GPU-First Heisenberg-Picture Tensor Network Dynamics for the 2D Transverse-Field Ising Model
Pith reviewed 2026-07-01 01:14 UTC · model grok-4.3
The pith
A custom device-to-device tensor permutation kernel yields 7.6x faster Trotter steps in a GPU Heisenberg-picture simulator for the 2D Ising model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
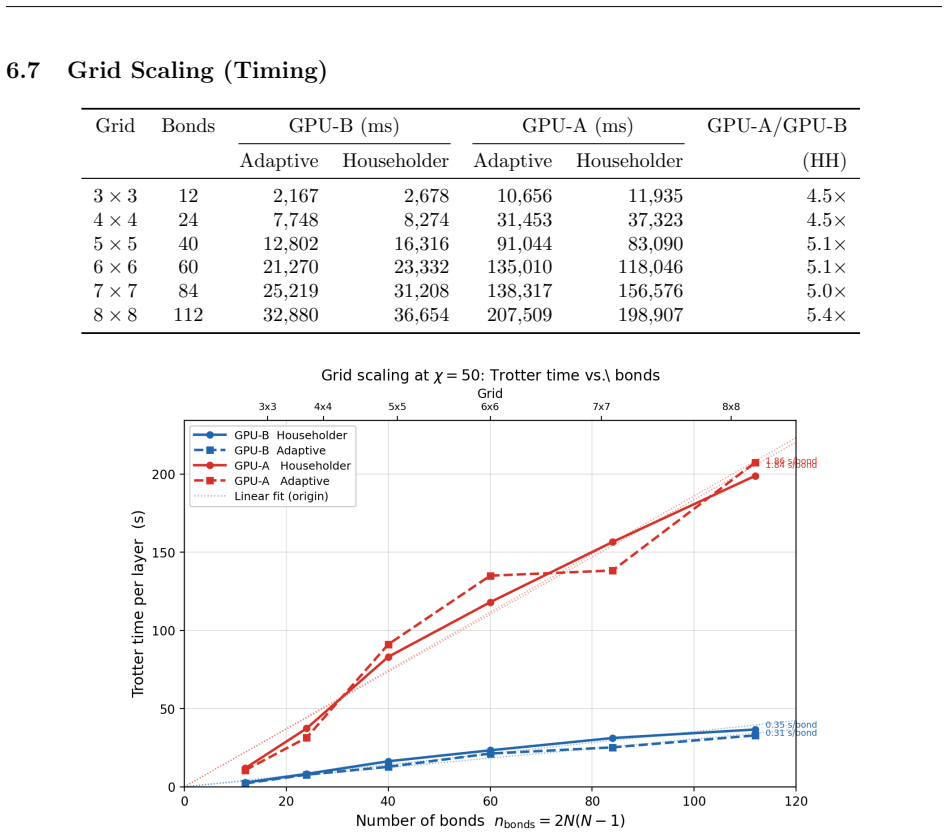
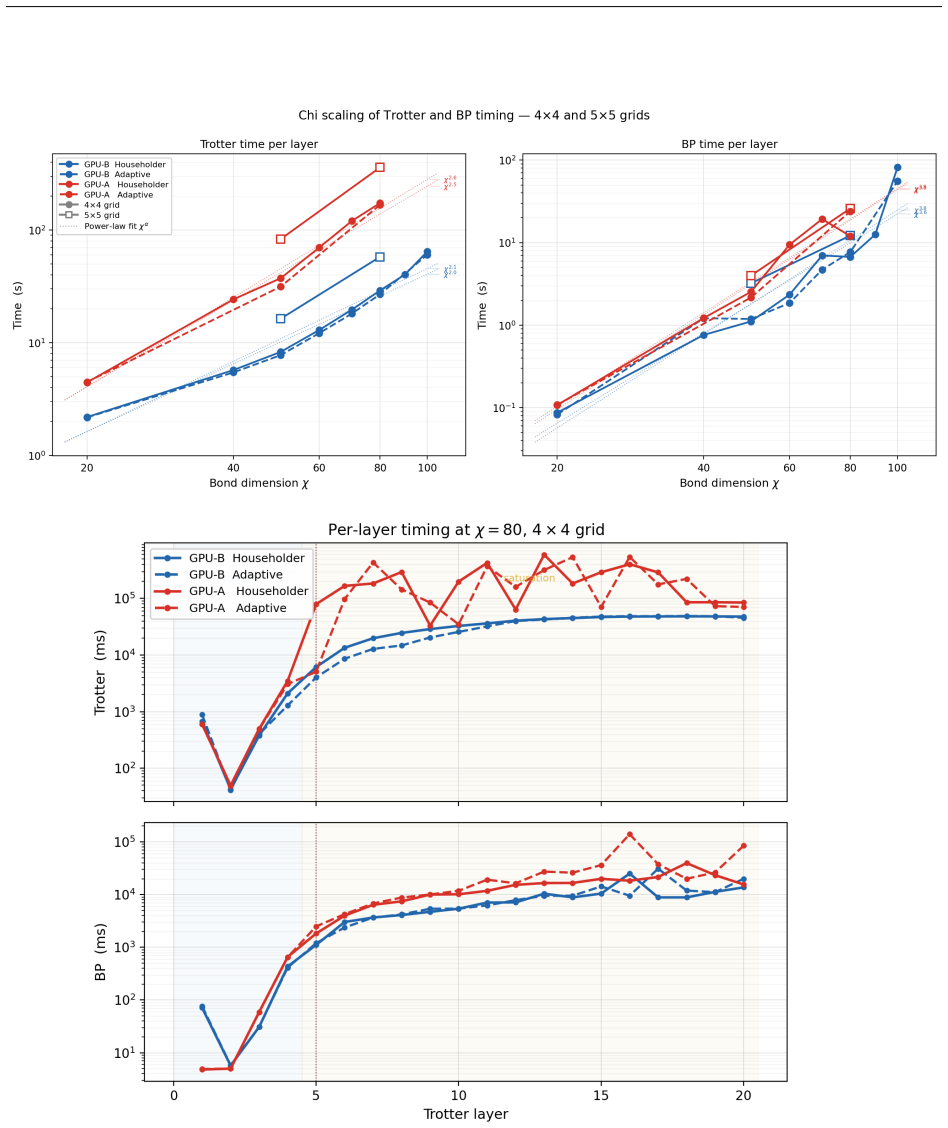
By replacing host-side index shuffling with a device-only permutation kernel, pre-allocating all GPU buffers at launch, switching between Cholesky-QR and Householder-QR according to matrix dimensions, and running adaptive belief propagation with explicit sign tracking, the simulator reaches a 7.6-fold reduction in wall-clock time per Trotter step while keeping the Heisenberg-picture contraction tractable for 2D Ising lattices.
What carries the argument
The custom GPU tensor permutation kernel that executes all index reordering as a device-to-device operation, eliminating host-device transfers during each Trotter layer.
If this is right
- Each Trotter layer completes in roughly one-seventh the time of a host-shuffling baseline.
- Runtime memory allocation overhead disappears because every buffer is reserved once at program start.
- QR factorizations automatically use the cheaper Cholesky route on tall-skinny matrices and Householder otherwise.
- Log-space belief propagation with sign tracking keeps partition-function evaluations stable during contraction.
Where Pith is reading between the lines
- The same zero-malloc and device-only permutation pattern could be reused in other tensor-network codes that currently move data to the CPU for reordering.
- Adaptive belief propagation with tracked signs may reduce the need for periodic re-orthogonalization when bond dimensions grow.
- Because all buffers are fixed at launch, the approach lends itself to deterministic real-time scheduling on GPU clusters.
Load-bearing premise
The listed GPU kernels and adaptive belief-propagation routine will maintain both the reported speed and numerical stability on the intended lattice sizes without any later adjustment or hidden accuracy cost.
What would settle it
Run the same 2D Ising Heisenberg evolution on a 16-by-16 lattice for 20 Trotter steps using both the new code and a reference implementation that still performs host-side permutations, then compare measured time per step and the deviation in local magnetization from an exact small-system benchmark.
