AC²P²SL: Adaptive Communication-Computation Pipeline Parallel Split Learning over Edge Networks
Pith reviewed 2026-07-01 03:37 UTC · model grok-4.3
The pith
By treating communication and computation as stages in one pipeline, AC²P²SL overlaps their work across micro-batches to shorten split learning training time on edge networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
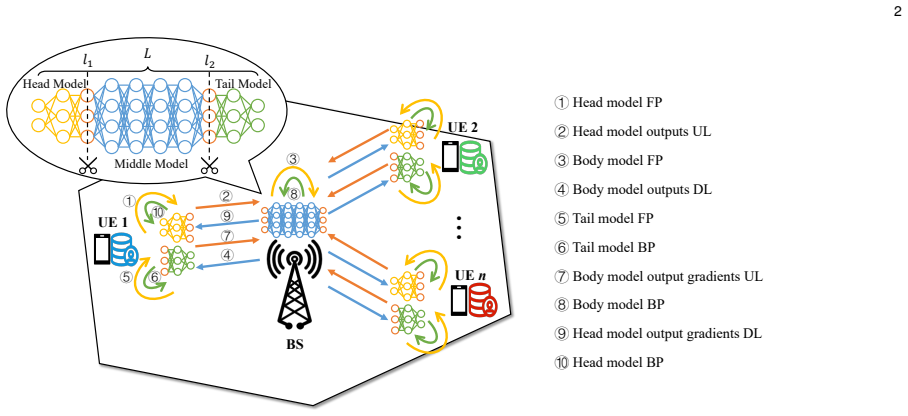
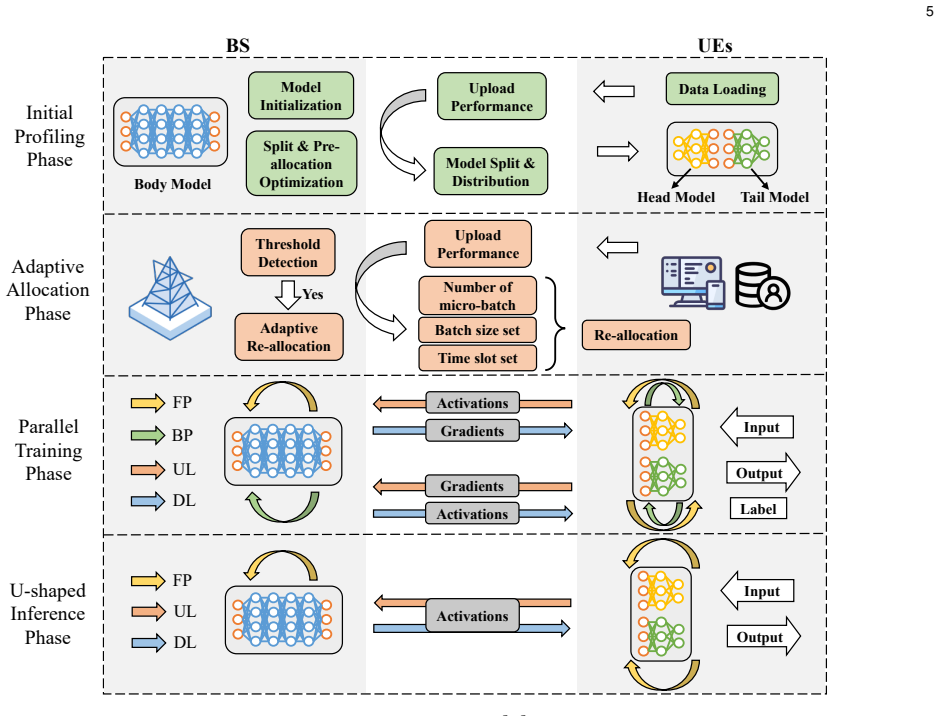
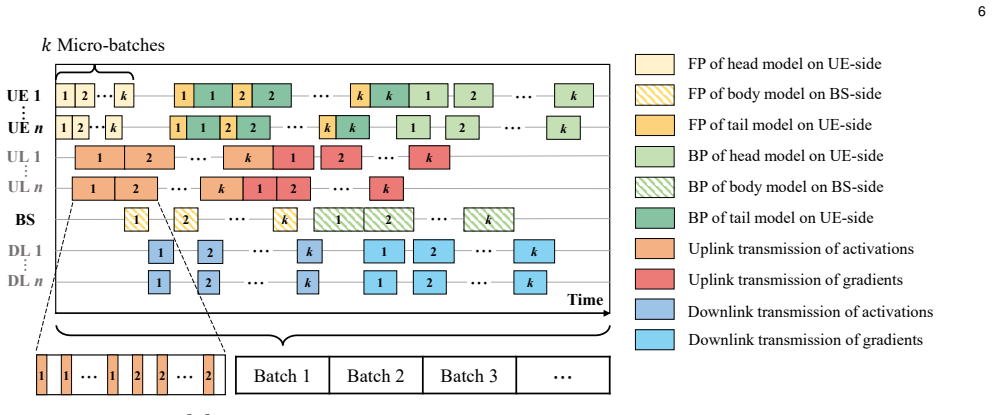
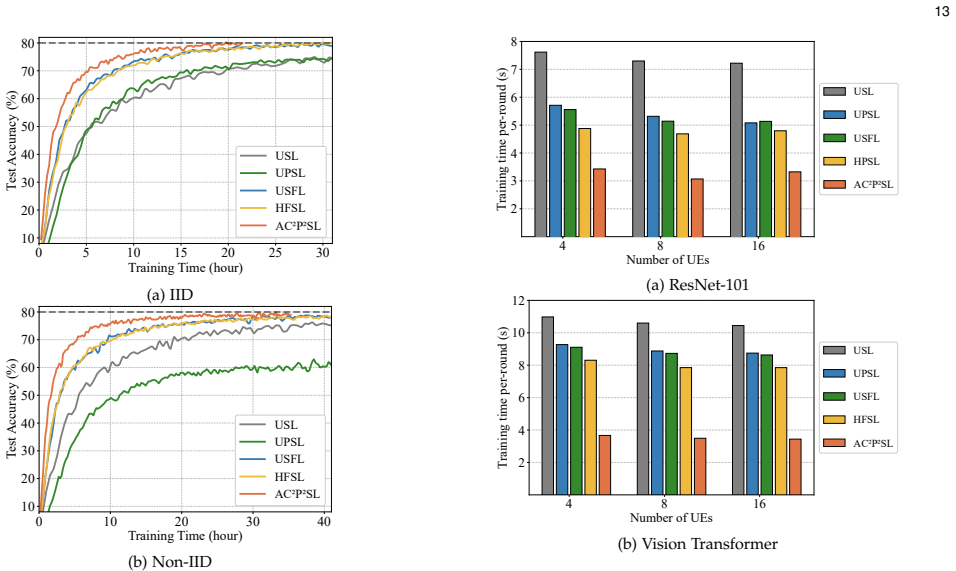
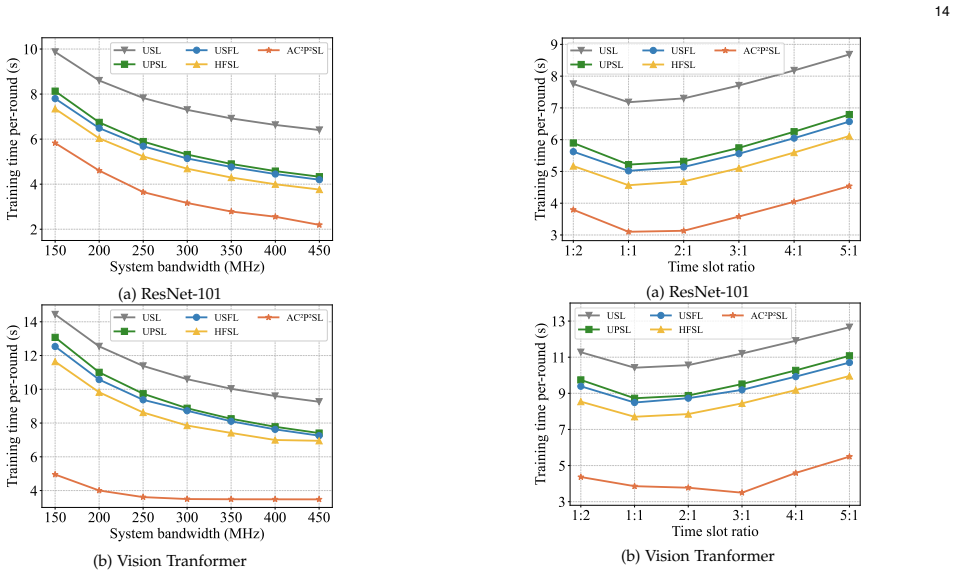
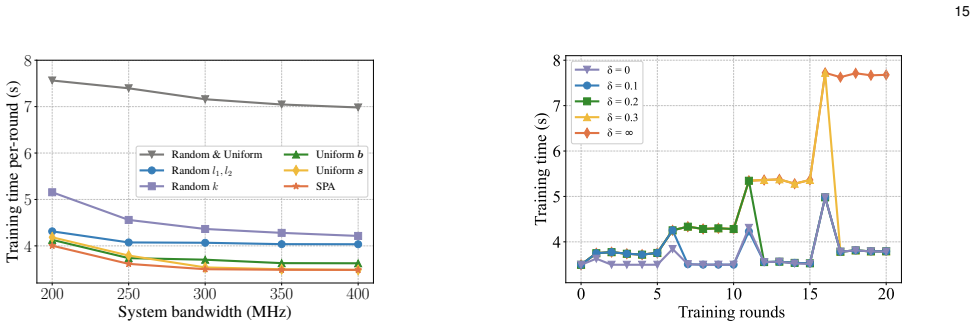
The paper claims that conceptualizing the communication and computation processes of UEs and the BS as a unified pipeline achieves fine-grained pipeline parallelism across multiple micro-batches. This enables effective overlapping of communication and computation, resulting in significant reduction of overall training latency. A joint optimization