SERF: Spatiotemporal Environment and Robot Feature Map for Long-Horizon Mobile Manipulation
Pith reviewed 2026-06-27 06:37 UTC · model grok-4.3
The pith
Conditioning a mobile manipulation policy on a spatiotemporal feature map improves reasoning over long horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
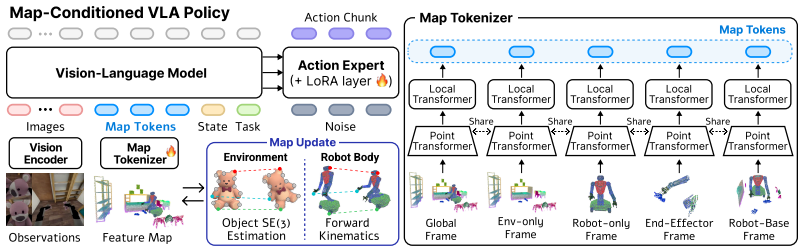
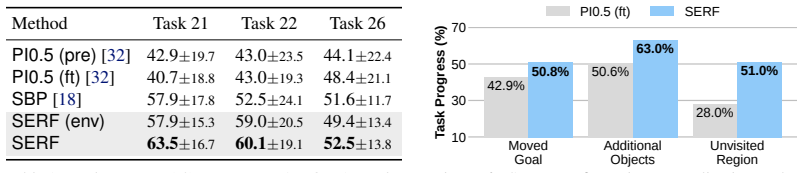
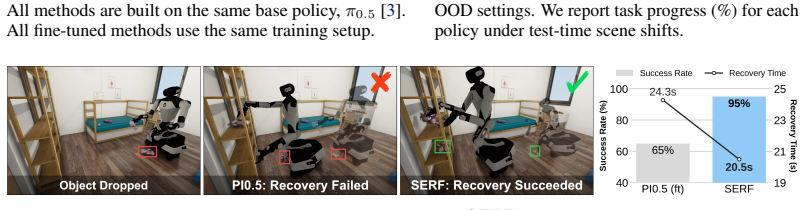
The central claim is that the SERF map, formed by neural points for environment and robot in one latent space and maintained from egocentric observations plus proprioception via object-level rigid tracking and forward kinematics, supplies map tokens at multiple reference frames and spatial scales to a VLA policy; on the BEHAVIOR-1K benchmark this yields higher success than image-only baselines, faster subgoal achievement through straighter paths, greater robustness to scene shifts, and improved recovery after object drops.
What carries the argument
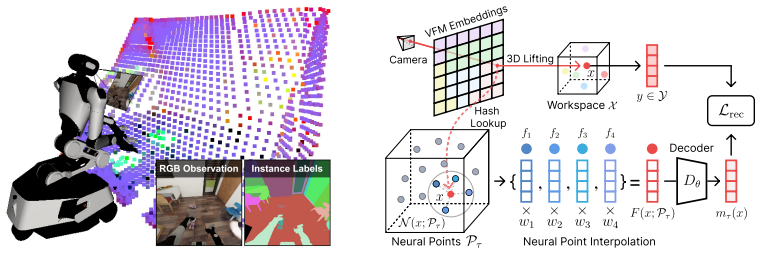
SERF map: shared latent space of neural points representing environment and articulated robot body, updated online with rigid tracking for objects and forward kinematics for the robot, then tokenized at multiple scales and frames for policy input.
If this is right
- The policy reaches subgoals faster by following more direct trajectories.
- Performance improves under shifts in scene configuration.
- Recovery succeeds more often after object-drop failures.
- The map supplies both local detail and global context through multi-frame, multi-scale token extraction.
Where Pith is reading between the lines
- The shared latent space for environment and robot points could support policies that explicitly reason about self-body collisions during manipulation.
- If rigid tracking remains stable, the same map structure might extend to tasks requiring persistent object memory across room transitions.
- Extracting tokens at varying spatial scales suggests the method could be combined with hierarchical planning that operates at different resolutions.