Figures

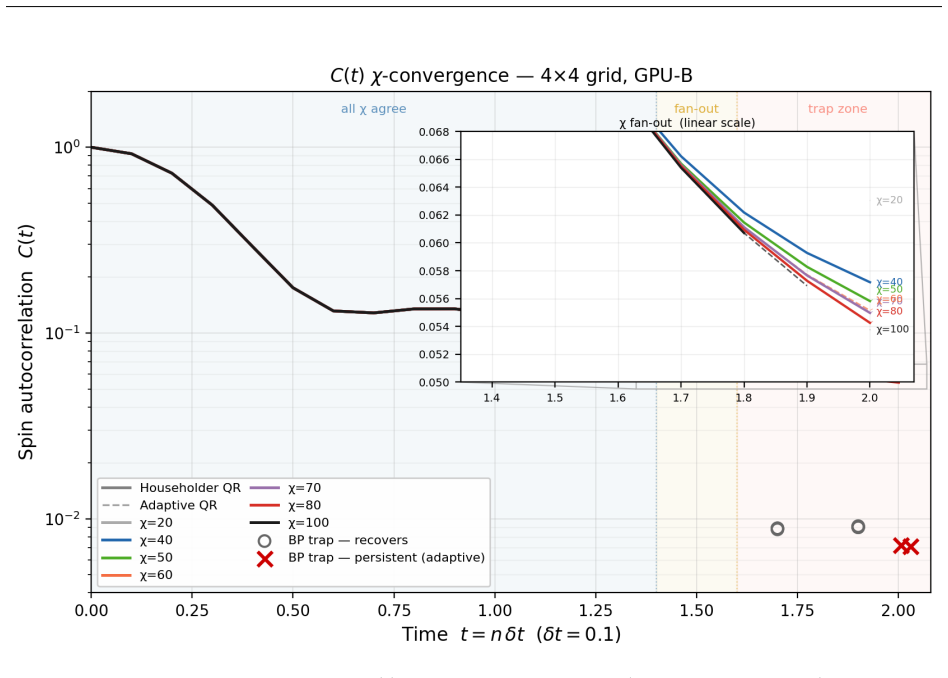
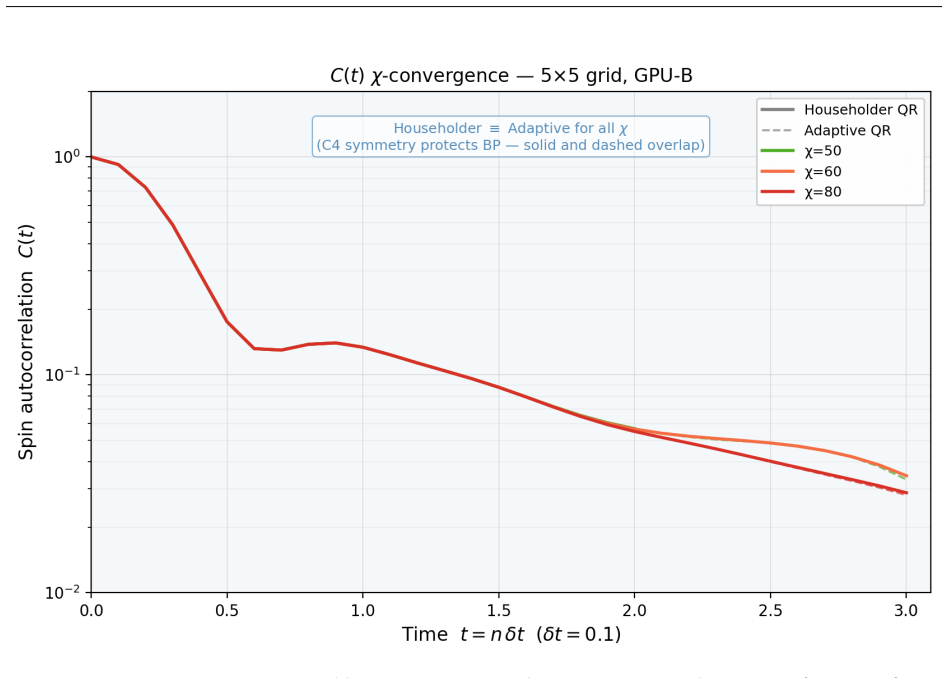
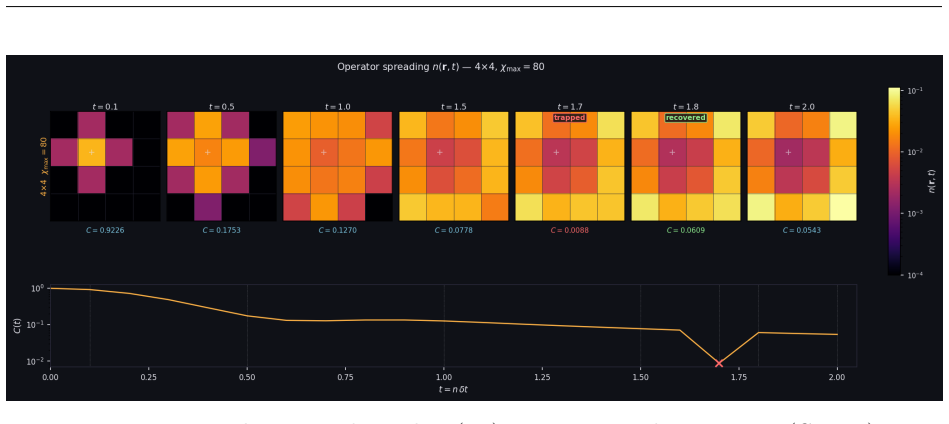
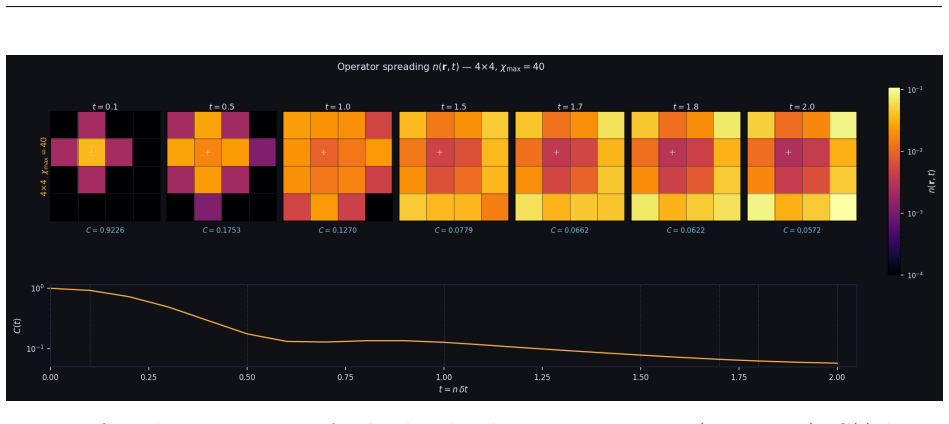
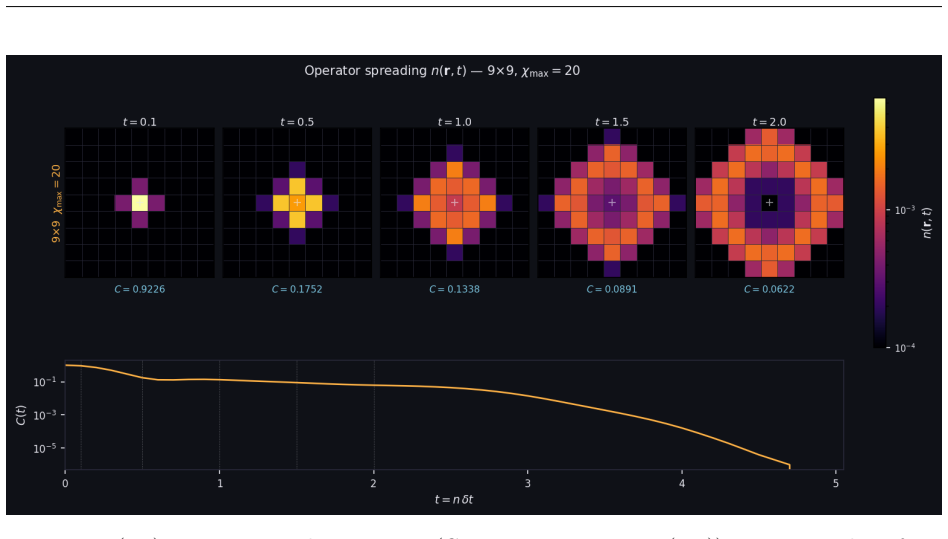
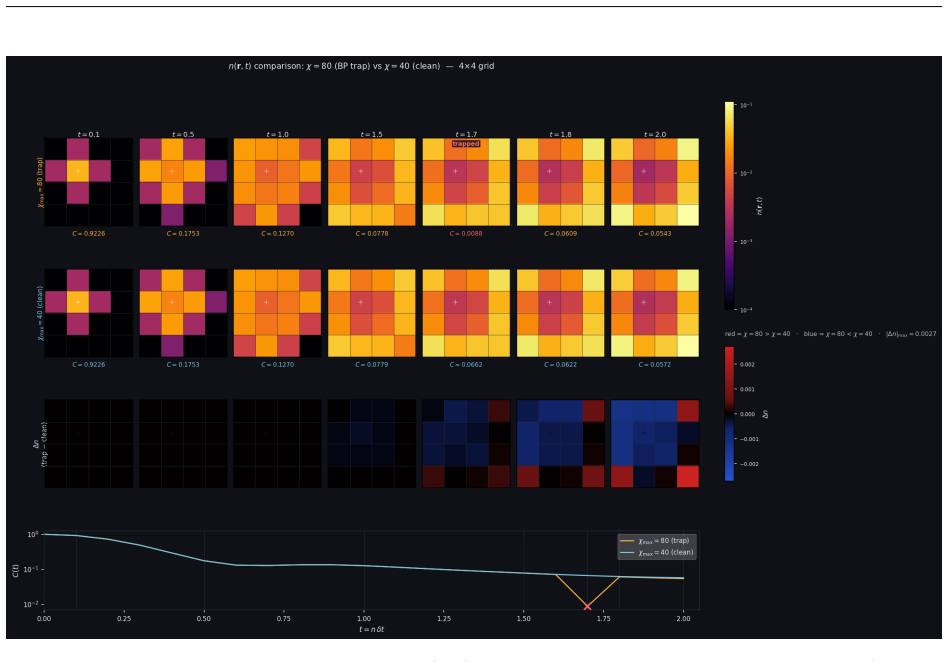
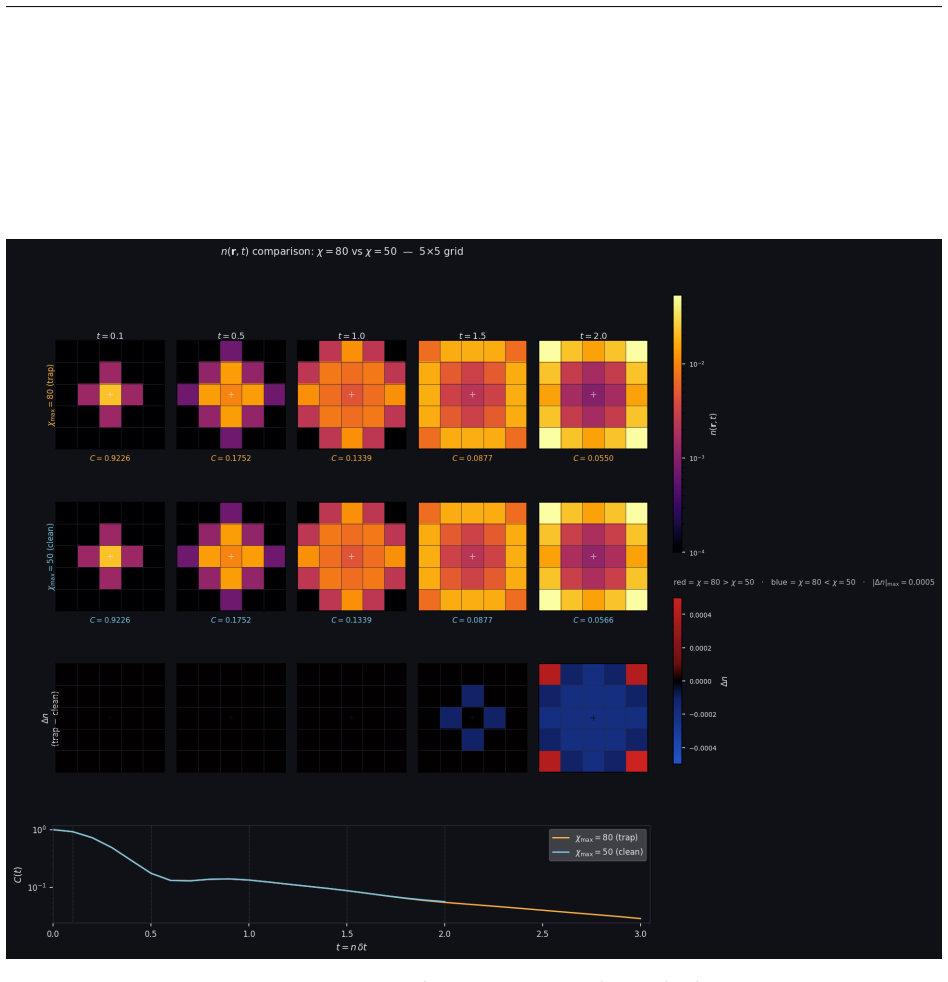
read the original abstract
We present CppSim, a C++/GPU 2D Ising simulator for Heisenberg-picture tensor network time evolution on GPUs. The key computational contributions are: first, a zero-malloc GPU workspace that pre-allocates all buffers at startup; second, a custom GPU tensor permutation kernel replacing host-side index shuffling with a pure device-to-device operation, yielding a 7.6x trotter speedup; third, a hybrid QR strategy selecting Cholesky-QR for tall-skinny matrices and Householder-QR otherwise; fourth, adaptive Belief Propagation with log-space Bethe partition function evaluation and explicit sign tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CppSim, a C++/GPU simulator for Heisenberg-picture tensor network time evolution of the 2D transverse-field Ising model. It describes four implementation optimizations: a zero-malloc GPU workspace pre-allocating buffers at startup, a custom GPU tensor permutation kernel (replacing host-side shuffling with device-to-device operations) claimed to yield a 7.6x Trotter speedup, a hybrid QR strategy (Cholesky-QR for tall-skinny matrices, Householder-QR otherwise), and adaptive Belief Propagation using log-space Bethe partition functions with explicit sign tracking.