problem is formulated to minimize training time under communication, computation, and storage constraints plus UE heterogeneity, and solved by a split and pre-allocation algorithm. An adaptive re-allocation strategy is designed for dynamic UE environments, with experiments confirming reduced training time while preserving data privacy.
What carries the argument
The unified pipeline that overlaps communication and computation processes across micro-batches, optimized by a split and pre-allocation algorithm plus adaptive re-allocation.
If this is right
- Overlapping communication and computation across micro-batches reduces overall training latency.
- The split and pre-allocation algorithm improves pipeline efficiency while satisfying communication, computation, and storage constraints.
- The adaptive re-allocation strategy sustains performance when user equipment conditions vary over time.
- Data privacy remains protected throughout the collaborative training process.
Where Pith is reading between the lines
- The same pipeline idea could apply to other distributed tasks on edge devices, such as serving models or running inference workloads.
- Pre-allocation rules that account for device heterogeneity may help resource schedulers in broader mobile edge computing scenarios.
- Evaluating the adaptive strategy on hardware testbeds that include real device movement would test its behavior beyond simulation.
Load-bearing premise
The joint optimization problem can be solved effectively by the proposed split and pre-allocation algorithm, and the adaptive re-allocation strategy will maintain performance when UE conditions change.
What would settle it
A side-by-side experiment that measures end-to-end training time for the same model and data using both conventional sequential split learning and AC²P²SL under identical network and device conditions; if the pipeline version shows no measurable latency reduction, the central claim is falsified.