Load-bearing premise
The neural points updated via object-level rigid tracking and forward kinematics from egocentric observations and proprioceptive state accurately represent the environment and articulated robot body.
What would settle it
A controlled test on BEHAVIOR-1K where the SERF-conditioned VLA policy shows no performance gain over image-only baselines, or fails to recover from object drops at the same rate, would falsify the improvement in long-horizon reasoning.
Figures








read the original abstract
Long-horizon robot mobile manipulation requires continual reasoning about localization, environment changes, and task progress, all of which are challenging to infer from image observations alone. In this paper, we show that conditioning a mobile manipulation policy on a spatiotemporal feature map improves reasoning over long horizons. The map represents the environment and the articulated robot body as neural points in a shared latent space and is updated online from egocentric observations and proprioceptive state. We update the environment neural points using object-level rigid tracking and the robot neural points using forward kinematics. We use our spatiotemporal environment and robot feature (SERF) map as a state input to a vision-language-action (VLA) model by extracting map tokens from multiple reference frames and spatial scales, providing the policy with both local and global context. We demonstrate SERF on BEHAVIOR-1K, a benchmark for long-horizon mobile manipulation in household environments. Experiments show that the SERF VLA policy outperforms image-only baselines, reaches subgoals faster by following more direct trajectories, improves robustness to scene-configuration shifts, and recovers from object-drop failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SERF, a spatiotemporal feature map that represents both the environment and the articulated robot body as neural points in a shared latent space. The map is updated online from egocentric RGB observations and proprioception: environment points via object-level rigid tracking and robot points via forward kinematics. Map tokens are extracted from multiple reference frames and spatial scales to condition a vision-language-action (VLA) policy. On the BEHAVIOR-1K benchmark for long-horizon household mobile manipulation, the SERF-conditioned VLA outperforms image-only baselines, reaches subgoals via more direct trajectories, improves robustness to scene-configuration shifts, and recovers from object-drop failures.
Significance. If the neural-point representation and updates remain faithful, the work would provide a concrete demonstration that explicit spatiotemporal state can improve long-horizon reasoning in VLA policies beyond raw images. The shared latent space for environment and robot, combined with multi-scale/multi-frame token extraction, is a technically coherent way to supply both local and global context. Use of the challenging BEHAVIOR-1K benchmark and the reported qualitative behaviors (direct trajectories, failure recovery) are positive elements that strengthen the empirical case if the underlying tracking assumptions hold.
major comments (1)
- [Method description of map updates (abstract and presumed §3)] The central claim that the SERF map supplies reliable state for the VLA policy rests on the premise that object-level rigid tracking from egocentric views (and forward kinematics) maintains accurate neural points over long horizons. The abstract states that environment points are updated via object-level rigid tracking, yet no ablation, failure-mode analysis, or quantitative tracking-error metrics are referenced; if tracking drifts under occlusion, fast motion, or non-rigid objects, the map tokens cease to encode geometry or articulation faithfully, directly undermining the reported gains on BEHAVIOR-1K.
minor comments (1)
- The abstract would benefit from at least one quantitative headline result (e.g., success rate or average time improvement) rather than purely qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reliability of the SERF map updates. We address the major comment below.
read point-by-point responses
-
Referee: [Method description of map updates (abstract and presumed §3)] The central claim that the SERF map supplies reliable state for the VLA policy rests on the premise that object-level rigid tracking from egocentric views (and forward kinematics) maintains accurate neural points over long horizons. The abstract states that environment points are updated via object-level rigid tracking, yet no ablation, failure-mode analysis, or quantitative tracking-error metrics are referenced; if tracking drifts under occlusion, fast motion, or non-rigid objects, the map tokens cease to encode geometry or articulation faithfully, directly undermining the reported gains on BEHAVIOR-1K.