Significance. If the performance claims are substantiated with benchmarks and the numerical stability is validated, the work could supply a practical, high-performance tool for simulating 2D quantum spin systems on GPUs, potentially enabling studies of larger lattices or longer evolution times in condensed-matter physics.
major comments (2)
- [Abstract] Abstract: the central claim attributes a specific 7.6x Trotter speedup to the custom GPU tensor permutation kernel, yet the text supplies no benchmarks, error bars, accuracy comparisons, or ablation studies that isolate this kernel's contribution while holding the zero-malloc workspace and hybrid QR fixed; without such data the attribution cannot be verified.
- [Abstract] Abstract: no validation data, error analysis, or comparisons against existing CPU/GPU tensor-network codes are provided, leaving the practical accuracy and stability of the adaptive BP and hybrid QR components unassessed for the target system sizes.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We agree that the performance attribution and numerical validation require stronger supporting data. Below we respond point-by-point and commit to revisions that address the identified gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes a specific 7.6x Trotter speedup to the custom GPU tensor permutation kernel, yet the text supplies no benchmarks, error bars, accuracy comparisons, or ablation studies that isolate this kernel's contribution while holding the zero-malloc workspace and hybrid QR fixed; without such data the attribution cannot be verified.
Authors: We accept the referee's observation. The manuscript states the 7.6x figure but does not present ablation experiments that isolate the permutation kernel while freezing the other three optimizations. We will add a dedicated benchmark section containing timing tables, error bars from repeated runs, and controlled ablations that vary only the permutation implementation. These results will be inserted into both the abstract and the main text. revision: yes