Figures
read the original abstract
In wireless edge networks, split learning (SL) enables base station (BS) to utilize the distributed data and computing power across user equipments (UEs) to achieve collaborative model training while protecting local data privacy. However, the inherent sequential execution of computation and communication processes in conventional SL usually leads to long training times. To overcome this limitation, this paper proposes an adaptive communication-computation pipeline parallel split learning (AC$^2$P$^2$SL) framework. By conceptualizing the communication and computation processes of UEs and the BS as a unified pipeline, AC$^2$P$^2$SL achieves fine-grained pipeline parallelism across multiple micro-batches. Through this approach, effective overlapping of communication and computation is achieved which results in significant reduction of the overall training latency. Moreover, by considering the system constraints in the communication, computation, and storage dimensions as well as the heterogeneity of UEs, we formulate a joint optimization problem to minimize the training time and propose a corresponding split and pre-allocation algorithm to further enhance the pipeline efficiency. Additionally, accounting for the practical dynamic environments for the UEs, we design an adaptive re-allocation strategy to enhance the system resilience. Extensive experimental results demonstrate the effectiveness and robustness of AC$^2$P$^2$SL in reducing training time while ensuring data privacy preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the AC²P²SL framework for split learning over wireless edge networks. It conceptualizes communication and computation at UEs and the BS as a unified pipeline to enable fine-grained parallelism across micro-batches, overlapping these processes to reduce overall training latency. A joint optimization problem is formulated to minimize training time subject to communication, computation, and storage constraints plus UE heterogeneity; this is solved by a split and pre-allocation algorithm. An adaptive re-allocation strategy is added to handle dynamic environments. Experimental results are claimed to demonstrate effectiveness and robustness while preserving data privacy.
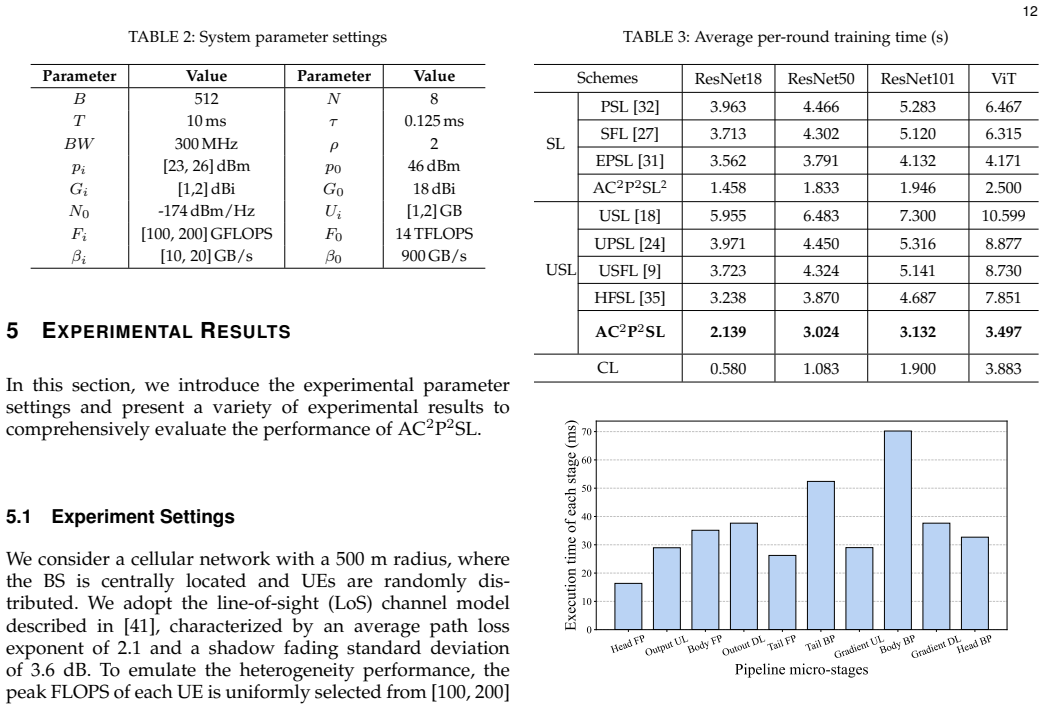
Significance. If the results hold, the work offers a concrete systems approach to a key practical bottleneck in distributed ML on edges by enabling pipeline parallelism under realistic constraints. The formulation of the problem as a mixed-integer program solved by a polynomial-time heuristic, together with validation on reported traces and the adaptive strategy for dynamics, are strengths that enhance applicability. This could meaningfully improve latency in privacy-preserving collaborative training scenarios.
minor comments (2)
- [Abstract] Abstract: the claim of 'extensive experimental results' demonstrating effectiveness would benefit from a brief parenthetical mention of the key metrics (e.g., latency reduction percentages) and baselines used, even if full details appear later.
- The optimization formulation section would be clearer if the decision variables for micro-batch split points versus resource pre-allocation were given distinct symbols from the outset to prevent any notational overlap.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review of our manuscript on the AC²P²SL framework. The recommendation for minor revision is noted, and we will incorporate any suggested improvements in the revised version. No specific major comments were listed in the report.