Authors: We agree that the absence of explicit tracking-error metrics, ablations, and failure-mode analysis leaves the reliability of the map updates insufficiently substantiated in the current manuscript. Section 3 describes the update process using object-level rigid tracking from egocentric RGB and forward kinematics, but does not quantify drift or test robustness to the listed conditions. The reported gains on BEHAVIOR-1K are therefore presented without direct evidence isolating the contribution of accurate map maintenance. In the revision we will add: (i) quantitative tracking accuracy metrics against simulator ground truth, (ii) qualitative and quantitative failure-mode analysis under occlusion and fast motion, and (iii) an ablation that disables online map updates while keeping the rest of the pipeline fixed. These additions will allow readers to assess the conditions under which the spatiotemporal map remains faithful. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines SERF as a neural point map updated from egocentric RGB and proprioception via object-level rigid tracking and forward kinematics, then feeds extracted tokens into a VLA policy. Reported gains are empirical comparisons against image-only baselines on BEHAVIOR-1K. No equations, predictions, or uniqueness claims reduce the performance result to a fitted quantity defined by the method itself, nor to a self-citation chain. The central claim remains an independent empirical observation rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[2]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, et al. π0: A vision-language- action flow model for general robot control. InRobotics: Science and Systems (RSS), 2025
2025
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, et al.π0.5: A vision- language-action model with open-world generalization. InConference on Robot Learning (CoRL), 2025
2025
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, et al. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2024
2024
-
[5]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. Gonzalez Arenas, T. Arm- strong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bohez, K. Bousmalis, A. Brohan, T. Buschmann, A. Byravan, et al. Gemini Robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Physical Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, et al. π∗ 0.6: A VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
P. Liu, Y . Orru, J. Vakil, C. Paxton, N. M. M. Shafiullah, and L. Pinto. OK-Robot: What really matters in integrating open-knowledge models for robotics. InRobotics: Science and Systems (RSS), 2024
2024
-
[9]
J. Chen, H. Liang, L. Du, W. Wang, M. Hu, Y . Mu, W. Wang, J. Dai, P. Luo, W. Shao, and L. Shao. OWMM-Agent: Open world mobile manipulation with multi-modal agentic data synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[10]
Z. Yan, S. Li, Z. Wang, L. Wu, H. Wang, J. Zhu, L. Chen, and J. Liu. Dynamic open-vocabulary 3D scene graphs for long-term language-guided mobile manipulation.IEEE Robotics and Automation Letters (RA-L), 2025
2025
-
[11]
P. Liu, Z. Guo, M. Warke, S. Chintala, C. Paxton, N. M. M. Shafiullah, and L. Pinto. DynaMem: Online dynamic spatio-semantic memory for open world mobile manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025. 9
2025
-
[12]
Mohammadi, D
M. Mohammadi, D. Honerkamp, M. B ¨uchner, M. Cassinelli, T. Welschehold, F. Despinoy, I. Gilitschenski, and A. Valada. MORE: Mobile manipulation rearrangement through grounded language reasoning. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[13]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation world models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[14]
Sridhar, J
A. Sridhar, J. Pan, S. Sharma, and C. Finn. MemER: Scaling up memory for robot control via experience retrieval. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[15]
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowicz, K. Dhabalia, M. Equi, Q. Vuong, J. T. Springenberg, S. Levine, et al. MEM: Multi-scale embodied memory for vision-language-action models.arXiv preprint arXiv:2603.03596, 2026
- [16]
-
[17]