-
Referee: [Abstract] Abstract: no validation data, error analysis, or comparisons against existing CPU/GPU tensor-network codes are provided, leaving the practical accuracy and stability of the adaptive BP and hybrid QR components unassessed for the target system sizes.
Authors: We agree that the current manuscript lacks systematic error analysis and external code comparisons. We will incorporate (i) convergence plots of local observables versus bond dimension and time step, (ii) direct numerical comparisons against established CPU tensor-network libraries on small lattices where exact results are available, and (iii) stability metrics (e.g., norm drift and sign-tracking fidelity) for the adaptive log-space BP and hybrid QR routines at the system sizes reported in the paper. revision: yes
Circularity Check
No circularity: pure implementation description with no derivations or self-referential predictions
full rationale
The paper describes engineering choices for a GPU tensor network simulator (zero-malloc workspace, custom permutation kernel, hybrid QR, adaptive BP) and reports an empirical 7.6x speedup. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The performance attribution is presented as a direct outcome of the listed kernels rather than derived from any self-referential structure or prior self-citation. This is a standard non-circular outcome for a software-engineering manuscript.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Or´ us. A practical introduction to tensor networks: Matrix product states and projected entangled pair states.Annals of Physics, 349:117–158, 2014
2014
-
[2]
G. Vidal. Efficient classical simulation of slightly entangled quantum computations.Physical Review Letters, 91(14):147902, 2003