Circularity Check
No significant circularity identified
full rationale
The manuscript formulates the core problem as a mixed-integer program over communication, computation and storage constraints, then solves it via an explicit polynomial-time heuristic (split and pre-allocation) whose output is validated on external traces rather than by construction. No equation is shown to equal its own fitted parameter, no uniqueness theorem is imported from self-citation, and the adaptive re-allocation step is described as an online adjustment rule independent of the offline optimum. The derivation chain therefore remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-computation pipeline parallel split learning over wireless edge networks,
C. Liu, Z. Zhang, Z. Chenet al., “Communication-computation pipeline parallel split learning over wireless edge networks,” in Proc. IEEE Globecom Workshops (GC Wkshps), 2025 (presented)
2025
-
[2]
Towards wireless native big AI model: The mission and approach differ from large language model,
Z. Chen, Z. Zhang, C. Liuet al., “Towards wireless native big AI model: The mission and approach differ from large language model,”Sci. China Inf. Sci., vol. 68, no. 7, p. 170303, 2025
2025
-
[3]
Distributed learning in wireless networks: Recent progress and future challenges,
M. Chen, D. G ¨und ¨uz, K. Huanget al., “Distributed learning in wireless networks: Recent progress and future challenges,”IEEE J. Sel. Areas Commun., vol. 39, no. 12, pp. 3579–3605, 2021
2021
-
[4]
Real-time health monitoring for athletes in dynamic sports environments based on split federated learning and recurrent neural networks,
L. Tao and H. Li, “Real-time health monitoring for athletes in dynamic sports environments based on split federated learning and recurrent neural networks,”IEEE T rans. Consum. Electron., vol. 71, no. 3, pp. 8956–8967, 2025
2025
-
[5]
A novel split learning-based consumer electronics network traffic anomaly detection framework for smart city environment,
D.-J. Kim, N. G. B. Amma, and V . Sarveshwaran, “A novel split learning-based consumer electronics network traffic anomaly detection framework for smart city environment,”IEEE T rans. Consum. Electron., vol. 70, no. 1, pp. 4197–4204, 2024
2024
-
[6]
Wireless distributed learning: A new hybrid split and federated learning approach,
X. Liu, Y. Deng, and T. Mahmoodi, “Wireless distributed learning: A new hybrid split and federated learning approach,”IEEE J. Sel. Areas Commun., vol. 22, no. 4, pp. 2650–2665, 2023
2023
-
[7]
Adaptive U-shaped split federated learning for image coding at resource-constrained UAV network,
Q. Sun, C. Guo, Y. Yanget al., “Adaptive U-shaped split federated learning for image coding at resource-constrained UAV network,” IEEE Internet Things J., vol. 13, no. 4, pp. 5569–5582, 2026
2026
-
[8]
Split federated learning for real-time aerial video event recognition in UAV-based geospatial monitoring,
W. Ullah, F. Outay, L. U. Khanet al., “Split federated learning for real-time aerial video event recognition in UAV-based geospatial monitoring,”IEEE T rans. Geosci. Remote Sens., vol. 64, pp. 1–11, 2026
2026
-
[9]
Model partition and resource allocation for split learning in vehicular edge networks,
L. Yu, Z. Chang, Y. Jiaet al., “Model partition and resource allocation for split learning in vehicular edge networks,”IEEE T rans. Intell. T ransport. Syst., vol. 26, no. 10, pp. 17 851–17 865, 2025
2025
-
[10]
Adaptive and parallel split federated learning in vehicular edge computing,
X. Qiang, Z. Chang, Y. Huet al., “Adaptive and parallel split federated learning in vehicular edge computing,”IEEE Internet Things J., vol. 12, no. 5, pp. 4591–4604, 2025
2025
-
[11]
Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,
Z. Chen, Z. Zhang, and Z. Yang, “Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,” IEEE Wireless Commun., vol. 31, no. 5, pp. 164–172, 2024
2024
-
[12]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighanet al., “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
Wireless distributed edge learning: How many edge devices do we need?
