. Hu, X. Wang, Y . Zhang, Q. Chen, and Q. Guan, “A comprehensive survey on contrastive learning,”Neurocomputing, vol. 610, p. 128645, Dec. 2024
2024
-
[35]
CSI2Vec: Towards a universal CSI feature representation for positioning and channel charting,
V . Palhares, S. Taner, and C. Studer, “CSI2Vec: Towards a universal CSI feature representation for positioning and channel charting,”arXiv preprint arXiv:2506.05237, Jun. 2025
arXiv 2025
-
[36]
WirelessGPT: A generative foundation model for multi-task integrated sensing and communication,
T. Yang, P. Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative foundation model for multi-task integrated sensing and communication,”IEEE Journal on Selected Areas in Com- munications, vol. 44, pp. 2259–2273, 2026
2026
-
[37]
Scalable pre-trained masked channel model of wireless communica- tions,
J. Guo, Z. Deng, Z. Qiao, J. Zhang, J. Xue, D. Niyato, and Z. Xu, “Scalable pre-trained masked channel model of wireless communica- tions,”IEEE Transactions on Communications, vol. 74, pp. 6197–6212, 2026
2026
-
[38]
Radio foundation models: Pre-training transformers for 5G-based indoor localization,
J. Ott, J. Pirkl, M. Stahlke, T. Feigl, and C. Mutschler, “Radio foundation models: Pre-training transformers for 5G-based indoor localization,” in2024 International Conference on Indoor Positioning and Indoor Navigation (IPIN). IEEE, Oct. 2024, pp. 1–6
2024
-
[39]
WiFo: Wireless foundation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless foundation model for channel prediction,”Science China Information Sciences, vol. 68, no. 6, p. 162302, Jun. 2025
2025
-
[40]
C. Zhang, X. Lyu, C. Ren, S. Liu, Q. Cui, and X. Tao, “HeterCSI: Channel-adaptive heterogeneous CSI pretraining framework for gener- alized wireless foundation models,”arXiv preprint arXiv:2601.18200, Jan. 2026
arXiv 2026
-
[41]
AirFM-DDA: Air- interface foundation model in the delay-doppler-angle domain for AI- native 6G,
K. Bian, M. Tao, J. Mo, Z. Chen, and L. Chen, “AirFM-DDA: Air- interface foundation model in the delay-doppler-angle domain for AI- native 6G,”arXiv preprint arXiv:2605.00020, May 2026
Pith/arXiv arXiv 2026
-
[42]
LWM-spectro: A founda- tion model for wireless baseband signal spectrograms,
N. Kim, S. Alikhani, and A. Alkhateeb, “LWM-spectro: A founda- tion model for wireless baseband signal spectrograms,”arXiv preprint arXiv:2601.08780, Jan. 2026
arXiv 2026
-
[43]
SpectrumFM: A foundation model for intelligent spectrum management,
F. Zhou, C. Liu, H. Zhang, W. Wu, Q. Wu, T. Q. S. Quek, and C.- B. Chae, “SpectrumFM: A foundation model for intelligent spectrum management,”IEEE Journal on Selected Areas in Communications, vol. 44, pp. 4471–4488, 2026
2026
-
[44]
IQFM: A wireless foundation model for I/Q streams in AI-native 6G,
O. Mashaal and H. Abou-Zeid, “IQFM: A wireless foundation model for I/Q streams in AI-native 6G,”IEEE Open Journal of the Communi- cations Society, vol. 7, pp. 1426–1441, 2026
2026
-
[45]
Foundation model for intelligent wireless communications,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “Foundation model for intelligent wireless communications,”arXiv preprint arXiv:2511.22222, Nov. 2025
Pith/arXiv arXiv 2025
-
[46]
A wireless world model for AI-native 6G networks,
Z. Chen, Y . Ren, Y . Huang, Q. Sun, N. Li, Y . Huang, Y . Li, L. Xiaet al., “A wireless world model for AI-native 6G networks,”arXiv preprint arXiv:2603.25216, Mar. 2026
arXiv 2026
-
[47]
6G WavesFM: A foundation model for sensing, communication, and localization,