2003
-
[3]
G. Vidal. Efficient simulation of one-dimensional quantum many-body systems.Physical Review Letters, 93(4):040502, 2004. doi:10.1103/PhysRevLett.93.040502
-
[4]
GPU BLAS library.https://github.com/GPUruntimeSoftwarePlatform/ BLAS, 2024
GPU runtime. GPU BLAS library.https://github.com/GPUruntimeSoftwarePlatform/ BLAS, 2024
2024
-
[5]
GPU LAPACK library.https://github.com/GPUruntimeSoftwarePlatform/ LAPACK, 2024
GPU runtime. GPU LAPACK library.https://github.com/GPUruntimeSoftwarePlatform/ LAPACK, 2024
2024
-
[6]
Sachdev.Quantum Phase Transitions
S. Sachdev.Quantum Phase Transitions. Cambridge University Press, Cambridge, 2nd edition,
-
[7]
doi:10.1017/CBO9780511973765
-
[8]
M. Suzuki. Generalized Trotter’s formula and systematic approximants of exponential opera- tors.Communications in Mathematical Physics, 51(2):183–190, 1976
1976
-
[9]
G. H. Golub and C. F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4th edition, 2013. ISBN 9781421407944
2013
- [10]
-
[11]
J. Tindall and M. Fishman. Gauging tensor networks with belief propagation.SciPost Physics, 15:222, 2023. doi:10.21468/SciPostPhys.15.6.222
-
[12]
J. S. Yedidia, W. T. Freeman, and Y. Weiss. Constructing free-energy approximations and gen- eralized belief propagation algorithms.IEEE Transactions on Information Theory, 51(7):2282– 2312, 2005. doi:10.1109/TIT.2005.850085
-
[13]
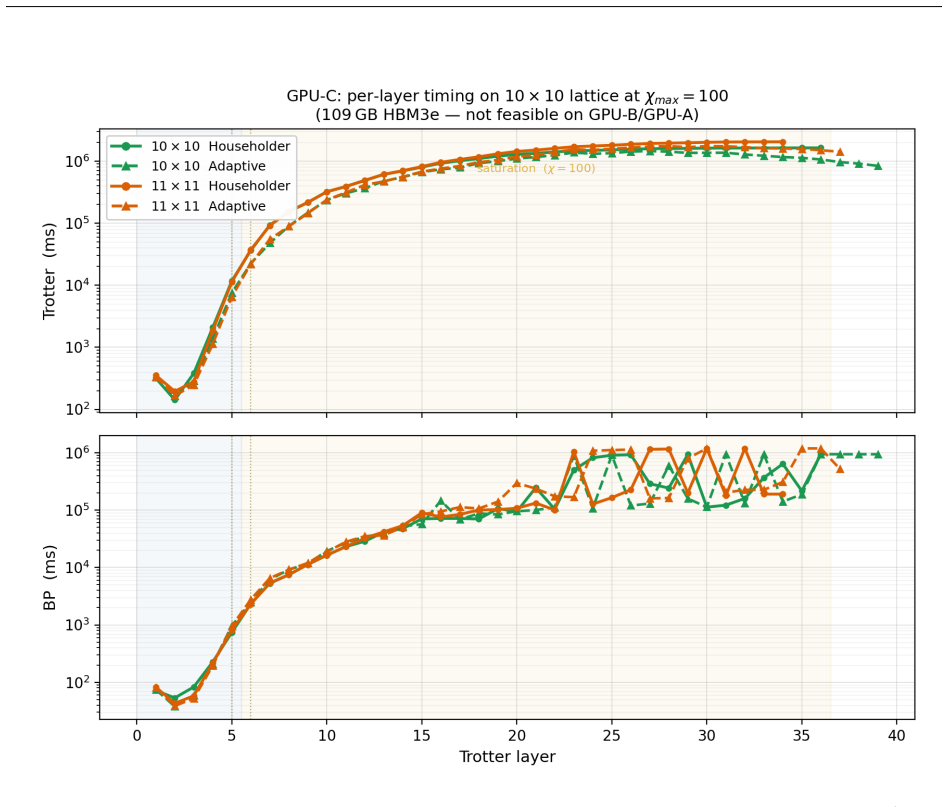
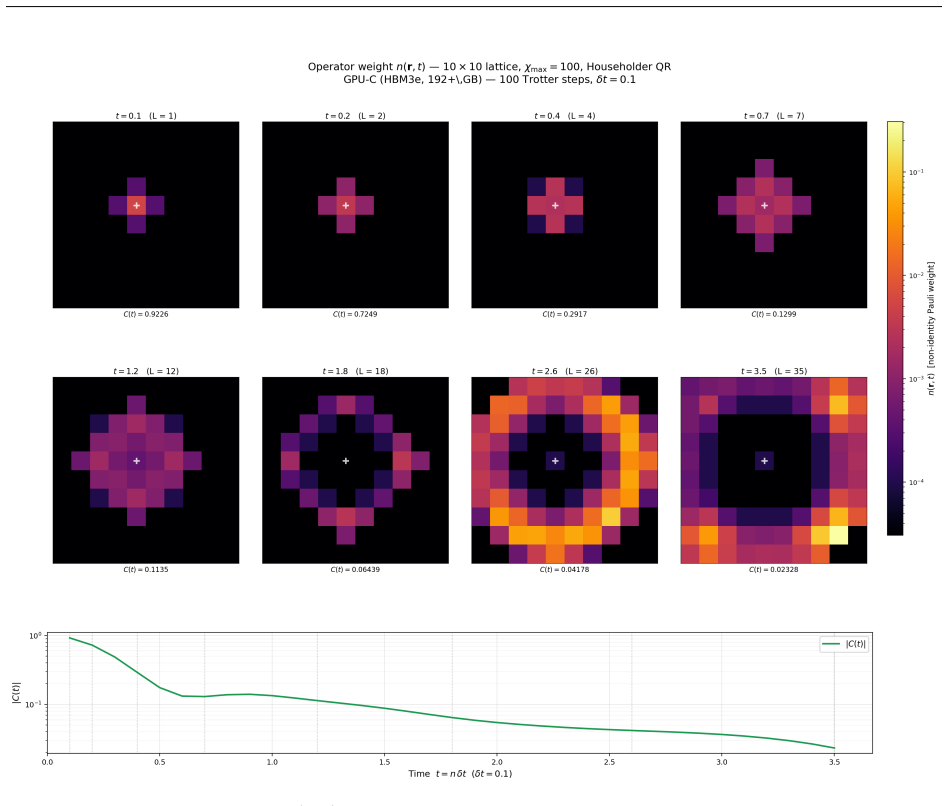
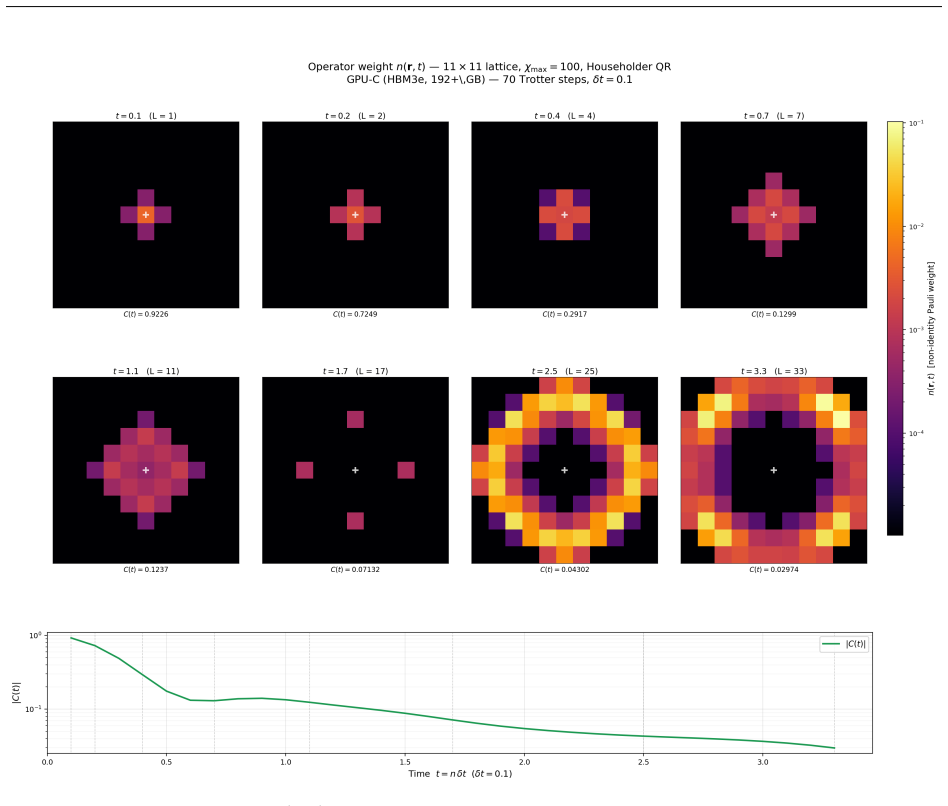
E. H. Lieb and D. W. Robinson. The finite group velocity of quantum spin systems.Commu- nications in Mathematical Physics,28:251–257, 1972. A High-Bandwidth Memory Regime: Adaptive QR and Large- Scale Simulations Section 8 established thatCppSimoperates in the memory-bandwidth-bound regime atχ≤100 on 4×4 grids, where algorithm choice (Householder vs. Chol...
1972
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.