J. Song and M. Kountouris, “Wireless distributed edge learning: How many edge devices do we need?”IEEE J. Sel. Areas Commun., vol. 39, no. 7, pp. 2120–2134, 2021
2021
-
[14]
HiveMind: Towards cellular native machine learning model splitting,
S. Wang, X. Zhang, H. Uchiyamaet al., “HiveMind: Towards cellular native machine learning model splitting,”IEEE J. Sel. Areas Commun., vol. 40, no. 2, pp. 626–640, 2022
2022
-
[15]
H-infinity tracking for intelligent edge-controlled systems over fading channels in AI-RAN,
M. Tang, C. Feng, G. Minet al., “H-infinity tracking for intelligent edge-controlled systems over fading channels in AI-RAN,”IEEE T rans. Veh. T echnol., vol. 75, no. 4, pp. 6916–6921, 2026
2026
-
[16]
AI-RAN: Transforming RAN with AI-driven computing infrastructure,
L. Kundu, X. Lin, R. Gadiyaret al., “AI-RAN: Transforming RAN with AI-driven computing infrastructure,”IEEE Commun. Mag., vol. 64, no. 1, pp. 168–174, 2026
2026
-
[17]
Pipelining split learning in multi-hop edge networks,
W. Wei, Z. Lin, T. Liet al., “Pipelining split learning in multi-hop edge networks,”arXiv preprint arXiv:2505.04368, 2025
-
[18]
Split learning for health: Distributed deep learning without sharing raw patient data
P . Vepakomma, O. Gupta, T. Swedishet al., “Split learning for health: Distributed deep learning without sharing raw patient data,”arXiv preprint, arXiv:1812.00564, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Split learning on segmented health- care data,
L. Hu, T. Zhou, Z. Liuet al., “Split learning on segmented health- care data,”IEEE T rans. Big Data, vol. 11, no. 5, pp. 2749–2763, 2025
2025
-
[20]
Dynamic corrected split federated learning with homomorphic encryption for U-shaped medical image networks,
Z. Yang, Y. Chen, H. Huangfuet al., “Dynamic corrected split federated learning with homomorphic encryption for U-shaped medical image networks,”IEEE J. Biomed. Health Inform., vol. 27, no. 12, pp. 5946–5957, 2023
2023
-
[21]
Split learning in 6G edge networks,
Z. Lin, G. Qu, X. Chenet al., “Split learning in 6G edge networks,” IEEE Wireless Commun., vol. 31, no. 4, pp. 170–176, 2024
2024
-
[22]
Robust split federated learning for U-shaped medical image networks,
Z. Yang, Y. Chen, H. Huangfuet al., “Robust split federated learning for U-shaped medical image networks,”arXiv preprint arXiv:2212.06378, 2022
-
[23]
Z. Chen, Z. Zhang, Z. Xinget al., “Analogical learning for cross- scenario generalization: Framework and application to intelligent localization,”arXiv preprint arXiv:2504.08811, 2025
-
[24]
Optimal resource allocation for U- shaped parallel split learning,
S. Lyu, Z. Lin, G. Quet al., “Optimal resource allocation for U- shaped parallel split learning,” inProc. IEEE Globecom Workshops (GC Wkshps), 2023, pp. 197–202
2023
-
[25]
SplitMAC: Wireless split learning over multiple access channels,
S. Kim, Y. Oh, and Y.-S. Jeon, “SplitMAC: Wireless split learning over multiple access channels,”IEEE T rans. Wireless Commun., vol. 23, no. 12, pp. 19 760–19 775, 2024
2024
-
[26]
SplitFed: When federated learning meets split learning,
C. Thapa, M. Chamikara, S. Camtepeet al., “SplitFed: When federated learning meets split learning,” inProc. AAAI Conf. Artif. Intell., 2022, pp. 8485–8493
2022
-
[27]
Accelerating split federated learning over wireless communication networks,
C. Xu, J. Li, Y. Liuet al., “Accelerating split federated learning over wireless communication networks,”IEEE T rans. Wireless Commun., vol. 23, no. 6, pp. 5587–5599, 2024
2024
-
[28]
PipeSFL: A fine-grained parallelization framework for split federated learning on hetero- geneous clients,
Y. Gao, B. Hu, M. B. Mashhadiet al., “PipeSFL: A fine-grained parallelization framework for split federated learning on hetero- geneous clients,”IEEE T rans. Mobile Comput., vol. 24, no. 3, pp. 1774–1791, 2025
2025
-
[29]