A. Aboulfotouh, E. Mohammed, and H. Abou-Zeid, “6G WavesFM: A foundation model for sensing, communication, and localization,”IEEE Open Journal of the Communications Society, vol. 6, pp. 6792–6807, 2025
2025
-
[48]
MUSE-FM: Multi-task environment-aware foundation model for wireless communications,
T. Zheng, J. Guo, L. Dai, S. Jin, and J. Zhang, “MUSE-FM: Multi-task environment-aware foundation model for wireless communications,” arXiv preprint arXiv:2509.01967, Sept. 2025
arXiv 2025
-
[49]
Comparative analysis of machine learning algorithms for LOS/NLOS identification,
P. Agarwal, R. Kumar, D. K. Jhariya, and M. K. Singh, “Comparative analysis of machine learning algorithms for LOS/NLOS identification,” in2024 First International Conference on Electronics, Communication and Signal Processing (ICECSP). IEEE, 2024, pp. 1–5
2024
-
[50]
A survey of beam management for mmwave and THz communications towards 6G,
Q. Xue, C. Ji, S. Ma, J. Guo, Y . Xu, Q. Chen, and W. Zhang, “A survey of beam management for mmwave and THz communications towards 6G,”IEEE Communications Surveys & Tutorials, vol. 26, no. 3, pp. 1520–1559, Third Quarter 2024
2024
-
[51]
AI model selection and monitoring for beam management in 5G-advanced,
C. Sun, L. Zhao, T. Cui, H. Li, Y . Bai, S. Wu, and Q. Tong, “AI model selection and monitoring for beam management in 5G-advanced,”IEEE Open Journal of the Communications Society, vol. 5, pp. 38–50, Jan. 2024
2024
-
[52]
A survey on integrated sensing and communication with intelligent metasurfaces: Trends, challenges, and opportunities,
A. Magbool, V . Kumar, Q. Wu, M. Di Renzo, and M. F. Flanagan, “A survey on integrated sensing and communication with intelligent metasurfaces: Trends, challenges, and opportunities,” Jan. 2024
2024
-
[53]
Self-supervised contrastive pre-training for time series via time-frequency consistency,
X. Zhang, Z. Zhao, T. Tsiligkaridis, and M. Zitnik, “Self-supervised contrastive pre-training for time series via time-frequency consistency,” Advances in Neural Information Processing Systems, vol. 35, pp. 3988– 4003, Dec. 2022
2022
-
[54]
DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,
A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,” in2019 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, Feb. 2019, pp. 1–8
2019
-
[55]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, Oct. 2020
Pith/arXiv arXiv 2010
-
[56]
Deep learning for mmwave beam and blockage prediction using sub-6 GHz channels,
M. Alrabeiah and A. Alkhateeb, “Deep learning for mmwave beam and blockage prediction using sub-6 GHz channels,”IEEE Transactions on Communications, vol. 68, no. 9, pp. 5504–5518, Sept. 2020
2020
-
[57]
Y . Jin, Y . Li, J. Jiang, Y . Gao, S. Liu, J. Du, Z. Yang, and S. Xu, “Generalizable and robust beam prediction for 6G networks: A deep- learning framework with positioning feature fusion,”arXiv preprint arXiv:2602.09685, Feb. 2026
arXiv 2026
-
[58]
Exploiting semantic local- ization in highly dynamic wireless networks using deep homoscedastic domain adaptation,
L. Chu, A. Alghafis, and A. F. Molisch, “Exploiting semantic local- ization in highly dynamic wireless networks using deep homoscedastic domain adaptation,”IEEE Transactions on Communications, vol. 73, no. 3, pp. 2032–2046, Mar. 2025
2032
-
[59]
Sionna: An open-source library for next-generation physical layer research,
J. Hoydis, S. Cammerer, F. Ait Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,”arXiv preprint arXiv:2203.11854, Mar. 2022
arXiv 2022
-
[60]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.