R. Steiner, A. Millane, D. Tingdahl, C. V olk, V . Ramasamy, X. Yao, P. Du, S. Pouya, and S. Sheng. MindMap: Spatial memory in deep feature maps for 3D action policies.arXiv preprint arXiv:2509.20297, 2025
-
[18]
S. Kim, W. Chung, Z. Dai, D. Bhatt, A. Shukla, H. Su, Y . Tian, and N. Atanasov. Seeing the Bigger Picture: 3D latent mapping for mobile manipulation policy learning. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[19]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3D-VLA: A 3D vision- language-action generative world model. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[20]
Aliev, A
K.-A. Aliev, A. Sevastopolsky, M. Kolos, D. Ulyanov, and V . Lempitsky. Neural point-based graphics. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[21]
Y . Pan, X. Zhong, L. Wiesmann, T. Posewsky, J. Behley, and C. Stachniss. PIN-SLAM: LiDAR SLAM using a point-based implicit neural representation for achieving global map consistency. IEEE Transactions on Robotics (T-RO), 2024
2024
-
[22]
O. Sim´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, et al. DINOv3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, et al. BEHA VIOR-1K: A human-centered, embodied AI benchmark with 1,000 everyday activities and realistic simulation. InConference on Robot Learning (CoRL), 2022
2022
-
[24]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, et al. SAM 2: Segment anything in images and videos. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[25]
C. M. Kim, M. Wu, J. Kerr, K. Goldberg, M. Tancik, and A. Kanazawa. GARField: Group anything with radiance fields. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[26]
Shi and C
J. Shi and C. Tomasi. Good features to track. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1994. 10
1994
-
[27]
Karaev, Y
N. Karaev, Y . Makarov, J. Wang, N. Neverova, A. Vedaldi, and C. Rupprecht. CoTracker3: Simpler and better point tracking by pseudo-labelling real videos. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[28]
Q.-Y . Zhou, J. Park, and V . Koltun. Fast global registration. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[29]
P. J. Besl and N. D. McKay. A method for registration of 3-D shapes.IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 1992
1992
-
[30]
Srivastava, C
S. Srivastava, C. Li, M. Lingelbach, R. Mart´ın-Mart´ın, F. Xia, K. Vainio, Z. Lian, C. Gokmen, S. Buch, C. K. Liu, S. Savarese, H. Gweon, J. Wu, and L. Fei-Fei. BEHA VIOR: Benchmark for everyday household activities in virtual, interactive, and ecological environments. InConference on Robot Learning (CoRL), 2021
2021
-
[31]
H. Zhao, L. Jiang, J. Jia, P. Torr, and V . Koltun. Point Transformer. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[32]
I. Larchenko, G. Zarin, and A. Karnatak. Task adaptation of vision-language-action model: 1st place solution for the 2025 BEHA VIOR challenge.arXiv preprint arXiv:2512.06951, 2025
-
[33]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[34]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[35]
Y . Tian, H. Cao, S. Kim, and N. Atanasov. MISO: Multiresolution submap optimization for efficient globally consistent neural implicit reconstruction. InRobotics: Science and Systems (RSS), 2025
2025
-
[36]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 11 Appendix A Map Dataset Generation. . . . . . . . . . . . . . . . . . . . . . . . . 12 B Map Representation Details. . . . . . . . . . . . . . . . . . . . . . 12 C Contrastive Objectives. . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
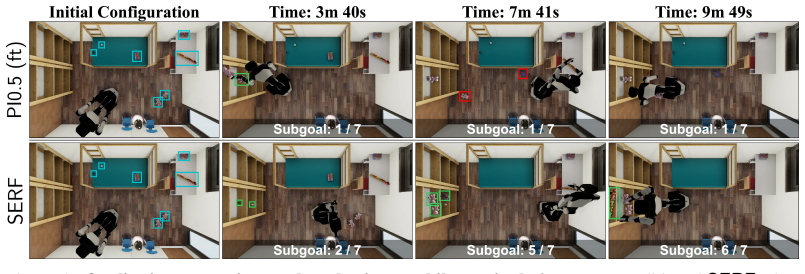
14 Figure 14:Qualitative comparisons on long-horizon mobile manipulation.The row pairs correspond to Task 21, Task 22, and Task 26, respectively, and comparePI0.5 (ft)withSERF
For each task, the top row shows third-person observations of the robot executing the task, and the bottom row shows the corresponding SERF feature map. 14 Figure 14:Qualitative comparisons on long-horizon mobile manipulation.The row pairs correspond to Task 21, Task 22, and Task 26, respectively, and comparePI0.5 (ft)withSERF. In these rollouts,SERFachie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.