Split learning over wireless networks: Parallel design and resource management,
W. Wu, M. Li, K. Quet al., “Split learning over wireless networks: Parallel design and resource management,”IEEE J. Sel. Areas Commun., vol. 41, no. 4, pp. 1051–1066, 2023
2023
-
[30]
Server-side local gradient aver- aging and learning rate acceleration for scalable split learning,
S. Pal, M. Uniyal, J. Parket al., “Server-side local gradient aver- aging and learning rate acceleration for scalable split learning,” arXiv preprint arXiv:2112.05929, 2021
-
[31]
Efficient parallel split learning over resource-constrained wireless edge networks,
Z. Lin, G. Zhu, Y. Denget al., “Efficient parallel split learning over resource-constrained wireless edge networks,”IEEE T rans. Mobile Comput., vol. 23, no. 10, pp. 9224–9239, 2024
2024
-
[32]
P . Joshi, C. Thapa, S. Camtepeet al., “Splitfed learning with- out client-side synchronization: Analyzing client-side split net- work portion size to overall performance,”arXiv preprint arXiv:2109.09246, 2021
-
[33]
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Y. Huang, Y. Cheng, A. Bapnaet al., “GPipe: Efficient training of giant neural networks using pipeline parallelism,”arXiv preprint, arXiv:1811.06965, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Wireless model splitting for communication-efficient personalized federated learning with pipeline parallelism,
L. Wang, Y. Dong, L. Zhanget al., “Wireless model splitting for communication-efficient personalized federated learning with pipeline parallelism,” inProc. IEEE 24th Int. Workshop Signal Pro- cess. Adv. Wireless Commun. (SP AWC), 2023, pp. 421–425
2023
-
[35]
Predictive GAN-powered multi- objective optimization for hybrid federated split learning,
B. Yin, Z. Chen, and M. Tao, “Predictive GAN-powered multi- objective optimization for hybrid federated split learning,”IEEE T rans. Commun., vol. 71, no. 8, pp. 4544–4560, 2023
2023
-
[36]
An instruction roofline model for GPUs,
N. Ding and S. Williams, “An instruction roofline model for GPUs,” inProc. IEEE/ACM Perform. Model., Benchmark. Simul. High Preform. Comput. Syst. (PMBS), 2019, pp. 7–18
2019
-
[37]
Mini-batch gradient descent: Faster convergence under data sparsity,
S. Khirirat, H. R. Feyzmahdavian, and M. Johansson, “Mini-batch gradient descent: Faster convergence under data sparsity,” inProc. IEEE 56th Annu. Conf. Decis. Control (CDC), 2017, pp. 2880–2887
2017
-
[38]
Communication- efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramageet al., “Communication- efficient learning of deep networks from decentralized data,” in Proc. Int. Conf. Artif. Intell. Statist., 2017, pp. 1273–1282
2017
-
[39]
Convergence of alternating optimization,
J. C. Bezdek and R. J. Hathaway, “Convergence of alternating optimization,”Dynamic Publishers, Inc., vol. 11, no. 4, pp. 351–368, 2003
2003
-
[40]
CVXPY: A Python-embedded modeling language for convex optimization,
S. Diamond and S. Boyd, “CVXPY: A Python-embedded modeling language for convex optimization,”J. Mach. Learn. Res., vol. 17, no. 83, pp. 1–5, 2016
2016
-
[41]
Probabilis- tic omnidirectional path loss models for millimeter-wave outdoor communications,
M. K. Samimi, T. S. Rappaport, and G. R. MacCartney, “Probabilis- tic omnidirectional path loss models for millimeter-wave outdoor communications,”IEEE Wireless Commun. Lett., vol. 4, no. 4, pp. 357–360, 2015
2015
-
[42]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socheret al., “ImageNet: A large-scale hierarchical image database,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 248–255
2009
-
[43]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Renet al., “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778
2016
-
[44]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikovet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.